基于包围框回归的目标检测网络原理及Tensorflow实现
对象检测是对图像内的对象进行分类和定位。 换句话说,它是图像分类和对象定位的结合。 构建用于图像分类的机器学习模型更简单,我在我的一篇文章中对此进行了描述。 然而,图像分类器无法准确判断对象在图像内的位置。 为了实现这一目标,我们需要构建一个神经网络,除了对其进行分类之外,它还可以定位图像内的对象。 在这篇文章中,我将描述如何通过解决这两个问题来构建用于对象检测的神经网络。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
1、检测对象
由于我的目的是从头开始构建模型,而不是在数据准备上花费太多时间,因此我选择了我能想到的最简单的对象。 我的选择是用一块纸板制作一个简单的红色视觉标记。 由于视觉标记只是一个 2D 形状,因此可以捕获它的不同角度是有限的,因此训练集所需的图像数量有限。 我将视觉标记制作成圆形和手掌大小,以便简单且易于操作。
2、模型的架构
在深入讨论实现细节之前,我想先描述一下模型的架构。 首先,我的目标是推断两个答案:
- 图像中是否有物体
- 物体的具体位置在哪里
为了解决第一个问题,我可以使用图像分类器——具有两个输出神经元的卷积神经网络。 这些输出神经元之一可以代表物体的存在,而另一个可以代表物体的不存在。 换句话说,图像分类器的输出是不同对象类别之间的概率分布,或者在本例中是对象存在(“圆圈”)或不存在(“无圆圈”)。 然后可以通过在输出层应用 Softmax 函数来确定概率最高的类别。
解决第二个问题则完全不同。 我想要的是通过在对象周围绘制边界框来定位对象。 为此,我必须找到边界框左上角和右下角的像素坐标。 这意味着我的神经网络必须计算出图像内这两个点的 x、y 坐标。 我可以通过设计一个输出层有 4 个神经元(代表 4 个数字坐标值)的卷积神经网络来做到这一点。

接下来的挑战是使用单个神经网络实现这两个目标。 一方面,解决方案的图像分类器部分将输出神经元的值视为概率分布。 然后它选择概率最高的一个,并将其标签作为答案。 另一方面,解决方案的对象定位部分需要 4 个输出神经元给出实际的边界框坐标。 因此,神经网络很难训练其完全连接的密集层来同时满足这两个要求。 因为,优化分类的权重和偏差会危及本地化的输出,反之亦然。
这个问题的解决方案是设计一个具有两个分支输出的神经网络。 由于必须对两个问题同等地执行特征提取,因此我使卷积层变得通用且可共享。 然而,在卷积层之后,我将网络分为两个——每个都有自己的密集层和输出层,以实现两种不同的结果。

这种架构允许我用不同的损失函数和激活函数来训练这两个头或分支。 此外,这使我能够使用不同的数据集单独训练它们。 我将在本文后面描述我是如何做到这一点的,以及为什么这样做很重要。
3、数据准备
与任何其他机器学习项目一样,数据准备也是关键。 首先,我将相机配置为将图像分辨率设置为 2160 x 2160,以捕获方形图像。然后,我拍摄了大约 126 张视觉标记照片,将其放置在图像帧内的不同位置,并将其放置在距相机不同的距离处。 此外,我拍摄了他们不同的背景。 训练数据集中的这些变化有助于模型最终实现更准确的预测。

我又拍了 62 张没有视觉标记的照片。 这样做是为了训练模型来识别标记的缺失。 然后我将所有照片的分辨率调整为 216×216 像素,因为没有必要使用更高分辨率的图像来识别这样一个简单的物体。
4、图像标注
下一步是使用边界框注释视觉标记。 与图像分类器不同,这是构建对象定位器的重要一步。 为此,我使用了名为 VoTT 的免费开源注释工具。
首先,我在 VoTT 中创建了一个名为“视觉标记检测器”的项目,并创建了源连接和目标连接,分别指向我计算机中源图像和生成注释的文件夹位置。
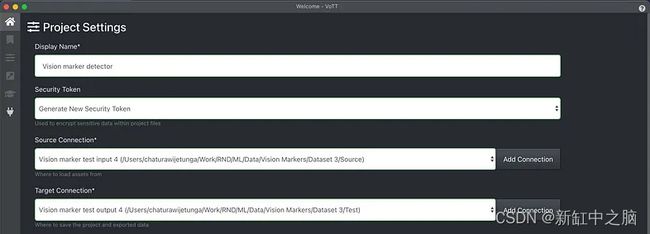
此外,我创建了一个名为“Circle”的标签(标签),用于注释图像中的视觉标记。

然后是时候进行不太有趣的图像注释任务了!
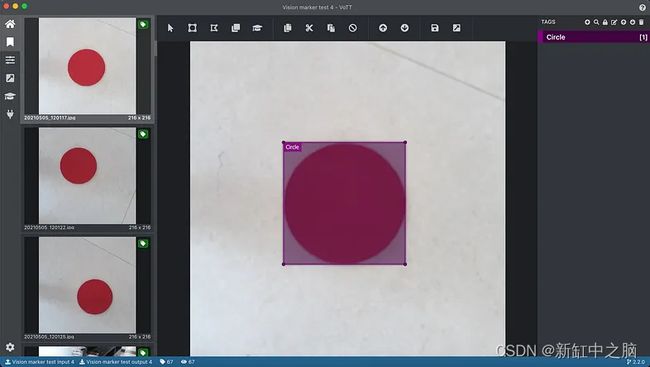
这里跳过了没有视觉标记拍摄的照片。 我将在本文后面描述如何使用这些图像进行训练。 但是,我确保导出设置中的以下设置也被设置为为未分配(未标记)图像生成注释 XML 文件。

在完成对图像进行注释的繁琐任务后,我使用 VoTT 中的导出选项将所有注释导出为 PASCAL VOC 格式。
5、组织文件夹结构
我将图像和相应的注释 xml 文件分为两组 - 一组代表训练集,另一组代表验证集。

然后我将它们移动到项目文件夹结构中名为“Images”的父文件夹中。
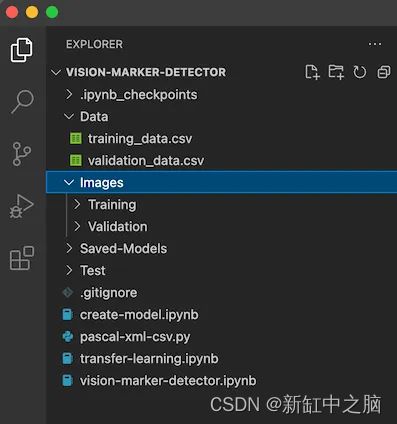
6、创建数据集
除了图像及其标签之外,在准备用于训练对象检测器的数据集的过程中使用边界框坐标也很重要。 为此,我使用了一个 python 脚本,该脚本读取 VoTT 生成的所有 xml 文件,并为训练和验证数据集生成两个 CSV 文件。 我编写此脚本的方式是,我可以使用配置变量 — SKIP_NEGATIVE 设置为 True 或 False 来运行它,以排除或包含负片图像(其中不包含对象的图像)。
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
SKIP_NEGATIVES = True
NEGATIVE_CLASS = "No-Circle"
def xml_to_csv(path, skipNegatives):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
if root.find('object'):
for member in root.findall('object'):
bbx = member.find('bndbox')
xmin = round(float(bbx.find('xmin').text))
ymin = round(float(bbx.find('ymin').text))
xmax = round(float(bbx.find('xmax').text))
ymax = round(float(bbx.find('ymax').text))
label = member.find('name').text
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
label,
xmin,
ymin,
xmax,
ymax
)
print(value)
xml_list.append(value)
elif not skipNegatives:
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
NEGATIVE_CLASS,
0,
0,
0,
0
)
print(value)
xml_list.append(value)
column_name = ['filename', 'width', 'height',
'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
datasets = ['training', 'validation']
for ds in datasets:
image_path = os.path.join(os.getcwd(), 'Images', ds)
xml_df = xml_to_csv(image_path, SKIP_NEGATIVES)
xml_df.to_csv('Data/{}_data.csv'.format(ds), index=None)
print('Successfully converted xml to csv.')
main()
然后,我编写了以下代码,通过读取上述步骤生成的training_data.csv 文件来创建训练数据集。 在这里,我创建了 3 个列表 - 第一个列表用于图像数据数组列表,然后第二个和第三个列表分别用于相应的边界框坐标和图像标签。
TRAINING_CSV_FILE = 'Data/training_data.csv'
TRAINING_IMAGE_DIR = 'Images/Training'
training_image_records = pd.read_csv(TRAINING_CSV_FILE)
train_image_path = os.path.join(os.getcwd(), TRAINING_IMAGE_DIR)
train_images = []
train_targets = []
train_labels = []
for index, row in training_image_records.iterrows():
(filename, width, height, class_name, xmin, ymin, xmax, ymax) = row
train_image_fullpath = os.path.join(train_image_path, filename)
train_img = keras.preprocessing.image.load_img(train_image_fullpath, target_size=(height, width))
train_img_arr = keras.preprocessing.image.img_to_array(train_img)
xmin = round(xmin/ width, 2)
ymin = round(ymin/ height, 2)
xmax = round(xmax/ width, 2)
ymax = round(ymax/ height, 2)
train_images.append(train_img_arr)
train_targets.append((xmin, ymin, xmax, ymax))
train_labels.append(classes.index(class_name))
我也使用相同的代码来加载验证数据集。 然后我使用以下代码将列表转换为 numpy 数组。
train_images = np.array(train_images)
train_targets = np.array(train_targets)
train_labels = np.array(train_labels)
validation_images = np.array(validation_images)
validation_targets = np.array(validation_targets)
validation_labels = np.array(validation_labels)
训练模型时,train_images 数组用作 Keras API 中 Model 类的 fit 方法的输入数据参数(或参数 x)。 然后,数组 — train_targets 和 train_labels 在字典中一起用作 fit 方法的目标参数(或参数 y)。 您将在本文后面注意到这一点。
7、构建模型
然后是时候构建模型了!
首先,我将必要的依赖项导入到脚本中。
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import pathlib
import pandas as pd
from PIL import Image
from PIL.ImageDraw import Draw
我以变量的形式创建了一些配置参数,并定义了用于模型的类数组。
width = 216
height = 216
num_classes = 2
classes = ["Circle", "No-Circle"]
然后我编写了定义模型的代码。 首先,我定义了输入层,然后定义了一个重新缩放层,将像素数据转换为数值范围 0-1。 然后我创建了卷积层,将一层的输出链接到下一层的输入。 我用前缀“bl_”命名所有这些卷积层,目的是稍后使用这个前缀来获取它们。
#create the common input layer
input_shape = (height, width, 3)
input_layer = tf.keras.layers.Input(input_shape)
#create the base layers
base_layers = layers.experimental.preprocessing.Rescaling(1./255, name='bl_1')(input_layer)
base_layers = layers.Conv2D(16, 3, padding='same', activation='relu', name='bl_2')(base_layers)
base_layers = layers.MaxPooling2D(name='bl_3')(base_layers)
base_layers = layers.Conv2D(32, 3, padding='same', activation='relu', name='bl_4')(base_layers)
base_layers = layers.MaxPooling2D(name='bl_5')(base_layers)
base_layers = layers.Conv2D(64, 3, padding='same', activation='relu', name='bl_6')(base_layers)
base_layers = layers.MaxPooling2D(name='bl_7')(base_layers)
base_layers = layers.Flatten(name='bl_8')(base_layers)
其次,我根据之前讨论的架构通过输入卷积层的扁平输出来定义分类分支层。 这里我只添加了两个密集层——一层有 128 个神经元,最后一层只有 2 个神经元,对应于我们必须预测的两个类标签。 此外,我为分类分支的层添加了前缀“cl_”。
#create the classifier branch
classifier_branch = layers.Dense(128, activation='relu', name='cl_1')(base_layers)
classifier_branch = layers.Dense(num_classes, name='cl_head')(classifier_branch)
第三,我再次定义本地化分支层,输入卷积层的平坦输出。 在这里,我添加了 4 个独立的密集层,神经元数量逐渐减少,最后一层有 4 个神经元,对应于用于预测的 4 个边界框坐标值。 该分支中的层以前缀“bb_”命名。
#create the localiser branch
locator_branch = layers.Dense(128, activation='relu', name='bb_1')(base_layers)
locator_branch = layers.Dense(64, activation='relu', name='bb_2')(locator_branch)
locator_branch = layers.Dense(32, activation='relu', name='bb_3')(locator_branch)
locator_branch = layers.Dense(4, activation='sigmoid', name='bb_head')(locator_branch)
最后,是时候通过传递输入层和两个输出分支来创建模型类了。 这是我们将两个输出分支焊接到基本模型中的地方。
model = tf.keras.Model(input_layer,
outputs=[classifier_branch,locator_branch])
模型的摘要如下所示:

8、编译模型
由于两个输出分支的设计目的是实现两种不同的结果(一个输出概率分布,另一个预测实际的边界框值),因此有必要为每个分支设置适当的损失函数。 我对分类头使用了稀疏分类交叉熵损失函数,对定位头使用了均方误差 (MSE)。 我通过定义以下字典来实现这一点。
losses =
{"cl_head":tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
"bb_head":tf.keras.losses.MSE}
然后我将其与 Adam 优化方法一起使用并编译了模型。
model.compile(loss=losses, optimizer='Adam', metrics=['accuracy'])
9、训练本地化模型—边界框回归
正如我在模型架构部分中所描述的,我的计划是首先训练模型进行对象本地化。 在训练的这一部分期间,模型的定位分支将执行边界框回归,然后调整其权重和偏差以优化边界框预测。
这里重要的是,我仅使用带注释的图像(仅具有视觉标记的图像)来训练模型的定位部分。 我通过运行 CSV 生成脚本(将 SKIP_NEGATIVES 参数设置为 True)来实现此目的,然后再运行上面数据集创建部分中所述的数据集生成代码。
在训练定位分支时跳过负图像(没有视觉标记的图像)的原因是,否则它会影响边界框预测的准确性。 因为我们必须设置虚拟边界框坐标值 - 例如,如果我们也在训练数据集中使用负图像,则为 (0,0) (0,0)。 例如,下图显示了如果我们使用训练集中的正图像和负图像进行训练,则本地化分支的训练性能如何。
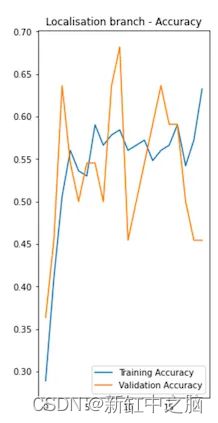
然而,仅使用正图像来训练定位分支的缺点是它会给负图像带来误报。 但由于我无意依赖本地化分支来确定视觉标记是否存在,所以这对我来说不是问题。
我使用以下代码定义了两个字典对象,用于两个命名分支 cl_head 和 bb_head 的训练和验证目标。 在这里,你会注意到标签数组用于分类分支,边界框坐标数组用于本地化分支。
trainTargets = {
"cl_head": train_labels,
"bb_head": train_targets
}
validationTargets = {
"cl_head": validation_labels,
"bb_head": validation_targets
}
我最初将 epoch 数设置为 20,将 batch_size 设置为 4。 然后我运行以下代码来训练模型。
history = model.fit(train_images, trainTargets,
validation_data=(validation_images, validationTargets),
batch_size=4,
epochs=training_epochs,
shuffle=True,
verbose=1)
下图展示了两个分支的训练表现。
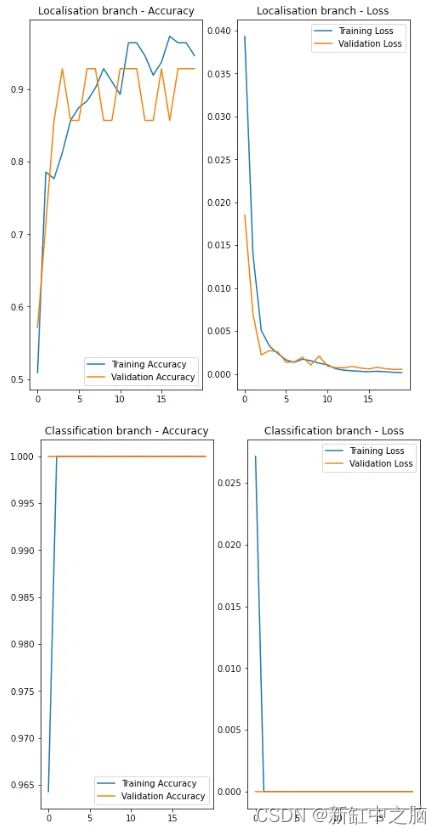
你会在上面的图表中注意到本地化分支的表现相当不错。 然而,分类分支所达到的准确度好得令人难以置信。 它的表现并不值得信赖,因为迄今为止还没有看到任何负面形象。 这意味着模型(它的分类部分)将始终将它所看到的内容分类为“视觉标记”,因为它从未见过没有它的任何东西。
然而,即使在这个阶段,模型仍然能够准确地预测边界框。

但话又说回来,当用于负图像时,它会给出误报,并按预期给出一些随机边界框坐标。

这就是我接下来想要通过训练分类分支来解决的问题。
10、训练分类模型
然后是时候训练模型的分类分支了。
这里的区别在于,我们需要使用正图像和负图像来训练分类器,因为模型需要学习图像的存在和不存在才能正确地对它看到的图像进行分类。
为了实现此目的,我再次运行 CSV 生成脚本,不过这次将 SKIP_NEGATIVES 参数设置为 False。 这会生成包含正片和负片图像记录的 CSV 文件。 对于负片图像,它创建了边界框坐标全零的记录,并分配了标签 - “No-Circle”作为标签。
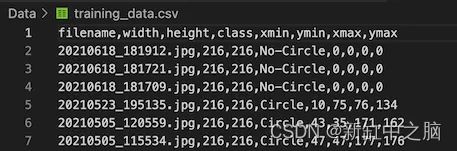
创建新数据集的其余步骤与创建用于训练本地化分支的数据集相同。
在第二阶段训练模型之前我做的另一件重要的事情是保留已经训练好的卷积层和定位分支的权重和偏差。 因为,否则使用不同图像集的新一轮训练可能会危及这些层已经训练的权重和偏差,从而导致性能下降。 解决方案是在使用新数据集训练分类分支之前冻结卷积层和边界框分支。
我通过使用各自的前缀获取基础层和本地化分支层并将每层的可训练属性设置为 False 来实现这一点。
for layer in model.layers:
if layer.name.startswith('bl_'):
layer.trainable = False
for layer in model.layers:
if layer.name.startswith('bb_'):
layer.trainable = False
在此步骤之后,模型中存在大量不可训练的参数。 这在模型的摘要中可见。

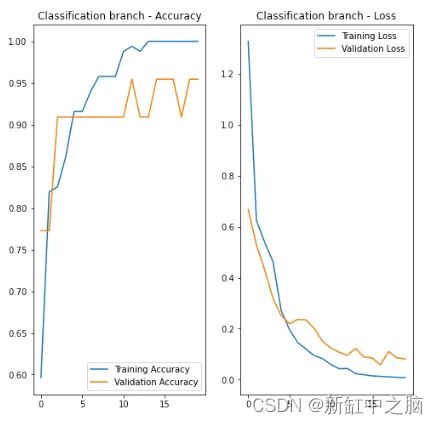
然后我使用包括正图像和负图像的第二个数据集来训练模型。 由于基础层和本地化分支层被冻结,它基本上只能训练本地化层。 仅 20 个 epoch 的分类分支的训练性能就不算太差,如下图所示。
11、使用模型进行物体检测
接下来是使用模型进行一些预测的有趣部分。
我使用了一组使用和不使用视觉标记拍摄的新照片来测试一些预测。 这里,定位器输出总是给出一个边界框,即使其中没有视觉标记。 但这在应用程序中不是问题,因为我们始终可以首先依赖分类输出,了解图像中是否存在对象,然后避免绘制边界框(如果不存在)。 在 Jupyter Notebook 中显示以下图像及其边界框时,我使用了相同的技术。

12、结束语
这个练习向我证明,我们可以从头开始构建一个简单的单类对象检测器,而无需依赖大型预训练模型。 其次,双输出架构和不同数据集的两阶段训练是实现这一结果的关键。 该模型给出了一些误报和漏报,但这主要是由于训练数据集有限和非最佳超参数造成的。 通过调整超参数和使用更大的训练数据集,我们将能够获得更好的结果。
原文链接:基于包围框回归的目标检测 — BimAnt