python实现最大匹配分词方法
问题描述
- 设置词长与词表,以及待分词的字符串;
- 实现基于最大匹配的分词方法;
- 列出分词过程,包括:步骤、s1、s2、w。
- 得到最终分词结果。
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 问题描述
- 最大匹配法
-
- 1、设置词长与词表,以及待分词的字符串
- 2、编写正向最大匹配法函数
- 3、编写逆向最大匹配法函数
- 实验截图
- 问题
最大匹配法
基于规则的分词是一种机械分词方法,需要不断维护和更新词典,在切分语句时,将语句的每个字符串与词表中的每个次进行逐一匹配,找到则切分,找不到则不予切分。按照匹配方法来划分,主要有正向最大匹配、逆向最大匹配以及双向最大匹配。
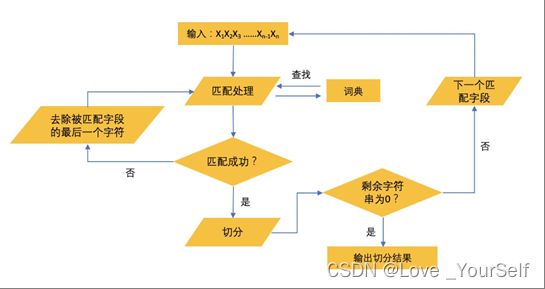
正向最大匹配先是从左向右取待切分汉语句的m个字符作为匹配字段,m为机器词典中最长词条的字符数。然后查找机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。 若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的m个字符(m为词典中最长词数作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
如图是最大匹配法的一般步骤:
1、设置词长与词表,以及待分词的字符串
首先在使用最大匹配法分词的时候,要先设置最大的词长以及要先建立好将要使用的词表,在这里因为词表是给出的,所以这个实验可以直接通过读取给定的词表来获得实验要使用到的词表。在这里我使用的带分词的字符串为“乒乓球拍卖完了。”,这个在人工分词的时候尚且会出现歧义,我在这里使用正向和逆向两种方法来测试最大匹配算法的分词结果会有什么结果。然后在这里我创建了一个读取词表、构建词典以及一些完成初始化工作功能的函数:
def init():
file = open(file='WordList.txt', mode='r', encoding='utf-8')
str1 = '乒乓球拍卖完了。'
text = file.read() # 读取词库
dic = text.split('\n') # 构造词典
max_chars = 4
print('字典中的最大字符长度为:' + str(max_chars))
2、编写正向最大匹配法函数
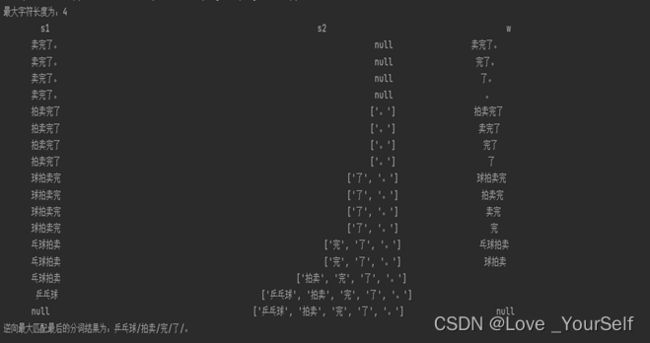
从带切分子串中取前max_chars个字符,比较是否在词表中,若无该子串,则去掉子串最后一个字符,继续比较;若只剩一个汉字时仍无法匹配,则将其单独成词,并且在正向最大匹配算法中实现打印每一次的处理过程,列出分词过程,包括:步骤、s1、s2、w。正向/逆向最大匹配法不能保证正确处理交集型歧义,例如实验中的“乒乓球拍/卖/完了”和“乒乓球/拍卖/完了”两个切分结果就属于交集型歧义问题,分词的结果与切分方向有关。
正向最大匹配法:
def MM(sentence, max_chars):
words = [] # 分词结果
n = 0
print('%10s' % 's1', end='')
print('%60s' % 's2', end='')
print('%40s' % 'w')
while n < len(sentence):
matched = 0
for i in range(max_chars, 0, -1):
s = sentence[n: n + i]
print('%10s' % sentence[n: n + max_chars], end=' ')
if s in dic:
words.append(s)
matched = 1
n = n + i
if len(words) == 0:
print('%60s' % 'null')
else:
print('%60s' % words)
break
if len(words) == 0:
print('%60s' % 'null', end=' ')
else:
print('%60s' % words, end=' ')
print('%20s' % s)
if not matched:
words.append(sentence[n])
n = n + 1
print('%10s' %'null', end=' ')
print('%60s' % words, end=' ')
print('%20s' % 'null')
res = str(words)
res = res.replace('\'', '')
res = res.replace('[', '')
res = res.replace(']', '')
res = res.replace(' ', '')
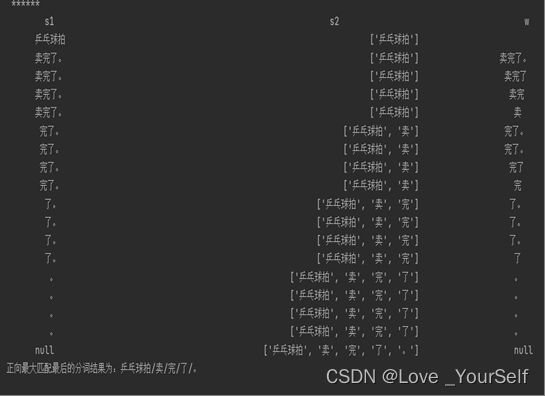
print('正向最大匹配最后的分词结果为:' + res.replace(',', '/'))
3、编写逆向最大匹配法函数
与正向同理,只是在取词的时候从子串后边开始取,且当不匹配时去掉子串前边第一个字符,继续比较,并且在逆向最大匹配算法中实现打印每一次的处理过程,列出分词过程,包括:步骤、s1、s2、w。正向/逆向最大匹配法也不能保证正确处理组合型歧义,例如 “法案”、“马上”,可单独成词也可分开理解,这与词库中是否有这几个词有关系。正向/逆向最大匹配法对汉字进行切分依靠的是词库,而不是语义,因此它无法根据语义对句子中的词语进行判断,从而无法保证正确切分。
逆向最大匹配法:
def RMM(sentence, max_chars):
words = [] # 分词结果
n = len(sentence)
print('%10s' % 's1', end='')
print('%60s' % 's2', end='')
print('%40s' % 'w')
while n > 0:
matched = 0
for i in range(max_chars, 0, -1):
if n - max_chars < 0:
st = 0
else:
st = n - max_chars
s = sentence[st: n]
print('%10s' % s, end=' ')
if n - i < 0:
st = 0
else:
st = n - i
s = sentence[st: n]
if s in dic:
words.insert(0, s)
matched = 1
n = n - i
if len(words) == 0:
print('%60s' % 'null')
else:
print('%60s' % words)
break
if len(words) == 0:
print('%60s' % 'null', end=' ')
else:
print('%60s' % words, end=' ')
print('%20s' % sentence[st: n])
if not matched:
words.insert(0, sentence[n-1])
n = n - 1
print('%10s' %'null', end=' ')
print('%60s' % words, end=' ')
print('%20s' % 'null')
res = str(words)
res = res.replace('\'', '')
res = res.replace('[', '')
res = res.replace(']', '')
res = res.replace(' ', '')
print('逆向最大匹配最后的分词结果为:' + res.replace(',', '/'))
实验截图
最大匹配法不能正确切分未登陆词。因为最大匹配法按照词库内容进行切分,不是按照语义来进行判断,而未登陆词没有被收录到词库中,因此无法正确被切分出来。
逆向最大匹配算法的结果图:
正向最大匹配算法的结果图:
问题
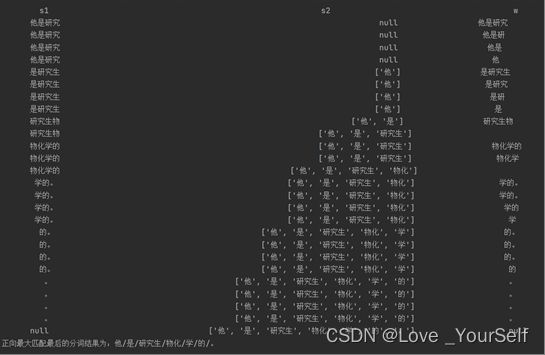
当处理字符串“他是研究生物化学的。”的时候,正向和逆向最大匹配算法出现了不一致
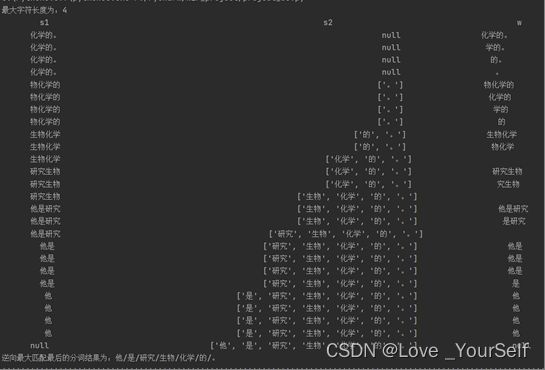
正向最大匹配算法为他/是/研究生/物化/学/的/。逆向最大匹配最后的分词结果为:他/是/研究/生物/化学/的/。
虽然使用规则分词的分词准确率看上去非常高,但是规则分词有几个特别大的问题:
① 不断维护词典是非常烦琐的,新词总是层出不穷,人工维护费时费力;
② 随着词典中条目数的增加,执行效率变得越来越低;
③ 无法解决歧义问题。
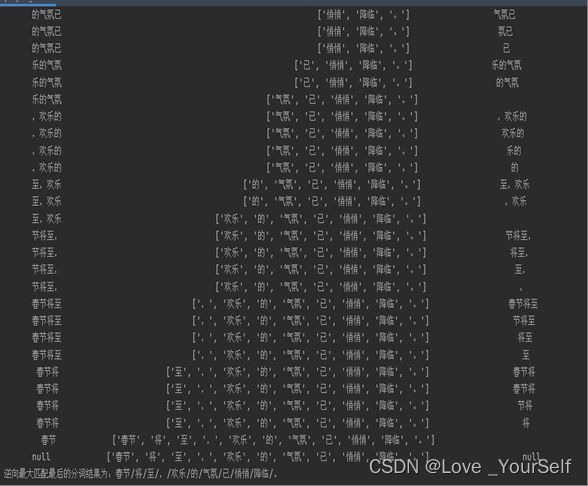
对于处理“春节将至,欢乐的气氛已悄悄降临。”,两种方法的处理结果又是一致的,最后的分词结果为:春节/将/至/,/欢乐/的/气氛/已/悄悄/降临/。,所以基于规则的分词一般都较为简单高效,但是词典的维护面临很庞大的工作量。在网络发达的今天,网络新词层出不穷,很难通过词典覆盖所有词。另外,词典分词也无法区分歧义以及无法召回新词。