Selenium Practice——a crawl to Taobao
Crawl Practice
- Preface
- Content
- Human-Like Input
- Hide Machine
- Login
- Find The Target Store
- Orientation
- Page Jump
- Problems Caused By Frame or iFrame
Preface
- The purpose of this article is to communicate and learn, and the original intention of creating a project stems from actual needs. Code development, but please use it correctly.
- The website changes and updates quickly without timeliness
- Tool: Pycharm, Chrome browser
- Module: time, random, selenium
Content
Login Taobao and send messages you want to specific online store in Taobao.
Human-Like Input
The login anti crawling mechanism of Taobao is strict. If the speed of entering an account password is too fast, it will be immediately recognized as a robot. At this time, it will give you a verification code, and when it gives you a verification code, it basically determines that you are a robot. At this time, it is basically useless, and readers can try it on their own.
In summary, the simplest idea we need for a * * “human like” * * input method is to input at random intervals. In order to be more human like, there is even a chance of backspacing to simulate the scenario of a human typing error. Here, you can actively utilize your intelligence and think about how to be a person. One blogger used the concept of physical acceleration, which inspired me. In the future, I may record my real typing speed for further simulation.
def human_login(elem, login_info):
# elem 是通过开发者工具定位到的元素
# login_info 是要输入的文本内容
info_len = len(login_info)
if info_len < 1:
print("Invalid LoginInfo")
return
i = 0
while i < info_len:
choice = random.randint(1, 5)
if choice == 5 and random.randint(0, 5) > 3:
if i == 0:
continue
else:
# 模拟打错退格
elem.send_keys(Keys.BACKSPACE)
i -= 1
else:
elem.send_keys(login_info[i])
i += 1
time.sleep(0.1 + choice * 0.02)
Hide Machine
Generally, using webdriver to start a browser is not a hassle. Typically, we write as follows:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.taobao.com/')
But in order to carry out the following crawler work smoothly, we hope our automatic test script is more hidden from the server.
Selenium’s startup of Chrome is basically similar to the real environment, but there are still some variables that are different and need to be noted.
Some websites recognize crawlers through these parameters window.navigator. webdrive with a value of undefined or false is a normal browser, and returning true indicates that Selenium is used to simulate the browser.
Enter window.navigator.webdrive on the console of the developer tool(F12) to see the current value.
The improved code is as follows:
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get('https://www.taobao.com/')
Login
Taobao’s anti crawling is very strict, my suggestion is to sleep generally.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import random
def human_login(elem, login_info):
info_len = len(login_info)
if info_len < 1:
print("Invalid LoginInfo")
return
i = 0
while i < info_len:
choice = random.randint(1, 5)
if choice == 5 and random.randint(0, 5) > 3:
if i == 0:
continue
else:
elem.send_keys(Keys.BACKSPACE)
i -= 1
else:
elem.send_keys(login_info[i])
i += 1
time.sleep(0.1 + choice * 0.02)
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# 进入淘宝官网
driver.get('https://www.taobao.com/')
driver.maximize_window()
# 定位到登录键
elem = driver.find_element("class name", "h")
elem.click()
time.sleep(2)
# 定位元素到账号一栏
elem = driver.find_element("id", "fm-login-id")
# 开始“类人”输入账号
human_login(elem, "your name")
# 睡一会
time.sleep(0.5)
# 定位元素到密码一栏
elem = driver.find_element("id", "fm-login-password")
# 开始“类人”输入密码
human_login(elem, "your password")
# 按下 enter 键
elem.send_keys(Keys.RETURN)
# 再睡会
# 这里睡的时间那么长,是为了防止出现验证界面(系统自己检测成功后会自动跳转)
time.sleep(3)
这里的定位非常简单,以账号一栏为例
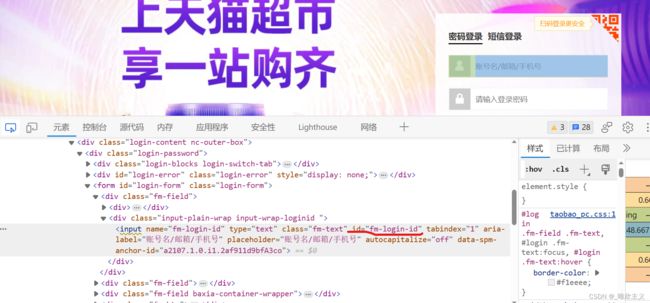
Find The Target Store
# 这里的定位很简单
elem = driver.find_element("id", "q")
human_login(elem, u"店铺名")
time.sleep(0.2)
elem.send_keys(Keys.RETURN)
I didn’t directly use the dropdown store (the code was always incorrect, but later discovered that it might be a frame issue), but instead chose to take a detour and find the target store in the search results

Just give an example: after entering the search results interface
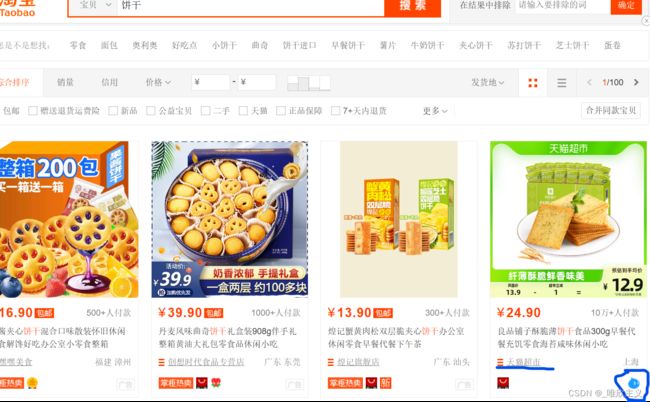
You can see that we can choose to enter the store or simply click the customer service button. At this point, my article is almost over, but there are a few questions that are still worth paying attention to.
Orientation
Here is my location code and I have a few points to mention:
try:
elem = driver.find_element("xpath", '//*[@id="root"]/div/div[2]/div[1]/div[1]/div[2]/div[3]/div/div[3]'
'/a/div/div[3]/div[1]/a')
elem.click()
except:
try:
elem = driver.find_element("xpath", '//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[3]/div[2]/'
'div[3]/div[1]/a/span[2]')
elem.click()
except:
print("Xpath Fail")
time.sleep(20)
- Common try exception statements: not only ensure smooth code execution, but also facilitate developers in locating bugs
- Positioning ability: In the previous steps of logging in and searching for products, our positioning is very simple. We only need to use id or class name to locate, such as:
elem = driver.find_element("class name", "h")
elem = driver.find_element("id", "fm-login-id")
However, when it comes to the later interface, it often becomes more complex. We urgently need to use XPath with stronger positioning capabilities for positioning. XPath is relatively difficult to parse HTML, and the formula is not clearly written. However, ordinary developer tools greatly simplify this difficulty by finding the location and right-clicking: Copy as XPath, like this:
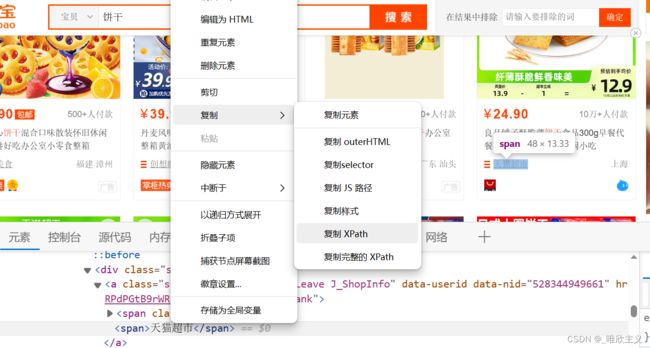
you can see that it’s simple and convenient
- Correct positioning: Taking the biscuit product just now as an example (not an advertisement, I haven’t eaten it either)

If you are reading not span, instead of a or div on the outer layer, the click events you bind will often become invalid.
Page Jump
When you enter the customer service page or a new page, you start your positioning work again and eagerly run the newly located code. It’s puzzling why you always report an error saying that you can’t find the element, even though your positioning is correct?
The reason is: Your search is still stuck on the old page, you need to switch to the target page——the new page first
windows = driver.window_handles
driver.switch_to.window(windows[-1])
# 睡觉是好习惯,新的页面加载需要时间,有时候跳转新的
# 界面后立马操作也会出现元素不存在的情况
time.sleep(2)
Problems Caused By Frame or iFrame
After entering the customer service page, remember the page jump issue. After handling the page jump, you are proficient in positioning work (input in the positioning input box), and once again run the code that has just been located with great anticipation. Once again, it is puzzling why you always report an error saying that the element cannot be found, even though your positioning is correct?
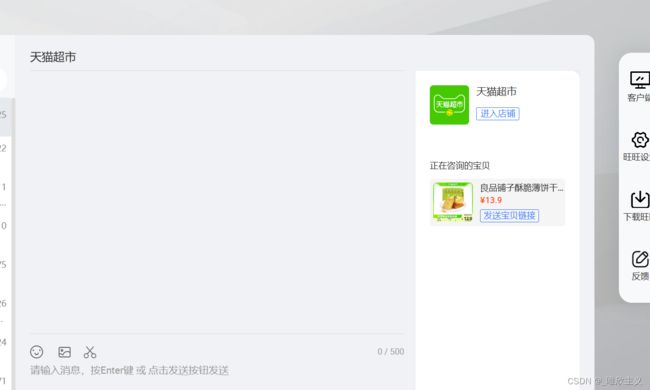
It may be caused by Embedded HTML. I have also encountered this kind of problem for the first time. Here are some answers from others.
In HTML, there are three types of frame tags: frameset, frame, and iframe.
For frameset, it is no different from other ordinary tags and can be positioned normally.
And frame and iframe belong to a special type, which will contain an embedded HTML document inside.
When using Selenium to open a webpage, it does not include embedded HTML documents.
If you need to manipulate elements within an embedded HTML document, you must switch the * * operation scope * * to the embedded HTML document
That is to say, due to the presence of embedded HTML, we cannot search for hidden HTML code, so we need to switch to the relevant frame/iframe for localization.
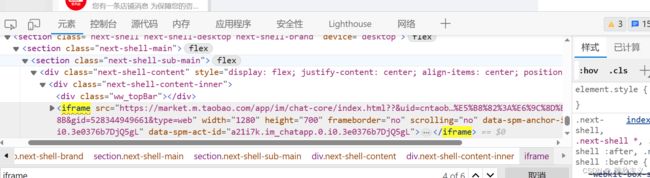
Open the developer tool, search for iframes in the elements, and check one by one to find the one that contains our element. Then, copy the familiar XPaths and modify the code as follows:
# 先定位到 iframe元素
frame_element = driver.find_element("xpath", '//*[@id="ice-container"]/section/section/section/div/div/iframe')
driver.switch_to.frame(frame_element)
# 定位工作略
At this point, we have solved most of the problems encountered during the process of logging into Taobao and sending information to designated stores.