基于进化表示学习的事态知识图谱(上)7.21 +(下)7.22
基于进化表示学习的时态知识图谱推理
- 摘要
- 介绍
- 相关工作
-
- 静态KG推理
- TKG推理
- 公式
- RE-GCN模型
-
- 进化单元
-
- 并发事实之间的结构依赖关系 7.22
- 跨时间相邻事实的序列模式
- 静态属性
- 不同任务的评分函数
- 参数学习
- 计算复杂性分析
- 实验
-
- 实验装置
-
- 数据集
- 评估指标
- 基准
- 实施细节
- 实验结果
- 消融研究
- 案例研究
- 细节分析
- 总结
- 代码运行
-
- 过程
-
- 错1:
- 错2:
- 错3:
原文:

摘要
知识图谱(KG)推理已经被广泛探索,它可以为不完整的KG预测缺失的事实。然而,预测未来事实的 Temporal KG(TKG) 的推理仍然远未解决。预测未来事实的关键是彻底了解历史事实。
Temporal KG(TKG)时态知识图谱
是一种扩展了传统知识图谱的数据表示形式,用于描述实体、关系和事件之间的时态关系。
传统知识图谱主要关注实体之间的静态关系,而时态知识知识图谱则引入了时间维度,可以描述实体和关系在不同时间点上的变化和演化。它记录了实体和关系的创建时间、失效时间、持续时间等信息,以及它们之间的时间相关性。
时态知识图谱的引入使得我们能够很好的理解和推理关于时间的事实和事件。它可以用于时间推理、事件预测、时间序列分析等任务。
TKG实际上是对应于不同时间戳的KG序列,其中每个KG中的所有 并发事实(Concurrent facts) 都表现出 结构依赖性(Structural dependencies) ,而时间上相邻的事实携带了 信息序列模式(informative sequential patterns) 。
“Concurrent facts”(并发事实)
是指在同一时间段内同时发生的多个事实或事件。
在知识图谱中,当多个实体或关系在相同的时间段内存在并发的关联时,可以将它们称为并发事实。例如,一个人可以在同一时间点上同时担任多个职位,这些职位之间存在并发关系。
对于并发事实的处理,需要考虑事实之间的时间戳、并发冲突的解决、并发操作的一致性等问题。
“Structural dependencies”(结构依赖)
在知识图谱中,结构依赖指的是不同实体之间的关联和依赖关系。它描述了实体之间的连接方式和层次结构,以及它们之间的关系如何影响整个知识图谱的组织和功能。
结构依赖可以是多种形式,包括层次结构、关系网络和属性关联。在层次结构中,实体按照一定的层次和父子关系进行组织,形成了一个树状结构。关系网络描述了实体之间的关联关系,可以是一对一、一对多或多对多的关系。属性关联指的是实体的属性与其他实体之间的关联,例如一个人的姓名和他所在的组织之间的关系。
通过建立结构依赖,知识图谱可以更好地组织和表示实体之间的关系,使得用户可以更方便地进行信息检索和推理。结构依赖还可以帮助系统理解和分析知识图谱中的数据,发现隐藏的模式和规律,从而提供更精确和准确的知识服务。
“informative sequential patterns”(信息序列模式)
是指在数据序列中发现有用和有意义的模式或规律。这些模式可以帮助我们理解和分析数据序列中的趋势、关联和重要事件。
具体来说,信息序列模式是指在时间序列或事件序列中,出现频率较高或具有显著性的序列模式。这些模式可以是一系列事件、行为或状态的组合,它们的出现可能具有特定的含义和重要性。
例如,在电子商务领域,我们可以通过分析用户的购买历史序列来发现用户的购买偏好和行为模式。这些模式可以包括用户经常购买的商品类别、购买的时间间隔、购买的数量等。通过发现这些信息序列模式,电子商务平台可以提供个性化的推荐和定制化的营销策略。
为了有效地捕捉这些特性,我们提出了一种新的基于图卷积网络(GCN)的递归进化网络,称为RE-GCN,它通过当前的KG序列来学习每个时间戳上的实体和关系的这种进化表示。
具体来说,对于进化单元,利用relation-aware GCN的来捕获每个时间戳的KG内的结构依赖关系。为了并行地捕捉所有事实的序列模式,通过 门循环组件(Gate Recurrent Component) 对 历史KG序列(historical KG sequence) 进行回归建模。
“Gate Recurrent Component”(门循环组件)
是一种在循环神经网络(RNN)中使用的关键组件。它主要用于处理序列数据,具有记忆和学习长期依赖关系的能力。
门循环组件最常见的形式是长短期记忆网络(LSTM)和门控循环单元(GRU)。这些组件通过使用一系列的门来控制信息的流动和记忆的更新,以便更好地处理序列中的长期依赖关系。
在LSTM中,门循环组件由输入门、遗忘门和输出门组成。输入门控制新输入的加入,遗忘门控制旧记忆的保留,输出门控制输出的生成。这些门通过使用sigmoid函数和逐元素乘法来决定信息的流动和记忆的更新。
在GRU中,门循环组件由更新门和重置门组成。更新门控制新输入和旧记忆的加权和,重置门控制旧记忆的遗忘。这些门通过使用sigmoid函数和逐元素乘法来决定信息的流动和记忆的更新。
“historical KG sequence”(历史知识图谱序列)
是指在时间上按照顺序排列的一系列历史知识图谱。每个历史知识图谱都代表了一个特定时间点或时间段内的知识状态。
此外,实体的静态属性(如实体类型)也通过静态图谱约束组件进行了调整,以获得更好的实体表示。然后可以基于进化实体和关系表示来重新实现未来时间戳的事实预测。
大量实验表明,RE-GCN模型在六个基准数据集上对时间推理任务获得了显著的性能和效率提高。特别是,它在实体预测的MRR方面实现了高达11.46%的改进,与最新基线相比,速度提高了82倍。
介绍
KG通常是不完整的,这限制了基于KG的应用的性能和范围。
为了缓解这个问题,对试图预测缺失行为的KG进行推理是自然语言处理中的一项关键任务。传统上,KG被认为是静态的多关系数据。然而,大量基于事件的交互数据表现出复杂的时间动态,这就需要能够通过TKG来表征和推理的方法。
TKG中的一个事实可以用(主体实体、关系、对象实体、时间戳)的形式表示。实际上,TKG可以表示为具有时间戳的KG序列,每个KG都包含在同一时间戳同时发生的事实。尽管TKG无处不在,但对这类数据的推理方法在有效性和效率方面都未能进行相对的探索。
从时间戳t0到tT的TKG推理主要有两种设置:插值(interpolation) 和 外推(extrapolation) 。前者试图从t0到tT推断缺失的事实。后者旨在预测t > tT的未来事实(事件),这更具挑战性。
interpolation(插值)和extrapolation(外推)是两种常见的推理方法,用于从已知的知识中推断出新的信息。
插值(interpolation)是指在已知的知识或数据点之间进行推理或估计。它基于已有的观测值或事实,通过填充两个已知点之间的空白来推断出中间的值。在知识推理中,插值可以用来填补知识图谱中的空白,推断出两个已知实体之间的关系或属性。
外推(extrapolation)是指在已知的知识或数据点之外进行推理或估计。它基于已有的观测值或事实,通过推断出现有模式或趋势的延伸来预测未来的值。在知识推理中,外推可以用来预测未来的事件、趋势或属性,基于已有的知识和模式进行推断。
对于TKG来说,基于观察到的历史KG来预测未来时间戳的新事实,有助于理解事件的隐藏因素并对新出现的事件做出反应。因此,外推法设置下的推理非常重要,它有助于许多实际应用。
本文中,时间推理任务(即在TKG上使用外推法的推理)包含两个子任务:
- 实体预测:预测哪个实体将会在未来某个时间戳和给出的实体一起具有给定关系
- 关系预测:预测两个给定实体将在将来的某个时间戳将会发生什么样的关系
为了准确预测未来的事实,需要将模型分解为历史事实。
在每个时间戳里,实体通过并发事实相互影响,这些事实形成一个KG并表现出复杂的 结构依赖 关系。如下图所示,2018年1月18日的同时发生的事实表明,government(India)受到许多人的压力,这可能会影响government(India)的行为(对Citizen使用暴力的行为)。
此外,在时间上相邻的事实中体现的每个实体的行为可以携带信息 序列模式 。如图所示,N.Naidu的历史行为在一定程度上反映了N.Naidu的偏好(对government(India)发出声明),并影响了N.Naidu未来的行为。这两种历史信息的结合推动了实体和关系的行为趋势和表现。
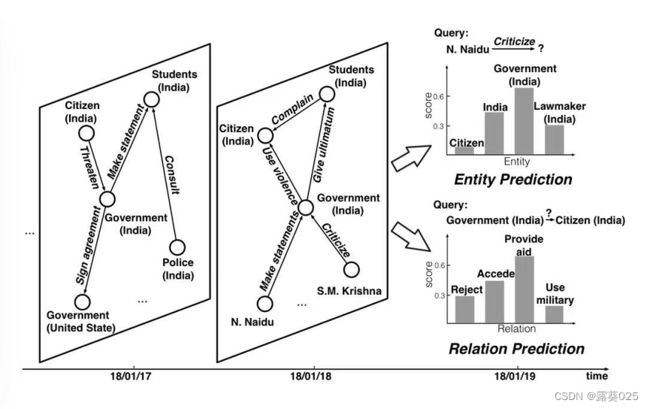
一些早期的尝试,通过将历史中所有事实的发生建模为时间点过程来学习进化实体表示。然而,它们不能在相同的时间戳上对并发的事实进行建模。
最近的一些尝试以 启发式的方式为每个单独的查询提取一些相关的历史信息。具体而言,RE-NET在实体预测的每个查询中为给定实体提取那些直接参与的历史事实,然后依次编码。CyGNet对具有相同实体的历史事实以及与实体预测的每一个查询的关系进行建模,因此主要侧重于用重复模式预测事实。
由于TKG实际上是一个KG序列,现有的方法有三个主要限制:
- 主要关注给定查询的实体和关系,忽略了每个时间戳KG中所有事实之间的结构依赖性;
- 通过单独地对每个查询的历史进行编码,效率低;
- 忽略实体的某些静态属性(如实体类型)的功能。
此外,现有的方法只关注实体预测,而关系预测不能用同一模型同时求解
在这项工作中,我们将TKG视为一个KG序列,并对整个KG序列进行统一建模,将所有历史事实编码为实体和关系表示,以便于实体和关系预测任务。因此,我们提出了一种新的基于GCN的递归进化网络,即RE-GCN,它通过对KG序列进行递归建模来学习每个时间戳处的实体和关系的进化表示。
具体来说,对于每个进化单元,利用 关系感知GCN(relation-aware GCN) 来捕获每个时间戳的KG内的结构依赖关系。这样就可以有效地对一个KG中所有事实之间的相互作用进行建模。历史KG序列通过门循环组件分量进行自回归建模,以有效地捕捉所有时间相邻事实之间的序列模式。TKG中实体和关系的所有历史信息都是并行编码的。此外,实体的静态属性,如实体类型,也通过静态图约束组件合并,以获得更具体的实体表示。然后,基于进化表示可以实现未来时间戳的实体预测和关系预测任务。总的来说,本文做出了以下贡献:
- 我们提出了一个用于TKG上的时间推理的进化表示学习模型RE-GCN,该模型考虑了KG中并发事实之间的结构依赖性、时间相邻事实之间的顺序模式以及实体的静态特性。这是第一项将所有这些整合到时间推理的进化表示中的研究。
- 通过从KG序列的角度对TKG进行表征,RE-GCN将TKG中的所有历史信息有效地建模为进化表示,进化表示同时适用于实体预测和关系预测。因此,与最先进的基线相比,它能够实现高达82倍的加速。
- 大量实验表明,通过对历史进行更全面的建模,RE-GCN在六个常用的基准上实现了与实体和关系预测任务相比一致且显著更好的性能(MRR提高了11.46%)。
relation-aware GCN(关系感知图卷积网络)
是一种针对关系图数据的图卷积网络模型。与传统的图卷积网络不同,relation-aware GCN考虑了节点之间的关系信息,并在图卷积操作中使用这些关系来更新节点表示。通过将节点特征与关系特征进行融合,relation-aware GCN可以更好地捕捉节点之间的关系,并生成更具表达力的节点表示。
相关工作
静态KG推理
现有的静态KG推理模型试图推断KG中缺失的事实。
最近,基于嵌入的模型引起了人们的广泛关注。
由于GCN是一个将图中的内容和结构特征相结合的代表性模型,一些研究将其推广到了relation-aware GCN中,以处理KGs。其中,R-GCN使用关系特定滤波器扩展了GCN,而WGCN在聚合期间使用可学习的关系特定权重。VR-GCN[和CompGCN在GCN聚合过程中共同将节点和关系嵌入关系图中。
上述模型都是在静态KG中设置的,它们无法预测未来的事实。
TKG推理
关于TKG的推理可以分为两种设置,插值和外推。
插值设置,模型试图推断历史时间戳中缺失的事实。TA DistMult、TA TransE和TTransE将事实发生的时间整合到关系的嵌入中。HIyTE将每个时间戳与相应的超平面相关联。然而,它们无法在未来的时间戳预测事实,也无法与外推设置直接兼容。
外推设置(本文所强调的)试图在历史的基础上预测未来时间戳中的新事实。
与我们的工作正交,一些模型通过逐点过程估计条件概率来进行实际预测。它们更能够在连续时间内对TKG进行建模,在连续时间下,不可能同时发生任何事实。
Glean将事件摘要构建的单词图纳入未来事实预测的模式中。然而,在实际应用中,并非所有事件都有摘要文本。CyGNet和RE-NET是与我们最相关的工作,他们试图从每个给定查询的角度解决实体预测任务,该任务对每个查询中与主题实体相关的历史事实进行编码。CyGNet使用生成复制网络来对具有相同主题实体和与给定查询的关系(即重复模式)的历史事实的频率进行建模。RE-NET使用GCN和GRU对与给定主题实体相关的1跳子图序列进行建模。 它们都忽略了在不同时间戳下KG内的结构依赖性和实体的静态特性。不同的是,RE-GCN将KG序列作为一个整体进行建模,它考虑了所有的结构依赖性,并能够极大地提高效率。
公式
RE-GCN模型
RE-GCN将每个时间戳的KG中的 结构依赖性、跨时间相邻事实的信息序列模式以及实体的静态特性合并到实体和关系的进化表示中。基于实体学习和关系表示,未来的时间戳推理可以利用各种得分函数来制作。因此,RE-GCN包含一个进化单元和多任务评分函数。进化单元用于对历史KG序列进行编码,得到实体和关系的演化表示。评分函数包含相应任务的得分函数,以最终时间戳的进化表示(即em beddings)作为输入。
进化单元
进化单元由一个relation-aware GCN、两个门循环组件和一个静态图约束组件组成。
relation-aware GCN试图在每个时间戳的KG内捕捉依赖结构。两个门循环分量对历史KG序列进行了 **自回归(auto-regressively)**建模。
具体地说,一个时间门循环分量和一个GRU分量相应地得到了每个时间戳上实体和关系的进化表示。静态图约束组件通过在实体的静态嵌入和进化嵌入之间添加一些约束,将静态属性集成到进化嵌入中。形式上,进化单元从最近m次时间戳的KGs序列计算映射(即{Gt-m+1, … ,Gt、 ))循环地转换为实体嵌入矩阵的序列(即,(Ht-m+1, … Ht)和关系嵌入矩阵序列(即(Rt-m+1, …Rt)。特别地,第一时间戳处的输入,包括实体嵌入矩阵H和关系嵌入矩阵R,被随机初始化。
并发事实之间的结构依赖关系 7.22
并发事实之间的结构依赖关系通过事实捕捉实体之间的关联,通过共享实体捕捉关系之间的关联。由于每个KG都是多个关系图,而 GCN是图结构数据的强大模型。使用 ω-layer(ω层) 的relation-aware GCN来对结构依赖性进行建模。
更具体地说,对于时间戳 t 处的KG,l 层(l∈[0,ω-1])处的对象实体o 在所考虑的 l 层处的关系嵌入的消息传递框架下从其主体实体获得信息,并获得其在下一个 l+1 层的嵌入,即,


self-loop 自环
一个节点与自身之间的边或连接,简言之,自环是从一个节点指向自身的边
图数据结构中,自环可以用来表示节点内部的自循环关系,即节点与自身之间存在某种特定的关系或属性。
在某些图模型中,自环可以用来表示节点的自我状态或自我更新。
relation-aware GCN 根据它们在每个时间戳发生的事实来获得实体嵌入,自循环操作可以被视为实体的自进化。
跨时间相邻事实的序列模式
对于实体o,这种包含它的历史事实的序列模式反映了它的行为趋势和偏好。
为了尽可能多地涵盖历史事实,该模型需要考虑所有在时间上相邻的事实。由于relation-aware GCN的最后一层的输出 (->)hω0,t-1 已经对时间戳 t-1 处的相邻事实的结构进行了建模,因此包含时间相邻事实的信息的一种直接有效的方法是使用 t-1,Ht-1处的输出实体嵌入矩阵作为relation-aware GCN 在t,H0t的输入。因此,通过堆叠ω层的relation-aware GCN来对潜在的序列模式进行建模。然而,尽管相邻的KGs不同,但当相邻时间戳的同一实体对之间发生重复关系时,也存在 过度平滑(over-smoothing) 的问题,即实体的嵌入收敛到相同的值。且当历史KG序列较长时,GCN的大量堆叠层可能会导致 消失梯度(vanishing gradient) 问题。
因此,后来,我们应用门循环组件来缓解这些问题。这样,实体嵌入矩阵Ht由两部分确定,即关系感知GCN在时间戳t的最后一层的输出Hωt和来自先前时间戳的Ht-1。正式地:

“Over-smoothing”(过度平滑)
是指在图数据分析中,当应用图卷积神经网络(Graph Convolutional Network,GCN)或其他图神经网络模型时,过度平滑的现象。这种现象会导致节点之间的特征差异逐渐减小,最终导致难以区分不同节点之间的特征。
在图数据中,每个节点都具有一组特征向量,而图神经网络模型通过将邻居节点的特征进行聚合来更新每个节点的特征。然而,当模型在多个层次上重复这个聚合过程时,节点的特征会逐渐趋于相似,这可能导致信息丢失和欠拟合。
总而言之,过度平滑是指在图神经网络中,节点特征逐渐变得相似,导致节点之间的区分能力下降的现象。
梯度消失问题(Gradient Vanishing Problem)
是指在深度神经网络中,当反向传播算法计算梯度时,梯度值逐渐变小并趋近于零的现象,从而导致难以训练和更新参数的问题。这导致在更新网络参数时,浅层的网络层几乎没有得到有效的梯度信息,从而导致它们的参数几乎不会更新,而深层的网络层则更容易受到梯度消失的影响.
静态属性
除了历史KG序列中包含的信息外,形成静态图的实体的一些静态性质可以被视为TKG的背景知识,有助于模型学习更准确的实体进化表示。因此,我们将静态图形纳入进化表示的建模中。基于最初包含在实体名称字符串中的实体属性信息,我们从ICEWS中构建了三个TKG的静态图谱。其中实体的大多数名称字符串的形式为“entity type(country)”。
ICEWS国际事件和冲突数据集
是一个全球范围的事件数据集,用于收集和分析有关国际冲突、政治事件和社会动荡的信息。
以ICEWS18的一个实体名为Police(Australia)为例,我们将关系“isA” 从该实体添加到财产实体“Police”,将关系“country”添加到财产实体 “Australia”。
由于静态图是多关系图,R-GCN可以对多关系图进行建模,而不需要为关系进行额外的嵌入。因此,我们采用了一个没有自循环的1层R-GCN来获得实体在TKG中的静态嵌入。然后,静态图的更新规则定义如下:

为了反映实体嵌入矩阵Ht-m, Ht-m+1, … ,Ht的学习序列中的静态特性,我们将同一实体的进化嵌入和静态嵌入之间的角度限制为不超过与时间戳相关的阈值。它随着时间的推移而增加,因为随着越来越多的事实的发生,实体的进化嵌入的允许变量范围随着时间的流逝而不断扩展。因此,它被定义为

因此,静态图约束分量在时间戳t处的损失函数可以定义为:

不同任务的评分函数
参数学习
计算复杂性分析
实验
实验装置
数据集
六个典型的TKG在以前的工作中常用,即ICEWS18、ICEWS14、ICEWS05-15、WIKI、YAGO、GDELT。

在这所有的数据集上评估RE-GCN。将ICEWS14和ICEWS05-15分为训练集、验证集和测试集,按以下时间戳的比例分别为80%、10%和10%。
数据集的详细信息如下表所示。间隔中的时间表示时间上相邻的事件之间的时间粒度。

评估指标
MRR和Hits@{1,3,10}作为实体预测和关系预测的度量。
基准
将RE-GCN模型与两类模型进行了比较:静态KG推理模型和TKG推理模型。
选择DistMult、ComplEx、R-GCN、ConvE、Con-vIransE、RotatE作为静态模型。
选择HyTE、TTransE和TA DistMult作为插值设置下的时间模型。
对于外推法设置之外的时间模型。比较了CyGNet和RE-NET。
对于Know evolution和DyRep,RE-NET将它们扩展到临时推理任务,但不发布它们的代码。
因此,我们只在他们的论文中报告结果。此外,GCRN是齐次图的模型,RE-NET通过用R-GCN代替GCN将其扩展到R-GCRN。
实施细节
对于演化单元,嵌入维度d设置为200;
relation-aware GCN的层数ω对于YAGO被设置为1,而对于其他数据集被设置为2;
对于relation-aware GCN的每一层,丢弃率被设置为0.2。
我们在验证集上对历史图序列的长度(1,15)和角度γ为(1°-20°)的上升速度进行网格搜索。
ICEWS18、ICEWS14、ICEWS05-15、WIKI、YAGO和GDELT的最佳历史长度m分别为6、3、10、2、1、1。
γ通过实验设定为10°。
Adam被用于参数学习,学习率为0.001。
对于静态图约束组件中使用的R-GCN,我们将块维度设置为2x2,每层的丢失率设置为0.2。
对于ConvTransE,核的数量设置为50,核的大小设置为2x3,丢失率设置为0.2。
对于实体预测任务和关系预测任务的联合学习,实验将γ1和γ2分别设置为0.7和0.3.
地静态图的统计数据如下表所示。只报告了在WIKI、YAGO和GDELT上没有静态图约束的结果,因为这些数据集中缺少静态信息。
为了在验证集和测试集中进行多步骤推理,我们用训练集最终时间戳处实体和关系的进化嵌入作为得分函数的输入来评估RE-GCN的性能。此外,我们还报告了在测试集上进行多步推理时给出的具有基本事实历史的模型的结果。所有实验都是在TeslaV100上进行的。
实验结果
消融研究
案例研究
细节分析
总结
知识图谱推理可以预测缺失的事实,但是预测未来事实的TKG推理还远未解决。
本文提出了用于时间推理的RE-GCN,通过捕获并发事实之间的结构依赖性和时间相邻事实的信息序列模式,来学习实体和关系的进化表示。
- 在每个时间戳里,实体通过并发事实相互影响,这些事实形成一个KG并表现出复杂的结构依赖关系,如一个时间戳中其他实体的态度关系会影响该实体在未来时间戳里的行为。
- 在时间上相邻的事实中体现的每个实体的行为可以携带信息序列模式,即历史的偏好会影响未来的行为。
目前方法有如下限制:
- 忽略每个时间戳KG中所有事实之间的结构依赖性。—解决—提出RE-GCN,通过对KG序列化进行递归建模来学习每个时间戳处的实体和关系的进化表示。
- 单独对每个查询历史进行编码效率低。—解决—TKG中实体和关系的所有历史信息都并行编码。
- 忽略实体的某些静态属性的功能。—解决—实体静态属性通过静态图约束组件合并,已获得更具体的实体表示。
基于最终时间戳的进化表示,使用各种得分函数进行时间推理。
六个基准测试的实验结果证明了RE-GCN在两个时间推理任务上的显著优点和优越性。
通过对KG序列进行整体建模,与最先进的基线RE-NET相比,RE-GCN实现了17至82倍的实体预测速度。
代码运行
过程
conda create -n regcn python=3.9
–n:也可以写为-name,regcn是新创建的虚拟环境的名字,创建完,可以在anaconda/envs下找到新环境
python=3.9:是python的版本号,可以指定
conda activate regcn #激活
pip install -r requirement.txt
#Python 用pip批量安装包 requirements.txt
tar -zxvf data-release.tar.gz #解压缩
cd ./data/
python ent2word.py
为占位符表示需要替换为实际的数据集名称

创建文件夹保存模型:
mkdir models
回到上级目录:
cd ..
按照论文给的数据给各模型赋值:
cd src
python main.py -d ICEWS14s --train-history-len 3 --test-history-len 3 --dilate-len 1 --lr 0.001 --n-layers 2 --evaluate-every 1 --gpu=0 --n-hidden 200 --self-loop --decoder convtranse --encoder uvrgcn --layer-norm --weight 0.5 --entity-prediction --relation-prediction --add-static-graph --angle 10 --discount 1 --task-weight 0.7 --gpu 0
错1:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x8d in position 5313: illegal multibyte sequence
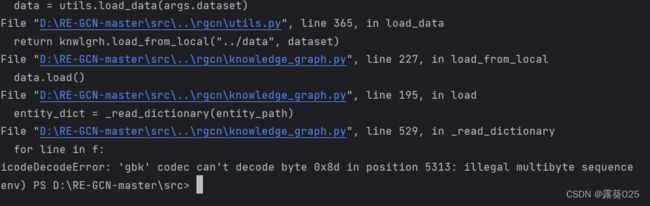
问题就是不知道数据集是怎么编码的
首先,你可以尝试使用其他常见的编码方式,例如 ASCII 或者 ISO-8859-1(也称为 Latin-1)来打开文件,看是否能够成功读取文件内容。
如果以上尝试仍然失败,你可以尝试使用一种称为自动检测编码(Auto-Detect Encoding)的工具来确定文件的实际编码。这些工具能够根据文件内容的特征自动推断出合适的编码方式。
在 Python 中,你可以使用第三方库 chardet 来进行编码检测。你可以先安装 chardet 库,然后使用以下代码来检测文件的编码:
import chardet
# 读取文件内容
with open('your_file.txt', 'rb') as f:
data = f.read()
# 检测编码
result = chardet.detect(data)
encoding = result['encoding']
# 使用检测到的编码方式重新打开文件
with open('your_file.txt', 'r', encoding=encoding) as f:
content = f.read()
这样,你就可以使用 chardet 库检测文件的实际编码,并使用检测到的编码方式重新打开文件,以正确读取文件内容
但 
7.23
上述处理错误的思路错了,在Python中,文件名中以"._"开头的文件通常是隐藏文件。隐藏文件是操作系统中的一种特殊文件,它们在文件管理器或命令行界面中默认不显示。这种命名约定通常用于标识一些系统生成的或特定用途的文件,以区别于普通文件。所以
才会出现乱七八糟的符号而且无法正常解码。
实际上是python中未明确给出编码方式默认成了GBK才会报错,手动添加上“encoding=‘utf-8’ ”后该问题就解决了。

错2:
FileNotFoundError: [Errno 2] No such file or directory: ‘…/data/ICEWS14s/e-w-graph.txt’
但是每个数据集中并没有e-w-graph.txt
![]()
而涉及的需要e-w-graph.txt的数据集都是数据集下的ent2word.py运行产生的,所以上述带哪里需要把所有数据集都运行一遍,此过程中,ent2word.py的编码还是有问题,又手动添加上来encoding=‘UTF-8’
该问题解决。
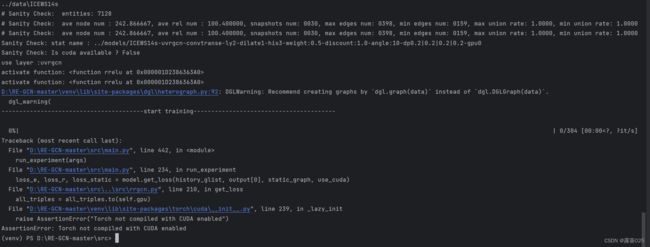
错3:
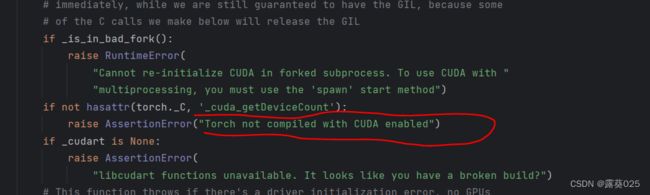
这里的问题