Raft 思想在架构中实践
Raft 诞生背景:
分布式存储系统通常通过维护多个副本来进行容错,提高系统的可用性。要实现此目标,就必须要解决分布式存储系统的最核心问题:维护多个副本的一致性。
首先需要解释一下什么是一致性(consensus),它是构建具有容错性(fault-tolerant)的分布式系统的基础。 在一个具有一致性的性质的集群里面,同一时刻所有的结点对存储在其中的某个值都有相同的结果,即对其共享的存储保持一致。集群具有自动恢复的性质,当少数结点失效的时候不影响集群的正常工作,当大多数集群中的结点失效的时候,集群则会停止服务(不会返回一个错误的结果)
高可用:
多副本架构是云原生的基础,也是高可用、分布式架构场景中常见的一种架构解决方案。对于应用服务、数据库、中间件服务来说高可用是一种共识追求的目标,很多公司也会有很多高可用衡量指标:
衡量指标:
-
PRO。Recovery Point Objective (RPO),是灾难(或中断)可能导致的数据(事务)丢失的最长目标时间,与数据恢复点设置有关,主要指的是业务系统所能容忍的数据丢失量,由业 务连续性规划定义。RPO不宜过长,以免数据丢失过多。
-
RTO。Recovery Time Objective (RTO) ,是灾难(或中断)后必须恢复业务流程的目标持续时间和服务级别, 主要指的是所能容忍的业务停止服务的最长时间,也就是从灾难发生到业务系统恢复服务功能所需要的最短时间周期。RTO不宜过长,以避免与业务连续性中断相关的不可接受的后果
-
SLA。Service Level Agreements (SLA)指的是与用户协商好的可容忍数据修复时长,一般以“几个9”来衡量:
-
99%或2个9:相当于每年3天15小时36分钟的停机时间。
-
99.9%或3个9:相当于每年8小时45分36秒的停机时间。
-
99.99%或4个9:相当于每年52分34秒的停机时间。
-
99.999%或5个9:相当于每年约5分钟的停机时间。
热门组件使用 Raft案例:
TIDB
简介:
TiDB 是 NewSql 一款很火的数据库,解决了 Mysql 对于海量数据的处理缺陷以及横向扩展能力(分布式),在此基础上还同时拥有 ACID 的事务特性,如果之前使用过Mysql 那么学习使用 TiDB 基本没有什么学习成本
我们重点来说说 TiDB中的 TiKV,TiDB 也是采用了存算分离架构,TiKV 就是存储层。
TiKV架构
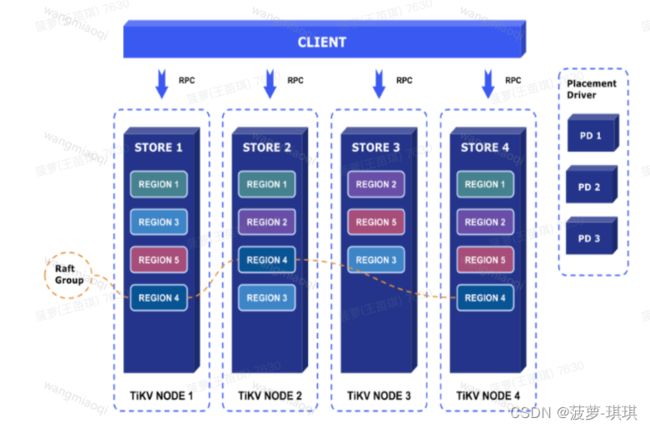
Placement Driver : Placement Driver (PD) 负责整个集群的管理调度。
Node : Node 可以认为是一个实际的物理机器,每个 Node 负责一个或者多个 Store。
Store : Store 使用 RocksDB 进行实际的数据存储,通常一个 Store 对应一块硬盘。
Region : Region 是数据移动的最小单元,对应的是 Store 里面一块实际的数据区间。每个 Region会有多个副本(replica),每个副本位于不同的 Store ,而这些副本组成了一个 Raft group。
Leader 节点的视角 Raft 副本同步
一阶段

在第一个阶段里,一份 Data 数据会被 RAFT 状态机转换为两份数据,一份数据转换为 Entries,然后落盘存储到 Disk,另一份数据转换为 Message,发送给其他 Follower 节点。
-
应用接受到请求 Data 信息
-
应用通过调用 RAFT 的 propose 接口将 Data 数据传递到 RAFT 状态机中去
-
应用调用 Ready 函数等待 从 RAFT 中获取 Ready 结构体,从 Ready 结构体中拿出 Entries 和 Message,分别进行落盘和转化为 MsgAppend 信息传递给 Follower。
-
应用还需要调用 advance 接口,来更新 RAFT 的内部状态,例如 Log index 信息,代表 Log Entries 已落盘。
二阶段
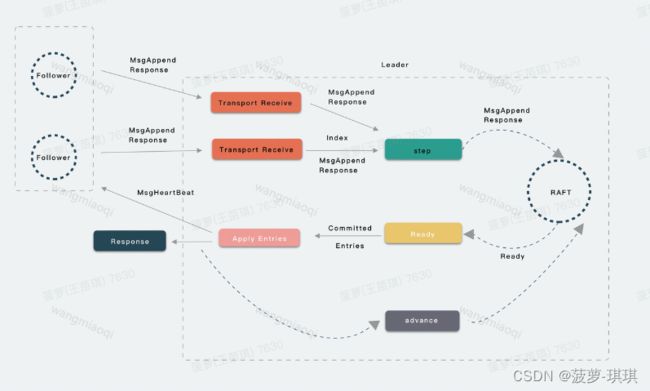
-
Follower 收到 Message 进行处理后 (例如落盘) 会将 Entries 的确认信息 MsgAppend Response 发送回给 Leader,值得注意的是这个 Message 中含有 Follower 已接收的最新的 Log Entries Index。
-
当 Leader 收到 Follower 节点的 Message 确认信息后,将会调用 step 函数将 Message 传递到 RAFT,RAFT 就会更新 Follower 的状态信息,尤其重要的是各个 Follower 的 Log Index 信息。
-
应用调用 Ready 接口后,就会将大多数 Follower 确认的 Log Entries 放到 Ready 结构体,应用就会收到已确认的 Committed Entries,可以对其进行 Apply。
-
之后依然还要调用 advance 接口,更新 RAFT 模块的状态,例如更新 Apply Index 信息,代表已提交。
-
最后,Leader 在给 Follower 发送 HeartBeat Msg 的时候,会带着 Leader 的 Committed Index,以此来告知 Follower 对应的 Log Entries 已经被提交,Follower 可以进行对应的 Apply 流程了。
RocketMQ
简介:
在 RocketMQ 4.5 版本之前,RocketMQ 只有 Master/Slave 一种部署方式,一组 Broker 中有一个 Master,有零到多个 Slave,Slave 通过同步复制或异步复制方式去同步 Master 的数据。Master/Slave 部署模式,提供了一定的高可用性。
但这样的部署模式有一定缺陷。比如故障转移方面,如果主节点挂了还需要人为手动的进行重启或者切换,无法自动将一个从节点转换为主节点。因此,我们希望能有一个新的多副本架构,去解决这个问题。
新的多副本架构首先需要解决自动故障转移的问题,本质上来说是自动选主的问题。这个问题的解决方案基本可以分为两种:
-
利用第三方协调服务集群完成选主,比如 zookeeper 或者 etcd。这种方案会引入了重量级外部组件,加重部署,运维和故障诊断成本,比如在维护 RocketMQ 集群还需要维护 zookeeper 集群,并且 zookeeper 集群故障会影响到 RocketMQ 集群。
-
利用 raft 协议来完成一个自动选主,raft 协议相比前者的优点,是它不需要引入外部组件,自动选主逻辑集成到各个节点的进程中,节点之间通过通信就可以完成选主。
多副本同步架构:

raft 协议是复制状态机的实现,这种模型应用到消息系统中就会存在问题。对于消息系统来说,它本身是一个中间代理,commitlog 的状态是系统最终的状态,并不需要状态机再去完成一次状态的构建。因此 DLedger 去掉了 raft 协议中状态机的部分,但基于 raft 协议保证 commitlog 是一致的,并且是高可用的。
副本复制流程:

在 DLedger 中,leader 向所有 follower 发送日志也是完全相互独立和并发的,leader 为每个 follower 分配一个线程去复制日志,并记录相应的复制的位点,然后再由一个单独的异步线程根据位点情况检测日志是否被复制到了多数节点上,返回给客户端响应。
短暂分区避免多主&频繁选主逻辑: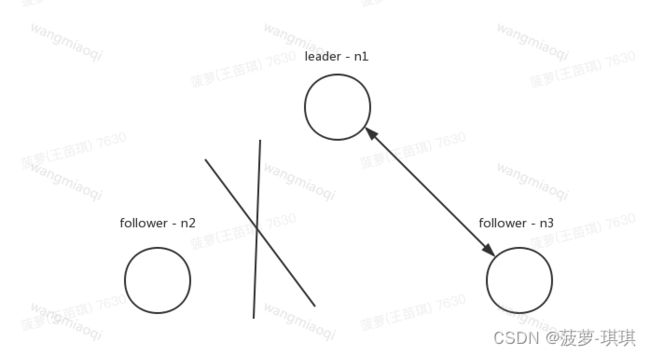
如果出现上图的网络分区,n2 与集群中的其他节点发生了网络隔离,按照 raft 论文实现,n2 会一直请求投票,但得不到多数的投票,term 一直增大。一旦网络恢复后,n2 就会去打断正在正常复制的 n1 和 n3,进行重新选举。
为了解决这种情况,DLedger 的实现改进了 raft 协议,请求投票的过程分成了多个阶段,其中有两个重要阶段:WAIT_TO_REVOTE 和 WAIT_TO_VOTE_NEXT。
WAIT_TO_REVOTE 是初始状态,这个状态请求投票时不会增加 term。
WAIT_TO_VOTE_NEXT 则会在下一轮请求投票开始前增加 term。
对于图中 n2 情况,当有效的投票数量没有达到多数量时。可以将节点状态设置 WAIT_TO_REVOTE,term 不会增加。通过这个方法,提高了 Dledger 对网络分区的容忍性。