Hudi数据湖技术引领大数据新风口(二)编译安装
文章目录
- 第2章 编译安装
-
- 2.1 编译环境准备
- 2.2 编译Hudi
-
- 2.2.1 上传源码包
- 2.2.2 修改pom文件
- 2.2.3 修改源码兼容hadoop3
- 2.2.4 手动安装Kafka依赖
第2章 编译安装
2.1 编译环境准备
本教程的相关组件版本如下:
| Hadoop | 3.1.3 |
|---|---|
| Hive | 3.1.2 |
| Flink | 1.13.6,scala-2.12 |
| Spark | 3.2.2,scala-2.12 |
(1)安装Maven
(1)上传apache-maven-3.6.1-bin.tar.gz到/opt/software目录,并解压更名
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
mv apache-maven-3.6.1 maven-3.6.1
(2)添加环境变量到/etc/profile中
sudo vim /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/maven-3.6.1
export PATH= P A T H : PATH: PATH:MAVEN_HOME/bin
(3)测试安装结果
source /etc/profile
mvn -v
(2)修改为阿里镜像
(1)修改setting.xml,指定为阿里仓库地址
vim /opt/module/maven-3.6.1/conf/settings.xml
nexus-aliyun
central
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
2.2 编译Hudi
2.2.1 上传源码包
将hudi-0.12.0.src.tgz上传到/opt/software,并解压
tar -zxvf /opt/software/hudi-0.12.0.src.tgz -C /opt/software
也可以从github下载:https://github.com/apache/hudi/
2.2.2 修改pom文件
vim /opt/software/hudi-0.12.0/pom.xml
(1()新增repository加速依赖下载
nexus-aliyun
nexus-aliyun
http://maven.aliyun.com/nexus/content/groups/public/
true
false
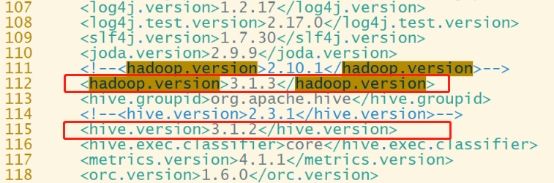
(2)修改依赖的组件版本
3.1.3
3.1.2
2.2.3 修改源码兼容hadoop3
Hudi默认依赖的hadoop2,要兼容hadoop3,除了修改版本,还需要修改如下代码:
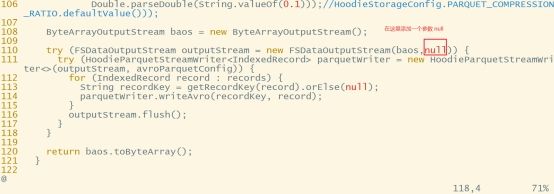
vim /opt/software/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
修改第110行,原先只有一个参数,添加第二个参数null:
否则会因为hadoop2.x和3.x版本兼容问题,报错如下:

2.2.4 手动安装Kafka依赖
有几个kafka的依赖需要手动安装,否则编译报错如下:

(1)下载jar包
通过网址下载:http://packages.confluent.io/archive/5.3/confluent-5.3.4-2.12.zip
解压后找到以下jar包,上传服务器hadoop1
Ø common-config-5.3.4.jar
Ø common-utils-5.3.4.jar
Ø kafka-avro-serializer-5.3.4.jar
Ø kafka-schema-registry-client-5.3.4.jar
(2)install到maven本地仓库
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serializer -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-avro-serializer-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-schema-registry-client-5.3.4.jar