LIMA:小规模监督数据指令微调
论文标题:LIMA: Less Is More for Alignment
论文链接:https://arxiv.org/abs/2305.11206
论文来源:Meta AI
一、概述
语言模型在大规模语料上以预测下一个token的方式预训练,使它们能够学习可迁移到几乎任何语言理解或生成任务的通用表示。为了实现这种迁移,已经提出了各种用于对齐语言模型的方法,主要包括在大型百万级示例数据集上的指令微调,以及从人类反馈中的强化学习 (RLHF),这些反馈是通过与人类标注员的数百万次交互收集的。现有的对齐方法需要大量的计算和专门的数据才能达到ChatGPT级别的性能。然而,我们证明,只需在1000个精心策划的训练示例上进行微调,就可以利用强大的预训练语言模型获得显著的强大性能。
我们假设对齐可以是一个简单的过程,其中模型学习与用户交互的风格或格式(style or format),以展示在预训练过程中已经获得的知识和能力。为了验证这个假设,我们策划了1000个接近真实用户提示和高质量响应的例子。我们从社区论坛(如Stack Exchange和wikiHow)中选取750个顶级问题和答案,以质量和多样性为采样依据。此外,我们手动编写了250个提示和响应的例子,以优化任务的多样性,并强调统一的响应形式,符合AI助手的风格。最后,我们以这1000个演示中训练了LIMA,也就对一个预训练的650亿参数的LLaMa模型进行指令微调。
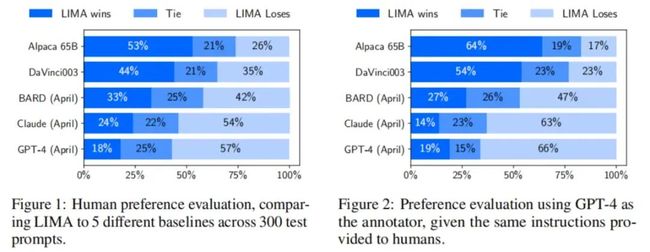
我们在300个具有挑战性的测试提示上将LIMA与当前的SOTA语言模型和产品进行比较。在一个人类偏好研究中,我们发现LIMA的性能优于OpenAI的RLHF训练的DaVinci003,以及在52000个示例上训练的Alpaca的650亿参数复现版本。尽管人们通常更喜欢GPT-4,Claude,和Bard的响应,而不是LIMA的响应,但这并非总是如此;在43%,46%,和58%的情况下,LIMA产生了相等或更可取的回应。使用GPT-4作为标准来评估人类偏好,产生了类似的结果。对LIMA响应的绝对比例分析表明,88%满足提示的要求,50%被认为是优秀的。
消融实验表明,当扩大数据量而不扩大提示的多样性时,收益会大幅减少,而优化数据质量时则会获得重大收益。此外,尽管没有任何对话例子,我们发现LIMA可以进行连贯的多轮对话,并且只需在训练集中添加30个手工制作的对话链,就可以显著提高这种能力。总的来说,这些可观的发现展示了预训练的力量,以及其相对于大规模指令调整和强化学习方法的相对重要性。
二、数据对齐
我们定义了「浅层对齐假设(Superficial Alignment Hypothesis)」:模型的知识和能力几乎完全在预训练期间学习,而对齐则教导它在与用户互动时应使用哪种子分布的格式。如果这个假设正确,对齐主要是关于学习风格或者格式,那么浅层对齐假设的一个推论是,人们可以用相当小的一组示例来充分调整预训练的语言模型。
为此,我们收集了一个包含1000个提示和响应的数据集,其中输出(响应)在风格上与彼此对齐,但输入(提示)是多样的。具体来说,我们寻求的输出是以一个有帮助的AI助手的风格。我们从各种来源策划这样的示例,主要分为社区问答论坛和手动编写的示例。我们还收集了一个包含300个提示的测试集和一个包含50个的开发集。下表显示了不同数据来源的概览,并提供了一些统计数据。
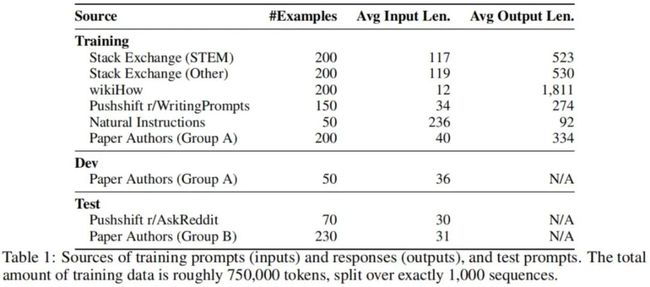 数据来源
数据来源
社区问答
我们从三个社区问答网站收集数据:Stack Exchange,wikiHow和Pushshift Reddit数据集。大体上来说,来自Stack Exchange和wikiHow的回答都与有帮助的AI助手的行为相符,因此可以自动采集,而在Reddit上得票多的回答往往带有幽默或恶搞成分,需要更人工的方式来策划符合适当风格的响应。
Stack Exchange
Stack Exchange包含179个在线交流社区(exchange),每个都专注于特定的主题,最受欢迎的是编程(Stack Overflow)。用户可以发布问题、答案、评论,并对上述所有内容进行投票(或反对)。由于活跃的社区成员和版主的存在,Stack Exchange成功维持了内容质量的高标准。我们在从Stack Exchange采样时会控制内容的质量和多样性。首先,我们将所有的社区分为75个STEM社区(包括编程、数学、物理等)和99个其他社区(英语、烹饪、旅行等);我们丢弃了5个小众社区。然后我们设置温度为来从每个集合中采样200个问题和答案,以获得不同领域的更均匀的样本。在每个社区中,我们选择评分最高且标题能够完整描述问题的问题。然后,我们选择每个问题的最佳答案,假设它得到了高度的积极评分(至少10)。为了符合有帮助的AI助手的风格,我们自动过滤掉过短(少于1200个字符)、过长(超过4096个字符)、用第一人称(“I”、“My”)写成或引用其他答案的答案(“as mentioned”、“stack exchange”等);我们还从回应中删除链接、图像和其他HTML标签,只保留代码块和列表。由于Stack Exchange的问题包含标题和描述,我们随机选择一些例子的标题作为提示,其他的描述作为提示。
wikiHow
wikiHow是一个在线wiki风格的出版物,提供超过240,000篇关于各种主题的how-to文章。任何人都可以向wikiHow投稿,文章受到严格的监管,因此几乎所有的内容都是高质量的。我们从wikiHow抽样200篇文章,先选一个类别(共19个),然后在其中选择一篇文章以确保多样性。我们用标题作为提示(例如,“How to cook an omelette?”),文章的正文作为回应。我们将通常的“This article...”开始替换为“The following answer...”,并应用一些预处理启发式方法来删除链接、图片和文本的某些部分。
Pushshift Reddit数据集
Reddit是全球最受欢迎的网站之一,用户可以在用户创建的子Reddit中分享、讨论和投票内容。由于它的巨大热度,Reddit更倾向于娱乐用户而不是帮助他们;往往有趣、讽刺的评论会比严肃、信息丰富的评论得到更多的赞。因此,我们将我们的样本限制在两个子集,r/AskReddit和r/WritingPrompts,并从每个社区中最受欢迎的帖子中手动选择示例。在r/AskReddit中,我们找到70个能够完整描述问题的提示(只有标题,没有正文),我们用这些提示作为测试集,因为最顶部的答案并不一定可靠。WritingPrompts的子Reddit包含了虚构故事的前提,其他用户被鼓励以创造性的方式完成这些故事。我们找到150个提示和高质量的响应,包括诸如爱情诗和短篇科幻小说等主题,这些我们都加入到训练集中。所有的数据实例都是从Pushshift Reddit数据集中获取的。
手工创作的样本
为了进一步扩大我们的数据多样性,本文的作者手写了提示。我们指定两组作者,A组和B组,分别根据自己或朋友的兴趣创作250个提示。我们选择A组的200个提示用于训练,另外50个提示作为保留的开发集。过滤掉一些问题提示后,B组剩余的230个提示用于测试。
我们用自己编写的高质量答案来补充200个训练提示。在编写答案时,我们试图设定一个适合于有用的AI助手的统一语调。具体来说,很多提示都会在答案本身之前以某种方式确认问题。初步实验表明,这种一致的格式通常会提高模型的性能;我们假设这有助于模型形成思维链,类似于“let’s think step-by-step”的提示。
我们还包括了13个带有一定毒性或恶意的训练提示。我们仔细地写出部分或完全拒绝该命令的回应,并解释为什么助手不会服从。测试集中也有30个类似问题的提示。
除了我们手工编写的示例,我们还从Super-Natural Instructions中抽取了50个训练示例。具体来说,我们选择了50个自然语言生成任务,如摘要、改写和风格转换,并从每个任务中选出一个随机示例。我们稍微编辑了一些示例,使其符合我们200个手动示例的风格。虽然潜在用户提示的分布可能与Super-Natural Instructions中的任务分布不同,但我们的直觉是,这个小样本增加了训练示例的整体多样性,可能增强模型的鲁棒性。
手动创建多样的提示和以统一风格编写丰富的响应是费力的。尽管一些最近的工作通过蒸馏和其他自动方式避免了手动编写,他们优先考虑数量而不是质量,但本文这项工作探索的是投资于多样性和质量的效果。
三、训练LIMA
我们按照以下方法训练LIMA(Less Is More for Alignment)。从LLaMa 65B开始,我们对我们的1,000个示例的对齐训练集进行微调。为了区分每个发言者(用户和助手),我们在每个对话的末尾引入一个特殊的end-of-turn token(EOT);这个标记扮演着和EOS结束生成的相同角色,但避免了与预训练模型可能赋予预先存在的EOS标记的任何其他含义的混淆。
我们遵循标准的微调超参数:我们使用AdamW进行15个epoch的微调,,权重衰减为0.1。不使用warm-up,我们将初始学习率设置为1e-5,并在训练结束时线性衰减到1e-6。批量大小设定为32(对于较小的模型为64),并且长于2048个token的文本会被修剪。训练时一个明显偏离常规的做法是使用残差dropout;我们遵循Ouyang等人(2022)的做法,在残差连接上应用dropout,从底层的开始,线性地将比率提高到最后一层的(对于较小的模型,)。我们发现困惑度并不与生成质量相关,因此我们在保留的50个示例开发集中手动选择在第5个到第10个epoch之间的检查点。
四、实验
 实验
实验  实验
实验  实验
实验 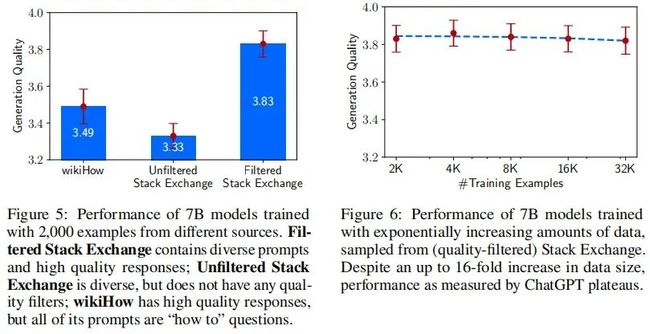 实验
实验 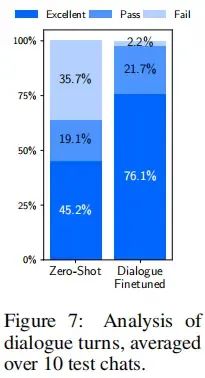 实验
实验  实验
实验