参数量的计算(以resnet50为例,bn层的参数
目录
-
- 模型参数量的计算一
- 模型参数量的计算二
- resnet50的网络结构:
- pytorch中BN层的weight和bias
模型参数量的计算一
print("resnet50 have {} paramerters in total".format(sum(x.numel() for x in resnet50.parameters())))
模型参数量的计算二
num_params = 0
for param in netG.parameters():
num_params += param.numel()
print(num_params / 1e6)
resnet50的网络结构:
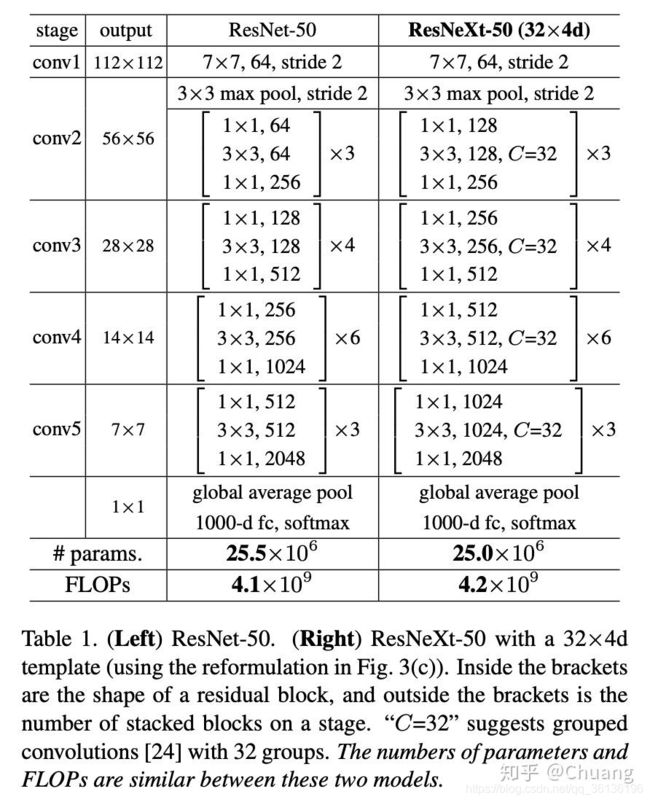
OrderedDict([('conv1', Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)), ('bn1', BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)), ('relu', ReLU(inplace=True)), ('maxpool', MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)), ('layer1', Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)), ('layer2', Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
bn层有两个可学习的参数gamma,beta,在pytorch中是weight和bias,有另外两个参数running_mean和running_var是计算得到的,并不是可学习的参数
conv1.weight 9408 #3*64*7*7=9408
bn1.weight 64 # gamma参数,是输出维度64
bn1.bias 64 # beta参数,是输出维度64
layer1.0.conv1.weight 4096
layer1.0.bn1.weight 64
layer1.0.bn1.bias 64
layer1.0.conv2.weight 36864
layer1.0.bn2.weight 64
layer1.0.bn2.bias 64
layer1.0.conv3.weight 16384
layer1.0.bn3.weight 256
layer1.0.bn3.bias 256
layer1.0.downsample.0.weight 16384 # 下采样实现是Conv2d+bn层
layer1.0.downsample.1.weight 256
layer1.0.downsample.1.bias 256
layer1.1.conv1.weight 16384
layer1.1.bn1.weight 64
layer1.1.bn1.bias 64
layer1.1.conv2.weight 36864
layer1.1.bn2.weight 64
layer1.1.bn2.bias 64
layer1.1.conv3.weight 16384
layer1.1.bn3.weight 256
layer1.1.bn3.bias 256
layer1.2.conv1.weight 16384
layer1.2.bn1.weight 64
layer1.2.bn1.bias 64
layer1.2.conv2.weight 36864
layer1.2.bn2.weight 64
layer1.2.bn2.bias 64
layer1.2.conv3.weight 16384
layer1.2.bn3.weight 256
layer1.2.bn3.bias 256
layer2.0.conv1.weight 32768
layer2.0.bn1.weight 128
layer2.0.bn1.bias 128
layer2.0.conv2.weight 147456
layer2.0.bn2.weight 128
layer2.0.bn2.bias 128
layer2.0.conv3.weight 65536
layer2.0.bn3.weight 512
layer2.0.bn3.bias 512
layer2.0.downsample.0.weight 131072
layer2.0.downsample.1.weight 512
layer2.0.downsample.1.bias 512
layer2.1.conv1.weight 65536
layer2.1.bn1.weight 128
layer2.1.bn1.bias 128
layer2.1.conv2.weight 147456
layer2.1.bn2.weight 128
layer2.1.bn2.bias 128
layer2.1.conv3.weight 65536
layer2.1.bn3.weight 512
layer2.1.bn3.bias 512
layer2.2.conv1.weight 65536
layer2.2.bn1.weight 128
layer2.2.bn1.bias 128
layer2.2.conv2.weight 147456
layer2.2.bn2.weight 128
layer2.2.bn2.bias 128
layer2.2.conv3.weight 65536
layer2.2.bn3.weight 512
layer2.2.bn3.bias 512
layer2.3.conv1.weight 65536
layer2.3.bn1.weight 128
layer2.3.bn1.bias 128
layer2.3.conv2.weight 147456
layer2.3.bn2.weight 128
layer2.3.bn2.bias 128
layer2.3.conv3.weight 65536
layer2.3.bn3.weight 512
layer2.3.bn3.bias 512
layer3.0.conv1.weight 131072
layer3.0.bn1.weight 256
layer3.0.bn1.bias 256
layer3.0.conv2.weight 589824
layer3.0.bn2.weight 256
layer3.0.bn2.bias 256
layer3.0.conv3.weight 262144
layer3.0.bn3.weight 1024
layer3.0.bn3.bias 1024
layer3.0.downsample.0.weight 524288
layer3.0.downsample.1.weight 1024
layer3.0.downsample.1.bias 1024
layer3.1.conv1.weight 262144
layer3.1.bn1.weight 256
layer3.1.bn1.bias 256
layer3.1.conv2.weight 589824
layer3.1.bn2.weight 256
layer3.1.bn2.bias 256
layer3.1.conv3.weight 262144
layer3.1.bn3.weight 1024
layer3.1.bn3.bias 1024
layer3.2.conv1.weight 262144
layer3.2.bn1.weight 256
layer3.2.bn1.bias 256
layer3.2.conv2.weight 589824
layer3.2.bn2.weight 256
layer3.2.bn2.bias 256
layer3.2.conv3.weight 262144
layer3.2.bn3.weight 1024
layer3.2.bn3.bias 1024
layer3.3.conv1.weight 262144
layer3.3.bn1.weight 256
layer3.3.bn1.bias 256
layer3.3.conv2.weight 589824
layer3.3.bn2.weight 256
layer3.3.bn2.bias 256
layer3.3.conv3.weight 262144
layer3.3.bn3.weight 1024
layer3.3.bn3.bias 1024
layer3.4.conv1.weight 262144
layer3.4.bn1.weight 256
layer3.4.bn1.bias 256
layer3.4.conv2.weight 589824
layer3.4.bn2.weight 256
layer3.4.bn2.bias 256
layer3.4.conv3.weight 262144
layer3.4.bn3.weight 1024
layer3.4.bn3.bias 1024
layer3.5.conv1.weight 262144
layer3.5.bn1.weight 256
layer3.5.bn1.bias 256
layer3.5.conv2.weight 589824
layer3.5.bn2.weight 256
layer3.5.bn2.bias 256
layer3.5.conv3.weight 262144
layer3.5.bn3.weight 1024
layer3.5.bn3.bias 1024
layer4.0.conv1.weight 524288
layer4.0.bn1.weight 512
layer4.0.bn1.bias 512
layer4.0.conv2.weight 2359296
layer4.0.bn2.weight 512
layer4.0.bn2.bias 512
layer4.0.conv3.weight 1048576
layer4.0.bn3.weight 2048
layer4.0.bn3.bias 2048
layer4.0.downsample.0.weight 2097152
layer4.0.downsample.1.weight 2048
layer4.0.downsample.1.bias 2048
layer4.1.conv1.weight 1048576
layer4.1.bn1.weight 512
layer4.1.bn1.bias 512
layer4.1.conv2.weight 2359296
layer4.1.bn2.weight 512
layer4.1.bn2.bias 512
layer4.1.conv3.weight 1048576
layer4.1.bn3.weight 2048
layer4.1.bn3.bias 2048
layer4.2.conv1.weight 1048576
layer4.2.bn1.weight 512
layer4.2.bn1.bias 512
layer4.2.conv2.weight 2359296
layer4.2.bn2.weight 512
layer4.2.bn2.bias 512
layer4.2.conv3.weight 1048576
layer4.2.bn3.weight 2048
layer4.2.bn3.bias 2048
fc.weight 2048000
fc.bias 1000
25.557032
pytorch中BN层的weight和bias
众所周知,BN层的输出Y与输入X之间的关系是:
Y = g a m m a ∗ X − r u n n i n g _ m e a n s q r t ( r u n n i n g _ v a r + e p s ) + b e t a Y = gamma * \frac{X - running\_mean}{sqrt(running\_var + eps) } + beta Y=gamma∗sqrt(running_var+eps)X−running_mean+beta此不赘言。其中gamma、beta为可学习参数(在pytorch中分别改叫weight和bias),训练时通过反向传播更新;而running_mean、running_var则是在前向时先由X计算出mean和var,再由mean和var以动量momentum来更新running_mean和running_var。所以在训练阶段,running_mean和running_var在每次前向时更新一次;在测试阶段,则通过net.eval()固定该BN层的running_mean和running_var,此时这两个值即为训练阶段最后一次前向时确定的值,并在整个测试阶段保持不变。
=========================
running_mean和running_var是测试时根据训练阶段得到的(也就是running_mean,running_var参数是用于验证,测试阶段的