渗透学习-SQL注入篇-基础知识的学习(持续更新中)
提示:仅供进行学习使用,请勿做出非法的行为。如若由任何违法行为,将依据法律法规进行严惩!!!
文章目录
- 前言
- 一、SQL注入产生的原因
- 二、手工注入大致过程
-
- 1.判断注入点:
- 2.猜解列名
- 3.猜解能够回显数据的地方:
- 4.信息收集、注入:
- 三、注入的大致分类
-
- 1.盲注
- 2、有关于http头部的注入
- 3、二次注入
- 4、宽字节注入
- 5、堆叠注入
- 6、order by 注入
- 四、WAF原理及其绕过姿势
- 参考文献
前言
提示:这里可以添加本文要记录的大概内容:
sql注入是web安全中严重的安全漏洞。虽然目前许多网站,可以通过预编译来有效的防御大部分的sql注入攻击,但是对于学习渗透的我们来说,学习如何利用、挖掘、修复此类漏洞依旧是及其重要的!!
提示:以下是本篇文章正文内容,下面案例可供参考
一、SQL注入产生的原因
sql注入一般是在表单交互当中,能够与数据库交互且具有可控并且可执行的变量时,若维护人员并未对输入的值进行有效的过滤。
则此时攻击者就可以利用,通过输入对应的sql语句达到非法访问数据库里的数据。例如:
select * from users ; #获取所有用户的信息
二、手工注入大致过程
大致的注入思路:
1)先确认有没有注入点:
可以用id=1asfdasdfasdf(加乱七八糟的东西) 看是否依旧正常;
加上闭合字符,如:id=1’ 或者"或者’)等等进行判断是否会报错,如果发现页面已经报错或者不正常时候,然后在加上and 1=1 and 1=2 等等进行确认代码中具体的闭合方式。
如果页面无论怎么加都显示正常,那么可以在加上闭合字符的同时后面加上sleep进行判断,如id=1’ and sleep(10) – 看是否延时了,如果延时则证明后面的sleep执行了,也就是说你写的语句能够被提交到数据库中进行执行。
2)开始尝试注入:
按照判断列、联合选择(注意此处最好让前一个id=错误)/xpath报错/延时注入、爆出库名、表名、数据等等。
当是在字符型下的数据注入时候尤其要注意:
可能代码中可能会有 ’ 等字符的干扰,因此需要加上形成闭环。且要用 --+或者-- (空格)先进行注释。或者利用 ’ 1讲原本的闭合回路进行闭合!
如代码中执行的语句为Select ****** where id=’ $id ’ LIMIT 0,1
1、 那么你可以使用注释符将其闭合,此后代码就为Select ****** where id=‘1’or 1=1-- ’ LIMIT 0,1
2、也可以利用’1进行闭合 如我们输入id=1’ || '1 ,那么代码就为:Select ****** where id=‘1’ || '1’ LIMIT 0,1 。因此,可以看出这样子我们也是能闭合上的!!
然后利用尝试’ " ') ") "))等放在id=1之后进行测试,看哪一个是正确的语句
这里我分享一个我一开始注入时遇到的一个困惑,即联合注入时候为什么要使得id=-1。这一个小地方,我之前老是出错,导致在原本对的地方卡了许久!!!!!!
##记得在注入时,要将前面的id=xxx进行输错,及如果原本id=-1是错误的页面,则在注入是就要已id=-1开头。
1.判断注入点:
首先,需要进行确定注入点,确定哪一处才具有注入对应的漏洞:
注:
例如:https://xxx.com/main.php?id=1&page=2 此处,假设在id处有注入点,则对应的操作注入:union select…等等都需要在id=1后写入;若在page后写入则有可能注入失败。
这是有很多原因导致的,比如说如果设计人员粗心大意只对page输入的参数进行滤过率(即将’ " ) union等进行了过滤,将其转化为了空格),而id处没有进行过滤操作,那么你输入的任何东西在id上都不会被过滤。但是在page上就会被过滤掉了!!!除此之外,还有参数污染等等也上需要在特定的参数处进行写入的!!
参数污染是什么?往下看吧 ,这里先大概知道一下就好了。
判断注入点:
1)利用and进行判断:
and 1=1 页面正常
and 1=2 页面出错
2)利用随机写入,看是否报错:(用上述例子)
id=1 页面正常
id=1as 页面错误(就是在1后面乱写)
3)如果是字符型(其实数字型也可以),在后面加入:
'
"
')
")
等等
有一个万能密码:(可以尝试一波)针对post的!!
or 1=1 #
2.猜解列名
利用order by:
https://xxx.com/main.php?id=1 order by x --
猜到页面报错为止。
3.猜解能够回显数据的地方:
利用union 联合查询,以便数据库能够执行我们想要的命令。再利用select 1…查看页面回显的地方在哪,而后进行收集数据时,便要设定在指定处:
https://xxx.com/main.php?id=-1 union select 1,2,...,x --
注:
此处一定要在id后加上错误的信息,不然可能不会回显对应的我们需要的信息。
4.信息收集、注入:
利用上一步中知道的回显数据之处,然后利用如下信息进行注入:
user() 判断用户
database() 判断数据库
version() 判断版本
@@datadir 判断路径
@@version_compile_os 判断操作系统
1 order by x 判断列的数量
2 union select 1,...,x 联合选择(带入上述的四个)
3 information_schema.tables 记录了所有表名
4 information_schema.columns 记录所有列名
5 table_name 表名
5 column_name 列名
6 table_schema 该表所属的库名
7 group_concat(....) 合并显示
8 information_schema.schemata 显示所有数据库
9 schema_name 库名
注:
对于信息的收集往往也很重要,因为获取了对应的数据库版本、操作系统版本、当前用户信息后,可以做更多的事情。比如:利用对应版本的漏洞、比如跨库攻击。
三、注入的大致分类
1.盲注
所谓的盲注就是指在注入的过程中,获取到的数据不能返回到前端页面。例如:
当我们在mysql中使用select函数时一般都会返回一个正确的结果值。而在使用delete、insert、update时,mysql往往只显示是否正确,因此我们不能利用union联合查询来进行回显。
所以,我们需要利用其他的一些方案来进行判断或者进行尝试,以下将主要介绍三类:
基于报错的SQL注入-报错回显:
floor,updatexml,extractvalue
基于布尔的SQL盲注-逻辑判断:
regexp,like,ascii,left,ord,mid
#可用于猜解字段
like ‘ro%’ #判断ro或ro…是否成立
regexp ‘^xiaodi[a-z]’ #匹配xiaodi及xiaodi…等
if(条件,5,0) #条件成立 返回5 反之 返回0
sleep(5) #SQL语句延时执行5秒
mid(a,b,c) #从位置b开始,截取a字符串的c位
substr(a,b,c) #从b位置开始,截取字符串a的c长度
left(database(),1),database() #left(a,b)从左侧截取a的前b位
length(database())=8 #判断数据库database()名的长度
ord=ascii ascii(x)=97 #判断x的ascii码是否等于97
基于时间的SQL盲注-延时判断
if,sleep
具体注入过程参考本人另一篇博文:渗透学习-SQL注入篇-靶场篇的Less-5部分有盲注的详细过程
2、有关于http头部的注入
在漏洞评估和渗透测试中,确定目标应用程序的输入向量是第一步。在web应用程序测试时,SQL注入漏洞的测试用例不能仅仅只限于特殊的输入向量GET和POST变量。对于其他的HTTP头部参数也会是潜在的SQL注入点。以下是几个常见的测试点:
注:
HTTP 查询字符参数(GET):输入参数通过URL发送
HTTP 正文参数(POST):输入参数通过HTTP正文发送
HTTP Cookie参数:输入参数通过HTTP cookie发送
HTTP Headers:HTTP提交应用程序使用的头
HTTP头字段是超文本传输协议(HTTP)中请求和响应的部分信息,它们定义了HTTP传输的操作参数。例如:
GET /v1/tiles HTTP/1.1
Host: contile.services.mozilla.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0
Accept: */*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: cross-site
Te: trailers
Connection: close
在进行测试的过程中,我们可以利用burpsuite进行抓包,然后针对于Host、X-Forward-For、cookies、User-Agent等等进行测试。
以下简要介绍一下http头部的各个参数:
1、Accept:告诉web浏览器自己接受什么介质类型:*/*代表所有类型,type/*表示接受该类型下的所有子类型,如:type/sub-type;
2、Accept-Charset:浏览器申明自己接受的字符串;
3、Accept-Encoding:接受的语言;
4、Accept-Ranges:web服务器表明是否接受获取其某个实体的一部分(例如文件的一部分)的请求。bytes:表接受,none:表拒绝;
5、Age:当代理服务器用自己缓存的实体去向右请求时,用此标识该实体从产生到现在所经历的时长;
6、Authorization:身份验证信息;
7、Cache-Control:
请求:
no-cache:不要缓存实体,直接去服务器取;
max-age:只接受age值小于max-age的值,且没有过期;
max-stale:接受过期的值,但是过期时间小于max-stale;
min-fresh:接受新鲜生命介于age与min-fresh之间的;
响应:
public:可用cache回应任何用户;
private:只能用缓存内容回应请求该内容的用户;
no-cache:可以缓存,但是只有在跟web服务器验证有效后才能回应;
max-age:包含对象的过期时间;
ALL:
no-store:不允许缓存。
8、Connection:
请求:
close:告诉服务器本次响应后就断开连接;
keepalive:继续保持连接;
响应:
close:连接已关闭;
keepalive:连接保持,等待后续请求
9、Content-Encoding:服务器表明自己使用的压缩方式;
10、Content-Language:服务器表明使用的语言;
11、Content-Length:服务器告知响应对象长度;
12、Content-Rang:服务器表明使用对象为整体对象的哪个部分。bytes:21010-47021/47022
13、Content-Type:服务器告知响应对象的类型,如application/xml;
14、ETag:一个对象的(比如URL)的标记值;主要是判断一个对象是否发送了改变;
15、Expired:服务器表明实体将在什么时候过期;
16、Host:客户端指定自己想要访问的web服务器地址;
17、if-Match:如果对象的ETag未发生改变,才执行请求当作;
18、if-None-Match:ETag发生了改变,代表对象改变了,此时才执行请求的动作;
19、if-Modified-Match:如果请求对象在头部指定的时间之后才修改,则执行请求动作,负责返回304;
20、if-Unmodified-Since:对象在头部指定时间过后没修改过,则执行请求动作;
21、id-Range:浏览器告诉web服务器,如果我请求的对象没有改变,酒吧我缺少的部分给我,如果对象改变了就把整个部分一起给我;
22、Last-Modify:服务器认为对象的最后修改时间;
23、Location:服务器告诉浏览器,试图访问的对象移到别的位置了;
24、Pramga:主要使用Prama:no-cache就相当于Cache-Control: no-cache;
25、Proxy-Authenticate:代理服务器响应浏览器,提供代理浏览器的身份验证信息;
26、Range:浏览器告诉web服务器自己想取的对象在哪一个部分;
27、Referer:浏览器告诉web服务器自己是从哪跳转过来的;
28、Server :web服务器表明自己是什么软件及版本信息等;
29、User-Agent:浏览器表明自己是什么浏览器(如谷歌);
30、Transfer-Encoding:服务器表明自己对本响应消息体的编码是什么;
31、Vary:服务器利用头部信息告诉cache服务器,在什么条件下才能用本响应头所返回的对象响应后续请求;
32、Via:列出从客户端到OCS或者相反方向的响应经过了那些代理服务器,用什么协议发送的请求。
以下进行简要讲解:
Host:
HTTP Host头的目的是帮助识别客户端要与之通信的后端组件。简单来说,就是它指定客户端要访问的域名。 例如,当用户访问https://example.net/web-security时,其浏览器将组成一个包含Host标头的请求,如下所示:
GET /web-security HTTP/1.1
Host: example.net
现如今,由于一个IP往往可能绑定的不止一个web的应用程序,即存在多个Web应用程序(不同端口,不同域名解析等)。因此,可以利用修改host的值进行访问其他的程序。
Host头部检测手法:
1)修改host的值:
简单的来说,可以修改HTTP头中的Host值,如果观察到响应包中含有修改后的值,说明存在漏洞。但有时候篡改Host头的值会导致无法访问Web应用程序,从而导致“无效主机头”的错误信息,特别是通过CDN访问目标时会发生这种情况。
除了直接将host的值修改为另一应用程序外,还可以通过加杂sql语句来进行判断:
如墨者学院的http头部注入就存在以下情况:
写入:
or 1=1
and 1=1
and 1=2
2)可以利用绝对路径看是否能成功;
3)添加于缩进:
当一些站点block带有多个Host头的请求时,可以通过添加缩进字符的HTTP头来绕过:
GET /example HTTP/1.1
Host: attack-stuff
Host: vulnerable-website.com
4)重复host头部字段:
与Host头功能相近的字段,如X-Forwarded-Host、X-Forwarded-For等,这些有时候是默认开启的。
GET /example HTTP/1.1
Host: vulnerable-website.com
X-Forwarded-Host: attack-stuff
详情参考该博文:https://blog.csdn.net/angry_program/article/details/109034421
X-Forward-for
X-Forwarded-For是HTTP头的一个字段。它被认为是客户端通过HTTP代理或者负载均衡器连接到web,而后用于服务端获取源ip地址的一个标准。
X-Forwarded-For主要用来记录ip的信息。标准格式如下:X-Forwarded-For: client1, proxy1, proxy2。从标准格式可以看出,X-Forwarded-For头信息可以有多个,中间用逗号分隔,第一项为真实的客户端ip,剩下的就是曾经经过的代理或负载均衡的ip地址,经过几个就会出现几个。
X-Forward-For主要是为你保留了真实的客户端IP, 因此后端web server就可以从X-Forward-For中获取真实的client ip。
那么,我们要如何利用X-Forward-For来进行注入攻击呢?首先让我们看一下某web利用X-Forward-For的源代码:
$req = mysql_query("SELECT user,password FROM admins WHERE
user='".sanitize($_POST['user'])."' AND
password='".md5($_POST['password'])."' AND ip_adr='".ip_adr()."'");
function ip_adr() {
if(isset($_SERVER['HTTP_X_FORWARDED_FOR'])) { $ip_adr = $_SERVER['HTTP_X_FORWARDED_FOR']; }
else { $ip_adr = $_SERVER["REMOTE_ADDR"]; }
if (preg_match("#^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}#",$ip_addr)) { return $ip_adr; }
else { return $_SERVER["REMOTE_ADDR"]; }
}
由此,可以看出ip_adr中会存储着X-Forward-For对应的ip,若未对ip_adr进行严格的过滤,那么攻击者就可以利用此处进行对应的攻击:
GET /index.php HTTP/1.1
Host: [host]
X_FORWARDED_FOR :127.0.0.1' or 1=1#
$req = mysql_query("SELECT user,password FROM admins WHERE
user='".sanitize($_POST['user'])."' AND
password='".md5($_POST['password'])."' AND ip_adr='"127.0.0.1"' or 1=1#"'");
#此处便完成了注入攻击
Host同理。
User-agent
用户代理(user agent)是记录软件程序的客户端信息的HTTP头字段,他可以用来统计目标和违规协议。在HTTP头中应该包含它,这个字段的第一个空格前面是软件的产品名称,后面有一个可选的斜杠和版本号。
Referer
Referer是另外一个当应用程序没有过滤存储到数据库时,容易发生SQL注入的HTTP头。它是一个允许客户端指定的可选头部字段,通过它我们可以获取到提交请求URI的服务器情况。它允许服务器产生一系列的回退链接文档,像感兴趣的内容,日志等。它也允许跟踪那些坏链接以便维护。
3、二次注入
首先需要大家了解一下二次注入是什么: 二次排序注入也称之为存储型注入,有点类似XSS(我自己认为的)。即hack将导致sql注入的语句存入到数据库当中(常在注册里见到),当服务器端再次调用该数据时,就会触发之前存取的sql语句进而导致了执行!
1、hack通过构造数据的方法,在web页面或者其他地方提交了http数据报文请求(内含sql注入语句)到服务器当中;
2、服务器响应web端的http请求,将信息存入数据库当中(之所以存入,是因为后续可能会对其他功能或请求的客户端进行响应,如注册的新用户等等);
3、hack利用web再次发送一个与第一次发送的http报文不一致的http请求;
4、服务器端收到后,进行响应,调用之前存储的数据信息,因此会触发之前存储的sql语句;
5、服务器端返回处理结果,hack注入成功。
4、宽字节注入
宽字节就是两个以上的字节,宽字节注入产生的原因就是各种字符编码的不当操作,使得攻击者可以通过宽字节编码绕过SQL注入防御。
通常来说,一个gbk编码汉字,占用2个字节。一个utf-8编码的汉字,占用3个字节。
因此当我们输入’时,在php代码中如果有过滤的话会利用转义字符\进行转义,而利用urlencode表示的话,就为%5c%27
我们若想要将%5c去掉,则若此时mysql用的是GBK编码,则可以在前面加上一个编码如%df,使得系统认定%df%5c表示着一个汉字。
该漏洞最早2006年被国外用来讨论数据库字符集设为GBK时,0xdf27本身不是一个有效的GBK字符,但经过 addslashes() 转换后变为0xdf5c27,前面的0xdf5c是个有效的GBK字符(但不能识别,也就是类似这种�),所以0xdf5c27会被当作一个字符0xdf5c和一个单引号来处理,结果漏洞就触发了。
5、堆叠注入
简要介绍:
Stacked Injections:堆叠注入。其意思就是一堆sql语句一起执行。也就是说,我们在命令行中可以输入多条语句同时进行对数据库的操作,每条语句利用;进行分割。如图所示,展现了三条sql语句的同时执行的场景:
 因此,假设我们在一个查询页面时候,输入delete from users的话,那么后端的mysql就会执行如下语句:
因此,假设我们在一个查询页面时候,输入delete from users的话,那么后端的mysql就会执行如下语句:
select * from users where id=1 limit 0,1;delete from users
这时就会达到恶意删表的攻击了!!(上述的只是为了方便理解,再打靶场时千万不要在没做备份的情况下使用删库,删表!!!)
与union区别:
主要区别在于使用union的话会对后面的语句有限制,即因为union是联合查询,因此后面只能使用selec语句。而堆叠注入则就随意。
局限性:
堆叠注入的局限性之一:主要在于并非所有的环境都可以使用,如oracle数据库就已经不给使用了。
堆叠注入的局限性之二:web前端页面通常只会返回一个结果,因此我们使用的堆叠注入的操作,并不一定都会返回结果到前端页面(如果有多条的话)。
在经历sql-libs Less38 关的实验后,这里我提出我自己的见解,如有错欢迎指出:
在我看来,联合查询是被mysql以及web前端页面认为是一条查询语句,也就是说是单独的一条查询结果,尽管他可以合并多条查询语句。因此,当使用联合查询的时候,即使,前一个select语句查询为空,但是后面查的到的话,依旧可以作为一个结果进行输出的!!!如下图,id=-1的查询结果为空的结果并没有显示出来:
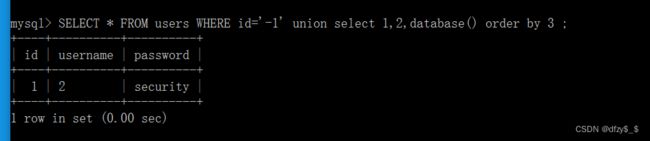 而id=1的结果存在的话,也是会合并成一个结果展示的:
而id=1的结果存在的话,也是会合并成一个结果展示的:
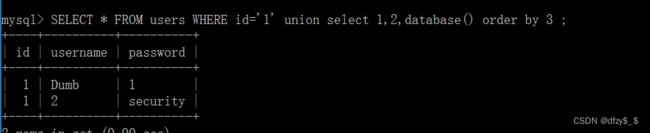 而使用堆叠的话会被放成两个结果展示:
而使用堆叠的话会被放成两个结果展示:
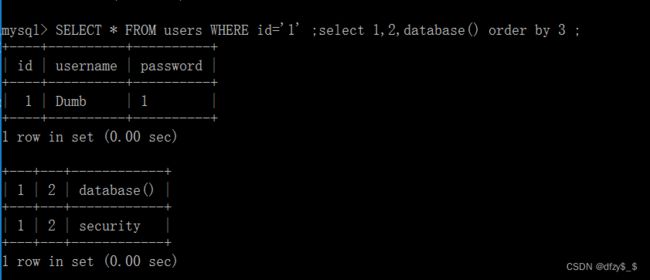
6、order by 注入
以下只是大致说明,最好配合着博客sqllibs-Less46来学习与理解!!
首先,所谓order by注入就是指在order by后面的变量当中具有着用户能够可控的参数变量。如less-46中,后端源代码所执行的sql语句为:
$sql = "SELECT * FROM users ORDER BY $id";
这里,可以看出我们的输入的参数就为order by后面的变量$id。id是我们可以输入的具有可控的参数。这里还有一点,由于是在order by 后面,因此我们不能使用union联合注入。联合注入只能位于where之后。order by后可接 【变量(用于表示按说明排序)】 【选项(升序或者降序等等)】
select * from users order by id desc;
order by 注入点分类:
(1)在order by后的数字处进行注入!
- 直接添加注入语句==> ?sort=(select *****)
- 利用某些特殊的函数,如rand() ==>?sort=rand(【sql语句】)。补充:一般rand()执行时,会辨别括号里是true还是false。即最总rand执行时候是rand(true)或者rand(false)。
- 利用and。==>?sort=1 and 【sql语句】
(2)procedure analyse参数后注入!
Procedure Analyze是MySQL提供的一个分析结果集的接口,以帮助提供数据类型优化建议。其语法格式如下
SELECT ... FROM ... WHERE ... PROCEDURE ANALYSE([max_elements,[max_memory]])
我们在注入时可以输入如下payload:
?sort=1 PROCEDURE ANALYSE(extractvalue(rand(),concat(0x3a,version())),1)
利用procedure analyse参数,我们可以结合起报错注入。同时,由于procede analyse 和order by之间可以存在着limit参数,因此我们还可以在limit 后进行注入。
(3)利用导入导出文件into outfile 参数
在order by后加入如下payload:
?sort=1 into outfile "c:\\xxx\\xxx\\xxx\xxx.txt"
可以将查询结果导入到某文件中,或者上传webshell。
上述的几个可以结合前面的xpath爆错注入,延时注入,布尔注入等等一起来综合利用!
这里解释一下rand()为什么可以注入:
在我们进行注入的过程中,利用order by主要是基于rand的两种形式:
rand(true)
rand(false)
这两种排序将会产生不同但各自又固定的排序结果:


这里可能会有疑惑,rand()产生的应该是一个随机的数,可以自行测试一下,ture与fasle下是两个不同的数,且都为一个小数。那么这里为什么 order by rand(true)又能够进行排序呢?
经过查阅资料:
这里意思大致是,使用rand进行排序的话,会为每一条记录都生成一个随机值,然后排序。

那么我接着看一下rand(N),rand(N)里面的N是一个用来生产随机数的seed value,类型为常量整数。

而ture与fasle就是代表着1与0,也就是说会给rand一个固定的种子值,因此,使用rand(true)时排序就会是固定的,这里也就是说给每一条记录都产生了一个固定的值进行排序。(这里你可以试一下,如果使用rand()直接排序,那么每一次的排序都会不一样的)
具体的可以看一下这篇博文:MySQL-17:order by rand()
四、WAF原理及其绕过姿势
WAF是什么?
Web应用防护系统(Web Application Firewall, 简称:WAF)代表了一类新兴的信息安全技术,用以解决诸如防火墙一类传统设备束手无策的Web应用安全问题。
WAF分为非嵌入型WAF和嵌入型WAF,非嵌入型WAF指的是硬件型WAF、云WAF、软件型WAF之类的;而嵌入型WAF指的是网站内置的WAF。非嵌入型WAF对Web流量的解析完全是靠自身的,而嵌入型WAF拿到的Web数据是已经被解析加工好的。所以非嵌入型的受攻击机面还涉及到其他层面,而嵌入型WAF从Web容器模块型WAF、代码层WAF往下走,其对抗畸形报文、扫操作绕过的能力越来越强。当然,在部署维护成本方面,也是越高的。
怎么绕过?
应用层方面:
1、采用大小写/双写:
id=1UnIoN SeLeCT1,user()
UNIunionON SELselectECT 1,2,3,4
2、利用各种编码:
URLCode:
空格变为%20、单引号%27、左括号%28、右括号%29。如果有某种情况URL编码只进行了一次解码过滤可以用两次编码绕过。
HEX编码(十六进制);
Unicode编码:
单引号:%u0027、%u02b9、%u02bc、%u02c8、%u2032、%uff07、%c0%27、%c0%a7、%e0%80%a7
空格:%u0020、%uff00、%c0%20、%c0%a0、%e0%80%a0
左括号:%u0028、%uff08、%c0%28、%c0%a8、%e0%80%a8
右括号:%u0029、%uff09、%c0%29、%c0%a9、%e0%80%a9
这里,我们就可以利用宽字节进行注入了!
3、利用注释符:
Mysql中常用的注释符有/**/、-- (空格)、# ,首先让我们来了解一下mysql的注释规则,以便助于我们理解该怎么绕过
⇒ --(空格) : 双重冲突注释样式至少需要在第二个破折号之后的空格或控制字符(空格,制表符,换行符等)。他的作用是从该位置后到行尾是注释的内容!
⇒ # 与上述那个相同。。
⇒/**/ 可注释多行!
⇒ 进一步的有可执行注释:
对于/*! / ,它的表示含义为继续执行注释里的内容。也就是说,该解释里的语句依旧会被执行,例如/!select * from test */ 这一个语句依旧会被mysql检测并执行该语句。
⇒ 然后还有个内联注释:即/*!xxxx 语句 / xxxx是数字,代表着mysql 的版本号,即:/!50001 语句 */ 代表着数据库5.00.01版本以上就会被执行。
在了解上述之后,我们就可以利用内联注释来将我们的语句进行隐藏起来,绕过waf的检测机制:
index.php?page_id=-15 /*!UNION*/ /*!SELECT*/ 1,2,3
除此之外,还可以利用换行符,跳过sql的单行注释,换行符一般位%0a:
select%201,2,group_concat(table_name)from/*!-- /*%0ainformation_schema.tables*/ where table_schema='security'--+
当然还可以直接利用内联注释进行绕过。
4、关键词的替换、等价的函数等等:
hex()、bin() ==> ascii()
sleep() ==>benchmark()
concat_ws()==>group_concat()
mid()、substr() ==> substring()
@@user ==> user()
@@datadir ==> datadir()
5、如有报错注入,可利用updatexml函数等等
6、特殊符号:
1)使用反引号 ` ,可以用来过空格和正则,特殊情况下还可以将其做注释符用,
例如 select `version()`
2)神奇的"-+.",select+id-1+1.from users; “+”是用于字符串连接的,”-”和”.”在此也用于连接,可以逃过空格和关键字过滤.
3)@符号,select@^1.from users; @用于变量定义如@var_name,一个@表示用户定义,@@表示系统变量。
4)Mysql function() as xxx 也可不用as和空格
6、缓冲区溢出:
由于不少WAF是有c所写的,而c语言没有缓冲区保护,因此可以利用这个漏洞触发bug。
?id=1 and (select 1)=(Select 0xA*1000)+UnIoN+SeLeCT+1,2,version(),4,5,database(),user(),
8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26
0xA*1000指0xA后面”A"重复1000次,一般来说对应用软件构成缓冲区溢出都需要较大的测试长度,这里1000只做参考也许在有些情况下可能不需要这么长也能溢出。
7、参数污染:
/?id=1/**/union/*&id=*/select/*&id=*/pwd/*&id=*/from/*&id=*/users
8、;%00截断
参考文献
小迪课程
简单的waf绕过