SparkSQLBroadcast join实例
最近做sparksql的优化,需要用到sparksql broadcast join,之前在网上找了好多资料,发现介绍理论的偏多,实际操作案例较少,在此记录:
Broadcast join:大表关联小表时使用. 比如:百亿级别的大表对千条数据量的小表进行关联查询时。
众所周知,在sparksql中进行join操作会产生shuffer,shuffer是会耗费大量的时间与机器性能。但是broadcast join能完美的避开这一缺点。
程序启动时,driver 会加载小表的数据,将这些数据发送给每一个executor。
executor存储小表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时;
注意:
- 被广播的表需要小于 spark.sql.autoBroadcastJoinThreshold 所配置的值,默认是10M;可以通过spark.sql.autoBroadcastJoinThreshold调整
- 基表不能被广播,比如 left outer join 时,只能广播右表
实际操作
1. 官网案例
Python:
from pyspark.sql.functions import broadcast
small_df = ...
large_df = ...
#spark版本<2.2
large_df.join(broadcast(small_df), ["foo"])
#spark版本>=2.2
large_df.join(small_df.hint("broadcast"), ["foo"])
Scala:
import org.apache.spark.sql.functions.broadcast
val smallDF: DataFrame = ???
val largeDF: DataFrame = ???
//spark版本<2.2
largeDF.join(broadcast(smallDF), Seq("foo"))
//spark版本>2.2
largeDF.join(smallDF.hint("broadcast"), Seq("foo"))
SQL
SELECT /*+ MAPJOIN(small) */ * FROM large JOIN small ON large.foo = small.foo
SELECT /*+ BROADCASTJOIN(small) */ * FROM large JOIN small ON large.foo = small.foo
SELECT /*+ BROADCAST(small) */ * FROM large JOIN small ON larger.foo = small.foo
2. 实际案例
2.1 scala
@Test
def sclaBroadcastJoin(): Unit = {
val start = System.currentTimeMillis()
val conf = new SparkConf().setAppName("Test Spark SQL Speed")
conf.set("spark.sql.warehouse.dir", "hdfs://master:8020/user/hive/warehouse")
//调整小表的大小
//注意:如果该值<0,则不开启broadcast join模式
conf.set("spark.sql.autoBroadcastJoinThreshold","1073741824")
val spark = SparkSession.builder()
.config(conf)
.master("local[5]")
.enableHiveSupport()
.getOrCreate()
val small: DataFrame = spark.sql("select * from xh.small").toDF()
small.createOrReplaceTempView("small")
small.cache()
val big: DataFrame = spark.sql("select * from xh.big").toDF()
big.createOrReplaceTempView("big")
//由于我的spark版本为2.3.1,所以使用的是第二张模式
big.join(small.hint("broadcast"),Seq("id"),"left").show(10)
}
2.2. sql
def sqlBroadcastJoin(): Unit = {
val sql = "SELECT /*+ BROADCASTJOIN(mdm_all_tmp) */ DISTINCT m.value, fymx.patientname, fymx.sexname, m1.value, m2.value, m3.value FROM ab_ip_feelist AS fymx LEFT JOIN mdm_all_tmp m ON fymx.hospitalno=m.key AND m.tablename = 'mdm_hospitalinfo' LEFT JOIN mdm_all_tmp m1 ON fymx.deptcode=m1.key AND m1.tablename = 'mdm_dept' LEFT JOIN mdm_all_tmp m2 ON fymx.itemcode=m2.key AND fymx.chargecategorycode in('01','02','03') LEFT JOIN mdm_all_tmp m3 ON fymx.chargecategorycode=m3.key AND m3.tablename = 'mdm_chargeitemcatalog'"
val conf = new SparkConf().setAppName("Test Spark SQL Speed")
conf.set("spark.sql.warehouse.dir", "hdfs://master:8020/user/hive/warehouse")
//调整小表的大小
//注意:如果该值<0,则不开启broadcast join模式
conf.set("spark.sql.autoBroadcastJoinThreshold","1073741824")
val spark = SparkSession.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate()
val small: DataFrame = spark.sql("select * from xh.mdm_all_tmp").toDF()
small.createOrReplaceTempView("mdm_all_tmp")
small.cache()
val big: DataFrame = spark.sql("select * from xh.ab_ip_feelist").toDF()
big.createOrReplaceTempView("ab_ip_feelist")
spark.sql(sql).show(100)
}
3. 其他
presto内也有broadcast join的概念,顺带说一句:
#进入命令行界面
./presto-cli-0.217-executable.jar --server node2:7670 --catalog hive --schema default
#查看所有session配置
show session;
可以看见如下显示:默认模式为:PARTITIONED
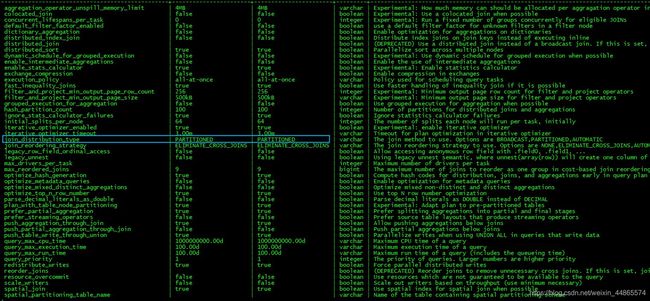
#修改模式,三种模式可以切换使用,目前presto内只有hive连接器能使用broadcast模式
set session join_distribution_type = 'AUTOMATIC';
set session join_distribution_type = 'BROADCAST';
set session join_distribution_type = 'PARTITIONED';
再次查看:
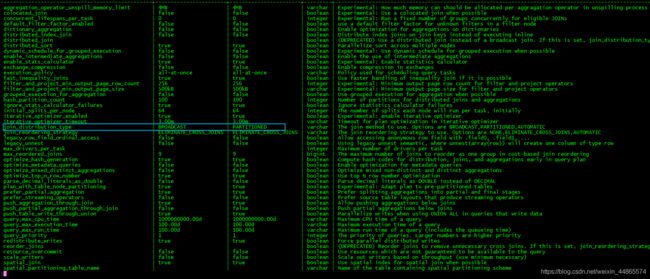
模式切换后即可直接查询;