python学习:爬虫爬取微信公众号数据
spider
-
- 一、获取链接
- 二、爬取文章标题、文章链接、文章正文、时间
- 三、爬取阅读量与点赞数
参考: https://blog.csdn.net/qq_45722494/article/details/120191233
一、获取链接
1、登录微信公众平台
- 这里我注册了个微信公众号
- 点击图文消息

- 点击超链接

- 搜索要爬取的公众号名称
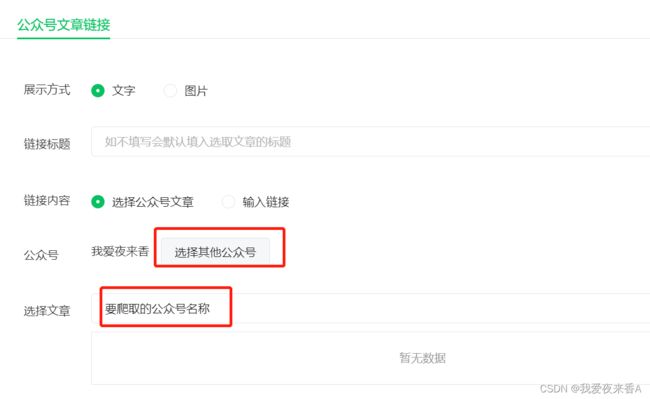
- 获取appmsg?action…

二、爬取文章标题、文章链接、文章正文、时间
上述第一步可以获取到cookie、fakeid、token、user_agent等,编辑成wechat.yaml文件,如下所示
cookie : xxxx
fakeid : xxxx
token : xxxx
user_agent: xxxx
代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
import json
import requests
import time
import random
import yaml
import datetime
from bs4 import BeautifulSoup
def main():
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
with open("app_msg_list.csv", "w", encoding='utf-8') as file:
file.write("seq,type,company,field,title,link,context,time\n")
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1, 10))
resp = requests.get(url, headers=headers, params=params, verify=False)
print(resp.text)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
text = getText(item['link'])
date = datetime.datetime.fromtimestamp(item['create_time'])
info = '"{}","{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], text, date)
with open("app_msg_list.csv", "a", encoding='utf-8') as f:
f.write(info + '\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
def getText(url):
response = requests.get(url)
# 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 获取文章正文
article = soup.find('div', {'class': 'rich_media_content'})
if article is not None:
article = article.get_text()
else:
article = ""
return article
if __name__ == '__main__':
main()
三、爬取阅读量与点赞数
- 因为阅读量与点赞量是在上面抓取的链接中是没有的,必须要通过抓包获取一些参数
1、使用fiddler或Charles抓包
- 点击微信公众号
- 获取getappmsgext?..

2、获取包中的一些参数:
key:
uin:
pass_ticket:

3、代码实现
# 获取阅读数和点赞数
import requests
import time
def getMoreInfo(link):
# 获得mid,_biz,idx,sn 这几个在link中的信息。
mid = link.split("&")[1].split("=")[1]
idx = link.split("&")[2].split("=")[1]
sn = link.split("&")[3].split("=")[1]
_biz = link.split("&")[0].split("_biz=")[1]
#该4个参数,需要自己从抓的包里面的请求头里面去获取,
uin = xxxxxx
pass_ticket = xxxxxx
key = xxxxxx
# 目标url
url = "http://mp.weixin.qq.com/mp/getappmsgext"
# 添加Cookie避免登陆操作。Cookie需要自己从抓的包里面去获取
phoneCookie = "rewardsn=; wxtokenkey=777; wxuin=1700579082; lang=zh_CN; appmsg_token=1130_Tml%2BYcZMk8oJAMuu6NYwpkTS-XtM-kz5LNJQv6N9AvC_sFfoc6dwKaHOYy4vNTEnvq7_bc6-HDgxo9mk; devicetype=Windows10x64; version=63030532; pass_ticket=FHAPWEyH4En5JI9SyHXcUtAfV1pxn/W/BMXpVnaOGQDhbD709+wejbXJCVLDGjvz; wap_sid2=CIqO86oGEooBeV9IUGFHMElKRUJpdENjbGd0QWxxd0RDUHEwWm5IV1JTMlFDVExncGVuYnh1bmRwSUpxVHV6U1hCbG5JQXE1UTh5V3FlOUh1V0JPeUxwcFVrR3V0REZ0NGJGRHB2VVpqcS1Md3J6WHlsY3VPQzkzOHVWTlk4NDlmTFFjOFgzdDgwVGJrY1NBQUF+MOO54YkGOA1AAQ=="
#这里的"User-Agent"最好为手机浏览器的标识
headers = {
"Cookie": phoneCookie,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.901.400 QQBrowser/9.0.2524.400"
}
# 添加data,`req_id`、`pass_ticket`。
data = {
"is_only_read": "1",
"is_temp_url": "0",
"appmsg_type": "9",
'reward_uin_count': '0'
}
#根据获取到的参数,构造PSOT请求的params
params = {
"__biz": _biz,
"mid": mid,
"sn": sn,
"idx": idx,
"key": key,
"pass_ticket": pass_ticket,
"appmsg_token": appmsg_token,
"uin": uin,
"wxtoken": "777",
}
#post请求提交后,将返回的respone转为json
json = requests.post(url, headers=headers, data=data, params=params).json()
#获取到阅读数
read_num=json['appmsgstat']['read_num']
# 获取到点赞数
like_num=json["appmsgstat"]["old_like_num"]
print(read_num,like_num)
#随便某一篇文章的url地址
url="http://mp.weixin.qq.com/s?__biz=MjM5Nzc5OTcxNA==&mid=2651014142&idx=1&sn=5f00452e553dad1f0621ca82b1a674bd&chksm=bd2391b38a5418a5dbcdeacbd738289fc8c421c7f0b125b97be21f65463b87d12d1c9ce75436#rd"
getMoreInfo(url)