[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset
ACL 2019 | DocRED: A Large-Scale Document-Level Relation Extraction Dataset
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第1张图片](http://img.e-com-net.com/image/info8/127936eaf7f14c5fb77f200da08bec51.jpg)
- 论文:https://arxiv.org/abs/1906.06127
- 代码:https://github.com/thunlp/DocRED
- Leaderboard:https://competitions.codalab.org/competitions/20717
DocRED数据集是由清华大学整理的文档级关系抽取数据集,近几年的文档级关系抽取的最新工作基本都是将此数据集作为主要的实验对象。
摘要
文档中的多个实体通常表现出复杂的句间关系,现有的关系提取 (RE) 方法通常侧重于提取单个实体对的句内关系,因此无法很好地处理这些问题。为了加速对文档级 RE 的研究,我们引入了 DocRED,这是一个由 Wikipedia 和 Wikidata 构建的新数据集,具有三个特点:(1)DocRED 同时标注了命名实体和关系,是最大的纯文本文档级关系抽取人工标注数据集; (2) DocRED需要阅读文档中的多个句子,通过综合文档的所有信息来提取实体并推断它们之间的关系; (3) 除了人工标注的数据,我们还提供大规模的远程监督数据,这使得 DocRED 可以用于监督和弱监督场景。为了验证文档级 RE 的挑战,我们实施了最近最先进的 RE 方法,并在 DocRED 上对这些方法进行了全面评估。实证结果表明,DocRED 对现有的 RE 方法具有挑战性,这表明文档级 RE 仍然是一个悬而未决的问题,需要进一步努力。基于对实验的详细分析,我们讨论了未来研究的多个有前景的方向。
为了加速文档级关系抽取的研究,本文提出了一个新的文档级关系抽取数据集——DocRED,这个数据集有三大特点,并且通过实验验证了DocRED 对现有的关系抽取方法具有挑战性,文档级关系抽取值得进一步去研究。
一、 简介
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第2张图片](http://img.e-com-net.com/image/info8/53e299f67b094b378b9d5a6814a23b80.jpg)
每个文档中的样例中,标注有命名实体识别(named entity mentions)、共指信息(coreferance information)、句内和句间关系(intra- and inter-sentence relations)、支持证据(supporting evidence)。在文档中大量关系事实==(什么是关系事实?)==是通过多个句子来表达的。
句子1-(Stockholm, the capotal of, Sweden) + 句子4-(Riddarhuset, locate in, Stockholm) → \to → (Riddarhuset, country, Sweden).该过程需要阅读和推理文档中的多个句子,根据本文从维基百科文档中抽取的人工注释语料库统计,至少有 40.7% 的关系事实只能从多个句子中提取出来,这是不可忽略的。因此,有必要将 RE 从句子级别推进到文档级别。
现有的一些文档级关系抽取数据集:
非人工标注:Quirk and Poon (2017) and Peng et al. (2017)是远程监督生成的数据集,没有人工标注,噪声大。
特定领域:BC5CDR(Li et al,2016)是一个人工注释的文档级RE数据集,由1500个PubMed文档组成,这些文档在生物医学的特定领域仅考虑“化学诱导的疾病”关系,使其不适合开发通用的文档级RE的目的方法。
特定方法:Levy等人(2017)通过使用阅读理解方法回答问题从文档中提取关系事实,其中问题从实体关联对转换。由于这个工作中提出的数据集是针对特定方法量身定制的,因此它也不适用于文档级RE的其他潜在方法
存在各种问题,所以提出了DocRED
即现有的文档级 RE 数据集要么只有少量手动注释的关系和实体,要么显示来自远程监督的嘈杂注释,要么服务于特定领域或方法。为了加速文档级RE的研究,我们迫切需要一个大规模的、人工标注的、通用的文档级RE数据集。
DocRED是由维基百科和维基数据构建而成的大规模人工标注的通用文档级关系抽取数据集,有以下特点:
- DocRED 在 5, 053 个维基百科文档上包含注释的 132, 375 个实体和 56, 354 个关系事实,使其成为最大的人工注释文档级 RE 数据集。
- 由于DocRED中至少有40.7%的关系事实只能从多个句子中提取,DocRED需要阅读文档中的多个句子,通过综合文档的所有信息来识别实体并推断它们之间的关系。这将 DocRED 与那些句子级别的 RE 数据集区分开来。
- 我们还提供大规模的远程监督数据来支持弱监督的RE研究。
为了评估 DocRED 的挑战,本文实施了最近最先进的 RE 方法,并在各种设置下对 DocRED 进行了彻底的实验。实验结果表明,现有方法在 DocRED 上的性能显着下降,表明文档级 RE 该任务比句子级 RE 更具挑战性,仍然是一个悬而未决的问题。此外,对结果的详细分析还揭示了多个值得追求的有前途的方向。
二、 数据收集
数据集构建的最终目标:包含命名实体识别、实体共指、所有实体对的关系和关系实例的支持证据的人工标注数据和大规模远程监督数据的数据集。
2.1 人工标注数据收集
(1)为维基百科文档生成远程监督标注。
(2)标注文档中提及的所有命名实体和共指信息。
(3)将命名实体提及链接到维基数据项。
(4)标签关系及相应的支持证据。
根据ACE 注释过程其中(2)、(4)步都需要对数据进行三次迭代:(1) 使用命名实体识别 (NER) 模型生成命名实体,或使用远程监督和 RE 模型生成关系推荐。 (2) 人工更正和补充建议。 (3) 审查并进一步修改第二遍的注释结果,以提高准确性和一致性。为了确保注释者得到良好的训练,采用了有原则的训练程序,并且要求注释者在注释数据集之前通过测试任务。并且只有经过精心挑选的有经验的标注者才有资格进行第三遍标注。
使用维基百科文档多种的介绍部分作为语料库(corpus),因为它们通常是高质量的并且包含大部分关键信息。
而维基数据是与维基百科紧密集成的大规模知识库,语料库的文本和知识库之间是强对齐的。
We use the 2018-5-24 dump of English Wikipedia and 2018-3-20 dump of Wikidata.
Stage 1: Distantly Supervised Annotation Generation
为维基百科文档生成弱监督标注
- 使用 spaCy 实现NER;
- 将这些提及的命名实体链接到维基数据的数据项,合并其中具有KB id的命名实体提及;
- 查询Wikidata标记文档中每个合并的命名实体对之间的关系。
长度小于128字的文档被丢弃。为了鼓励推理,我们进一步丢弃包含少于4个实体或少于4个关系实例的文档
输入:维基百科文档、维基数据数据项
输出:107,050个具有远程监督标签的文档,其中我们随机选择5053个文档和最常见的96个关系进行人工注释。
Stage 2: Named Entity and Coreference Annotation
- 人工注释人员首先审查、更正和补充stage 1中生成的命名实体提及建议,然后合并那些引用相同实体的不同提及,这提供了额外的共指信息。
生成的中间语料库包含各种命名实体类型,包括不属于上述类型的人员、位置、组织、时间、数量和其他实体的名称。
输入:stage 1中的命名实体提及建议
输出:修正后的实体提及和共指信息
Stage 3: Entity Linking
- 将每个提到的命名实体链接到多个Wikidata项,以便为下一阶段提供远程监督的关系建议。
- 特别地,数字和时间是语义匹配的。
输入:命名实体和维基数据项
输出:关系建议
Stage 4: Relation and Supporting Evidence Collection.
关系和支持证据的注释基于阶段2,并面临两个主要挑战。第一个挑战来自文档中大量的潜在实体对。一方面,考虑到文档中潜在实体对的数量是实体数量的二次元数(平均19.5个实体),穷竭地标记每个实体对之间的关系会导致繁重的工作量。另一方面,文档中的大多数实体对不包含关系。第二个挑战在于我们的数据集中存在大量细粒度关系类型。因此,注释者从头开始标记关系是不可行的。通过为人工注释人员提供来自RE模型的建议,以及基于实体链接的远程监督(阶段3)来解决这个问题。 → \to →为了缓解标注压力,说明提供给人工注释人员哪些关系建议
- 平均而言,我们建议每个文档从实体链接获得19.9个关系实例,从RE模型获得7.8个关系实例作为补充。我们要求注释人员检查建议,删除不正确的关系实例并补充遗漏的实例。我们还要求注释者进一步选择所有支持保留关系实例的句子作为支持证据。保留的关系必须体现在文件中,而不依赖于外部世界的知识。最后,从实体链接中保留57.2%的关系实例,从正则模型中保留48.2%的关系实例。
输入:关系建议
输出:关系实例、支持证据
2.2 远程监督数据收集
从106926个文档中删除了5053个人工注释文档,并使用剩下的1010873个文档作为远程监督数据的语料库。
- 为了确保远程监督数据和人类注释的数据共享相同的实体分布,使用BERT的双向编码器表示重新识别命名实体,该表示对第2.1节中收集的人类注释数据进行了微调,并达到了90.5%的F1分数。(命名实体识别)
- 我们通过基于启发式的方法将提到的每个命名实体链接到一个Wikidata项,该方法联合考虑目标Wikidata项的出现频率及其与当前文档的相关性。(实体链接)
- 然后我们用相同的KB id合并命名实体。(共指消解)
- 最后,通过远程监督标记每个合并实体对之间的关系。(关系建议)
三、 数据分析
将分析DocRED的各个方面,以便更深入地理解数据集和文档级RE的任务。
3.1 数据规模
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第3张图片](http://img.e-com-net.com/image/info8/56e602c616904a26ae00dcaeef4718c1.jpg)
代表性关系抽取数据集:
- SemEval-2010 Task 8:SemEval数据集来自于2010年的国际语义评测大会中Task 8:“Multi-Way Classification of Semantic Relations Between Pairs of Nominals ”,常用作全监督的关系抽取任务。下载地址、关系抽取数据集介绍。
- ACE 2003-2004:MUC会议停开后,ACE将关系抽取任务作为一个子任务从2002至2007年共持续六年。关系抽取任务也被定义的更加规范和系统。其中,获得认可的一届关系抽取任务主要是ACE-2004,其数据来源于语言数据联盟(LDC),分成广播新闻和新闻专线两部分,总共包括451和文档和5702个关系实例。ACE20014提供了丰富的标注信息,从而为信息抽取中的实体识别、指代消解和关系抽取等子任务提供基准的训练和测试语料库。关系抽取常用的数据集和工具。
- TACRED:TACRED 是一个大型关系提取数据集,包含 106,264 个示例,这些示例基于新闻专线和网络文本,来自每年TAC 知识库人口 (TAC KBP) 挑战中使用的语料库。TACRED 中的示例涵盖了 TAC KBP 挑战中使用的 41 种关系类型(例如,per:schools_attended和org:members ),或者如果没有定义关系,则标记为*no_relation 。*这些示例是通过结合来自 TAC KBP 挑战和众包的可用人工注释创建的。【数据集分析】TACRED关系抽取数据集分析(一)—— 理解单条实例、TAC 关系抽取数据集。
- FewRel:FewRel 是一个Few -shot Relation分类数据集,它包含 70, 000 个自然语言句子,表达 100 个由众包标注的关系。适用于few-shot关系分类任务的大规模监督数据集。a Few-shot Relation classification dataset、论文笔记:FewRel 2.0: Towards More Challenging Few-Shot Relation Classification。
- BC5CDR:BC5CDR语料库由 1500 篇 PubMed 文章组成,其中包含 4409 种带注释的化学物质、5818 种疾病和 3116 种化学-疾病相互作用。BC5CDR (BioCreative V CDR corpus)。
DocRED在很多方面都比现有的数据集要大,包括文档、单词、句子、实体的数量,特别是在关系类型、关系实例和关系事实方面。我们希望大规模的DocRED数据集能够推动从句子级到文档级的关系提取。
3.2 命名实体类型
DocRED涵盖了人(18.5%)、地点(30.9%)、组织(14.4%)、时间(15.8%)、数字(5.1%)等多种实体类型。它还涵盖了不属于上述类型的各种各样的实体名称(15.2%),如事件、艺术作品和法律。每个实体平均被注释1.34次。
These types include “Person (PER)”, “Organization (ORG)”, “Location (LOC)”, “Time (TIME)”, “Number (NUM)”, and “other types (MISC)”(miscellaneous entity names). The types of named entities in DocRED and their covered contents are shown in Table 9.
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第4张图片](http://img.e-com-net.com/image/info8/f1e46ee89ef645279e170998d14db542.jpg)
3.3 推理类型
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第5张图片](http://img.e-com-net.com/image/info8/9578e048e59142638cf4562357c01fb4.jpg)
我们从开发和测试集中随机抽取300个文档,其中包含3820个关系实例,并手动分析提取这些关系所需的推理类型。表2显示了我们数据集中主要推理类型的统计数据。从推理类型的统计中,我们发现:
- 大多数关系实例(61.1%)需要推理来识别,而通过简单模式识别可以提取的关系实例只有38.9%,这说明在文档级正则中,推理是必不可少的。
- 在有推理的关系实例中,大多数(26.6%)需要逻辑推理,其中两个实体之间的关系是通过桥梁实体间接建立的。逻辑推理要求RE系统能够对多个实体之间的交互进行建模。
- 相当多的关系实例(17.6%)需要共指推理,其中必须首先执行共指消解以识别丰富上下文中的目标实体;
- 相似比例的关系实例(16.6%)必须基于常识推理来识别,读者需要将文档中的关系事实与常识结合起来完成关系识别。
总之,DocRED需要丰富的推理技能来综合文档的所有信息。
3.4 句间关系实例
我们发现每个关系实例平均与1.6个支持句相关,其中46.4%的关系实例与一个以上支持句相关。此外,详细分析表明,40.7%的关系事实只能从多个句子中提取,这表明DocRED是文档级RE的一个很好的基准。我们还可以得出结论,对于文档级RE来说,多句阅读、综合和推理能力是必不可少的。(40.7%的关系事实只能从多个句子中提取和大多数关系实例(61.1%)需要推理来识别,这两个数据的差别在哪些地方?)
3.5 关系列表
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第6张图片](http://img.e-com-net.com/image/info8/27472eeffa2445309f5ef9261b3755f8.jpg)
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第7张图片](http://img.e-com-net.com/image/info8/560ec31024ff4e7a9be3beef227619c1.jpg)
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第8张图片](http://img.e-com-net.com/image/info8/f792c252567c42459387b8b74c7b3e48.jpg)
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第9张图片](http://img.e-com-net.com/image/info8/a60ca64a45db49afbc1fc82becca3665.jpg)
四、 基准设置
我们分别为监督和弱监督场景设计了两种基准测试设置。对于这两种设置,RE系统都在高质量的人工注释数据集上进行评估,这为文档级RE系统提供了更可靠的评估结果。表3显示了用于这两种设置的统计数据。
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第10张图片](http://img.e-com-net.com/image/info8/9e0c45d5d311418db6c8df1f78201961.jpg)
4.1 监督设置
使用5053个监督文档,随机分为训练集,开发集和测试集。监督设置为文档级RE系统带来了以下两个挑战:
- 第一个挑战来自执行文档级RE所需的丰富推理技巧。如第3节所示,大约61.1%的关系实例依赖于复杂的推理技能,而不是模式识别来提取,这要求正则系统超越识别单个句子中的简单模式,并对文档中的全局和复杂信息进行推理。
- 第二个挑战在于对长文档建模的高计算成本和文档中大量的潜在实体对,这与文档中的实体数量(平均19.5个实体)有关。因此,使用二次或更高计算复杂度的算法对上下文信息进行建模的 RE 系统(Sorokinand Gurevych,2017;Christopoulou 等人,2018)对于文档级 RE 来说效率不够高。因此上下文感知的效率RE系统需要进一步完善以适用于文档级RE。
4.2 弱监督设置
此设置与监督设置相同,只是训练集被远程监督数据替换(第 2.2 节)。除了上述两个挑战外,远程监督数据不可避免的错误标记问题是弱监督环境下 RE 模型的主要挑战。许多努力致力于缓解句子级 RE 中的错误标签问题(Riedel 等人,2010 年;Hoffmann 等人,2011 年;Surdeanu 等人,2012 年;Lin 等人,2016 年)。然而,文档级远程监督数据中的噪声明显多于句子级的噪声。例如,对于在人类注释数据收集的第 4 阶段(第 2.1 节)中头尾实体同时出现在同一个句子中的推荐关系实例(即句内关系实例),41.4% 被标记为不正确,而 61.8% 的句间关系实例被标记为不正确,表明错误标记问题对于弱监督文档级 RE 更具挑战性。因此,我们相信在 DocRED 中提供远程监督数据将加速文档级 RE 远程监督方法的发展。此外,还可以联合利用远程监督数据和人工注释数据来进一步提高 RE 系统的性能。
五、实验
为了评估 DocRED 的挑战,我们进行了综合实验,以评估数据集上最先进的 RE 系统。具体来说,我们在监督和弱监督基准设置下进行实验。我们还评估人类表现并分析不同支持证据类型的表现。此外,我们进行消融研究以调查不同特征的贡献。通过详细分析,我们讨论了文档级 RE 未来的几个方向。
5.1 模型
- CNN (Zeng et al., 2014) based model
- LSTM (Hochreiter and Schmidhuber, 1997) based model
- bidirectional LSTM (BiLSTM) (Caiet al., 2016) based model
- Context-Aware model (Sorokin and Gurevych, 2017)
前三个模型仅编码器不同。将文档 D D D利用CNN/LSTM/BiLSTM作为编码器得到隐藏状态向量 { h i } i = 1 n \{h_i\}^{n}_{i=1} {hi}i=1n ,然后计算实体的表示,最后预测每个实体对的关系。
对于每个词,提供给编码器的特征是其 GloVe 词嵌入(Pennington 等人,2014 年)、实体类型嵌入和共指嵌入的串联。实体类型嵌入是通过使用嵌入矩阵将分配给单词的实体类型(例如,PER、LOC、ORG)映射到向量中获得的。实体类型由人工为人工标注数据分配,由微调的 BERT 模型为远程监督数据分配。与同一实体相对应的命名实体提及项被分配了相同的实体 ID,该 ID 由其在文档中首次出现的顺序确定。实体 ID 作为共指嵌入映射到向量中。
命名实体提及的词向量由隐状态的平均得到,实体的词向量由命令实体提及的平均得到。
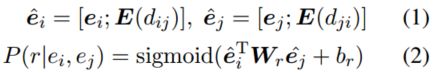
[ ⋅ ; ⋅ ] [·; ·] [⋅;⋅]表示连接, d i j d_{ij} dij和 d j i d_{ji} dji是文档中两个实体第一次提及的相对距离, E E E是嵌入矩阵, r r r是关系类型, W r W_r Wr, b r b_r br是依赖于关系类型的可训练参数。
5.2 评价指标
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第11张图片](http://img.e-com-net.com/image/info8/e247b22c1bd54d0fae5fcc0620bee139.webp)
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第12张图片](http://img.e-com-net.com/image/info8/2b766a114497489ab50b630395b73a10.jpg)
A c c u r a c y = ( T P + T N ) ( T P + T N + F P + F N ) Accuracy = \frac{(TP+TN)}{(TP+TN+FP+FN)} Accuracy=(TP+TN+FP+FN)(TP+TN)
P r e c i s i o n = T P ( T P + F P ) Precision = \frac{TP}{(TP+FP)} Precision=(TP+FP)TP
R e c a l l = T P ( T P + F N ) Recall = \frac{TP}{(TP+FN)} Recall=(TP+FN)TP
F 1 = 2 ∗ ( P r e c i s i o n ∗ R e c a l l ) ( P r e c i s i o n + R e c a l l ) F1 = \frac{2*(Precision*Recall)}{(Precision+Recall)} F1=(Precision+Recall)2∗(Precision∗Recall)
F1值就是Precision和Recall的调和平均数,如果只考虑精确度或者只考虑召回率都不能够作为评价一个模型好坏的指标,所以使用F1值来调和两者,兼容到精确度和召回率。F1值最大值为1,最小值为0,精确度越高越好,召回率越高越好,可以在0~1的这个值域内,F1越大越好。
然而,一些相关事实同时存在于训练集和开发/测试集中,因此模型可能会在训练期间记住它们之间的关系,并以一种不受欢迎的方式在开发/测试集上取得更好的性能,从而引入**评估偏差。**然而,训练集和开发/测试集之间的关系事实重叠是不可避免的,因为许多共同的关系事实可能在不同的文档中共享。因此,我们还报告了F1分数不包括训练集和开发/测试集共享的那些相关事实,表示为 Ign F1。
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。ROC曲线全称为受试者工作特征曲线(receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率为纵坐标,假阳性率为横坐标绘制的曲线。
T P R a t e = T P T P + F N TP_{Rate}=\frac{TP}{TP+FN} TPRate=TP+FNTP
F P R a t e = F P F P + T N FP_{Rate}=\frac{FP}{FP+TN} FPRate=FP+TNFP
5.3 模型性能
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第13张图片](http://img.e-com-net.com/image/info8/780f75cf121d4c20ac368ac48a959ced.jpg)
结果:
- 用人工注释数据训练的模型通常优于在远程监督数据上训练的模型。这是因为虽然通过远程监督可以很容易地获得大规模的远程监督数据,但错误标记问题可能会损害 RE 系统的性能,这使得弱监督设置变得更加困难。
- 一个有趣的例外是,在远程监督数据上训练的 LSTM、BiLSTM 和 Context-Aware 获得了与在人工注释数据上训练的那些相当的 F1 分数,但在其他指标上的分数明显较低,表明训练和训练之间的重叠实体对开发/测试集确实会导致评估偏差。因此,报告 Ign F1 和 Ign AUC 是必要的。
- 利用丰富的上下文信息的模型通常可以获得更好的性能。 LSTM 和 BiLSTM 优于 CNN,表明在文档级 RE 中建模长依赖语义的有效性。上下文感知实现了有竞争力的性能,但是,它不能显着优于其他神经模型。这表明在文档级 RE 中考虑多个关系的关联是有益的,而当前的模型不能很好地利用相互关系信息。
5.4 人类性能
为了评估人类在DocRED上的文档级RE任务中的表现,我们从测试集中随机抽取了100个文档,并要求其他众包工作人员识别关系实例和支持证据。以与第2.1节相同的方式确定的关系实例被推荐给众包工作者提供帮助。第2.1节中收集的原始注释结果作为ground truth。我们还提出了联合识别关系实例和支持证据的子任务,并设计了一个管道模型。表5显示了RE模型和人的性能。人类在文档级RE任务(RE)和联合识别关系和支持证据任务(RE+Sup)上都取得了有竞争力的结果,说明DocRED的上限性能和注释者之间的一致性都比较高。此外,RE模型的总体性能明显低于人类的性能,这表明文档级RE是一项具有挑战性的任务,并表明有足够的改进机会。
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第14张图片](http://img.e-com-net.com/image/info8/fe3afeb113be4e3f85c0650de71c3cf2.jpg)
5.5 表现和支持性证据类型
为了研究从不同类型的支持性证据中综合信息的难度,我们将开发集中的12,332个关系实例分为三个不相干的子集。
- single:6,115个关系实例只有一个支持句(表示为单句);
- mix:1,062个关系实例有多个支持句,并且实体对至少共同出现在一个支持句中(表示为混合句);
- multiple:4,668个关系实例有多个支持句,并且实体对没有共同出现在任何支持句中,这意味着它们只能从多个支持句中提取(表示为多重句)。
TP知道、FN知道,当一个模型预测了一个错误的关系时,我们不知道哪些句子被用作支持证据,因此预测的关系实例不能被归入上述子集?
因此只能计算recall,不能计算precision。
单一的召回率为51.1%,混合的召回率为49.4%,而多重的召回率为46.6%。这表明,虽然mix中的多个支持性句子可以提供互补的信息,但要有效地综合丰富的全局信息是具有挑战性的。此外,对多个句子的表现不佳表明,RE模型在提取句子间的关系方面仍有困难
5.6 特征消融
我们对 BiLSTM 模型进行特征消融研究,以研究不同特征在文档级 RE 中的贡献,包括实体类型、共指信息和实体之间的相对距离(等式 1)。表 6 显示上述特征都对性能有贡献。具体来说,实体类型由于对可行关系类型的约束而贡献最大。共指信息和实体之间的相对距离对于合成来自多个命名实体提及的信息也很重要。这表明 RE 系统在文档级别利用丰富的信息很重要。
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第15张图片](http://img.e-com-net.com/image/info8/2d7a84ae9daa42ff982dbbc70afcc1cf.jpg)
5.7 支持证据预测
我们提出了一项新任务来预测关系实例的支持证据。一方面,联合预测证据提供了更好的可解释性。另一方面,从文本中识别支持证据和推理相关事实自然是具有潜在相互促进作用的双重任务。我们设计了两种支持证据的预测方法:(1)启发式预测器。我们实现了一个简单的基于启发式的模型,该模型将所有包含头部或尾部实体的句子视为支持证据。 (2) 神经预测器。我们还设计了一个神经支持证据预测器。给定一个实体对和一个预测关系,句子首先通过单词嵌入和位置嵌入的串联转换为输入表示,然后输入 BiLSTM 编码器进行上下文表示。受 Yang 等人 (2018) 的启发,我们将 BiLSTM 在第一个和最后一个位置的输出与可训练关系嵌入连接起来,以获得句子的表示,用于预测该句子是否被用作给定关系的支持证据实例。如表 7 所示,神经预测器在预测支持证据方面明显优于基于启发式的基线,这表明 RE 模型在联合关系和支持证据预测方面的潜力。
![[ ACL 2019 ] DocRED: A Large-Scale Document-Level Relation Extraction Dataset_第16张图片](http://img.e-com-net.com/image/info8/50550ee3fa7146c195d67775820f5fac.jpg)
5.8 讨论
从以上的实验结果和分析中我们可以得出结论,文档级的RE比句子级的RE更具挑战性,需要加紧努力来缩小RE模型的性能与人类之间的差距。我们认为以下研究方向是值得关注的。
- 模型的推理能力:探索明确考虑推理的模型;
- 模型能收集和综合利用句子间的信息:设计更具表现力的模型架构来收集和综合句子间的信息;
- 模型能利用好远程监督数据集:利用远距离监督的数据来提高文档级RE的性能。
六、 相关工作
近年来为RE构建了多种数据集,极大地促进了RE系统的发展。
- 句子级关系抽取数据集
- Hendrickx 等人 (2010)、Doddington 等人 (2004) 和 Walker 等人 (2006) 构建了关系类型和实例相对有限的人工注释 RE 数据集。
- Riedel et al (2010) 通过远程监督将纯文本与 KB 对齐来自动构建 RE 数据集,但存在错误标记问题。
- Zhang et al (2017) 和 Han et al (2018b) 进一步将外部推荐与人工注释相结合,构建大规模高质量数据集。
- 文档比句子提供更丰富的信息,将研究从句子级别转移到文档级别是许多领域的流行趋势,事件提取和验证、阅读理解、情感分类、摘要和机器翻译等都是如此。对于RE来说也有一些文档级数据集,但存在一些问题。
- 通过远程监督构建的(Quirk 和 Poon,2017 年;Peng 等人,2017 年),存在不可避免的错误标签问题。
- 仅限于特定领域(Li 等人,2016 年;Peng 等人,2017 年)。
DocRED 由具有丰富信息的众包工作者构建,并且不限于任何特定领域,这使其适合训练和评估通用文档级 RE 系统。
七、 总结
为了促进RE系统从句子层面到文档层面的发展,我们提出了DocRED,一个大规模的文档级RE数据集,其特点是数据量大,要求对多个句子进行阅读和推理,并为促进弱监督的文档级RE的发展提供了远距离监督数据。实验表明,人类的表现明显高于RE基线模型,这表明未来有大量的改进机会。