1 .数据模型
Guido 对语言设计美学的理解令人惊叹.
我认识不少优秀的语言设计师, 他们可以构建出理论上看起来漂亮的语言, 但没人会使用.
Guido知道如何在理论上做出一定妥协, 设计出来的语言让使用者如沐春风, 这真是不可多得.
--Jim Hugunin
Jython作者, AspectJ作者之一, .NET DLR架构师①
(注1: 摘自'Story of Jython', Jython Esshon (Samuele Pedroni 和 NoelRappin著)一书的序.)
Python的质量保证得益于一致性.
使用Python一段时间之后, 便可以根据自己掌握的知识, 正确的猜出新功能的作用.
*-------------------------------------------解读: 一致性---------------------------------------*
在Python编程中, 一致性是指代码的规范性和统一性.
Python有一个称为'Python Enhancement Proposals'(PEP)的规范文档, 其中定义了新功能的规范和实现细节.
这些规范被广泛遵循, 确保了新功能的一致性和易用性.
由于Python社区高度重视一致性, 所以新功能通常被精心设计和测试,
以确保它们符合Python的整体设计原则, 并与现有功能保持一致.
PEP文档地址: https://github.com/python/peps/tree/main
当你使用Python一段时间并掌握了一些核心概念和常用功能后, 你会逐渐熟悉Python的设计模式和惯用法.
这种熟悉使你能够更容易地理解和推测新功能的作用.
Python的一致性设计使得许多功能在语言和标准库中都有相似的模式和命名约定,
因此你可以利用这些知识来推断新功能的用途和行为.
*---------------------------------------------------------------------------------------------*
然而, 如果你在接触Python之前有其他面向对象语言的经验, 就会觉得很奇怪:
为什么获取容器大小不使用collection.len(), 而是使用len(collection)?
*--------------------------------------------解读---------------------------------------------*
在Python中, 获取容器大小使用len(collection)而不是collection.len()的原因是为了保持一致性和简洁性.
Python采用了一种称为'鸭子类型'(duck typing)的策略, 即关注对象的行为而不是类型.
这种策略使得Python更加灵活, 并且可以让不同类型的对象在相同的语法下执行相似的操作.
len(collection)的语法符合Python的一般原则: 简洁明了, 易于理解.
它使得获取容器大小的方式在各种容器类型(如列表, 元组, 字典等)之间保持一致, 不需要记忆和适应不同的方法名.
*---------------------------------------------------------------------------------------------*
这一点表面上看确实奇怪, 而且只是众多奇怪行为的冰山一角,
不过直到背后的原因之后, 你会发现这才真正符合'Python 风格'.
一切的一切都埋藏在Python数据模型中.
我们平常自己创建对象时就要使用这个API, 确保使用最地道的语言功能.
可以把Python列表视为一个框架, 而'数据模型'就是对框架的描述,
规范语言自身各个组成部分的接口, 确立序列, 函数, 迭代器, 协程, 类, 上下文管理器等部分的行为.
*--------------------------------------------解读---------------------------------------------*
数据模型: 是一种规范, 定义了如何在程序中表示和处理数据.
API(Application Programming Interface): 是一组定义了要在软件中实现的程序接口的规范.
Python数据模型定义了对象在特定操作下的行为和语义, 以及与内置函数, 操作符和语言特性的交互方式.
特殊方法与数据模型的关系可以理解为:
数据模型定义了一组操作和行为的规则和约定, 描述了对象如何与内置运算符, 函数和语言特性进行交互.
特殊方法是实现数据模型的具体手段, 通过实现特殊方法, 您可以为自定义类定义与数据模型相对应的行为和操作.
特殊方法的命名和功能与数据模型中定义的操作和行为相对应.
例如, __add__()方法用于定义对象的加法操作, __getitem__()方法用于支持索引访问操作等.
遵循Python数据模型提供的API,
你可以确保你的自定义对象与Python内置对象一样地道和一致(自定义类提供与内置类型相似的行为和功能).
还能使你的对象能够无缝地与Python标准库和第三方库进行交互.
*---------------------------------------------------------------------------------------------*
使用框架要花费大量时间编写方法, 交给框架调用.
利用Python数据模型构建新类也是如此.
Python解释器调用特殊方法来执行基本对象操作, 通常由特殊句法触发.
特殊方法的名称前后两端都有双下划线.
例如, 在obj[key]句法背后提供支持的是特殊方法__getitem__.
为了求解my_collection[key], Python解释器要调用my_collection.__getitem__(key).
如果想让对象支持一下基本的语句结构并与其交互, 就需要实现特殊方法:
• 容器;
• 属性存取;
• 迭代(使用async for 的异步迭代);
• 运算符重载;
• 函数和方法调用;
• 字符串表示形式和格式化;
• 对象创建和析构;
• 使用with或async with语句管理上下文;
**-----------------------------------------魔法方法和双下划线----------------------------------**
特殊方法用语叫作'魔法方法(magic method)'.
需要一个特殊方法(例如__getitem__)说出来时, 因该怎么表达呢?
我一般说:'dunder-getitem'. 这是跟著名作家和教师Steve Holden学的.
'dunder'表示'前后双下划线'. 因此, 特殊方法也叫'双下划线方法'.
<<Python 语言参考手册>>中的第2章'词法分析'警告道:
'任何时候, 若不遵守文档明确说明的方式使用__*__名称, 一切后果自负.'
Python 语言参考手册: http://study.yali.edu.cn/pythonhelp/reference/index.html
**-------------------------------------------------------------------------------------------**
1.1 本章新增内容
相较于第1版本, 本章内容改动较少, 毕竟Python数据模型相当稳定.
本章只要改动如下:
• 1.4节中的表格增加了支持异步编程和其他功能的特殊方法.
• 新增1.3.4节, 在图1-2中给出容器相关的特殊方法,
包括Python3.6引入的collections.abs.Collection抽象基类.
另外, 本章和第2版其他章节统一采用Python3.6引入的f字符串句法.
这种句法解读性更好, 而且通常比str.format()方法和%运算符等旧的字符串格式表示法更方便.
*---------------------------------------------------------------------------------------------*
如果my_fmt的定义与格式操作在代码的不同位置, 那就可以继续使用my_fmt.format().
比如说, my_fmt的内容占据多行, 更适合定义为常量. 或者必须从配着文件或数据库中读取.
这种情况确实存在, 但很少见.
*---------------------------------------------------------------------------------------------*
1.2 一摞Python风格的纸牌
示例1-1虽然简单, 却展示了实现__getitem__和__len__两个特殊方法之后得到的强大功能.
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
首先用collections.namedtuple构建一个简单的类, 表示单张纸牌.
使用namedtuple构建只有属性而没有自定义方法的类对象, 例如, 数据库中的一条记录.
这个示例中使用这个类(Card类)表示一摞牌中的各张纸牌, 如以下控制台会话所示.
>>> beer_card = Card('7', 'diamonds')
>>> beer_card
Card(rand='7', suit='diamonds')
但是, 这个示例的重点是简短精炼的FrenchDeck类.
首先, 与标准的Python容器一样, 一摞牌响应len()函数, 返回一摞牌有多少张.
>>> deck = FrenchDeck()
>>> len(deck)
52
得益于__getitem__方法, 我们可以轻松地从这摞牌中抽取某一张, 比如说第一张或最后一张.
>>> deck[0]
Card(rank='2', suit='spades')
>>> deck[-1]
Card(rank='A', suit='hearts')
如果想随机选一张牌, 需要定义一个方法吗?
不需要, 因为Python已经提供了从序列中随机获取一项的函数, 即random.choice.
我们可以在一摞牌上使用这个函数.
>>> from random import choice
>>> choice(deck)
Card(rank='3', suit='hearts')
>>> choice(deck)
Card(rank='k', suit='spades')
>>> choice(deck)
Card(rank='2', suit='clubs')
import collections
from random import choice
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
beer_card = Card('7', 'diamonds')
print(beer_card)
deck = FrenchDeck()
print(len(deck))
print(deck[0])
print(deck[-1])
print(choice(deck))
print(choice(deck))
print(choice(deck))
可以看到, 通过特殊方法利用Python数据模型, 这样做有两个优点.
• 类的用户不需要记住标准操作的方法名称('怎样获取项数? 使用.size(), .length(), 还是其他方法?')
• 可以充分利用Python标准库, 例如random.chioce函数, 无须重新发明轮子. 好戏还在后头.
由于__getitem__方法把操作委托给self._cards的[]运算符, 一摞牌自动支持切片(slicing).
(ps: self._cards是内置的list列表对象, 支持一切列表的操作.)
下面展示如何从一摞新牌中抽取最上面三张, 再从索引12位开始, (连续)跳过13张牌, 只抽4张A.
>>> deck[:3]
[Card(rand='2', suit='spades'), Card(rand='3', suit='spades'), Card(rand='4', suit='spades')]
>>> deck[12::13]
[Card(rand='A', suit='spades'), Card(rand='A', suit='diamonds'),
Card(rand='A', suit='clubs'), Card(rand='A', suit='hearts')]
实现特殊方法__getitem__之后, 这摞纸牌还可以迭代.
(ps: 文章末尾简单介绍doctest模式的使用..., 内容很少, 建议看完后再往下阅读...)
>>> for card in deck:
... print(card)
Card(rand='2', suit='spedes')
Card(rand='3', suit='spedes')
Card(rand='4', suit='spedes')
...
另外, 也可以反向迭代这摞纸牌.
>>> for card in reversed(deck):
... print(card)
Card(rand='A', suit='hearts')
Card(rand='K', suit='hearts')
Card(rand='Q', suit='hearts')
...
class MyObject:
def __init__(self):
self.data = [1, 2, 3, 4, 5]
def __getitem__(self, position):
print(f'position的值{position}')
return self.data[position]
obj = MyObject()
for i in obj:
print(i)
*--------------------------------------doctest中的省略号--------------------------------------*
本书中的Python控制台会话内容从doctest中摘录, 力求准确无误. 如果输出太长, 则内容有所节略.
节略的部分使用省略号(...)标记, 例如, 前一段代码中的最后一行.
这种情况下, 为了让doctest通过, 我加上了# doctest: +ELLIPSIS.
在交互控制台中实验这些实例时, 可以把doctest注释全部去掉.
doctest是Python中的一个模块, 用于测试代码示例是否与文档字符串中的预期输出匹配.
它允许将代码示例作为文档的一部分, 并自动运行这些示例以确保其正确性.
在doctest中, +ELLIPSIS是一个特殊的指令选项, 用于允许一些输出被省略.
*--------------------------------------------------------------------------------------------*
迭代往往是隐式的.
如果一个容器没有实现__contains__方法, 那么in运算符就会做一次顺序扫描.
本例就是这样, FrenchDeck类支持in运算发, 因为该类可迭代(FrenchDeck实现了__getitem__, 所有可迭代.).
class MyObject:
def __init__(self):
self.data = [1, 2, 3, 4, 5]
def __getitem__(self, position):
return self.data[position]
obj = MyObject()
print(1 in obj)
>>> Card('Q', 'hearts') in deck
True
>>> Card('7', 'beases') in deck
False
那么排序呢? 按照常规, 牌面大小按点数(A最大), 以及黑桃(最大), 红心, 方块, 梅花(最小)的顺序排列.
下面按照这个规则定义扑克牌排序函数, 梅花2返回0, 黑桃A返回51.
suit_value = dict(spades=3, hearts=2, diamonds=1, clubs=0)
def spades_high(card):
rank_value = FrenchDeck.ranks.index(card.rank)
return rank_value * len(suit_values) + suit_value[card.suit]
定义好spades_high函数后, 现在按照牌面大小升序列出一副牌.
>>> for card in sorted(deck, key=spades_high):
... print(card)
...
Card(rank='2', suit='clubs')
Card(rank='2', suit='diaminds')
Card(rank='2', suit='hearts')
... (46 cards omitted)
Card(rank='A', suit='diaminds')
Card(rank='A', suit='hearts')
Card(rank='A', suit='spades')
虽然FrenchDeck类隐式继承object类, 但是前者的多数功能不是继承而来的, 而是源自数据模型和组合模式.
通过前面使用random.choice, reversed和sorted的示例可以看出,
实现__len__和__getitem__两个特殊方法后, FrenchDeck的行为就像标准的Python序列一样,
受益于语言核心特性(例如, 迭代和切片)和标准库.
__len__和__getitem__的实现利用组合模式, 把所有工作委托给一个list对象, 即self._cards.
*------------------------------------------ps-----------------------------------------------*
在Python中, 显式调用(Explicit Invocation)和隐式调用(Implicit Invocation)是两种不同的调用方式.
显式调用: 是指在程序中显式地调用一个函数或方法, 以执行特定的操作.
隐式调用: 是指系统自动调用某些函数或方法, 而不需要显式地在程序中调用它们.
这些函数或方法通常是在特定的事件发生时自动调用的.
*---------------------------------------------------------------------------------------------*
*--------------------------------------------如何洗牌-----------------------------------------*
按照目前的设计, FrenchDeck对象不能洗牌, 因此它是不可变的:
纸牌自身及其位置不能变化, 除非违背封装原则, 直接处理_cards属性.
第13章将添加只有一行代码的__setitem__方法, 解决这个问题.
(ps: 现在不能通过random.choice, reversed和sorted操作FrenchDeck对象, 需要提供__setitem__方法才行.)
*---------------------------------------------------------------------------------------------*
1.3 特殊方法是如何使用的
首先明确一点, 特殊方法供Python解释器调用, 而不是你自己.
也就是说, 没有my_object.__len__()这种写法, 正确的写法是len(my_object).
如果my_object是用户自定义的类的实例, Python将调用你实现的__len__方法.
(ps: len(my_object) 会调用自定义类的__len__方法. )
然而, 处理内置类型时, 例如, list, str, bytearray, NumPy数组等拓展, Python解释器会抄个近路.
Python中可变长度容器的底层C语言实现中有一个结构体, ②名为PyVarObject.
(注2: C语言结构体是一种使用具名字段的记录类型.)
在这个结构体中, ob_size字段保存着容器中的项数.
如果my_object是某个内置类型的实例, 则len(my_object)直接读取ob_size字段的值, 这比调用方法快很多.
很多时候, 特殊方法是隐式调用的.
例如, for i in x: 语句其实在背后调用iter(x),
接着又调用x.__iter__() (前提是有该方法)或x.__getitem__().
在FrenchDeck示例中, 调用者的是后者.
我们在编写代码时一般不直接调用特殊方法, 除非涉及大量元编程,
即使如此, 大部分时间也是实现特殊方法, 很少显示调用.
唯一例外的是__init__方法, 为自定义的类实现__init__方法时经常直接调用它调取超类的初始化方法.
如果需要调用特殊方法, 则最好调用相应的内置函数例如len, iter, str等.
这些内置函数不仅调用对应的特殊方法, 通常还提供额外服务, 而且对于内置类型来说, 速度比调用方法更快.
17.3节有一个示例. (ps: 很多内置方法有对应的内置函数去调用, 部分函数中还提供了优化方法..., 如上例的len.)
接下来几节会说明特殊方法最重要的用途:
• 模拟数值类型;
• 对象的字符串表示形式;
• 对象的布尔值;
• 实现容器;
1.3.1 模拟数值类型
有几个特殊方法可以让用户对象响应+(号)等运算法.
第16章对此有详细的探讨, 这个只是借此再举一个简单的例子, 说明特殊方法的用途.
接下来将实现一个二维向量类, 即数学和物理中使用的欧几里德向量(见图1-1).
*--------------------------------------------------------------------------------------------*
内置的complex类型可以用于表示二维向量, 不过我们实现的类经过拓展可以表示n维向量, 详见17章.
*--------------------------------------------------------------------------------------------*
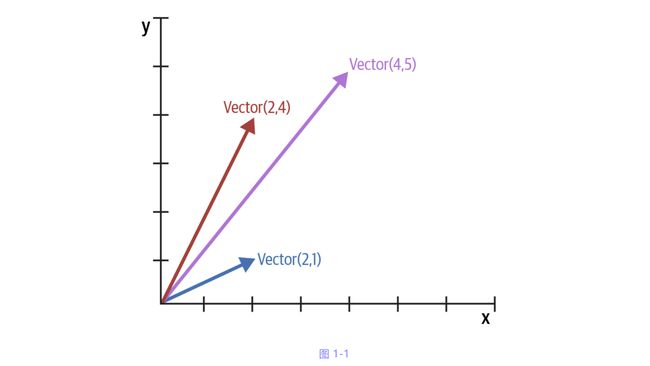
图1-1: 二维向量加法图示: Vector(2, 4) + Vector(2, 1) = Vector(4, 5)
为了给这个类设计API, 先写出模拟的控制台会话, 作为doctest.
以下代码片段测试图1-1中的向法加量.
>>> v1 = Vector(2, 4)
>>> v2 = Vector(2, 1)
>>> v1 + v2
Vector(4, 5)
注意, +运算符的结果是一个新Vector对象, 在控制台中以友好的格式显示.
内置函数abs返回整数和浮点数的绝对值, 以及复数的模.
为了保证一致性, 我们的API也使用abs函数计算向量的模.
*-----------------------------------------------解读------------------------------------------*
内置的abs函数在处理数值类型时通常用于计算绝对值或模的值.
因此, 为了与内置类型保持一致, 我们可以在Vector类中使用abs函数计算向量的模.
*---------------------------------------------------------------------------------------------*
>>> v = Vector(3, 4)
>>> abs(v)
5.0
还可以实现*运算符, 计算向量的标量积(即一个向量乘以一个数, 得到一个方向相同, 模为一定倍数的新向量).
>>> v * 3
Vector(9 , 12)
>>> abs(v * 3)
15.0
示例1-2使用__repr__, __abs__, __add__和__mul__等特殊方法为Vector类实现这个这几种运算.
"""
vector2d.py: 一个简单的类, 演示一些特殊方法
只是演示, 一些问题作为简化处理. 缺少错误处理, 尤其是__add__和__mul__方法.
本书后文还会扩充这个示例.
加法::
>>> v1 = Vector(2, 4)
>>> v2 = Vector(2, 1)
>>> v1 + v2
Vector(4, 5)
绝对值::
>>> v = Vector(3, 4)
>>> abs(v)
5.0
标量积::
>>> v * 3
Vector(9 , 12)
>>> abs(v * 3)
15.0
"""
import math
class Vector:
def __init__(self, x=0, y=1):
self.x = x
self.y = y
def __repr__(self):
return f'Vector({self.x!r}, {self.y!r})'
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x, y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
除了我们熟悉的__init__方法, 这个类还实现了另外5个特殊方法.
注意, 这些方法在类内部, 或者在前面的doctest中都没有直接调用.
正如前文所说, 多数特殊方法最常被Python解释器调用.
示例1-2实现了+和*两个运算符, 展示了__add__和__mul__方法的基本用法.
这个两个方法创建并返回一个新Vector实例.
没有修改运算对象, 只是读取self或other.
这是中缀运算符的预期行为, 即创建对象, 不修改运行对象. 这一点会在第16章详谈.
***----------------------------------------------------------------------------------------***
示例1-2中实现, 一个Vector对象可以乘以一个整数, 但是一个数不能乘以一个Vector对象,
这违背了标量积的交换律.
这个问题在第16章会使用特殊方法__rmul__解决.
意思就是:
__mul__方法可以让对象乘以一个整数如: Vector * 2
__rmul__方法可以让整数乘以一个对象如: 2 * Vector
***----------------------------------------------------------------------------------------***
接下来的几章讨论Vector类的其他特殊方法.
1.3.2 字符串表示形式
特殊方法__repr__供内置方法repr调用, 获取对象的字符串表示形式.
如未定义__repr__方法, Verctor实例在Python控制台中显示为<Vector object at 0x10e100070>形式.
交互式控制台和调试器在表达式求值结果上调用repr函数,
处理方法与使用%运算符处理经典格式化方中中的%r占位符,
以及使用str.format方法处理新字符串格式化句法中!r转换字段一样.
注意, Vector类__repr__方法中的f字符串使用!r以标准的表示形式显示属性.
这样比较好, 因为Vector(1, 2)和Vector('1', '2')之间是有区别的,
后者在这个示例中不可用, 因为构造函数接受的参数是数值而不是字符串.
__repr__方法返回的字符串应当没有歧义, 如果可能, 做好与源码保持一致, 方便重新创建所表示的对象.
鉴于此, 我们才以类似构造函数的形式(例如, Vector(3, 4))返回Vector对象的字符串表示形式.
与此形成对照的是, __str__方法由内置函数str()调用, 在背后供print函数使用, 返回对终端用户友好的字符串.
有时, __repr__方法返回的字符串足够友好, 无须再定义__str__方法,
因为继承自object类的实现最终会调用__repr__方法.
本书中有几个示例定义类__str__方法, 例如示例5-2.
如果你属性的编程语言使用toString方法, 那么你可能习惯实现__str__方法,
而不是__repr__方法, 在Python中, 如果必须二选一的话, 请选择__repr__方法?
Stack Overflow网站中有一个问题, 'What is the difference between __str__ and __repr__?',
Python专家Alex Martelli和Martijn Pieters对此做出了详尽解答.
*----------------------------------------------解读--------------------------------------------*
在使用Python的print()函数打印字符串时, 输出的字符串是不包含引号的.
这是因为引号只是用来标示字符串的开始和结束, 并不是字符串本身的一部分.
在Python的交互模式下, 直接输入变量名输出变量的时候, 字符串会保留引号并输出整个字符串.
这是因为Python的交互模式在输出变量时, 会将变量值转换为字符串格式输出.
对于字符串变量, 其值本身已经是一个字符串, 因此在转换为字符串的时候会包含原始的引号.
repr()函数可以将一个对象转换为字符串表示形式.
对于字符串, repr()函数会返回它的带引号表示形式,
其中包含了字符串的内容和引号, 以便于将其表示为代码字面量.
例如, 对于一个包含字符串Hello World的变量s,
repr()函数会将其转换为带引号的字符串: 'Hello World'.
这是因为repr()函数的作用是生成给定对象的表示形式,
而字符串在代码中通常是需要加引号的, 因此返回的字符串中包含了引号.
需要注意的是, repr()函数生成的字符串可能并不是完全等同于原始的字符串.
在某些情况下, repr()函数生成的字符串包含了转义符号.
例如, 如果字符串中包含了引号, 则repr()函数会将其转义为\'.
但是这不影响字符串的内容和语义, 只是为了表示字符串的字面量形式而引入的.
f''字符串通常被称为f-string(格式化字符串), 其中f代表了format(格式化)操作,
{!r}相当于是format语法的%r, 表示的用repr()处理字符串对象.
>>> s1 = 'Hello World!'
>>> s1
'Hello World!'
>>> print(s1, type(s1))
Hello World! <class 'str'>
>>> num = repr(1)
>>> print(num, type(num))
1 <class 'str'>
>>> s1 = 'Hello World!'
>>> s2 = repr(s1)
>>> print(s2, type(s2))
'Hello World!' <class 'str'>
>>> s3 = "I'm"
>>> s4 = repr(s3)
>>> print(s4, type(s4))
"I'm" <class 'str'>
'有歧义的字符串': 是指在不同的上下文中, 同一个字符串可以被解释成不同的含义.
这通常会导致误解和混淆, 因为不同的人可能会对同一个字符串有不同的理解.
例如, 假设一个程序员写了一个类的__repr__方法, 返回的字符串表示类的一些属性:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return f'Person("{self.name}", {self.age})'
obj = Person('Oscar "The Grouch" Grouchkowski', 42)
print(obj)
在这个例子中, 如果一个Person对象的name属性包含双引号, 则__repr__方法返回的字符串可能会产生歧义.
例如, 如果一个Person对象的name属性为'Oscar "The Grouch" Grouchkowski',
则__repr__方法返回的字符串将是: Person("Oscar "The Grouch" Grouchkowski", 42)
这个字符串在Python中是无法正确解析的, 因为字符串中的双引号没有被转义.
这就产生了歧义, 因为这个字符串可能被解释成Person对象的name属性是'Oscar ',
其余部分被视为无效的Python代码.
因此, __repr__方法应当返回一个没有歧义的字符串, 以避免这样的问题.
在上面的例子中, 可以使用单引号来表示字符串, 或者将双引号转义, 以确保字符串可以被正确解析.
在Python中, __repr__方法返回的字符串中使用!r语法会调用对象的__repr__方法自身.
这是因为!r语法实际上是在内部调用对象的__repr__方法, 以获取对象的字符串表示形式,
并在格式化字符串中使用repr()函数将该字符串转义, 以确保它可以被正确解析.
我们在__repr__方法中使用!r语法来调用self.name属性的__repr__方法, 并将其插入到字符串中:
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return f'Person("{self.name!r}", {self.age!r})'
obj = Person('Oscar "The Grouch" Grouchkowski', 42)
print(obj)
使用repr处理的字符串, 内部的字符串会使用反斜杠\转义.
'Oscar "The Grouch" Grouchkowski' 被处理成 "\'Oscar \"The Grouch\" Grouchkowski\'" .
我们在__repr__方法中使用了!r语法, 它会调用self.name属性的__repr__方法.
由于self.name是一个字符串, 所以它会调用内置的str类的__repr__方法,
返回一个包含字符串本身的表示字符串, 这样就不会递归调用__repr__方法.
因此, 在__repr__方法内使用!r语法是安全的, 它不会导致无限递归调用__repr__方法.
"与源码保持一致": 指的是返回的字符串应该与类的构造函数的调用方式相同,
以便于使用这个字符串来重新创建对象.
具体来说, 如果类的构造函数需要一个或多个参数来创建对象,
则在定义类的__repr__方法时应该返回一个字符串表示形式,
字符串表示形式应该与构造函数调用时提供的参数相同.
这种做法有助于保持代码的一致性, 使得对象的字符串表示形式更容易理解和维护.
假设我们有一个名为v1的Vector对象, 它的坐标为(3, 4).
我们可以使用以下代码来创建一个新的Vector对象, 其属性与v1相同:
v2 = eval(repr(v1))
在这个例子中, 我们使用repr方法获取v1的字符串表示形式,
并使用eval函数将该字符串转换为一个Python表达式, 从而创建一个新的Vector对象v2, 其属性与v1相同.
需要注意的是, 这种做法只适用于可以安全地使用eval函数的情况.
在某些情况下, repr方法返回的字符串可能包含危险的代码, 因此不建议在这些情况下使用eval函数.
__str__和__repr__都是Python类中预定义的特殊方法, 用于控制类的字符串表示形式.
如果一个类没有定义__str__方法, 则Python解释器会输出__repr__方法返回的字符串.
如果一个类既没有定义__str__方法又没有定义__repr__方法, 则默认返回对象的内存地址.
__str__方法是用于返回对象的'非正式'或'友好'字符串表示形式.
也就是通常用于打印和可读性较高的字符串表示,
而__repr__方法则返回的是对象的'正式'字符串表示形式, 通常用于调试和开发.
具体来说, __str__方法返回的是一个更加友好和可读性高的字符串.
通常这个字符串不需要包含对象的所有信息, 而应该是对对象的一个简单描述.
而__repr__方法返回的字符串应该是一个可以识别出对象的字符串表示形式,
可以在交互模式下直接执行, 重新创建该对象.
例如, 对于一个字符串对象, __repr__方法应该返回包含引号的字符串,
而__str__方法则返回该字符串的内容本身.
*---------------------------------------------------------------------------------------------*
1.3.3 自定义类型的布尔值
Python有一个bool类型, 在需要布尔值的地方处理对象,
例如, if或while语句的条件表达式, 或者and, or和not的运算对象.
为了确定x表示的值为真或假, Python调用bool(x), 返回True或False.
默认情况下, 用户定义的实例都是真值, 除非实现了__bool__或__len__方法.
简说, bool(x)调用x.__bool__(), 以后者返回的结果为准.
如果没有实现__bool__方法, 则Python尝试调用x.__len__();
如果该方法返回值零值, 则bool函数返回Fasle, 否则返回True.
上例, 我们实现的__bool__方法没用到什么高深的理论, 如果向量的模为0, 则返回False, 否则返回True.
我们使用bool(abs(self))把向量的模转换为布尔值, 因为__bool__方法必须返回一个布尔值.
在__bool__方法外部, 很少需要显示调用bool(), 因为任何对象都可以在布尔值上下文中使用.
注意: 这个__bool__特殊方法遵守Python标准库文档中'Built-in Types'一章中定义的真值测试规则.
"布尔值上下文": 指的是在条件语句, 循环语句, 逻辑运算等场景中使用布尔值的上下文环境.
**------------------------------------------------------------------------------------------**
Verctor.__bool__方法也可以像下面这样简单定义.
def __bool__(self):
return bool(self.x or self.y)
这样定义虽然不易读懂, 但是不用经过abs和__abs__处理, 也无须计算平方和平方根.
使用bool显示转换是有必要的, 因为__bool__方法必须返回一个布尔值.
or返回两个操作数的其中一个, 而且原封不动:
如果x是真值, 则 x or y 的求值结果为x, 否则为y, 无论y是真是假.
**------------------------------------------------------------------------------------------**
1.3.4 容器API
Python语言中基本容器类型的接口如图1-2所示.
图中所有的类都是抽象基类.
抽象基类和coollections.abs模块将在第13章讨论.
本章简要说明Python中最重要的容器接口, 总览容器类型对特殊方法的使用情况.
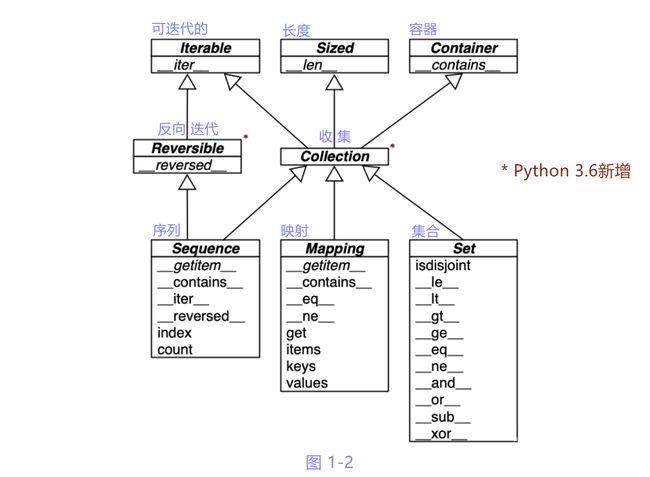
图1-2:基本容器类型UML类图.
以斜体显示的方法名称表示抽象方法, 必须由具体子类(例如list和dict)实现.
其他方法有具体实现, 子类可以直接继承.
*--------------------------------继承这些基类, 子类必须实现的方法:-------------------------------*
继承Iterable必须实现__iter__方法.
继承Sized必须实现__len__方法.
继承Contaion必须实现__contation__方法.
继承Collection必须实现__iter__, __len__, __contation__方法.
继承Reversible必须实现__iter__, __reversed__方法.
(注意下面的基类中, 自己也也显示了部分方法.)
继承Sequence, 必须实现__getitem__, __len__方法.
继承Mapping, 必须实现__getitem__, __iter__, __len__方法.
继承Set, 必须实现__contains__, __iter__, __len__方法.
*---------------------------------------------------------------------------------------------*
顶部3个抽象基类均只有一个特殊方法.
抽象基类Collection(Python3.6 新增)统一了这三个基本接口, 每一个容器类型均应实现如下事项:
• Iterable: 要支持for, 拆包和其他迭代方式;
• Sized: 要支持内置函数len;
• Contaion: 要支持in运算符;
Python不强制要求具体类继承这些抽象基类中的任何一个.
只要实现了__len__方法, 就说明那个类满足Sized接口.
Collection有3个十分重要的专用接口:
• Sequence: 规范list和str等内置类型的接口;
• Mapping: 被dict, collections.defaultdict等实现;
• Set: 是set和frozenset两个内置类型的接口.
只有Sequence实现了Reversible, 因为序列要支持以任意顺序排序内容, 而Mapping和set不需要.
**------------------------------------------------------------------------------------------**
Python3.7开始, dict类型正式'有顺序了', 不过只是保留键的插入顺序.
你不能随意重新排列dict中的键.
**------------------------------------------------------------------------------------------**
Set抽象基类中的所有特殊方法实现的都是中缀运算法.
(ps: 中缀运算法是指将运算符置于两个运算对象之间的一种运算符表示法.)
例如, a & b计算集合a和b的交集, 该运算符由__add__特殊方法实现.
接下来的两章会详细说明标准库中的序列, 映射和集合.
接下来按大类介绍Python数据模型定义的特殊方法.
1.4 特殊方法概述
<<Python语言参考手册>>中的第三章列出了80多个特殊方法名称,
其中一半以上用于实现算术运算符, 按位运算符和比较运算符.
下面几张表格概述了这些可用的特殊方法.
表1-1不包含实现中级运算符和核心数学函数(例如abs)的特殊方法.
这里列出的多数特殊方法本书中有所讨论, 包括新增的几个,
比如__anext__(Python 3.5新增)等异步特殊方法, 以及为类定义钩子的__init_subclass__(Python 3.6新增).
表1-1: 特殊方法名称(不含运算符). (为了格式好看一点, 将双下划线__改为单下划线_.)
| 类别 |
方法名 |
字符串(字节序列)表示形式 |
_repr_ _str_ format_ _bytes_ _fspath_ |
转换为数值 |
_bool_ _complex_ _int_ _float_ _hash_ _index_ |
模拟容器 |
_len_ _getitem_ _setitem_ _delitem_ _contains_ |
迭代 |
_iter_ _aiter_ _next_ _anext_ _reversed_ |
可调用对象或执行协程 |
_call_ _await_ |
上下文管理 |
_enter_ _exit_ _aexit_ _aenter |
实例创建和销毁(构造和析构实例) |
_new_ _init_ _del_ |
属性管理 |
_getattr_ _getattribute_ _setattr_ _delattr_ _dir |
属性描述符 |
_get_ _set_ _delete_ _set_name_ |
抽象基类 |
_instancecheck_ _subclasscheck_ |
类元编程 |
_prepare_ _init_subclass_ _class_getitem_ _mro_entries_ |
中缀运算符和数字运算符由表1-2中的特殊方法提供支持.
其中, __matmul__, __rmatmul__和imatmul是Python3.5新增的, 用于实现矩阵乘法中缀运算符@(见16章).
表1-2: 运算符的符号和背后的特殊方法. (为了格式好看一点, 将双下划线__改为单下划线_.)
| 运算符分类 |
符号 |
方法名称 |
一元数值运算符 |
-(负) +(正) abs() |
_neg_ _pos_ _abs_ |
各种比较运算符 |
< <= == != > => |
_lt_ _le_ _eq_ _ne_ _gt_ _ge_ |
算术运算符 |
+ - * / // % @ |
_add_ _sub_ _mul_ _truediv_ _floordiv_ |
|
divmod() round() ** pow() |
_mod_ _matmul_ _divmod_ _round_ _pow_ |
反向算术运算符 |
(交换算术运算符的操作数) |
_radd_ _rsub_ _rmul_ _rtruediv_ _rfloordiv_ |
|
|
_rmod_ _rmatmul_ _rdivmod_ _rround_ _pow_ |
增量赋值算术运算符 |
+= -= *= /= //= |
_iadd_ _isub_ _imul_ itruediv_ _ifloordiv_ |
|
@= **= |
_mod_ _imatmul_ _ipow_ |
按位运算符 |
& | ^ << >> ~ |
_and_ or_ _xor_ _lshift_ _rshift_ invert_ |
反向按位运算符 |
(交换按位运算符的操作数) |
_rand_ _ror_ _rxor_ _rlshift_ _rrshift_ |
增量赋值按位运算符 |
&= |= ^= <<= >>= |
_iand_ _ior_ _ixor_ _ilshift_ _irshift_ |
**------------------------------------------------------------------------------------------**
如果第一个操作数对应的特殊方法不可用, 则Python在第二操数上调用反向运算符对应的特殊方法.
(ps: 比如, 在执行a + b时, 如果a对象的__add__()方法不存在,
那么Python会尝试使用b对象的__radd__()方法来进行反向的加法运算.
如果反向运算符的特殊方法也不存在, 那么Python会抛出TypeError类型的异常.)
增量赋值时给结合了变量赋值功能的中缀运算符的简写形式, 例如 a += b.
第16章会详细说明反向运算符和增量赋值.
**------------------------------------------------------------------------------------------**
1.5 len为什么不是方法
这个问题我在2013年问过核心开发人员Raymond Htttinger,
他在回答时引用了<<Python之禅>>中的一句话, 道出了玄机: '实用胜过纯粹'.
1.3节说过, 当x是内置类型的实例是, len(x)运算速度非常快.
计算Cpython内置对象的长度是不调用任何内置方法, 而是直接读取C语言结构体中的字段.
获取容器中的项数是一项最常见的操作, str, list, memoryview等各种基本的容器类型必须高效完成这项工作.
换句话说, len之所以不作为方法调用, 是因为它经过了特殊处理,
被当作Python数据模型的一部分, 就像abs函数一样.
但是, 借助特殊方法__len__, 也可以让len适用于自定对象.
这是一种相对公平的这种方案, 即满足了内在对象对速度的要求, 又保证了语言的一致性.
这也体现了<<Python之禅>>中的另一句话: '特殊情况不是打破规则的理由'.
**------------------------------------------------------------------------------------------**
忘掉面对对象语言中方法调用句法, 把abs和len看作一元运算符, 说不定你更能接受它们表面上看似对函数的调用.
Python源自ABC语言, 很多特性继承自ABC, ABC中#运算符与Python中的len作用相同, 写作#S.
#也可作为中缀运算符使用, 写作x#s, 计算s中有多少个x.
对应到Python中, 写作s.count(x) (s是某种序列).
**------------------------------------------------------------------------------------------**
1.6 本章小节
借助特殊方法, 自定对象的行为可以像内置类型一样,
让我们写出更具表现力的代码, 符合社区所认可的Python风格.
Python对象基本上都需要提供一个有用的字符串表示形式, 在调试, 登记日志和向终端用户展示时使用.
鉴于此, 数据模型中才有__rerp__和__str__两个特殊方法.
模拟序列的行为(例如FrenchDeck示例)是特殊方法最常见的用途之一.
比如说, 数据库代码库返回的查询结果往往就是一个类似序列的容器.
第二章会具体说明如何充分利用现用的序列类型.
自己实现序列类型的方式在第12章讲解, 届时我们将在Vector类的基础上创建一个多维向量类.
得益于运算符重载, Python提供了丰富的数值类型, 除内置的数值类型之外,
还有decimal.Decimal和fractions.Fraction, 全部支持中缀算术运算符.
数据科学库NumPy还提供了矩阵和张量的中缀运算符.
第16章增强Vector类的示例将实现运算符, 包括反向运算符和增量赋值运算符.
Python数据模型中余下的特殊方法如何使用和实现, 本书大部分有所涵盖.
1.7 延伸阅读
本章及本书大部分内容参考了<<Python 语言参考手册>>中的第3章'数据模型'. 这是最权威的资料.
Python in Nuteshell, 3rd ed. (Alex Martelli. Anna Ravenscroft和Steve Holdon著)
对数据模型的讲解很精彩.
书中对属性访问机制的解说是我见过除CPython源码之外最权威的.
Martelli 还经常在Stack Overflow中回答问题, 目前已回答6200多个问题.
不信的话, 可以看看他在Stack Overflow中的个人资料.
Aavid Beazley著有两本基于Python3的书, 对数据模型做了详尽的介绍.
一个本<<Python参考手册(第4版)>>, 另一本是与Brian k. jones和著的<<Python Cookbook中文版(第3版)>>.
The Art of the Metaobject Protocol(Gregor Kiczales, Jim des Rivieres和Daniel G. Bobrow著)
解读了元对象协议的概念, Python数据模型就是其中一个例子.
*-------------------------------杂谈: 数据模式还是对象模型---------------------------------------*
Python文档中的说法是'Python数据模型', 而多数作者采用的说法是'Python对象模型'.
Python in a Nutshell, 3rd ed. 以及<<Python参考手册(第4版)>>都对Python数据模型进行了深入解读,
不过这几位作者用的均是'对象模型'.
维基百科给对象模式的第一个定义是'一门计算机编程语言中对象的一般特性'.
这正是'Python数据模型'所描述的概念,
本书采用'数据模型'这一说法, 因为Python文档始终使用这个词代指Python对象模型,
而且还因为<<Python语言参考手册>>中与本书关系最大的那一章的标题就是'数据模型'.
*---------------------------------------------------------------------------------------------*
*--------------------------------------------麻瓜方法------------------------------------------*
按照The Original Hacker's Dictionary的定义.
'魔法'的意思是'神秘莫测, 或复杂到说不清', 或者'鲜为人知的功能, 让不可能成为可能'.
Ruby中也有类似'特殊方法'的概念, Ruby社区被称之为'魔法方法'.
Python社区也有不少人采用这种说法.
而我认为, '特殊方法'与'魔法方法'是对应的.
Python和Ruby都利用这个概念丰富元对象协议, 即使是你我这种不会'魔法'的麻瓜,
凭借完善的文档, 也能模拟核心开发人员编写语言解释器时用到的很多功能.
Go语言就不一样了.
在这门语言中, 一些对象的功能确实像魔法, 因为用户自己定义的类型无法模拟.
例如, Go语言中的数组, 字符串和映射支持使用方括号存取项, 写作a[i].
但是, 我们自定义的容器类型无法使用[]表示法. 更糟糕是, Go语言没有可迭代接口或迭代器对象之类的概念,
因此for/range句法仅支持5种'魔法'内置类型, 包括数组, 字符串和映射.
以后Go语言的设计人员说不定增强元对象协议. 但是目前来看, 与Python或Ruby相比, 它的功能十分有限.
**------------------------------------------------------------------------------------------**
**-------------------------------------------元对象-----------------------------------------**
The Art of the Metaobject Protocol(以下简称AMOP)是我最喜欢的一本计算机图书.
我提到这本书是因为'元对象协议'对理解Python数据模型有帮助, 而且其他语言中也有类似的功能.
'元对象'值构成语言自身的基本对象. 在这个语境下, '协议'等同于'接口'.
所有, '元对象协议'就是对象模型的高级说法, 指语言核心构建的API.
一套丰富的元对象协议能让我们拓展语言, 支持你的编程范式.
AMOP的第一作者Gregor Kiczales后来成为面向方向的程序设计(aspect-oriented programming)的先驱,
也是AspectJ(实现该范式的Java拓展)的最初作者.
面向方面的程序设计在Python这样的动态语言中实现起来更简单, 一些框架就提供了这个范式,
Plone内容管理系统中的zope.interface就是一例.
**------------------------------------------------------------------------------------------**
2. doctest模块
2.1 介绍
doctest模块是Python标准库中自带的模块,
它可以让你编写测试用例, 测试你的函数或者模块是否符合预期的输出结果.
一般情况下, 我们在开发Python应用程序时, 可以使用doctest来作为单元测试工具.
它的优点在于测试用例直接就在docstring(文档字符串)中,
所以非常容易编写和维护, 而且代码和文档写在一起, 方便后续维护.
2.1 基本使用
下面是一个简单的doctest示例:
def add(a, b):
"""
`add` 函数将两个数字相加在一起
>>> add(2, 2)
4
>>> add(5, 7)
12
"""
return a + b
在文档字符串中每个测试都由一个三行格式组成:
>>> [expression to be tested]
[expected output]
第一行以>>>开始, 表示要测试的内容, 可以是任意Python表达式(函数, 变量, 操作等等).
第二行是预期输出, 将作为测试用例的期望输出结果. 第三行留空(也可以不留).
如果有多个测试, 则继续以三行格式重复进行.
其它字符是普通的描述文档.
这里的测试会测试add函数, 确保其返回期望的结果, 并且同时作为函数的文档注释.
使用doctest进行测试的方式其他需要注意的点包括:
• 对于输出结果的比较, 可以使用 == 符号.
这里会使用Python的assert语句自动进行比较, 如果失败了则会抛出AssertionError异常.
• 如果测试用例中涉及到需要执行一些命令到程序中,
可以尝试使用doctest.NORMALIZE_WHITESPACE标志来让doctest自动进行空格的格式化, 这样更加方便测试.
• doctest中涉及到多行字符串的情况, 也可以使用'''或"""来包裹需要测试的字符串.
• 最后, 可以使用doctest.testmod()来运行测试.
注意: doctest不适合进行复杂的测试, 一般只适合测试简单的输入/输出.
如果需要进行更加深入的测试, 建议使用unittest模块.
可以按照如下方式在程序中运行测试:
if __name__ == "__main__":
import doctest
doctest.testmod()
这个单元测试会自动查找模块中所有的docstrings, 并且运行其中的doctest.
2.3 预期输出省略格式
# doctest: +ELLIPSIS 是一种特殊的注释, 用于告诉doctest在测试输出中允许使用省略符号(...).
省略符号可以用于表示输出的部分被省略, 通常用于测试长文本或大型数据结构时, 以简化测试结果的显示.
要使用 # doctest: +ELLIPSIS, 只需在文档字符串的示例代码之前添加该注释即可. 例如:
def print_sequence(sequence):
"""
>>> print_sequence(range(100)) # doctest: +ELLIPSIS
0
1
2
...
99
"""
for i in sequence:
print(i)
if __name__ == "__main__":
import doctest
doctest.testmod()
在上述示例中, # doctest: +ELLIPSIS注释被添加到print_sequence()函数的文档字符串中的示例代码之前.
这将告诉doctest在比较输出时忽略省略符号.
运行doctest.testmod()时, doctest会执行该函数中的示例代码, 并将其与预期输出进行比较.
在比较过程中, 如果遇到省略符号, doctest将忽略省略的部分, 并继续比较后续的输出.
(省略符号(...)后面还可以写预期输出, 结果对不上样会报错.)
使用# doctest: +ELLIPSIS注释可以使测试结果更具灵活性和可读性, 特别是在处理较长的输出时.