兴趣点推荐代码_推荐系统模型阿里用户兴趣模型(附完整代码)
项目地址:StephenBo-China/recommendation_system_sort_model
阿里天池数据集地址:数据集-阿里云天池
最近由于工作需要用tensorflow2.0复现了下阿里的兴趣模型,本文将先对论文进行描述,再介绍如何使用tensorflow2.0进行复现。建议阅读本文前先读一遍论文,本文的论文解析部分可作为辅助。
一、论文解析:
Base Model:
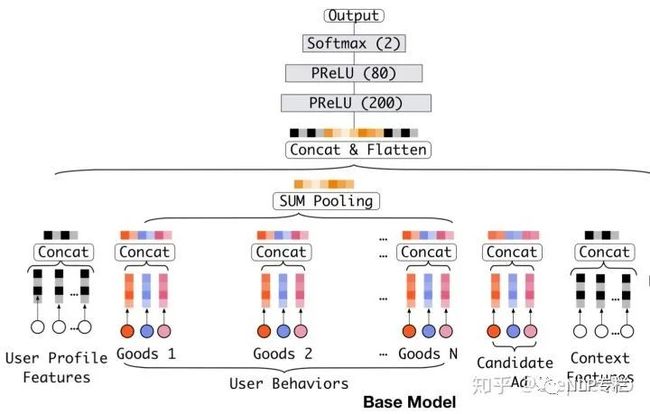
base model比较简单,就是将用户历史行为序列的各个商品的类别特征embedding之后,与非类别特征concat后进入pooling层(sum pooling与average pooling均可,具体可根据实际情况进行调整);pooling后与embedding后的用户画像特征及目标商品特征一起concat后进入最后的MLP得到最终的分类结果。
Embedding Layer:
input: high dimensional binary vectors
ouput: low dimensional dence representations
对于第i个category特征来说,该特征有K个不同类别的值,我们希望将它embedding到D维,则:
为第i个特征的词典, 为第j个类别的embedding后的向量。具体的embedding的其他方法可阅读embedding相关的paper。
2. Pooling Layer:
由于MLP的输入层必须是固定长度的节点数,但是不同用户的历史行为序列长度不同,因而我们没有办法直接对行为序列特征进行concat,为了使得embedding后的行为序列长度相同,我们可以采用pooling操作让行为序列产出的特征长度相同,pooling可使用sum pooling或average pooling。sum对emebdding后的行为序列的各个item求和,average对embedding后的行为序列的各个item求均值得到。
3. MLP:
输入为concat(用户画像特征,pooling(embedding(历史行为序列)),目标商品特征)的全连接神经网络,最终使用softmax得到最终分类结果。loss采用log loss。
Base Mode存在的问题:
pooling直接处理用户历史行为序列会有信息丢失:
Base模型中直接对多个Embedding向量进行等权的sum-pooling,这种方法肯定会带来信息的丢失,而且相对重要的Embedding向量也无法完全突出自己所包含的信息。base model中使用average pooling或者sum pooling对emebdding后的历史行为序列进行处理,对不同用户的行为序列得到同长度的MLP输入。但是这样做对于行为序列内的所有内容都是一视同仁的,不利于用户兴趣的表达。比较简单的方法是将embedding后的向量直接展开,但是这样会增加embedding层的学习权重,容易导致过拟合(个人理解,这样做不但会增加训练权重,且依然不能表达用户的兴趣信息,但是论文中是这样说的)。
2. 如何让Base Model的pooling层产出能够表达出用户兴趣信息?
用Attention给pooling添加权重后求和,让模型更加关注有用的信息。因为在用户的历史行为序列中,展现item的数量要多于点击item,如果直接对行为序列等权sum pooling,展现序列贡献的信息要更多,但是点击item更加能体现用户的实际兴趣,因而加权后进行pooling可以提取出更多的兴趣信息。
DIN:

DIN创新点:
(1) weighted-sum pooling:
a. weighted-sum pooling方法:
在历史行为序列进入pooling前,加入attention层,计算出行为序列中不同item的权重a_i后,再使用如下公式得到sum pooling的结果:
其中, 为embedding后的用户行为序列; 是emebdding后目标商品的特征向量; 为attention层产出结果。
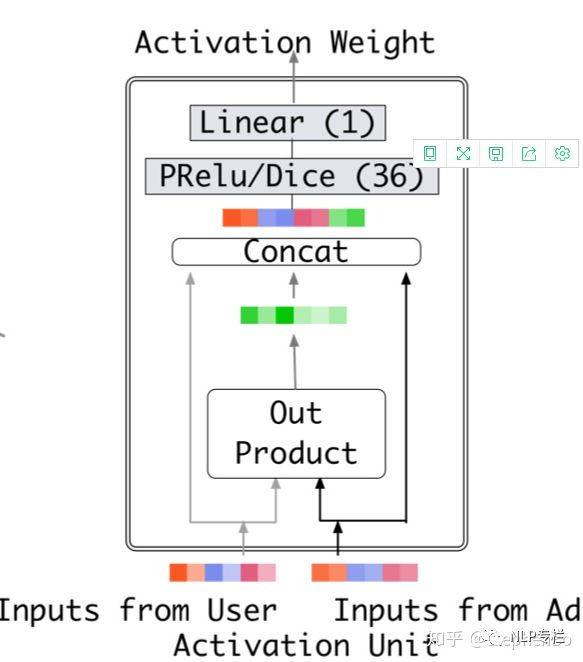
本文attention不使用传统的attention方法,需单独维护一个全连接神经网络得到最终attention结果,attention神经网络的输入为:行为序列中的每个item组合上目标商品的特征concat后作为输入,输出为各个item的权重。即用全连接层得到行为序列各个item的attention权重后,直接使用attention的权重向量与emebdding后行为序列做矩阵乘法即可得到 。
attention的神经网络结构如下图所示:
b. weighted-sum pooling为什么不用传统attenion方法:
传统方法使用softmax获得attention产出的权重被遗弃,因为传统方法使得attention的权重求和为1,这样求得的权重并不是用户兴趣的分布估计,采用神经网络最终使用sigmoid或其他激活函数得到序列attention权重分布,从而获得对用户兴趣的权重估计更适用于用户兴趣的表示。比如一个用户历史行为序列中90%都是衣服,10%是电子产品。如果目标商品是t恤和手机的话,传统attention方法会使得t恤的 高于手机,因为用户的行为序列中大部分都是衣服,但是用户购买手机与否与他购买衣服与否是没有直接关联的,因而不能用传统的方法直接求softmax,softmax使得行为序列中的各个item都有了关联从而得出了商品权重。实际使用时可尝试最后激活函数使用softmax与sigmoid分别看效果后进行选择。
2. Dice激活函数:
可也看到,每一个yi对应了一个概率值pi。pi的计算主要分为两步:将yi进行标准化和进行sigmoid变换。Dice激活函数与batch normalisation一样都是用来解决Internal Covariate Shift问题。
3. Mini-batch Aware Regularization:
商品id等需要embedding的特征,有些特征非常稀疏,导致embedding的训练参数过多,很容易造成过拟合。用户对于商品的数据符合长尾定律,也就是说有些id只出现了几次,而以下部分id会出现很多次,这样训练过程中就加入了更多噪声,使得模型更容易过拟合。因而需要正则化的方法来防止过拟合,但是由于DIN的大部分训练权重都是由embedding贡献的,直接加入L1正则或者L2正则的话会提高模型训练的复杂度(对于一个mini-batch来说,在没有L2正则时,梯度下降只需要更新embedding中的非0参数,但是加入L2正则由于要计算L2-norm,则需要对所有的参数进行计算)。因而论文提出了mini-batch regularization的方法,让模型自适应各个embedding feature的正则化强度。
最终推导出的权重更新公式如下:
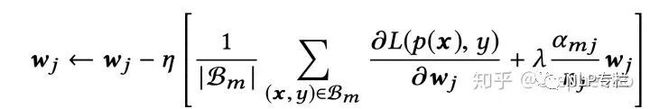
由于Mini-batch Aware Regularization是生效在embedding层的权重更新中,且只有在需要embedding的特征非常稀疏时,才需要该正则化方法,因而本文直接使用tensorflow自带的embedding层,只要输入特征不是非常稀疏,不用该方法不会影响到模型最终效果。
二、实现:
模型自定义层:
1.weighted-sum pooling:
Attention层输入为行为序列与target item组合后的特征,由于一个batch下的行为序列长度不同,因而给长度不足最大长度的补1padding后,输入到全连接神经网络,最后通过sigmoid激活函数得到a(i)的值,在用得到的权重向量与embedding后的行为序列矩阵做矩阵乘法即得到了权重乘以各个item后求和pooling的结果。
class attention(tf.keras.layers.Layer):
def __init__(self, keys_dim):
super(attention, self).__init__()
self.keys_dim = keys_dim
self.fc = tf.keras.Sequential()
self.fc.add(layers.BatchNormalization())
self.fc.add(layers.Dense(100, activation="sigmoid"))
self.fc.add(layers.ReLU())
self.fc.add(layers.Dense(50, activation="sigmoid"))
self.fc.add(layers.ReLU())
self.fc.add(layers.Dense(1, activation=None))
def call(self, queries, keys, keys_length):
#Attention
queries = tf.tile(tf.expand_dims(queries, 1), [1, tf.shape(keys)[1], 1])
din_all = tf.concat([queries, keys, queries-keys, queries*keys], axis=-1)
outputs = tf.transpose(self.fc(din_all), [0,2,1])
key_masks = tf.sequence_mask(keys_length, max(keys_length), dtype=tf.bool)
key_masks = tf.expand_dims(key_masks, 1)
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(key_masks, outputs, paddings)
outputs = outputs / (self.keys_dim ** 0.5)
#outputs = tf.keras.activations.softmax(outputs, -1)
outputs = tf.keras.activations.sigmoid(outputs)
#Sum Pooling
outputs = tf.squeeze(tf.matmul(outputs, keys))
print("outputs:" + str(outputs.numpy().shape))
return outputs2.Dice激活函数:
class dice(tf.keras.layers.Layer):
def __init__(self, feat_dim):
super(dice, self).__init__()
self.feat_dim = feat_dim
self.alphas= tf.Variable(tf.zeros([feat_dim]), dtype=tf.float32)
self.beta = tf.Variable(tf.zeros([feat_dim]), dtype=tf.float32)
self.bn = tf.keras.layers.BatchNormalization(center=False, scale=False)
def call(self, _x, axis=-1, epsilon=0.000000001):
reduction_axes = list(range(len(_x.get_shape())))
del reduction_axes[axis]
broadcast_shape = [1] * len(_x.get_shape())
broadcast_shape[axis] = self.feat_dim
mean = tf.reduce_mean(_x, axis=reduction_axes)
brodcast_mean = tf.reshape(mean, broadcast_shape)
std = tf.reduce_mean(tf.square(_x - brodcast_mean) + epsilon, axis=reduction_axes)
std = tf.sqrt(std)
brodcast_std = tf.reshape(std, broadcast_shape)
x_normed = self.bn(_x)
x_p = tf.keras.activations.sigmoid(self.beta * x_normed)
return self.alphas * (1.0 - x_p) * _x + x_p * _x整体实现:
除了weighted-sum pooling为din的自定义层,其余均为tensorflow包含层,直接通过论文中模型结构构造整个模型即可:

class DIN(tf.keras.Model):
def __init__(self, embedding_count_dict, embedding_dim_dict, embedding_features_list, user_behavior_features, activation="PReLU"):
super(DIN, self).__init__(embedding_count_dict, embedding_dim_dict, embedding_features_list, user_behavior_features, activation)
#Init Embedding Layer
self.embedding_dim_dict = embedding_dim_dict
self.embedding_count_dict = embedding_count_dict
self.embedding_layers = dict()
for feature in embedding_features_list:
self.embedding_layers[feature] = layers.Embedding(embedding_count_dict[feature], embedding_dim_dict[feature])
#DIN Attention+Sum pooling
self.hist_at = attention(utils.get_input_dim(embedding_dim_dict, user_behavior_features))
#Init Fully Connection Layer
self.fc = tf.keras.Sequential()
self.fc.add(layers.BatchNormalization())
self.fc.add(layers.Dense(200, activation="relu"))
if activation == "Dice":
self.fc.add(Dice())
elif activation == "dice":
self.fc.add(dice(200))
elif activation == "PReLU":
self.fc.add(layers.PReLU(alpha_initializer='zeros', weights=None))
self.fc.add(layers.Dense(80, activation="relu"))
if activation == "Dice":
self.fc.add(Dice())
elif activation == "dice":
self.fc.add(dice(80))
elif activation == "PReLU":
self.fc.add(layers.PReLU(alpha_initializer='zeros', weights=None))
self.fc.add(layers.Dense(2, activation=None))
def get_emb_din(self, user_profile_dict, user_profile_list, hist_behavior_dict, target_item_dict, user_behavior_list):
user_profile_feature_embedding = dict()
for feature in user_profile_list:
data = user_profile_dict[feature]
embedding_layer = self.embedding_layers[feature]
user_profile_feature_embedding[feature] = embedding_layer(data)
target_item_feature_embedding = dict()
for feature in user_behavior_list:
data = target_item_dict[feature]
embedding_layer = self.embedding_layers[feature]
target_item_feature_embedding[feature] = embedding_layer(data)
hist_behavior_embedding = dict()
for feature in user_behavior_list:
data = hist_behavior_dict[feature]
embedding_layer = self.embedding_layers[feature]
hist_behavior_embedding[feature] = embedding_layer(data)
return utils.concat_features(user_profile_feature_embedding), utils.concat_features(target_item_feature_embedding), utils.concat_features(hist_behavior_embedding)
def call(self, user_profile_dict, user_profile_list, hist_behavior_dict, target_item_dict, user_behavior_list, length):
#Embedding Layer
user_profile_embedding, target_item_embedding, hist_behavior_emebedding = self.get_emb_din(user_profile_dict, user_profile_list, hist_behavior_dict, target_item_dict, user_behavior_list)
hist_attn_emb = self.hist_at(target_item_embedding, hist_behavior_emebedding, length)
join_emb = tf.concat([user_profile_embedding, target_item_embedding, hist_attn_emb], -1)
logit = tf.squeeze(self.fc(join_emb))
output = tf.keras.activations.softmax(logit)
return output, logit三、实验:
本文使用阿里天池数据集进行实验:
数据集介绍:
用户行为日志:
本数据集涵盖了raw_sample中全部用户22天内的购物行为(共七亿条记录)。字段说明如下:
(1) user:脱敏过的用户ID;
(2) time_stamp:时间戳;
(3) btag:行为类型, 包括以下四种:浏览、加入购物车、喜欢、购买。其中浏览为负例(展现未点击),其他均为正例(点击)。
2. 用户画像特征:
(1) cms_segid:微群ID;
(2) cms_group_id:cms_group_id;
(3) final_gender_code:性别 1:男,2:女;
(4) age_level:年龄层次;
(5) pvalue_level:消费档次,1:低档,2:中档,3:高档;
(6) shopping_level:购物深度,1:浅层用户,2:中度用户,3:深度用户
(7) occupation:是否大学生 ,1:是,0:否
(8) new_user_class_level:城市层级
3. 目标商品:
(1) user_id:脱敏过的用户ID;
(2) adgroup_id:脱敏过的广告单元ID;
(3) time_stamp:时间戳;
(4) pid:资源位;
(5) noclk:为1代表没有点击;为0代表点击;
(6) clk:为0代表没有点击;为1代表点击;
4. 内容特征:
(1) adgroup_id:脱敏过的广告ID;
(2) cate_id:脱敏过的商品类目ID;
(3) campaign_id:脱敏过的广告计划ID;
(4) customer_id:脱敏过的广告主ID;
(5) brand:脱敏过的品牌ID;
(6) price: 宝贝的价格
5. 已处理好的实验数据集:
备注:实际训练样本共23249296条,测试样本共3308665条【用前面7天的做训练样本(20170506-20170512),用第8天的做测试样本(20170513)】。为快速评估复现模型,仅取训练样本中10000条样本进行训练,测试样本中1000条进行测试。
训练loss:
(epoch=3,batch=100,训练数据集10000条,测试数据集1000条)

模型评估:
评估报告

2. ROC曲线及AUC:
