论文阅读--Segment Anything
Title: Segment Anything
Abstract: We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at Segment Anything | Meta AI to foster research into foundation models for computer vision.
Keywords: NONE
题目:分割任何目标
摘要:我们介绍了Segment Anything(SA)项目:一个用于图像分割的新任务、模型和数据集。通过在数据收集循环中使用我们的高效模型,我们建立了迄今为止最大的分割数据集,在 1100 万张获得许可且尊重隐私的图像上使用了 10 亿多个掩码。该模型被设计和训练为可提示的,因此它可以将零样本转换为新的图像分布和任务。我们评估了其在许多任务上的能力,发现其零样本性能令人印象深刻,通常与之前的完全监督结果相竞争,甚至优于这些结果。我们将在 Segment Anything | Meta AI上发布包含 10 亿个掩膜和 1,100 万张图像的 "分割任意模型"(Segment Anything Model,SAM)和相应的数据集(SA-1B),以促进计算机视觉基础模型的研究。
关键词:无
1.引言
在网络规模数据集上预先训练的大型语言模型正以强大的零样本和较少的快照泛化革新自然语言处理(Natural Language Process,NLP)。这些“基础模型”可以推广到训练过程中看到的任务和数据分布之外的任务。这种功能通常通过提示工程来实现,在提示工程中,手工编制的文本用于提示语言模型为手头的任务生成有效的文本响应。当使用来自网络的大量文本语料库进行缩放和训练时,这些模型的零和少镜头性能与微调模型(在某些情况下甚至匹配)相比出奇地好。经验趋势表明,这种行为随着模型规模、数据集大小和总训练计算的增加而改善。
基础模型也在计算机视觉中进行了探索,尽管程度较低。也许最突出的插图将来自网络的成对文本和图像对齐。例如,CLIP和ALIGN使用对比学习来训练对齐两种模态的文本和图像编码器。经过训练后,工程文本提示可以实现对新视觉概念和数据分布的零样本概括。这种编码器还与其他模块有效组合,以实现下游任务,如图像生成。虽然在视觉和语言编码器方面已经取得了很大进展,但计算机视觉包括了超出这一范围的广泛问题,其中许多问题还不存在丰富的训练数据。
在这项工作中,我们的目标是建立一个图像分割的基础模型。也就是说,我们寻求开发一个可提示的模型,并使用能够实现强大泛化的任务在广泛的数据集上对其进行预训练。有了这个模型,我们的目标是使用即时工程解决新数据分布上的一系列下游分割问题。
这个计划的成功取决于三个组成部分:任务、模型和数据。为了开发它们,我们解决了以下关于图像分割的问题:
1.什么任务可以实现零样本计数普遍化?
2.相应的模型架构是什么?
3.什么数据可以加强该任务和模型?
这些问题错综复杂,需要全面解决。我们首先定义了一个可提示的分割任务,该任务足够通用,可以提供强大的预训练目标,并实现广泛的下游应用。此任务需要一个支持灵活提示的模型,并且可以在提示时实时输出分割掩码,以允许交互式使用。为了训练我们的模型,我们需要一个多样化的、大规模的数据源。
不幸的是,没有用于分割的网络规模的数据源;为了解决这个问题,我们构建了一个“数据引擎”,即我们在使用高效模型来帮助数据收集和使用新收集的数据来改进模型之间进行迭代。接下来,我们介绍每个互连的组件,然后是我们创建的数据集和证明我们方法有效性的实验。
Task(章节2)。在NLP和最近的计算机视觉中,基础模型是一个很有前途的发展,它可以对新数据集和任务执行零样本和少快照学习,通常使用“提示”技术。受这一系列工作的启发,我们提出了可提示的分割任务,其中的目标是在给定任何分割提示的情况下返回有效的分割掩码(见图1a)。提示只是指定在图像中分割什么,例如,提示可以包括标识对象的空间或文本信息。有效输出掩码的要求意味着,即使提示不明确并且可能涉及多个对象(例如,衬衫上的一个点可能指示衬衫或穿着衬衫的人),输出也应该是这些对象中至少一个的合理掩码。我们使用可提示分割任务作为预训练目标,并通过提示工程解决一般的下游分割任务。

图1:我们旨在通过引入三个相互关联的组件来构建分割的基础模型:即时分割任务、支持数据注释并通过即时工程将零样本传输到一系列任务的分割模型(SAM),以及用于收集SA-1B的数据引擎,SA-1B是我们拥有超过10亿个掩码的数据集。
Model(章节3)。可提示的分割任务和真实世界使用的目标对模型架构施加了约束。特别是,该模型必须支持灵活的提示,需要实时计算掩码以允许交互式使用,并且必须具有模糊性意识。令人惊讶的是,我们发现一个简单的设计满足了所有三个约束:强大的图像编码器计算图像嵌入,提示编码器嵌入提示,然后将这两个信息源组合在预测分割掩码的轻量级掩码解码器中。我们将此模型称为分割任意模型或SAM(见图1b)。通过将SAM分离为图像编码器和快速提示编码器/掩码解码器,可以在不同提示下重用相同的图像嵌入(并分摊其成本)。给定一个图像嵌入,提示编码器和掩码解码器在web浏览器中从提示预测掩码,时间为~50ms。我们专注于点、框和遮罩提示,还使用自由形式的文本提示显示初始结果。为了让SAM意识到模糊性,我们将其设计为预测单个提示的多个掩码,使SAM能够自然地处理模糊性,例如衬衫与人的示例。
Data engine(章节 4)。为了实现对新数据分布的强泛化,我们发现有必要在一组庞大而多样的掩码上训练SAM,而不是现有的任何分割数据集。虽然基础模型的一种典型方法是在线获取数据,但口罩并不自然丰富,因此我们需要一种替代策略。我们的解决方案是建立一个“数据引擎”,即我们与模型在环数据集注释共同开发我们的模型(见图1c)。我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM帮助注释器注释掩码,类似于经典的交互式分段设置。在第二阶段,SAM可以通过提示可能的对象位置自动为对象子集生成掩码,注释器专注于注释其余对象,有助于增加掩码的多样性。在最后阶段,我们用前景点的规则网格提示SAM,平均每张图像产生约100个高质量掩膜。
Dataset(章节5)。我们的最终数据集SA-1B包括来自一千一百万个许可和隐私保护图像的超过10亿个掩模(见图2)。SA-1B是使用我们的数据引擎的最后阶段完全自动收集的,其掩码比任何现有的分割数据集都多400倍,正如我们广泛验证的那样,掩码具有高质量和多样性。
Responsible AI(章节6)。我们研究并报告了使用SA-1B和SAM时潜在的公平问题和偏差。SA-1B中的图像跨越了地理和经济上不同的国家,我们发现SAM在不同人群中表现相似。我们希望这将使我们的工作在现实世界的用例中更加公平。我们在附录中提供了模型和数据集卡。
Experiments(章节7)。我们对SAM进行了广泛的评估。首先,使用一套由23个分割数据集组成的新数据集,我们发现SAM从单个前景点产生了高质量的掩模,通常仅略低于手动注释的地面实况。其次,我们使用提示工程在零样本传输协议下的各种下游任务上发现了一致的强定量和定性结果,包括边缘检测、对象建议生成、实例分割和文本到掩码预测的初步探索。这些结果表明,SAM可以与即时工程一起开箱即用,以解决涉及SAM训练数据之外的对象和图像分布的各种任务。尽管如此,正如我们在第8节中所讨论的,仍有改进的空间。
发布(Release):我们发布SA-1B数据集用于研究目的,并在允许的开放许可证(Apache 2.0)下提供SAM Segment Anything | Meta AI.我们还通过在线演示展示SAM的能力。
图2:我们旨在通过引入三个相互关联的组件来构建分割的基础模型:即时分割任务、支持数据注释并通过即时工程将零样本传输到一系列任务的分割模型(SAM),以及用于收集SA-1B的数据引擎,SA-1B是我们拥有超过10亿个掩码的数据集。
2.分割任意任务
我们从NLP中获得了灵感,其中下一个令牌预测任务用于基础模型预训练,并通过prompt engineering解决各种下游任务(Language models are few-shot learners)。为了建立分割的基础模型,我们的目标是定义具有类似功能的任务。
Task. 我们首先将提示的概念从NLP转换为分割,其中提示可以是一组前景/背景点、粗略框或掩码、自由格式文本,或者通常是指示在图像中分割什么的任何信息。那么,可提示的分割任务是在给定任何提示的情况下返回有效的分割掩码。“有效”掩码的要求只是意味着,即使提示不明确,并且可能涉及多个对象(例如,回忆衬衫与人的例子,见图3),输出也应该是其中至少一个对象的合理掩码。这一要求类似于期望语言模型对不明确的提示输出连贯的响应。我们选择此任务是因为它会产生一种自然的预训练算法和一种通过提示将零样本转移到下游分割任务的通用方法。
图3:每列显示SAM从单个不明确的点提示(绿色圆圈)生成的3个有效掩码。
Pre-training。可提示分割任务提出了一种自然的预训练算法,该算法模拟每个训练样本的提示序列(例如,点、框、掩码),并将模型的掩码预测与基本事实进行比较。我们将这种方法从交互式分割中改编出来,尽管与交互式分割不同,交互式分割的目的是在足够的用户输入后最终预测有效的掩码,但我们的目的是始终预测任何提示的有效掩码,即使提示不明确。这确保了预先训练的模型在涉及歧义的用例中是有效的,包括我们第四节data engine要求的自动注释。我们注意到,在这项任务中表现出色具有挑战性,需要专门的建模和训练损失选择,我们将在第三节中讨论。
Zero-shot transfer。直观地说,我们的预训练任务赋予了模型在推理时对任何提示做出适当响应的能力,因此可以通过设计适当的提示来解决下游任务。例如,如果有一个猫的边界框检测器,则可以通过向我们的模型提供检测器的框输出作为提示来解决猫实例分割问题。一般来说,一系列实用的分割任务可以作为提示。除了自动数据集标记外,我们还在第七节中的实验中探索了五个不同的示例任务。
相关任务(Related tasks)。分割是一个广泛的领域:有交互式分割(interactive segmentation)、边缘检测(edge detection)、超级像素化(super pixelization)、对象建议生成(object proposal generation)、前景分割(foreground segmentation)、语义分割(semantic segmentation)、实例分割(instance segmentation)、全景分割(panoptic segmentation)等。我们的可提示分割任务的目标是生成一个功能广泛的模型,可以通过即时工程适应许多(尽管不是全部)现有和新的分割任务。这种能力是任务泛化的一种形式。请注意,这与之前关于多任务分割系统的工作不同。在多任务系统中,单个模型执行一组固定的任务,例如联合语义、实例和全景分割,但训练和测试任务是相同的。我们工作中的一个重要区别是,为可提示分割训练的模型可以在推理时通过充当更大系统中的组件来执行新的不同任务,例如,为了执行实例分割,将可提示分割模型与现有的对象检测器相结合。
讨论(Discussion)。提示和组合是功能强大的工具,使单个模型能够以可扩展的方式使用,有可能完成模型设计时未知的任务。这种方法类似于其他基础模型的使用方式,例如CLIP是DALL·E图像生成系统的文本图像对齐组件。我们预计,与专门为固定任务集训练的系统相比,由即时工程等技术提供动力的可组合系统设计将实现更广泛的应用程序。从合成的角度比较可提示分割和交互式分割也很有趣:虽然交互式分割模型是在考虑人类用户的情况下设计的,但为可提示分割训练的模型也可以组成一个更大的算法系统,正如我们将要演示的那样。
3.分割任意模型
接下来,我们将描述可提示分割的分割任意模型(SAM)。SAM有三个组件,如图4所示:图像编码器、灵活提示编码器和快速掩码解码器。我们建立在Transformer视觉模型的基础上,对(摊销的)实时性能进行了特定的权衡。我们在这里对这些组成部分进行了高层描述,详细信息见附录A。

图4:分段任意模型(SAM)概述。重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询该图像嵌入,以摊余的实时速度生成对象掩码。对于与多个对象对应的模糊提示,SAM可以输出多个有效掩码和相关的置信度分数。
图像编码器(Image encoder)。受可扩展性和强大的预训练方法的启发,我们使用了MAE预训练的视觉转换器(Vision Transformer, ViT)[33],该转换器至少适用于处理高分辨率输入[62]。图像编码器每个图像运行一次,并且可以在提示模型之前应用。
提示编码器(Prompt encoder)。我们考虑两组提示:稀疏(点、框、文本)和密集(掩码)。我们通过位置编码来表示点和框,这些位置编码与每个提示类型的学习嵌入相加,并使用CLIP中现成的文本编码器来表示自由格式文本。密集提示(即掩码)使用卷积嵌入,并与图像嵌入逐元素求和。
掩码解码器(Mask decoder)。掩码解码器有效地将图像嵌入、提示嵌入和输出令牌映射到掩码。该设计受到的启发,采用了Transformer解码器块的修改,然后是动态掩码预测头。我们修改的解码器块在两个方向上使用提示自注意和交叉注意(提示到图像嵌入,反之亦然)来更新所有嵌入。在运行两个块之后,我们对图像嵌入进行上采样,MLP将输出令牌映射到动态线性分类器,然后该分类器计算每个图像位置的掩码前景概率。
解决歧义(Resolving ambiguity)。对于一个输出,如果给出不明确的提示,模型将平均多个有效掩码。为了解决这一问题,我们修改了模型,以预测单个提示的多个输出掩码(见图3)。我们发现,3个掩码输出足以解决最常见的情况(嵌套掩码通常最多有三个深度:整体、部分和子部分)。在训练过程中,我们只在掩膜上反向探测最小的损失。为了对掩码进行排序,该模型预测每个掩码的置信度得分(即估计的IoU)。
效率(Efficiency)。整个模型的设计很大程度上是出于效率的考虑。给定预先计算的图像嵌入,提示编码器和掩码解码器在网络浏览器中运行,在CPU上,大约50ms。这种运行时性能使我们的模型能够无缝、实时地交互提示。
损失和训练(Losses and training)。我们使用(End-to-end object detection with Transformers)中使用的focal loss [65]和dice loss [73]的线性组合来监督掩模预测。我们使用几何提示的混合来训练可提示的分割任务(文本提示请参见第7章第5)。在[92,37]之后,我们通过每个掩码随机抽样11轮提示来模拟交互式设置,使SAM能够无缝集成到我们的数据引擎中。
4. 分割任意数据引擎
由于互联网上的分割掩码并不丰富,我们建立了一个数据引擎来收集我们的11亿个掩码数据集SA-1B。数据引擎有三个阶段:(1)模型辅助的手动注释阶段,(2)混合了自动预测掩码和模型辅助注释的半自动阶段,以及(3)我们的模型在没有注释器输入的情况下生成掩码的全自动阶段。我们将详细介绍每一个。
辅助手动阶段(Assisted-manual stage)。在第一阶段,类似于经典的交互式分割,一组专业注释人员通过使用SAM提供的基于浏览器的交互式分割工具点击前景/背景对象点来标记掩膜。掩膜可以使用pixelprecise“画笔”和“橡皮擦”工具进行细化。我们的模型辅助注释直接在浏览器内实时运行(使用预先计算的图像嵌入),从而实现真正的交互式体验。我们没有对标记对象施加语义约束,注释器可以自由地标记“东西”和“事物”。我们建议注释器标记他们可以命名或描述的对象,但没有收集这些名称或描述。要求注释者按突出顺序标注目标,并鼓励注释者在一个掩膜的注释时间超过 30 秒后继续注释下一个图像。
在这个阶段开始时,SAM是使用公共分割数据集进行训练的。在充分的数据注释之后,仅使用新注释的掩码对SAM进行再训练。随着收集到更多的掩模,图像编码器从ViT-B扩展到ViT-H,并发展了其他架构细节;我们总共对模型进行了6次再培训。随着模型的改进,每个掩码的平均注释时间从34秒减少到14秒。我们注意到,14秒比COCO的掩码注释快6.5倍,仅比使用极值点的边界框标记慢2倍。随着SAM的改进,每张图像的平均掩模数量从20个增加到44个。总的来说,我们在这个阶段从120k张图像中收集了430万个掩码。
半自动阶段(Semi-automatic stage)。在这个阶段,我们的目标是增加掩码的多样性,以提高我们的模型分割任何东西的能力。为了将注释器集中在不太突出的对象上,我们首先自动检测到自信的掩码。然后,我们向注释器展示了预先填充了这些掩码的图像,并要求他们注释任何其他未注释的对象。为了检测可靠的掩码,我们使用通用的“对象”类别在所有第一阶段掩码上训练了一个边界框检测器[84]。在此阶段,我们在180k张图像中额外收集了590万个掩模(总共1020万个掩膜)。与第一阶段一样,我们定期根据新收集的数据对模型进行再培训(5次)。每个掩码的平均注释时间回到了34秒(不包括自动掩码),因为这些对象更难标记。每张图像的平均掩码数量从44个增加到72个(包括自动掩码)。
全自动阶段(Fully automatic stage)。在最后阶段,注释是完全自动的。这是可行的,因为我们的模型有两个主要的改进。首先,在这个阶段开始时,我们收集了足够的掩膜来大大改进模型,包括前一阶段的各种掩膜。其次,到了这个阶段,我们已经开发了模糊感知模型,它使我们能够预测有效的掩码,即使在模糊的情况下也是如此。具体来说,我们用32×32的规则网格提示模型,并为每个点预测一组可能对应于有效对象的掩膜。使用模糊感知模型,如果一个点位于部分或子部分上,我们的模型将返回子部分、部分和整个对象。我们模型的IoU预测模块用于选择置信掩膜;此外,我们只识别并选择了稳定的掩膜(如果在0.5-δ 和0.5+δ 处对概率图进行阈值处理会导致类似的掩膜,则我们认为掩膜是稳定的)。最后,在选择了置信和稳定的掩码后,我们应用非最大抑制(NMS)来过滤重复。为了进一步提高较小掩膜的质量,我们还处理了多个重叠的放大图像裁剪。有关此阶段的更多详细信息,请参见附录B。我们将全自动掩模生成应用于数据集中的所有1100万张图像,总共生成了11亿个高质量掩膜。接下来,我们将描述并分析生成的数据集SA-1B。
5. 分割任意目标数据集
我们的数据集SA-1B由我们的数据引擎收集的1100万多样、高分辨率、许可和隐私保护图像以及11亿个高质量分割掩膜组成。我们将SA-1B与现有数据集进行了比较,并分析了掩膜质量和特性。我们正在发布SA-1B,以帮助未来开发计算机视觉的基础模型。我们注意到,SA-1B将在某些研究用途的有利许可协议下发布,并为研究人员提供保护。
Images。我们从一家直接与摄影师合作的供应商那里获得了1100万张新照片的许可。这些图像具有高分辨率(平均3300×4950像素),由此产生的数据大小可能会带来可访问性和存储方面的挑战。因此,我们发布了最短边设置为1500像素的下采样图像。即使在下采样之后,我们的图像的分辨率也明显高于许多现有的视觉数据集(例如,COCO图像为~480×640像素)。请注意,目前大多数模型都使用分辨率低得多的输入。在公布的图像中,人脸和车牌被模糊了。
Masks。我们的数据引擎产生了11亿个掩膜,其中99.1%是完全自动生成的。因此,自动掩膜的质量至关重要。我们将它们直接与专业注释进行比较,并观察各种掩膜属性与突出的分割数据集的比较情况。正如下面的分析和第7章中的实验所证实的那样,我们的主要结论是,我们的自动掩膜质量高,对训练模型有效。受这些发现的启发,SA-1B仅包括自动生成的掩膜。
Mask quality。为了估计掩膜质量,我们随机采样了500张图像(~50k个掩膜),并要求我们的专业注释人员提高这些图像中所有掩膜的质量。注释人员使用我们的模型和像素精确的“画笔”和“橡皮擦”编辑工具来完成这项工作。这一过程产生了一对自动预测和专业校正的掩膜。我们计算了每对之间的IoU,发现94%的对的IoU大于90%(97%的对的IoU大于75%)。为了进行比较,先前的工作估计注释器之间的一致性为85-91%IoU[44,60]。我们在§7中的实验通过人工评分证实,相对于各种数据集,掩膜质量很高,在自动掩膜上训练我们的模型几乎与使用数据引擎产生的所有掩膜一样好。
Mask properties。在图5中,与现有最大的分割数据集相比,我们绘制了SA-1B中对象中心的空间分布。所有数据集中都存在常见的摄影师偏差。我们观察到,与分布最相似的两个数据集LVIS v1和ADE20K相比,SA-1B具有更大的图像角覆盖范围,而COCO和Open Images V5具有更显著的中心偏差。
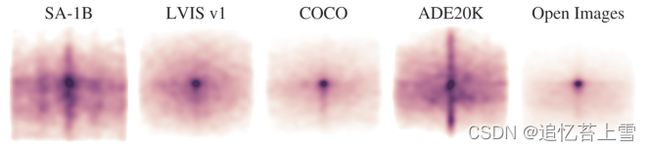
图5:图像大小归一化掩膜中心分布。
在图6(图例)中,我们按大小比较了这些数据集。SA-1B比第二大的Open images多了11倍的图像和400倍的掩膜。平均而言,它每张图像的掩膜是Open Images的36倍。在这方面最接近的数据集ADE20K,每张图像的掩膜仍然减少了3.5倍。图6(左)绘制了掩膜周边图像的分布。接下来,我们看看图中的图像相对掩膜大小(掩膜面积除以图像面积的平方根)。第6(中间)段。正如预期的那样,由于我们的数据集每张图像都有更多的掩膜,因此它也倾向于包括更大比例的中小型相对大小掩膜。最后,为了分析形状的复杂性,我们观察图中的掩膜凹度(1减去掩膜面积除以掩膜凸包的面积)。第6(右)段。由于形状复杂度与掩膜大小相关,我们通过首先从装仓掩膜大小执行分层采样来控制数据集的掩膜大小分布。我们观察到,我们的掩膜的凹陷分布与其他数据集的凹陷分布大致相似。

图6:数据集掩膜属性。图例引用了每个数据集中图像和掩膜的数量。请注意,SA-1B比现有最大的分割数据集Open images多了11倍的图像和400倍的掩膜。
6. 分割任意RAI分析
接下来,我们通过调查使用 SA-1B 和 SAM 时可能存在的公平性问题和偏差,对我们的工作进行了可靠的人工智能(Responsible AI, RAI)分析。我们重点关注 SA-1B 的地域分布和收入分布,以及 SAM 在受保护人群属性方面的公平性。我们还在附录F中提供了数据集、数据注释和模型卡。
地域和收入代表性(Geographic and income representation)。我们推断国家图像是使用标准方法拍摄的(见附录C)。在图7中,我们可视化了SA-1B(左)和图像最多的50个国家(右)中的每个国家的图像计数。我们注意到,排名前三的国家来自世界不同地区

图7:SA-1B图像的估计地理分布。世界上大多数国家的SA-1B图像都超过1000张,图像最多的三个国家来自世界不同地区。
接下来,在表1中,我们比较了SA-1B、COCO和Open Images的地理和收入代表。SA-1B在欧洲、亚洲和大洋洲以及中等收入国家的图片比例要高得多。所有数据集都低估了非洲和低收入国家的代表性。我们注意到,在SA-1B中,包括非洲在内的所有地区都至少有2800万个掩膜,比以往任何数据集的掩膜总数都多10倍。最后,我们观察到每个图像(未示出)的平均掩模数量在区域和收入之间相当一致(每个图像94-108个)。

表1:地域代表性和收入代表性的比较。SA-1B在欧洲、亚洲和大洋洲以及中等收入国家拥有较高的代表性。来自非洲、拉丁美洲和加勒比地区以及低收入国家的图像在所有数据集中的代表性都不足。
分割人群的公平性(Fairness in segmenting people)。我们通过测量各组之间SAM的表现差异,调查了感知性别表现、感知年龄组和感知肤色的潜在公平问题。我们使用更具包容性的人注释(MIAP)数据集来进行性别表示和年龄,并使用专有的肤色数据集(见附录C)。我们的评估使用模拟交互式分割,随机采样1和3个点(见附录D)。表2(左上)显示了感知性别表现的结果。我们注意到,女性在检测和分割数据集中的代表性不足,但观察到SAM在各组中的表现相似。我们重复表2中对感知年龄的分析(左下),注意到那些被感知为越来越年轻的人在大规模数据集中的代表性不足。SAM在那些被认为年龄较大的人身上表现最好(尽管置信区间很大)。最后,我们重复表2(右)中对感知肤色的分析,注意到在大规模数据集中,表观肤色较浅的人被证明代表性过高,而肤色较深的人代表性不足。
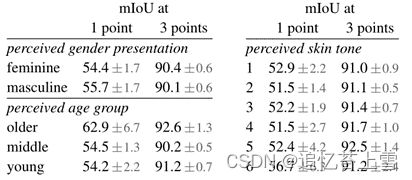
表2:SAM根据感知的性别表现、年龄组和肤色对人群进行细分的表现。显示了95%的置信区间。在每一组中,除了较老的置信区间与中等的置信区间外,所有置信区间都重叠。
由于MIAP不包含感知肤色注释,我们使用了一个专有数据集,该数据集包含感知Fitzpatrick皮肤类型的注释,其范围从1(最浅肤色)到6(最深肤色)。虽然平均数有所不同,但我们没有发现各组之间的显著差异。我们相信我们的发现源于任务的性质,并承认当SAM被用作更大系统的组件时可能会出现偏差。最后,在附录C中,我们将分析扩展到服装细分,在那里我们发现了感知性别表现的偏见迹象。
7. 零样本迁移实验
在本节中,我们将介绍SAM的零样本迁移实验,即分段任意模型。我们考虑了五个任务,其中四个任务与用于训练SAM的可提示分割任务有很大不同。这些实验在训练期间没有看到的数据集和任务上评估SAM(我们使用的“零样本迁移”遵循CLIP中的用法)。数据集可以包括新颖的图像分布,例如水下或以自我为中心的图像(例如图8),据我们所知,并未出现在SA-1B中。

图8:来自23个不同分段数据集的样本,用于评估SAM的零样本迁移能力。
我们的实验从测试提示分割的核心目标开始:从任何提示生成有效的掩码。我们强调单一前景点提示的挑战性场景,因为它比其他更具体的提示更有可能是模糊的。接下来,我们介绍了一系列实验,这些实验跨越了低、中、高级别的图像理解,并大致平行于该领域的历史发展。具体而言,我们提示SAM(1)执行边缘检测,(2)对所有内容进行分割,即。对象建议生成,(3)分割检测到的对象,即实例分割,以及(4)作为概念证明,从自由格式文本中分割对象。这四项任务与SAM接受培训并通过即时工程实施的可提示分割任务有很大不同。我们的实验以消融研究结束。
Implementation。除非另有规定:(1)SAM使用MAE预训练的ViT-H图像编码器,(2)SAM在SA-1B上训练,注意该数据集仅包括数据引擎最后阶段自动生成的掩膜。关于所有其他模型和训练细节,如超参数,请参考附录A。
7.1 零样本单点有效掩膜评估
任务(Task)。我们评估从单个前景点分割对象。由于一个点可以引用多个对象,因此任务不适合。大多数数据集中的地面实况掩膜并没有列举所有可能的掩膜,这可能会使自动度量变得不可靠。因此,我们用一项人类研究来补充标准的mIoU指标(即预测掩膜和地面实况掩膜之间的所有IoU的平均值),在该研究中,注释者对掩膜质量的评分从1(无意义)到10(像素完美)。有关更多详细信息,请参见附录D.1、E和G。
默认情况下,我们根据交互式分割中的标准评估协议[92],从地面实况掩膜的“中心”(掩膜内部距离变换的最大值)采样点。由于SAM能够预测多个掩膜,因此默认情况下,我们只评估模型中最有信心的掩膜。基线都是单掩膜方法。我们主要与RITM[92]进行比较,这是一种强大的交互式分割器,与其他强大的基线相比,它在我们的基准上表现最好[67,18]。
数据集(Datasets)。我们使用了一套新编译的23个数据集,这些数据集具有不同的图像分布。图8列出了数据集,并显示了每个数据集的样本(更多详细信息,请参见附录表7)。我们使用所有23个数据集进行mIoU评估。对于人类研究,我们使用图9b中列出的子集(由于此类研究的资源需求)。该子集包括SAM根据自动度量优于和低于RITM的两个数据集。

表7:使用点提示评估零样本分割的分割数据集。23个数据集涵盖了广泛的领域;请参阅“image type”栏。为了提高我们的评估效率,我们对超过15k个掩膜的数据集进行了子采样。具体来说,我们对图像进行随机采样,使图像中的掩膜总数为~10k。(以上是部分截图,详情见原文)
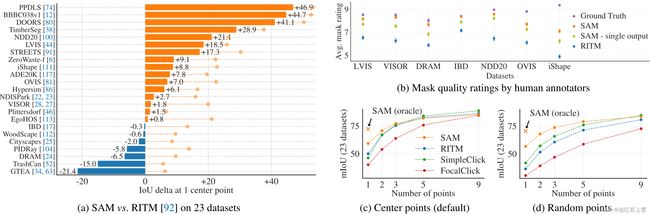
图9:23个数据集上的点对掩膜评估。(a) SAM和最强单点分割器RITM[92]的平均IoU。由于模糊性,单个掩膜可能与地面实况不匹配;圆圈显示SAM的3个预测中最相关的“预言”结果。(b) 注释器对掩膜质量评级的每个数据集比较,从1(最差)到10(最好)。所有方法都使用地面实况遮罩中心作为提示。(c,d)mIoU,具有不同数量的点。SAM以1分的成绩显著优于先前的交互式分割器,并且与更多的分数不相上下。1点处的低绝对mIoU是模糊性的结果。
结果(Result)。首先,我们研究使用mIoU对23个数据集的全套数据集进行自动评估。我们比较了图9a中每个数据集的结果与RITM。SAM在23个数据集中的16个数据集上产生了更高的结果,高达~47 IoU。我们还提出了一个“预言”结果,其中SAM的3个掩膜中最相关的是通过将它们与基本事实进行比较来选择的,而不是选择最可靠的掩膜。这揭示了模糊性对自动评估的影响。特别是,使用oracle来执行模糊性解决,SAM在所有数据集上都优于RITM。
人体研究结果如图9b所示。误差条是平均掩码评级的95%置信区间(所有差异都是显著的;详见附录E)。我们观察到,注释者一致认为SAM掩码的质量大大高于最强基线RITM。一个带有单一输出掩码的烧蚀的“模糊感知”SAM版本的评级一直较低,尽管仍高于RITM。SAM的平均评级在7到9之间,这与定性评级指南相对应:“高分(7-9):对象是可识别的,错误很小,也很罕见(例如,缺少一个小的、严重模糊的断开组件,…)。”这些结果表明SAM已经学会从一个点分割有效的掩膜。请注意,对于像DRAM和IBD这样的数据集,SAM在自动指标上更差,它在人类研究中得到的评级一直更高。
图9c显示了额外的基准,SimpleClick和FocalClick,它们获得的单点性能低于RITM和SAM。随着点数从1增加到9,我们观察到方法之间的差距减小。随着任务变得更容易,这是意料之中的事;此外,SAM没有针对非常高的IoU制度进行优化。最后,在图9d中,我们将默认的中心点采样替换为随机点采样。我们观察到SAM和基线之间的差距越来越大,并且SAM能够在任何一种采样方法下获得可比较的结果。
7.2 零样本边缘检测
方法(Approach)。我们使用BSDS500在边缘检测的经典低级别任务上评估SAM。我们使用一个简化版本的自动掩膜生成管道。具体来说,我们用前景点的16×16规则网格提示SAM,从而产生768个预测掩膜(每个点3个)。冗余掩码由NMS移除。然后,使用无阈值掩码概率图的Sobel滤波和标准轻量级后处理(包括边缘NMS)来计算边缘图(详见附录D.2)。
结果(Result)。我们在图10中可视化了具有代表性的边缘图(更多信息见图15)。定性地说,我们观察到,即使SAM没有经过边缘检测训练,它也能产生合理的边缘图。与基本事实相比,SAM预测了更多的边缘,包括BSDS500中未注释的合理边缘。这种偏差定量地反映在表3中:50%精度(R50)的召回率很高,但以精度为代价。SAM自然落后于学习BSDS500偏差的最先进方法,即要抑制哪些边缘。然而,与HED(也接受过BSDS500培训)等开创性深度学习方法相比,SAM表现良好,并且明显优于以前的零样本转移方法,尽管该方法已经过时。

图10:BSDS500上的零样本边缘预测。SAM没有被训练来预测边缘图,也没有在训练期间访问BSDS图像或注释。
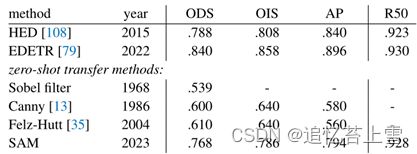
表3:BSDS500上的零样本传输到边缘检测。
7.3 零样本目标建议
方法(Approach)。方法。接下来,我们将评估 SAM 在生成对象提案这一中级任务上的表现。这项任务在物体检测研究中发挥了重要作用,是开创性系统的中间步骤。为了生成对象建议,我们运行了一个稍微修改过的自动掩膜生成通道版本,并将掩码作为建议输出(有关详细信息,请参见附录D.3)。
我们在LVIS v1上计算标准平均召回率(AR)指标。我们关注LVIS,因为它的大量类别是一个具有挑战性的测试。我们将其与作为ViTDet检测器(具有级联掩膜R-CNN ViT-H)实现的强基准进行比较。我们注意到,这个“基准”对应于游戏AR中显示的“检测器伪装为提案生成器”(Detector Masquerading
as Proposal, DMP)方法,使其成为一个真正要求苛刻的比较。
结果(Result)。在表4中,我们毫不奇怪地看到,使用来自ViTDet-H的检测作为对象建议(即,玩AR游戏的DMP方法)总体上表现最好。然而,SAM在几个指标上做得非常好。值得注意的是,它在中型和大型对象以及稀有和常见对象上的性能优于ViTDet-H。事实上,SAM只在小对象和频繁对象上表现不如ViTDet-H,其中ViTDet-H可以很容易地学习LVIS特定的注释偏差,因为它是在LVIS上训练的,而不是SAM。我们还将其与消除歧义的SAM版本(“single-out.”)进行了比较,后者在所有AR指标上的表现明显不如SAM。

表4:LVIS v1上的对象建议生成。SAM应用于零样本,即它没有经过对象建议生成训练,也没有访问LVIS图像或注释。
7.4 零样本实例分割
方法(Approach)。转到更高层次的愿景,我们使用SAM作为实例分割器的分割模块。实现很简单:我们运行一个对象检测器(之前使用的ViTDet),并用其输出框提示SAM。这说明了在更大的系统中组成SAM。
结果(Result)。我们比较了表5中SAM和ViTDet对COCO和L VIS预测的掩膜。从掩膜AP指标来看,我们在两个数据集上都观察到了差距,其中SAM相当接近,尽管肯定落后于ViTDet。通过可视化输出,我们观察到SAM掩膜通常在质量上优于ViTDet的掩膜,具有更清晰的边界(参见§D.4和图16)。为了调查这一观察结果,我们进行了一项额外的人体研究,要求注释者在之前使用的1到10质量量表上对ViTDet掩膜和SAM掩膜进行评分。在图11中,我们观察到SAM在人体研究中始终优于ViTDet。
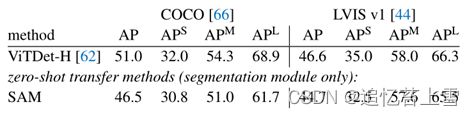
表5:实例分割结果。使用ViTDet框提示SAM进行零样本分段。全监督的ViTDet优于SAM,但在更高质量的LVIS掩模上差距缩小。有趣的是,根据人工评分,SAM优于ViTDet(见图11)。

图11:我们对ViTDet和SAM的人体研究中的口罩质量评级分布,均应用于L VIS地面实况盒。我们还报告了LVIS和COCO地面实况质量。图例显示了评级平均值和95%置信区间。尽管其AP较低(表5),但SAM的评级高于ViTDet,这表明ViTDet利用了COCO和L VIS训练数据中的偏差。
我们假设,在COCO上,掩膜AP间隙较大,基本事实质量相对较低(如人类研究所证实的),ViTDet了解了COCO掩膜的具体偏差。SAM是一种零样本方法,无法利用这些(通常不需要的)偏差。LVIS数据集具有更高质量的基本事实,但仍然存在特定的特性(例如,掩膜不包含洞,它们是构造的简单多边形)以及模态掩膜与阿莫尔掩膜的偏差。同样,SAM没有接受过学习这些偏见的培训,而ViTDet可以利用这些偏见。
7.5 零样本文本到掩码
方法(Approach)。最后,我们考虑一个更高层次的任务:从自由格式文本中分割对象。这个实验证明了SAM处理文本提示的能力。虽然我们在之前的所有实验中都使用了完全相同的SAM,但对于这一次,SAM的训练过程被修改为具有文本意识,但不需要新的文本注释。具体地,对于面积大于1002的每个手动收集的掩模,我们提取CLIP图像嵌入。然后,在训练过程中,我们用提取的CLIP图像嵌入作为SAM的第一次交互来提示SAM。这里的关键观察是,因为CLIP的图像嵌入被训练为与文本嵌入对齐,所以我们可以使用图像嵌入进行训练,但使用文本嵌入进行推理。也就是说,在推理时,我们通过CLIP的文本编码器运行文本,然后将生成的文本嵌入作为SAM的提示(详见附录D.5)。
结果(Result)。我们在图12中显示了定性结果。SAM可以根据简单的文本提示(如“a wheel”)以及短语(如“beaver tooth grille”)来分割对象。当SAM无法仅从文本提示中选择正确的对象时,一个额外的点通常会修复预测,类似于[PhraseClick: toward achieving flexible interactive segmentation by phrase and click]。

图12:零样本文本到掩码。SAM可以使用简单而细致的文本提示。当SAM未能做出正确的预测时,额外的点提示会有所帮助。
7.6 消融实验
方法(Approach)。我们使用单中心点提示协议对23个数据集套件进行了多次消融。回想一下,单个点可能是模糊的,而这种模糊性可能不会在每个点只包含一个掩膜的基本事实中表示。由于SAM在零发射传输设置中操作,因此SAM的顶级掩膜与数据注释指南产生的掩膜之间可能存在系统偏差。因此,我们还报告了关于人工标注的最佳掩膜(“oracle”)。
图13(左)绘制了根据数据引擎阶段的累积数据进行训练时SAM的性能。我们观察到,每个阶段都会增加mIoU。在所有三个阶段的训练中,自动掩膜的数量远远超过手动和半自动掩膜。为了解决这一问题,我们发现在训练中对手动和半自动掩膜进行10倍的过采样可以获得最佳结果。这种设置使训练变得复杂。因此,我们测试了第四种设置,该设置仅使用自动生成的掩膜。有了这些数据,SAM的性能仅略低于使用所有数据(~0.5 mIoU)。因此,默认情况下,我们仅使用自动生成的掩膜来简化训练设置。
在图13(中间图),我们观察了数据量的影响。完整的SA-1B包含11M图像,我们对其进行了均匀的亚采样,分别为1M和0.1M。在0.1万张图像中,我们观察到在所有设置下mIoU都有很大的下降。然而,对于1M个图像,约占完整数据集的10%,我们观察到的结果与使用完整数据集相当。这个数据体系仍然包括大约1亿个掩膜,对于许多用例来说可能是一个实用的设置。
最后,图13(右)显示了使用ViT-B、ViT-L和ViT-H图像编码器的结果。与ViT-B相比,ViT-H显著提高,但与ViT-L相比仅略有提高。此时,进一步的图像编码器缩放似乎没有取得丰硕成果。

图13:我们的数据引擎阶段、图像编码器缩放和训练数据缩放的消融研究。(左)每个数据引擎阶段都会改进我们的23个数据集套件,仅使用自动数据(我们的默认值)进行训练会产生与使用所有三个阶段的数据类似的结果。(中)使用~10%SA-1B和完整SA-1B训练的SAM具有可比性。默认情况下,我们使用所有11M图像进行训练,但使用1M图像是一个合理的实用设置。(右)缩放SAM的图像编码器显示出有意义但饱和的增益。然而,在某些设置中,较小的图像编码器可能是优选的。
8. 讨论
基础模型(Foundation models)。自机器学习的早期以来,预先训练的模型就已经适应了下游任务。近年来,随着对规模的日益重视,这种范式变得越来越重要,这类模型最近被(重新)称为“基础模型”:即“在大规模的广泛数据上训练并适应广泛下游任务的模型”。我们的工作与这一定义很好地相关,尽管我们注意到图像分割的基础模型本质上是有限的,因为它代表了计算机视觉的一个重要但部分的子集。我们还将我们的方法的一个方面与进行了对比,后者强调了自我监督学习在基础模型中的作用。虽然我们的模型是用自监督技术(MAE)初始化的,但其绝大多数能力来自大规模的监督训练。在数据引擎可以扩展可用注释的情况下,如我们的情况,监督训练提供了一个有效的解决方案。
组件(Compositionality)。经过预先训练的模型可以提供新的能力,甚至超出训练时的想象。一个突出的例子是CLIP如何在更大的系统中用作组件,如DALL·E。我们的目标是用SAM使这种合成变得简单。我们的目标通过要求SAM为广泛的分割提示预测有效的掩码来实现这一点。其效果是在SAM和其他组件之间创建一个可靠的接口。例如,MCC[106]可以很容易地使用SAM来分割感兴趣的对象,并实现对看不见的对象的强泛化,以便从单个RGB-D图像进行3D重建。在另一个例子中,SAM可以通过可穿戴设备检测到的注视点来提示,从而启用新的应用程序。由于SAM能够推广到以自我为中心的图像等新领域,此类系统无需额外培训即可工作。
局限性(Limitations),虽然SAM总体表现良好,但并不完美。它可能会错过精细的结构,有时会产生小的断开连接的组件的幻觉,并且不会像“放大”的计算密集型方法那样清晰地产生边界。通常,当提供许多点时,我们期望专用的交互式分割方法优于SAM。与这些方法不同,SAM是为通用性和使用广度而设计的,而不是高IoU交互式分割。此外,SAM可以实时处理提示,但当使用重型图像编码器时,SAM的总体性能不是实时的。我们对文本屏蔽任务的尝试是探索性的,并不完全稳健,尽管我们相信可以通过更多的努力来改进。虽然SAM可以执行许多任务,但尚不清楚如何设计实现语义和全景分割的简单提示。最后,还有一些特定于领域的工具,我们希望它们在各自的领域中优于SAM。
结论(Conclusion)。Segment Anything项目试图将图像分割提升到基础模型时代。我们的主要贡献是一项新任务(可提示分割)、模型(SAM)和数据集(SA-1B),使这一飞跃成为可能。SAM是否达到了基础模型的地位,还有待于它在社区中的使用方式,但无论我们对这项工作的前景如何,超过1B个掩膜的发布和我们可推广的细分模型都将有助于为未来铺平道路。