ChatGPT 原理解析:对ChatGPT的常见误解
本文目录:
- ChatGPT 原理解析:对ChatGPT 的常见误解
ChatGPT 原理解析:对ChatGPT 的常见误解

本文是台大李宏毅教授的深度学习课程的视频笔记。李宏毅教授的机器学习课程内行的都知道,大概是全世界最好、最完整的 Deep Learning 中文学习资源。李教授在课程中广征博引学术论文,但却同时非常浅显易懂。本文是李教授2023年关于生成式AI的最新课程笔记。
大家好,我想大家都已经听说过ChatGPT了,不是吗?也许你已经听得厌烦了。但是,在这门课中,我们仍然要用ChatGPT作为开场白。首先,让我来说一下大家对ChatGPT的一些常见误解。
ChatGPT是在2022年11月30日公开的,我那时候试玩了一下,老实说,我的心情受到了极大的震撼,因为我们实验室做了很多与这种聊天机器人有关的研究,我们有很多训练end-to-end模型的经验,而且我常常与这种end-to-end的模型互动,所以我知道这类完全凭借类神经网络模型生成的结果大概有什么样的水平。但我必须说,ChatGPT的能力远比我预期的要好得多。当时的感觉就是,这好像不是AI,感觉有个人躲在背后。所以,一周之后,我录了一个视频,讲ChatGPT背后可能的原理,让大家知道ChatGPT可能是如何被训练出来的,背后仍然是科学而不是模仿。现在,距离那个时候已经过去了三个多月了。今天,我想花更长的时间跟大家讲一下ChatGPT背后可能的原理。
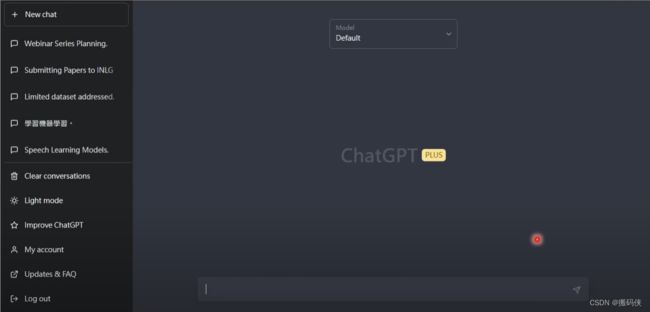
在开始之前,让我先介绍一下ChatGPT表面上看起来是如何运作的。假设有同学完全没有玩过ChatGPT,你可以趁这个机会认识一下。ChatGPT进来以后,你会看到这样一个界面,下面有一个对话框,你可以输入任何东西。比如说,你可以跟他说:“我下学期要教一门叫机器学习的课程,请帮我规划课程大纲。”ChatGPT会有问必答,你输入一个东西,它一定会给你回应。所以,ChatGPT给我的回应就是:
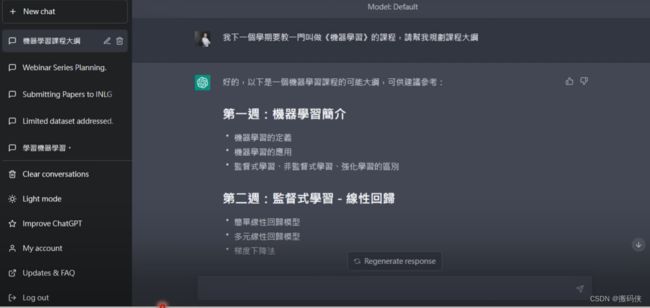
它真的给我了一个课程大纲,而且你仔细读一下会发现,这个课程大纲有条理,与我们这门课的安排也非常接近。我们先做机器学习的简介,讲机器学习的定义和应用、督导式学习、非督导式学习、强化学习,这是第一周。第二周讲监督学习,然后从这个线性回归开始讲起,与这门课的安排非常相似。而且,它可以一直拉下来,总共安排了11周的课程。
我要强调的是,ChatGPT的每次输出都不一样。所以,如果你问同样的问题,你可能会得到非常不同的答案。ChatGPT的另外一个功能是,你可以继续追问,在同一个对话里面可以有多轮的互动。比如说,我会接着问:“课程太长了,请给我三周的规划。”然后,他就会把原来的规划做一下修改,真的给了我一个三周的规划:第一周教机器学习,第二周教监督式学习,第三周教非监督式学习。一个有趣的地方是,我现在问的问题完全没有提到“机器学习”这四个字,但是显然,ChatGPT知道我之前已经问过的问题,他已经知道,在这个对话里面,我们要讨论的就是机器学习这门课的大纲。所以,在同一则对话里面,ChatGPT知道我们过去的输入。如果你要重新开始,要刷新ChatGPT的记忆,你必须要点“new chat”才行。你要点“new chat”,他才会忘记之前对答过的内容。
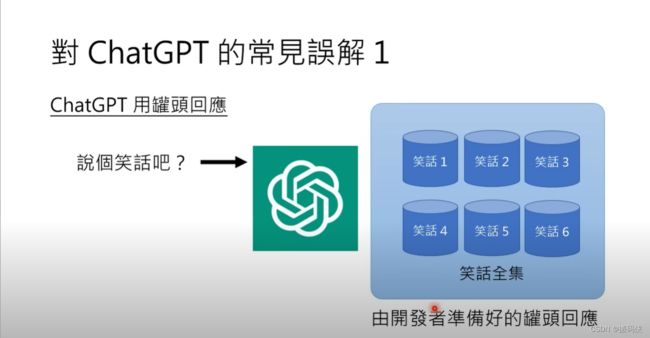
关于ChatGPT,我看到了几个常见的误解。第一个误解是ChatGPT的回答是预先准备好的固定信息。很多人可能认为当你让ChatGPT讲笑话时,他从一个笑话集合中准备了很多笑话,这些笑话都是开发人员事先准备好的,然后程序只是从这些预先编写好的笑话中随机挑选一个作为回复。实际上,ChatGPT的回答绝对不是这样的。如果你玩过就会知道,他的回答不可能是固定的信息。

那另外一个常见的误解是,大家会觉得 ChatGPT回答问题的方式是这样:你问他一个问题,比如“什么是 Diffusion Model”,然后呢,这个 ChatGPT就去网路上做一下搜寻,搜寻到好多跟 Diffusion Model 有关的文章,从这些文章里面做一下整理、重组,给我们一个答案。所以也许他的答案就是网路上抄来的句子。但是如果你把 ChatGPT给你的答案去网路上搜寻,你会发现多数时候 ChatGPT的答案在网路上都找不到一模一样的文句,甚至他常常给我们幻想出来的答案。什么叫做幻想出来的答案呢?这边直接举一个例子:
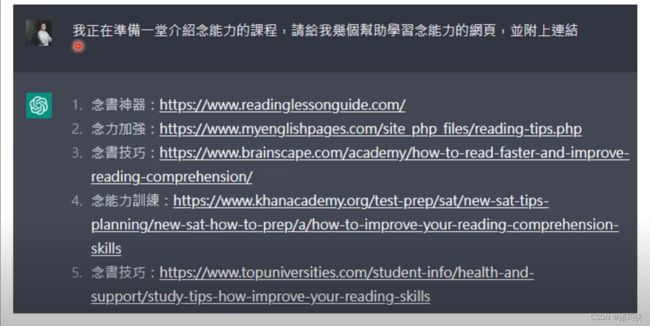
我跟 ChatGPT说,“我要准备一堂介绍念能力的课程,请给我几个学习念能力的网页,而且我这边强调要附上链接。”他确实帮我附上一些链接,但他对念能力有一些误解了,他以为念能力是念书的能力。那这个我也不怪他,你知道念能力是只有职业猎人才会的,这个念能力本来就是应该被保密的,知道吗?所以 ChatGPT不知道我也是可以接受的。但是如果你仔细看一下这些网址,看起来都像模像样,比如说“念书技巧”,这个网址是“How to read faster and improve reading comprehension”,或者是“念能力训练”,他当然不是指的是猎人的念能力,他是说“How to improve your reading comprehension skill”或“念书技巧:Study tips How to improve your reading skill”。看起来这些网址都像模像样,但是上述网址没有一个是存在的,我每个去点了,他通通没有这些网页。这些网页是 ChatGPT幻想出来的。所以他并没有去网路上做搜寻,他不是把网路的答案塞要给你看,这些答案是他自己想出来的。

事实上,OpenAI 官方也有澄清过了。有人问说,为什么 ChatGPT都会给些错的答案呢?他的答案到底能不能相信呢?那官方的第一句话就告诉你说,ChatGPT是没有联网的,他的答案并不是网路上搜寻得到的。那官方还给了一些补充,首先因为他不是网路上搜寻的答案,所以你并不能够保证他得到的是正确答案,但网路上搜寻到的答案也不一定是正确的。但是这边想要表达的意思是说,他的答案不是来自于网路上的某一篇文章,而且他对于 2021 年以后的是发生的事情所知是有限的。所以官方建议说,如果你要用 ChatGPT,他的答案不能尽信,你要自己去核实 ChatGPT的答案。那以上这个回应是来自于 OpenAI 的官网,所以 OpenAI 的官网都告诉你说,ChatGPT是没有联网的。
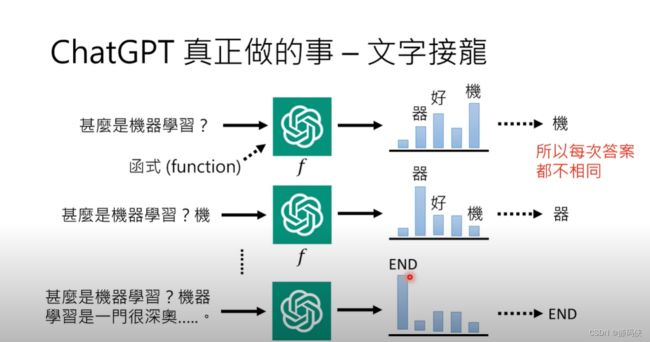
那实际上 ChatGPT真正在做的事情是什么呢?ChatGPT真正在做的事情,一言以蔽之,就是做文字接龙。因此,正确理解ChatGPT的方式就是将其视为一个函数,用小写字母"f"来代表该函数。这个函数的输入是一些东西,输出也是一些东西。ChatGPT这个函数可以有什么样的输入,会有什么样的输出呢?它可以接受一个句子作为输入,然后输出该句子后面应该接的词汇的概率。如果输入是"机器学习",那么它的输出就是一个词汇的概率分布,为每个可能的符号分配一个概率。举个例子,如果输入是"机器学习",那么下一个可能的中文词汇"机"的概率可能会比较高,而其他词汇的概率就会很低。ChatGPT输出的是这样一个概率分布,接下来会从这个概率分布中进行取样,根据这个概率分布来取样一个词汇。
举例来说,”机“的机率是最高的,因此从这个机率分布中抽取一个词汇时,”机“的机率可能比其他词汇高,但也不是不可能抽到其他词汇。这就是为什么ChatGPT每次的答案都不同的原因,因为在产生答案时,它是从一个机率分布中随机取样的。因此,每次答案都是不同的。
你可能会问,那他只能回答一个字,而不能回答一个句子,那么他是如何回答整个句子的呢?它是这样回答句子的:已经产生了“机”,这个可以接在“什么是机器学习”这个句子之后的词汇了,那么就把“机”加到原来的输入中,这样ChatGPT的输入就变成了“什么是机器学习?机”。有了这段文字以后,再根据这段文字去看看接下来应该接哪一个词汇。已经输出了“机”,因此接下来接“器”的机率可能就非常高了。”机“后面接”器“才接得顺,接其他词汇可能就不太顺,因此接“器”的机率很高。这样,你做抽样时很有可能会抽到“器”,然后你再把“器”当作输入,再把它扔给ChatGPT,让它输出下一个可以接的字。这样反复进行下去,在ChatGPT可以输出的符号里面,应该会有一个符号代表结束这件事情。当被采样出来的符号是”END”,那就代表输出结束了,这段对话完成了。ChatGPT就把所有的答案输出来给你看,所以ChatGPT真正做的事情是文字接龙。
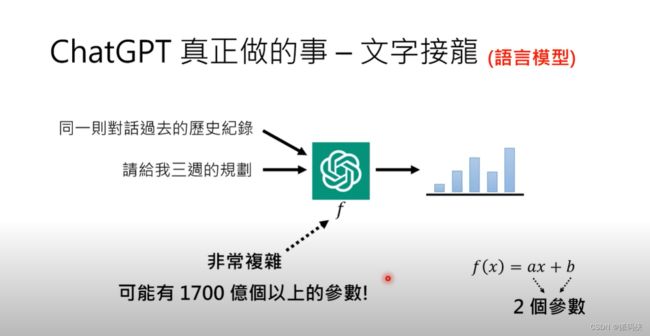
你可能还会问说,那他怎么考虑过去的对话历史记录呢?其实原理是一样的。为什么我说给我三周的规划,ChatGPT会知道说现在讨论的是机器学习而不是其他的课程呢?因为他的输入不是只有你现在的输入,还包含同一则对话里面所有过去的互动。所以同一则对话里面所有过去的互动也都会一起被输入到这个function里面,让这个function决定要接哪一个词汇。这个function非常非常的复杂,你要给一段对话,而且还要给一个历史记录,要找出要输出合适的可以接在后面的词汇,显然不是一个容易的问题。所以这个function非常非常的复杂,可能有1700亿个参数。为什么说可能而不是给一个肯定的答案呢?那是因为在ChatGPT之前,OpenAI有另外一个版本的模型叫做GPT-3,GPT-3有1750亿个参数。我想ChatGPT总不会比GPT-3少,我认为他只有可能更多不会更少,所以我这边说可能有1700亿个参数。也许事后之后 OpenAI 他们把 ChatGPT相关的论文发表以后,你会发现这个模型更大也说不定。
那到底参数是什么意思呢?假设你不知道参数是什么意思的话,那我就告诉你说,像这样的函式 F(x) = ax+b,他的参数就是两个 A 跟 B。那 ChatGPT他里面有 1700 亿个以上的参数,所以他显然非常的复杂。那你最近可能也常常听到说,有人说 ChatGPT就是一个大型的语言模型。什么叫语言模型?做文字接龙的模型就是语言模型。所以当大家称 ChatGPT为语言模型的时候,意思就是说他做的事情就是文字接龙。
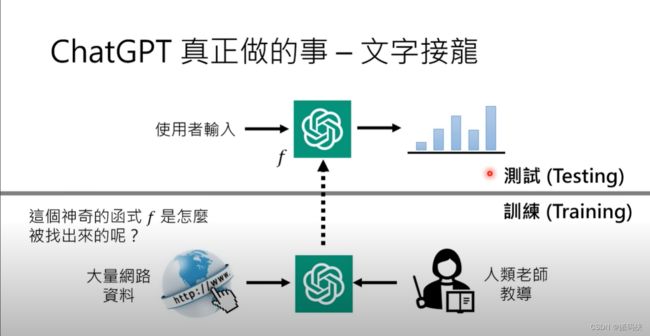
那这个我们已经知道说 ChatGPT其实就是一个函数,使用者的输入是过去对话的历史纪录,输出一个接下一个词的机率分布。那接下来要问的问题是,这个神奇又复杂的函数是怎么被找出来的呢?那如果要讲得科普一点的话,我会说这个神奇的函数是透过人类老师的教导,加上大量网路上爬到的资料所找出来的。但是讲到这边,大家又会有点困惑。刚才不是才说 a没有联网吗?怎么这边又说他是透过大量网路的资料来进行学习的?所以这边大家要注意,上半部跟下半部要切成两个部分来看。寻找函数的过程我们叫做训练,那英文叫做 training。寻找函数的时候,ChatGPT去收集网路的资料,来帮助他找到这个可以做文字接龙的函数 F。但是当这个可以做文字接龙的函数 F 被找出来以后,他就不需要联网了。当这个 F 被找出来以后,就进入下一个阶段叫做测试,英文就是 testing。当进入测试阶段时,不需要去网上搜寻资料。希望大家能够了解训练和测试之间的差异。打个比方来说,训练就像是准备考试,你可以阅读教科书或上网搜集资料来准备考试。而测试则是真实的考试,你不能翻书,也不能联网。你需要凭借脑海中记忆的东西来回答问题。ChatGPT也是一样的,它的答案是依靠脑海中的知识而产生的。这里的“脑”可能是引号中的,它不是真正的脑,而是在ChatGPT脑中的记忆产生出来的答案。