Hadoop生态体系-HDFS
目录标题
-
- 1、Apache Hadoop
- 2、HDFS
-
- 2.1 设计目标:
- 2.2 特性:
- 2.3 架构
- 2.4 注意点
- 2.5 HDFS基本操作
-
- 2.5.1 shell命令选项
- 2.5.2 shell常用命令介绍
- 3、HDFS基本原理
-
- 3.1 NameNode 概述
- 3.2 Datanode概述
1、Apache Hadoop
Hadoop:允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
核心组件有:
HDFS(分布式文件系统):解决海量数据存储
YARN(作业调度和集群资源管理的框架):解决资源任务调度
MAPREDUCE(分布式运算编程框架):解决海量数据计算
特点:扩容能力(Scalable)成本低(Economical)高效率(Efficient)可靠性(Rellable)
HADOOP 集群具体来说包含两个集群:HDFS 集群和 YARN 集群
HDFS 集群负责海量数据的存储
YARN 集群负责海量数据运算时的资源调度
Hadoop 部署方式分三种,Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster mode(群集模式),其中前两种都是在单机部署。
独立模式又称为单机模式,仅 1 个机器运行 1 个 java 进程,主要用于调试。
伪分布模式也是在 1 个机器上运行 HDFS 的 NameNode 和 DataNode、YARN 的ResourceManger 和 NodeManager,但分别启动单独的 java 进程,主要用于调试。
集群模式主要用于生产环境部署。会使用 N 台主机组成一个 Hadoop 集群。
2、HDFS
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统
分布式文件系统解决的问题就是大数据存储
2.1 设计目标:
- 硬件故障是常态,有成百上千个服务器组成,每一个组成部分都 有可能出故障。因此故障检测和自动快速恢复是HDFS的核心架构目标
- 相较于数据访问的反应时间,更注重数据访问的高吞吐量
- HDFS被调整成支持大文件
- 对文件的要求是write-one-read-many访问模式,即一个文件一旦创建-写入-关闭后就不需要修改了,这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能
- 移动计算的代价比之移动数据的代价低
- 在异构的硬件和软件平台上的可移植性
2.2 特性:
是一个文件系统,用于存储文件,通过统一的命令空间目录树来定位文件;
是分布式的,很多服务器联合起来实习其功能,
2.3 架构
一般一个HDFS集群有一个Namenode和一定数目的Datanode组成
Namenode是HDFS的集群主节点,Datanode是HDFS集群从节点
HDFS中文件在物理上是分块存储的
2.4 注意点
把目录结构及文件分块位置信息叫做元数据
为了容错,文件的所有 block 都会有副本。副本数量也可以通过参数设置 dfs.replication,默认是 3。
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改。正因为如此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做.网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
2.5 HDFS基本操作
Hadoop 提供了文件系统的 shell 命令行客户端,使用方法如下:
Hadoop fs
#例子:
hadoop fs -ls hdfs://namenode:host/parent/child
#对于本地文件系统,命令示例如下:
hadoop fs -ls file:///root/
2.5.1 shell命令选项
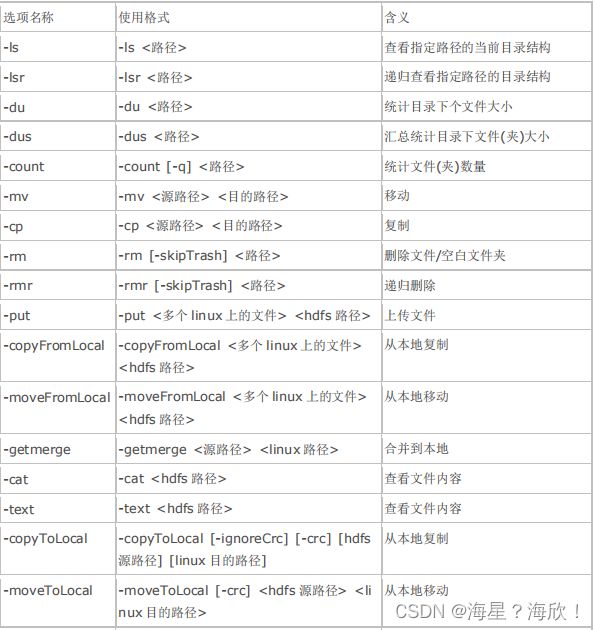

2.5.2 shell常用命令介绍
- -ls -查看
hadoop fs -ls [-h] [-R]
显示文件、目录信息
2)-mkdir -创建目录
hadoop fs -mkdir [-p]
创建目录,-p表示会创建各级父目录
3)-put --上传
使用方法:hadoop fs -put [-f] [-p]
将单个src或者多个srcs从本地文件系统复制到目标文件系统
-f :覆盖目的地
-p :保留访问和修改时间
4) -get --下载
hadoop fs -get [-ignorecrc] [-crc] [-p] [-f]
-ignorecrc:跳过对下载文件的CRC检查
-crc :为下载的文件写crc校验和
功能:将文件复制到本地文件系统
5) -appendToFile --追加
hadoop fs -appendToFile
追加一个文件到已经存在的文件末尾



3、HDFS基本原理
3.1 NameNode 概述
是HDFS的核心
也称为master
仅存储元数据(文件系统中所有文件的目录树,并跟踪整个集群中的文件)
namenode不存储实际数据或数据集。数据本身实际存储在DataNodes中。
namenode知道HDFS中任何给定文件的快列表及其位置
namenode并不持久化存储每个文件中各个块所在的Datanode的位置信息
Namenode所在机器通常会配置大量内存
3.2 Datanode概述
datanode负责将实际数据存储在HDFS中
Datanode也称为slave
NameNode和Datanode会不断通信
Datanode发布时,它将自己发布到namenode上并汇报自己负责持有的块列表
当某个 DataNode 关闭时,它不会影响数据或群集的可用性。NameNode 将安排由其他 DataNode 管理的块进行副本复制。
DataNode 所在机器通常配置有大量的硬盘空间。因为实际数据存储在DataNode 中。
DataNode 会定期(dfs.heartbeat.interval 配置项配置,默认是 3 秒)向NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效。
block 汇报时间间隔取参数 dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时.