MySQL的函数
目录
第一章 单行函数
0.函数的概念
1.函数的分类
2.基本函数
3.字符串函数
4.日期和时间函数
5.流程控制函数
6.加密与解密
第二章 聚合函数
1.聚合函数
2.group by的使用
3.having的使用
4.where和having的对比
第一章 单行函数
0.函数的概念
概念:将经常使用的代码封装起来,在需要的时候直接调用
作用:提高代码效率和可维护性,提高用户对数据库的管理效率
1.函数的分类
1.单行函数:输入一行输出一行
2.多行函数:输入多行输出一行
2.基本函数
1.常用的数值函数
ceil、ceiling:返回大于或等于某个值的最小整数
floor:返回小于或等于某个值的最大整数
abs-绝对值;
sign-符号函数;
pi-3.1415;
MOD-去余;
least-取最小值;
greatest-取最大值;
代码示例:
SELECT
ABS(-123),ABS(32),SIGN(-23),SIGN(43),PI(),CEIL(32.32),CEILING(-43.23),FLOOR(32.32),
FLOOR(-43.23),MOD(12,5)
FROM DUAL;![]()
2.随机数rand-返回0-1随机数;
rand(x):x作为种子值,相同x返回相同随机数
SELECT RAND(),RAND(),RAND(10),RAND(10),RAND(-1),RAND(-1)
FROM DUAL;![]()
3.四舍五入;round(x):对x四舍五入;
round(x,y):对x四舍五入,保留小数点后Y位;
sqrt(x):返回x的平方根。当x位负数返回null
truncate(x,y):返回x截断y位小数的结果
SELECT
ROUND(12.33),ROUND(12.343,2),ROUND(12.324,-1),TRUNCATE(12.66,1),TRUNCATE(12.66,-1)
FROM DUAL;
4.角度与弧度互换函数

5.三角函数:里面是弧度值
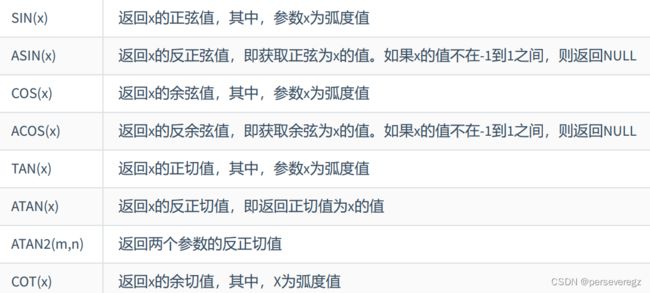
6.指数和对数
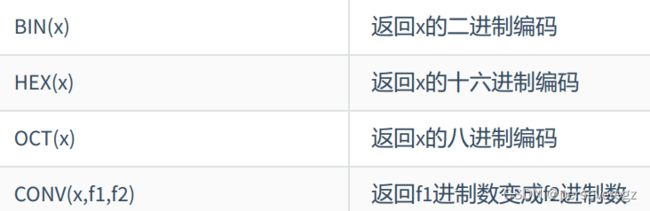
7.进制间的转换
3.字符串函数
1.注意:mysql中索引是从1开始的
2.LPAD:实现右对齐效果(一般右对齐)RPAD:实现左对齐效果

4.日期和时间函数
日期的格式化和解析
格式化:日期——>字符串
解析:字符串——>日期
注意:此时都是对日期的显式操作
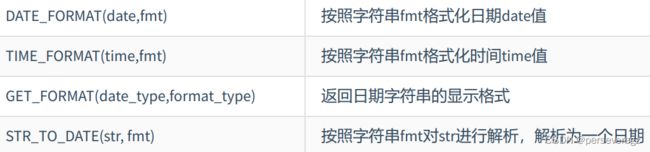
格式化与解析的代码示例:
#格式化
SELECT last_name,hire_date,department_id
FROM employees
WHERE department_id IN (80,90,110)
AND commission_pct IS NOT NULL
AND DATE_FORMAT(hire_date,'%Y-%m-%d') >= '1997-01-01';
#解析
SELECT last_name,hire_date,department_id
FROM employees
WHERE department_id IN (80,90,110)
AND commission_pct IS NOT NULL
AND hire_date >= STR_TO_DATE('1997-01-01','%Y-%m-%d');
5.流程控制函数
1.为什么流程控制函数中没有循环结构?
答:mysql查询中自带循环结构,可以将数据一条一条输出
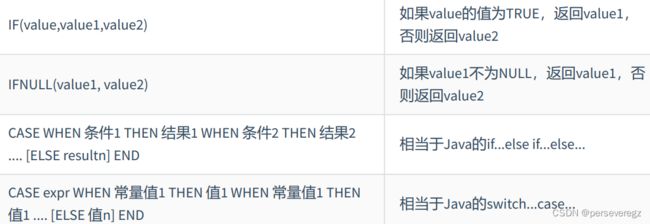
2.理解方式:(MyBatis中会用到)
case when …then:相当于if-else
case…when…then:相当于switch- case
6.加密与解密

注:password():在mysql8.0中弃用;同样encode和decode在mysql8.0中也被弃用;
而MD5和SHA是不可逆的,无法还原回之前的明文
第二章 聚合函数
1.聚合函数
1.定义:作用于一组数据,并只返回一个值
2.常见的聚合函数:
avg/sum:只适用于数值类型的字段/变量
max/min:适用于数值类型、字符串类型、日期时间类型的字段/变量
count:计算指定字段在查询结果中出现的个数;
注意:计算指定字段出现的个数时,是不计算null值的。
代码示例:
SELECT department_name,location_id,COUNT(employee_id) "员工数量",AVG(e.salary) "avg_salary"
FROM employees e
RIGHT JOIN departments d
ON e.department_id = d.department_id
GROUP BY department_name,location_id
ORDER BY avg_salary DESC;2.group by的使用
!!!注意:一旦select中出现了聚合函数和非聚合函数,一定要使用group by!!!
1.可以将表中的数据按需求分成若干组
2.select中出现的非组函数必须声明在group by中,反之不一定
3.group by声明的位置:
在from后面、where后面、order by前面、limit前面
4.group by中使用with rollup:
此时无法使用order by进行排序;且rollup和order by相互排斥
代码示例:
SELECT department_name,job_id,MIN(salary) minsalary
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id
GROUP BY department_name,job_id
ORDER BY minsalary DESC;3.having的使用
1.作用:用来过滤数据
2.如果过滤条件中使用了聚合函数,则必须使用having来替换where,否则报错。
3.having必须声明在group by 的后面。
4.开发中,使用having的前提是SQL中使用了group by。即二者必须一起使用
5.但过滤条件中有聚合函数时,则过滤条件必须声明在having中;当过滤条件中没有过滤条件中,过滤条件中建议声明在where中
代码示例:
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;4.where和having的对比
1.从使用范围上,having的使用范围更广
2.如果过滤条件中没有聚合函数,where的效率高于having
3.where是先筛选后连接;having是先连接后筛选