分布式学习-1 Hadoop Spark安装
前言:折腾了一个多月的时间,成功实现了一些应用。学习过程中还是踩了不少坑的,所以在这里对整个构建过程进行整理,方便大家参考学习。
0.硬件说明
0.1 硬件信息及网络配置
现有三台设备,系统为ubuntu20.04,我们为其设定固定ip。
- node1 192.168.1.111
- node2 192.168.1.112
- node3 192.168.1.113
为了方便起见我们将上述设置信息写入hosts,为host起一个别名。
sudo vim /etc/host
写入以下信息:
192.168.1.111 node1
192.168.1.112 node2
192.168.1.113 node3
0.2 准备工作
注意:以下操作需要在三台设备上操作三次。
python及pip安装
# python安装,pip安装
sudo apt-get install python3 python3-pip
# pip更新
sudo python3 -m pip install --upgrade pip
# pip换清华源
sudo pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
SSH安装及配置
# ssh安装
sudo apt-get install ssh
# ssh生成秘钥
sudo ssh-keygen
# 回车三次即可
到这里ssh的安装就完成了,接下来我们需要设置三台设备之间root用户的免密登录。
-
首先设置root的密码
sudo passwd root这里直接输入密码和确认密码,密码输入过程是不可见的。
确认之后会提示密码修改完成。

-
然后修改ssh的配置文件,允许其他设备可以通过ssh登录root用户。
sudo vim /ets/ssh/这里只修改两个地方
# 允许root登录 改为yes PermitRootLogin yes # 公钥许可 改为yes PubkeyAuthentication yes修改后的记结果如下图(这里只截取了修改的部分)

-
最后是免密登录
sudo ssh-copy-id node1 sudo ssh-copy-id node2 sudo ssh-copy-id node3在输入命令之后输入之前设置的root密码就可以。
1.hadoop安装及配置
首先简单介绍一下hadoop和spark的关系。
hadoop是一个完整的框架,包括:
- 文件管理系统(具体而言是hadoop的分布式文件管理系统,即hdfs)
- 资源管理系统(具体而言是hadoop的资源管理系统,即yarn)
- 分布式计算框架(具体而言是hadoop的分布式计算框架,即MapReduce)
spark自身是一个优秀的分布式计算框架,在上述的框架中可以代替MapReduce,与hdfs和yarn进行组合进行分布式计算。
1.1 安装
注意:以下操作在node1中的root用户下完成。
# 切换root用户
su root
# 输入之前设置的root密码即可
首先是java安装包和hadoop安装包的下载:
-
java安装包,版本jdk8,下载地址:https://www.oracle.com/java/technologies/downloads/#java8
(需要注册登录) -
hadoop安装包,版本3.3(及以上),下载地址:https://hadoop.apache.org/releases.html
我们将安装包存放在/usr/local这一目录下(目录没有强制的要求,按照个人习惯来就行),进入/usr/local目录,进行解压,软连接等操作。
# 进入目录
cd /usr/local/
# 解压
tar -zxvf jdk*
tar -zxvf hadoop*
# 删除压缩包
rm jdk*.tar.gz hadoop*.tar.gz
# 设置软连接(这个也是为了方便操作)
ln -s jdk* jdk
ln -s hadoop* hadoop
然后是环境变量的设置。
vim /etc/profile
在环境变量中写入以下信息:
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin:$PATH
使配置生效:
source /etc/profile
到这里java的安装配置完成了。我们可以测试以下:
java -version
见到下图显示的内容配置完成。

1.2 单一节点配置
注意:以下操作继续在node1中的root用户下完成。
将目录切换到/usr/local/hadoop/etc/hadoop,修改其中的配置文件。
cd /usr/local/hadoop/etc/hadoop/
-
修改hadoop-env.sh
vim hadoop-env.sh写入以下内容:
export JAVA_HOME=/usr/local/jdk export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root保存并退出。
-
修改core-site.xml
vim core-site.xml在
和 之间写入以下内容:<property> <name>fs.defaultFSname> <value>hdfs://node1:8020value> property> <property> <name>hadoop.tmp.dirname> <value>/usr/local/hadoopvalue> property> <property> <name>hadoop.http.staticuser.username> <value>rootvalue> property> <property> <name>hadoop.proxyuser.root.hostsname> <value>*value> property> <property> <name>hadoop.proxyuser.root.groupsname> <value>*value> property> <property> <name>fs.trash.intervalname> <value>1440value> property>保存并退出。
-
修改hdfs-site.xml
vim hdfs-site.xml在
和 之间写入以下内容:<property> <name>dfs.namenode.secondary.http-addressname> <value>node2:9868value> property>退出并保存。
-
修改mapred-site.xml
vim mapred-site.xml在
和 之间写入以下内容:<property> <name>mapreduce.framework.namename> <value>yarnvalue> property> <property> <name>mapreduce.jobhistory.addressname> <value>node1:10020value> property> <property> <name>mapreduce.jobhistory.webapp.addressname> <value>node1:19888value> property> <property> <name>yarn.app.mapreduce.am.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property> <property> <name>mapreduce.map.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property> <property> <name>mapreduce.reduce.envname> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value> property>保存并退出。
-
修改yarn-site.xml
vim yarn-site.xml在
和 之间写入以下内容:<property> <name>yarn.resourcemanager.hostnamename> <value>node1value> property> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.nodemanager.pmem-check-enabledname> <value>falsevalue> property> <property> <name>yarn.nodemanager.vmem-check-enabledname> <value>falsevalue> property> <property> <name>yarn.log-aggregation-enablename> <value>truevalue> property> <property> <name>yarn.log.server.urlname> <value>http://node1:19888/jobhistory/logsvalue> property> <property> <name>yarn.log-aggregation.retain-secondsname> <value>604800value> property>保存并退出。
-
修改works
vim workers直接写入以下内容
node1 node2 node3保存并退出。
以上是所有的hadoop文件的配置过程。
1.3 多节点配置
我们将node1中的jdk文件夹和hadoop文件夹复制到node2和node3,在完成ssh免密登录后我们可以通过scp指令完成。
# 在node1节点中
# 复制文件
cd /usr/local/
scp -r jdk1.8.* node2:$PWD
scp -r jdk1.8.* node3:$PWD
scp -r hadoop-3.* node2:$PWD
scp -r hadoop-3.* node3:$PWD
# 复制环境变量
cd /etc/
scp profile node2:$PWD
scp profile node3:$PWD
在node2和node3中创建软连接,更新环境变量。
# 在node2和node3都要进行以下操作
# 设置软连接
ln -s jdk* jdk
ln -s hadoop* hadoop
# 配置生效
source /etc/profile
1.4 hadoop启动
文件系统初始化。
hdfs namenode -format
hadoop启停:
# 在node1启动即可
# 启动hdfs
start-dfs.sh
# 关闭hdfs
stop-dfs.sh
# 启动yarn
start-yarn.sh
# 关闭yarn
stop-yarn.sh
# 同时启动hdfs和yarn
start-all.sh
# 同时关闭hdfs和yarn
stop-all.sh
在启动所有的节点后我们可以通过jps查看进程。
-
下图是node1的进程:

对于hdfs而言,node1有2个进程,分别是NameNode和DataNode。
对于yarn而言,node1有2个进程,分别是ResourceManager和NodeManager。 -
下图是node2的进程:

对于hdfs而言,node2有2个进程,分别是SecondaryNameNode和DataNode。
对于yarn而言,node2有1个进程,是NodeManager。 -
下图是node3的进程:

对于hdfs而言,node3有1个进程,是DataNode。
对于yarn而言,node3有1个进程,是NodeManager。
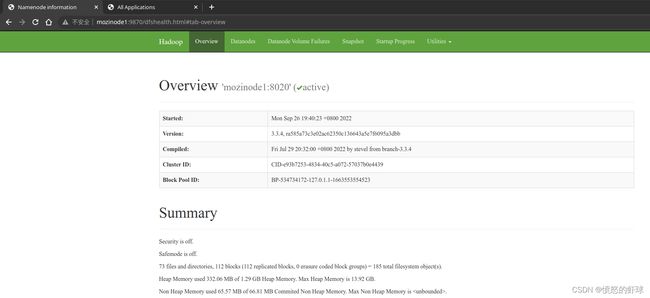
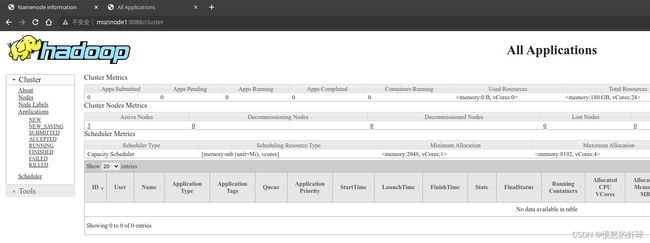
我们也可以从web端查看集群的文件系统和任务状态。
文件系统的端口是9870
任务状态信息的端口是8088
2.Spark安装与配置
2.1 安装
注意:以下操作在node1中的root用户下完成。
首先是spark安装包的下载:
- spark安装包,版本3.2,下载地址:https://spark.apache.org/downloads.html
- 说明:目前貌似有更新的版本,但是我的应用场景偏向于图,新版本对graphframes貌似并不支持,所以我选择了3.2。
与之前的操作类似,我们将安装包存放在/usr/local这一目录下,进入/usr/local目录,进行解压,软连接等操作。
# 进入目录
cd /usr/local/
# 解压
tar -zxvf spark*
# 删除压缩包
rm spark*.tgz
# 设置软连接
ln -s spark* spark
然后是环境变量的设置。
vim /etc/profile
在环境变量中写入以下信息:
export SPARK_HOME=/usr/local/spark
export PATH=${SPARK_HOME}/bin:$PATH
使配置生效:
source /etc/profile
到这里spark的安装配置完成了。
说明这里并没有对spark的sbin进行环境变量的设置,hadoop/sbin和spark/sbin目录下的指令会发生冲突。
2.2 单一节点配置
注意:以下操作继续在node1中的root用户下完成。
将目录切换到/usr/local/spark/conf/,修改其中的配置文件。
cd /usr/local/spark/conf/
-
修改spark-env.sh
# 重命名 mv spark-env.sh.template spark-env.sh vim spark-env.sh在最后写入以下内容:
## java path JAVA_HOME=/usr/local/jdk ## HADOOP path HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop ## spark master SPARK_MASTER_HOST=node1 SPARK_MASTER_PORT=7077 SPARK_MASTER_WEBUI_PORT=8080 # worker cpu SPARK_WORKER_CORES=2 # worker memory SPARK_WORKER_MEMORY=4g SPARK_WORKER_PORT=7078 SPARK_WORKER_WEBUI_PORT=8081 ## history server SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"注意:
1.jdk和hadoop的地址需要注意。
2.节点的资源可以根据自身设备的配置进行调整。 -
修改spark-defaults.conf
# 重命名 mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf在最后写入以下内容:
spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:8020/sparklog/ spark.eventLog.compress true -
修改workers
# 重命名 mv workers.template workers vim workers删除最后一行的localhost,在最后写入以下内容:
node1 node2 node3
以上是所有的spark文件的配置过程。
2.3 多节点配置
与hadoop类似在这一阶段对文件进行分发。
# 在node1节点中
# 复制文件
cd /usr/local/
scp -r spark-3.* node2:$PWD
scp -r spark-3.* node3:$PWD
# 复制环境变量
cd /etc/
scp profile node2:$PWD
scp profile node3:$PWD
在node2和node3中创建软连接,更新环境变量。
# 在node2和node3都要进行以下操作
# 设置软连接
ln -s spark* spark
# 配置生效
source /etc/profile
2.4 spark启动
根据上述的配置文件我们在hdfs中创建一个文件夹,用于存放spark的日志文件。
hadoop fs -mkdir /sparklog/
进入/usr/local/spark/sbin/目录:
# 启动历史服务器
./start-history-server.sh
# 停止历史服务器
./stop-history-server.sh
# 启动
./start-all.sh
# 关闭
./stop-all.sh
首先还是查看jps进程。
-
下图是node1的进程:

可以看到除了之前的进程之外多了三个进程,分别是spark的Master进程、Worker进程和HistoryServer进程。 -
下图是node2的进程:

node2多了一个进程,是Worker。 -
下图是node3的进程:

node3多了一个进程,是Worker。
spark同样也有web端,端口是8080。

2.5 三种模式下的测试
我们都通过pyspark进行测试:
-
local
pyspark --master local[*]可以看到以下结果:

-
standalone
pyspark --master spark://node1:7077可以看到以下结果:
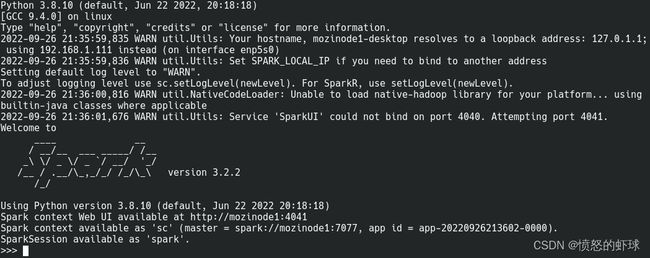
-
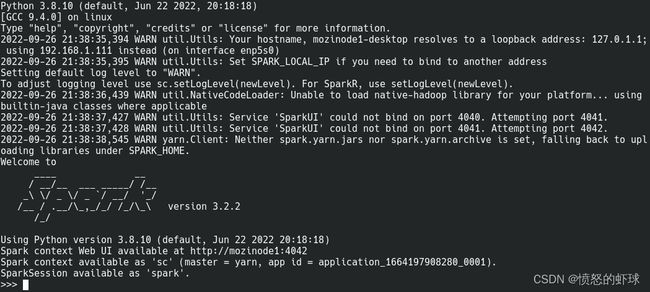
yarn
pyspark --master yarn可以看到以下结果:
后语:
整个配置还是比较繁琐的,中间参数设置的部分参考了黑马程序员教程中的参数设置,在此感谢。
同时感谢Joker_724、hadesmisss对本篇博客的贡献。
后续还会更新参数的一些说明,分布式图计算(pyspark+GraphFrames),以及spark on k8s的相关内容。