分布式架构--两阶段提交和三阶段提交
在分布式系统中,著有CAP理论,该理论由加州大学伯克利分校的Eric Brewer教授提出,该理论阐述了在一个分布式系统中不可能同时满足一致性(Consistency)、可用性(Availability),以及分区 容错性(Partition tolerance)。
-
一致性
在分布式系统中数据往往存在多个副本,一致性描述的是这些副本中的数据在内容和组织上的一致。 -
可用性
可用性描述了系统对用户的服务能力,所谓可用是指在用户容忍的时间范围内返回用户期望的结果。 -
分区容错性
分布式系统通常由多个节点构成,这些节点通常分布在不同的网络中,然而网络始终是不可靠的,所以存在分布式集群中的节点因为网络通信故障导致被孤立成一个个小集群的可能性,分区容错性要求在出现这种情况下系统仍然能够对外提供一致性的可用服务。
对于一个分布式系统,我们始终要假设网络是不可靠的,所以分区容错性是对一个分布式系统最基本的要求,所以我们更多的是尝试在可用性和一致性之 间寻找一个平衡点。让分布式集群始终对外提供可用的一致性服务一直是富有挑战和趣味的一项任务。暂且抛开可用性,拿一致性来说,对于关系型数据库我们通常 利用事务来保证数据的一致性,当我们的数据量越来越大,大到单库已经无法承担时,我们不得不采取分库分表的策略对数据库实现拆分,构建分布式数据库集群, 这样可以将一个数据库的压力分摊到多个数据库,极大的提升了数据库的存储和响应能力,但是也为我们使用数据库带来了许多的限制,比如主键的全局唯一、联表 查询、数据聚合等等,另外一个相当棘手的问题就是数据库的事务由原先的单库事务变成了现在的分布式事务。
分布式事务的实现并不是很难,比如下 文要展开的两阶段提交(2PC:Two-Phrase Commit)和三阶段提交(3PC:Three-Phrase Commit)都给我们提供了思路,但是如果要保证数据的强一致性,并要求对外提供可用的服务,那么就变成了一个几乎不可能的任务(至少目前是),因此很 多分布式系统对于数据强一致性都敬而远之,本人在之前项目的架构设计中也花费不少时间在系统的一致性和可用性之间寻找平衡。
两阶段提交协议(2PC:Two-Phrase Commit)
两阶段提交协议的目标在于在分布式系统中保证数据的一致性,许多分布式系统采用该协议提供对分布式事务的支持(提供但不一定有人用,呵呵~)。 顾名思义,该协议将一个分布式的事务过程拆分成两个阶段:投票阶段和事务提交阶段。为了让整个数据库集群能够正常的运行,该协议指定了一个“协调者”单 点,用于协调整个数据库集群的运行,为了简化描述,我们将数据库里面的各个节点称为“参与者”,三阶段提交协议中同样包含“协调者”和“参与者”这两个定 义。
第一阶段:投票阶段
该阶段的主要目的在于打探数据库集群中的各个参与者是否能够正常的执行事务,具体步骤如下:
1. 协调者向所有的参与者发送事务执行请求,并等待参与者反馈事务执行结果。
2. 事务参与者收到请求之后,执行事务,但不提交,并记录事务日志。
3. 参与者将自己事务执行情况反馈给协调者,同时阻塞等待协调者的后续指令。
第二阶段:事务提交阶段
在第一阶段协调者的询盘之后,各个参与者会回复自己事务的执行情况,这时候存在三种可能:
1. 所有的参与者回复能够正常执行事务
2. 一个或多个参与者回复事务执行失败
3. 协调者等待超时。对于第一种情况,协调者将向所有的参与者发出提交事务的通知,具体步骤如下:
1. 协调者向各个参与者发送commit通知,请求提交事务。
2. 参与者收到事务提交通知之后,执行commit操作,然后释放占有的资源。
3. 参与者向协调者返回事务commit结果信息。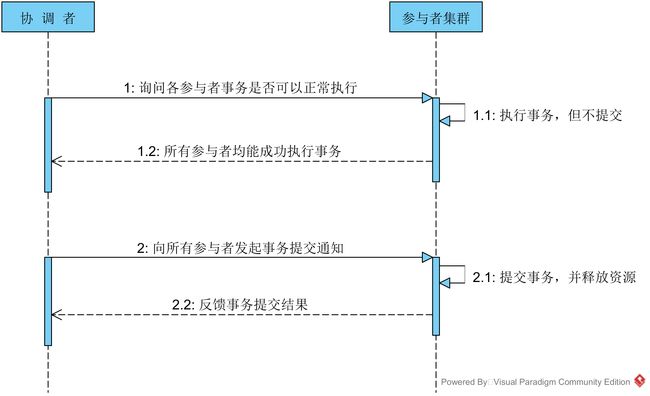
对于第二、三种情况,协调者均认为参与者无法正常成功执行事务,为了整个集群数据的一致性,所以要向各个参与者发送事务回滚通知,具体步骤如下:
1. 协调者向各个参与者发送事务rollback通知,请求回滚事务。
2. 参与者收到事务回滚通知之后,执行rollback操作,然后释放占有的资源。
3. 参与者向协调者返回事务rollback结果信息。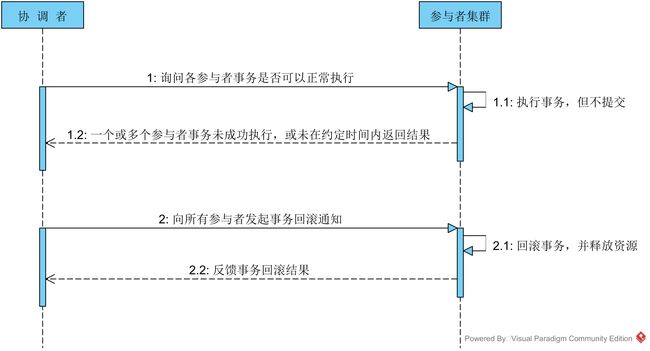
两阶段提交协议解决的是分布式数据库数据强一致性问题,其原理简单,易于实现,但是缺点也是显而易见的,主要缺点如下:
-
单点问题
协调者在整个两阶段提交过程中扮演着举足轻重的作用,一旦协调者所在服务器宕机,那么就会影响整个数据库集群的正常运行,比如在第二阶段中,如果协调者因为故障不能正常发送事务提交或回滚通知,那么参与者们将一直处于阻塞状态,整个数据库集群将无法提供服务。 -
同步阻塞
两阶段提交执行过程中,所有的参与者都需要听从协调者的统一调度,期间处于阻塞状态而不能从事其他操作,这样效率及其低下。 -
数据不一致性
两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能,比如在第二阶段中,假设协调者发出了 事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了commit操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这 时候就产生了数据的不一致性。
三阶段提交协议(2PC:Three-Phrase Commit)
针对两阶段提交存在的问题,三阶段提交协议通过引入一个“预询盘”阶段,以及超时策略来减少整个集群的阻塞时间,提升系统性能。三阶段提交的三个阶段分别为:can_commit,pre_commit,do_commit。
第一阶段:can_commit
该阶段协调者会去询问各个参与者是否能够正常执行事务,参与者根据自身情况回复一个预估值,相对于真正的执行事务,这个过程是轻量的,具体步骤如下:
-
第二阶段:pre_commit
本阶段协调者会根据第一阶段的询盘结果采取相应操作,询盘结果主要有三种:
1. 协调者向各个参与者发送事务询问通知,询问是否可以执行事务操作,并等待回复
2. 各个参与者依据自身状况回复一个预估值,如果预估自己能够正常执行事务就返回确定信息,并进入预备状态,否则返回否定信息
针对第一种情况,协调者会向所有参与者发送事务执行请求,具体步骤如下:
1. 协调者向所有的事务参与者发送事务执行通知
2. 参与者收到通知后,执行事务,但不提交
3. 参与者将事务执行情况返回给客户端在上面的步骤中,如果参与者等待超时,则会中断事务。 针对第二、三种情况,协调者认为事务无法正常执行,于是向各个参与者发出abort通知,请求退出预备状态,具体步骤如下:
1. 协调者向所有事务参与者发送abort通知
2. 参与者收到通知后,中断事务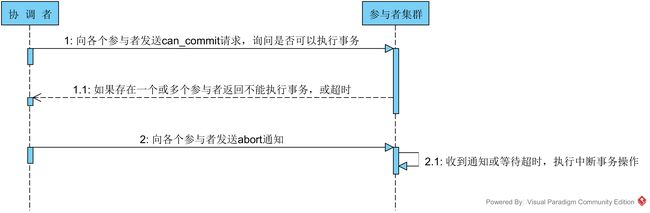
第三阶段:do_commit
如果第二阶段事务未中断,那么本阶段协调者将会依据事务执行返回的结果来决定提交或回滚事务,分为三种情况:
1. 所有的参与者都能正常执行事务
2. 一个或多个参与者执行事务失败
3. 协调者等待超时针对第一种情况,协调者向各个参与者发起事务提交请求,具体步骤如下:
1. 协调者向所有参与者发送事务commit通知
2. 所有参与者在收到通知之后执行commit操作,并释放占有的资源
3. 参与者向协调者反馈事务提交结果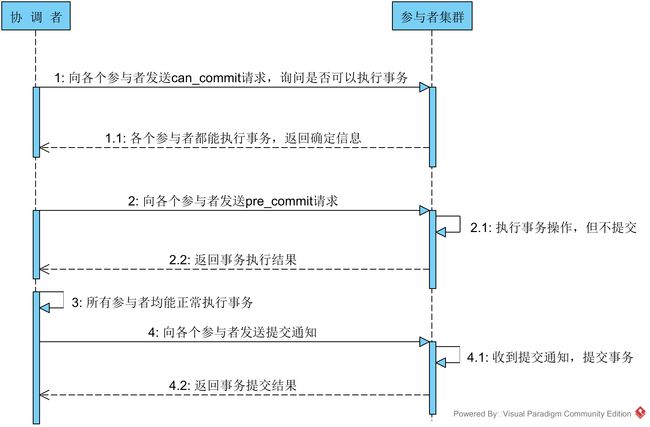
针对第二、三种情况,协调者认为事务无法正常执行,于是向各个参与者发送事务回滚请求,具体步骤如下:
1. 协调者向所有参与者发送事务rollback通知
2. 所有参与者在收到通知之后执行rollback操作,并释放占有的资源
3. 参与者向协调者反馈事务提交结果
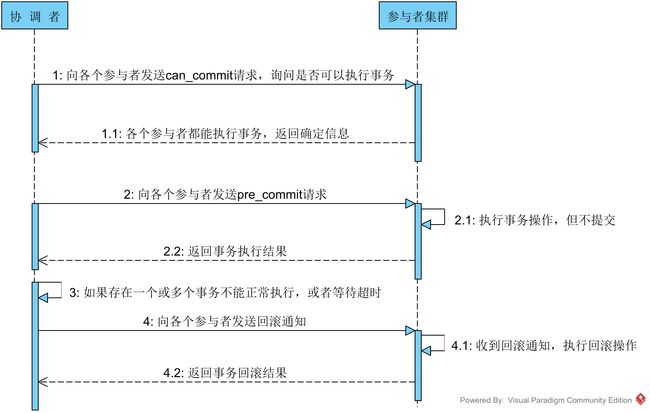
在本阶段如果因为协调者或网络问题,导致参与者迟迟不能收到来自协调者的commit或rollback请求,那么参与者将不会如两阶段提交中那样陷入阻塞,而是等待超时后继续commit。相对于两阶段提交虽然降低了同步阻塞,但仍然无法避免数据的不一致性。
在分布式数据库中,如果期望达到数据的强一致性,那么服务基本没有可用性可言,这也是为什么许多分布式数据库提供了跨库事务,但也只是个摆设的原因,在实际应用中我们更多追求的是数据的弱一致性或最终一致性,为了强一致性而丢弃可用性是不可取的。