【SQL语句复习】第1-2章
SQL复习
学习目标:复习SQL语句
学习地址:https://linklearner.com/learn/detail/70
第一章 初始数据库
数据库是将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合。该数据集合称为数据库(Database,DB)。用来管理数据库的计算机系统称为数据库管理系统(Database Management System,DBMS)。
1.1 DBMS的种类
DBMS 主要通过数据的保存格式(数据库的种类)来进行分类,现阶段主要有以下 5 种类型.
-
层次数据库(Hierarchical Database,HDB)
-
关系数据库(Relational Database,RDB)
- Oracle Database:甲骨文公司的RDBMS
- SQL Server:微软公司的RDBMS
- DB2:IBM公司的RDBMS
- PostgreSQL:开源的RDBMS
- MySQL:开源的RDBMS
如上是5种具有代表性的RDBMS,其特点是由行和列组成的二维表来管理数据,这种类型的 DBMS 称为关系数据库管理系统(Relational Database Management System,RDBMS)。
-
面向对象数据库(Object Oriented Database,OODB)
-
XML数据库(XML Database,XMLDB)
-
键值存储系统(Key-Value Store,KVS),举例:MongoDB
本课程将向大家介绍使用 SQL 语言的数据库管理系统,也就是关系数据库管理系统(RDBMS)的操作方法。
1.2 RDBMS关系数据库管理系统
使用 RDBMS 时,最常见的系统结构就是客户端 / 服务器类型(C/S类型)这种结构

1.3 初始SQL

数据库中存储的表结构类似于excel中的行和列,在数据库中,行称为记录,它相当于一条记录,列称为字段,它代表了表中存储的数据项目。
根据对 RDBMS 赋予的指令种类的不同,SQL 语句可以分为以下三类.
- DDL :DDL(Data Definition Language,数据定义语言) 用来创建或者删除存储数据用的数据库以及数据库中的表等对象。DDL 包含以下几种指令。
- CREATE : 创建数据库和表等对象
- DROP : 删除数据库和表等对象
- ALTER : 修改数据库和表等对象的结构
- DML :DML(Data Manipulation Language,数据操纵语言) 用来查询或者变更表中的记录。DML 包含以下几种指令。
- SELECT :查询表中的数据
- INSERT :向表中插入新数据
- UPDATE :更新表中的数据
- DELETE :删除表中的数据
- DCL :DCL(Data Control Language,数据控制语言) 用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对 RDBMS 的用户是否有权限操作数据库中的对象(数据库表等)进行设定。DCL 包含以下几种指令。
- COMMIT : 确认对数据库中的数据进行的变更
- ROLLBACK : 取消对数据库中的数据进行的变更
- GRANT : 赋予用户操作权限
- REVOKE : 取消用户的操作权限
实际使用的 SQL 语句当中有 90% 属于 DML,本书同样会以 DML 为中心进行讲解。
1.4 SQL的基本书写规则
- SQL语句要以分号( ; )结尾
- SQL 不区分关键字的大小写,但是插入到表中的数据是区分大小写的
- 单词需要用半角空格或者换行来分隔
SQL 语句的单词之间需使用半角空格或换行符来进行分隔,且不能使用全角空格作为单词的分隔符,否则会发生错误,出现无法预期的结果。
1.5 数据库的基本操作
创建数据库:
CREATE DATABASE <数据库名称>;
创建本课程使用的数据库:
CREATE DATABASE shop;

使用当前数据库:
use <数据库名>;
use shop;
表的创建:
CREATE TABLE <表名>
(<列名1><数据类型><该列所需约束>,
<列名1><数据类型><该列所需约束>,
<列名1><数据类型><该列所需约束>,
<列名1><数据类型><该列所需约束>,
.
.
<列名1><数据类型><该列所需约束>,....
);
创建本课程使用的数据库:
CREATE TABLE product
(product_id CHAR(4) NOT NULL,
product_name varchar(100) NOT NULL,
product_type varchar(32) NOT NULL,
sale_price integer ,
purchase_price integer,
regist_date date,
primary key(product_id)
);

命名规则
-
只能使用半角英文字母、数字、下划线(_)作为数据库、表和列的名称
-
名称必须以半角英文字母开头
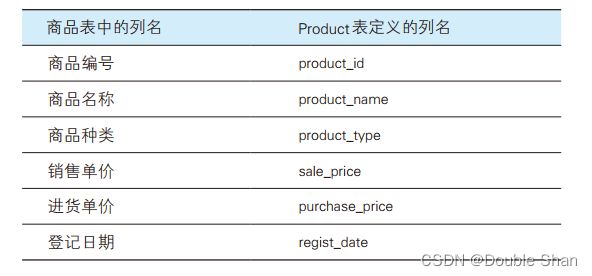
表1-3 商品表和 product 表列名的对应关系
数据类型的指定
数据库创建的表,所有的列都必须指定数据类型,每一列都不能存储与该列数据类型不符的数据。
四种最基本的数据类型
- INTEGER 型
用来指定存储整数的列的数据类型(数字型),不能存储小数。
- CHAR 型
用来存储定长字符串,当列中存储的字符串长度达不到最大长度的时候,使用半角空格进行补足,由于会浪费存储空间,所以一般不使用。
- VARCHAR 型
用来存储可变长度字符串,定长字符串在字符数未达到最大长度时会用半角空格补足,但可变长字符串不同,即使字符数未达到最大长度,也不会用半角空格补足。
- DATE 型
用来指定存储日期(年月日)的列的数据类型(日期型)。
约束
约束是除了数据类型之外,对列中存储的数据进行限制或者追加条件的功能。
NOT NULL是非空约束,即该列必须输入数据。
PRIMARY KEY是主键约束,代表该列是唯一值,可以通过该列取出特定的行的数据。
表的数据插入
INSERT into <表名>(列1,列2,列3,...) VALUES(值1,值2,值3,...);
对表进行全列 INSERT 时,可以省略表名后的列清单。这时 VALUES子句的值会默认按照从左到右的顺序赋给每一列。
本例子中:
INSERT into product VALUES('0001','T恤衫','衣服','1000','500','2009-09-20');
INSERT INTO product VALUES('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO product VALUES('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO product VALUES('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO product VALUES('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO product VALUES('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO product VALUES('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO product VALUES('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');
也可多行插入
INSERT into product VALUES('0001','T恤衫','衣服','1000','500','2009-09-20');
VALUES('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
VALUES('0003', '运动T恤', '衣服', 4000, 2800, NULL);
VALUES('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
VALUES('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
VALUES('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
VALUES('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
VALUES('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');
也可以使用INSERT…SELECT语句从其他表复制数据
--将商品表中的数据复制到商品复制表中
insert into productcopy(product_id,product_name,product_type,sale_price,purchase_price,regist_date)
select product_id,product_name,product_type,sale_price,purchase_price,regist_date from product;
表的删除和更新
删除表的语法:
DROP TABLE <表名>;
删除product表
需要特别注意的是,删除的表是无法恢复的,只能重新插入,请执行删除操作时奥特别谨慎。
DROP TABLE product;
添加列的ALTER TABLE 语句
ALTER TABLE <表名> ADD COLUMN <列的定义>;
添加一列可以存储100位的可变长字符串的product_name_pinyin列
ALTER TABLE product ADD COLUMN product_name_pinyin vARCHAR(100);
删除product_name_pinyin列
ALTER TABLE product DROP COLUMN product_name_pinyin;
删除表中特定的列(语法)
DELETE FROM product WHERE COLUMN_NAME='xxx';
ALTER TABLE 语句和 DROP TABLE 语句一样,执行之后无法恢复。误添加的列可以通过 ALTER TABLE 语句删除,或者将表全部删除之后重新再创建。 【扩展内容】
清空表内容
TRUNCATE TABLE TABLE_NAME;
优点:相比drop / delete,truncate用来清除数据时,速度最快。
数据的更新
基本语法:
UPDATE <表名>
SET <列名>=<表达式>[,<列名2>=<表达式2>...]
WHERE<条件>--可选,非常重要
ORDER BY 子句 --可选
limit 子句; --可选
使用 update 时要注意添加 where 条件,否则将会将所有的行按照语句修改
-- 修改所有的注册时间
UPDATE product
SET regist_date = '2009-10-10';
-- 仅修改部分商品的单价
UPDATE product
SET sale_price = sale_price * 10
WHERE product_type = '厨房用具';
使用 UPDATE 也可以将列更新为 NULL(该更新俗称为NULL清空)。此时只需要将赋值表达式右边的值直接写为 NULL 即可。
-- 将商品编号为0008的数据(圆珠笔)的登记日期更新为NULL
UPDATE product
SET regist_date = NULL
WHERE product_id = '0008';
和 INSERT 语句一样, UPDATE 语句也可以将 NULL 作为一个值来使用。 **但是,只有未设置 NOT NULL 约束和主键约束的列才可以清空为NULL。**如果将设置了上述约束的列更新为 NULL,就会出错,这点与INSERT 语句相同。
索引
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
如何创建索引
创建表时可以直接创建索引,语法如下:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX[indexName](username(length))
);
还可以使用如下语句创建:
-- 方法一
CREATE INDEX indexName ON table_name(column_name)
--方法二
CREATE TABLE tableName ADD INDEX indexName(column_name)
-
索引分类
- 主键索引
建立在主键上的索引被称为主键索引,一张数据表只能有一个主键索引,索引列值不允许有空值,通常在创建表时一起创建。
- 唯一索引
建立在UNIQUE字段上的索引被称为唯一索引,一张表可以有多个唯一索引,索引列值允许为空,列值中出现多个空值不会发生重复冲突。
- 普通索引
建立在普通字段上的索引被称为普通索引。
- 前缀索引
前缀索引是指对字符类型字段的前几个字符或对二进制类型字段的前几个bytes建立的索引,而不是在整个字段上建索引。前缀索引可以建立在类型为char、varchar、binary、varbinary的列上,可以大大减少索引占用的存储空间,也能提升索引的查询效率。
- 全文索引
利用“分词技术”实现在长文本中搜索关键字的一种索引。
语法:
SELECT * FROM article WHERE MATCH (col1,col2,...) AGAINST (expr [ search _ modifier ])1、MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
2、MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
3、只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
4、如果可能,请尽量先创建表并插入所有数据后再创建全文索引,而不要在创建表时就直接创建全文索引,因为前者比后者的全文索引效率要高。
- 单列索引
建立在单个列上的索引被称为单列索引。
- 联合索引(复合索引、多列索引)
建立在多个列上的索引被称为联合索引,又叫复合索引、组合索引。
练习题

CREATE TABLE Addressbook(
regist_no integer not null,
name VARCHAR(128) not null,
address VARCHAR(256) not null,
tel_no char(10) ,
mail_address char(20) ,
primary key(regist_no)
);
第二章 基础查询
2.1 SELECT语句基础
从表中选取数据
SELECT语句
从表中选取数据时需要使用SELECT语句,也就是只从表中选出(SELECT)必要数据的意思。通过SELECT语句查询并选取出必要数据的过程称为匹配查询或查询(query)。
基本SELECT语句包含了SELECT和FROM两个子句(clause)。示例如下:
SELECT <列名>,
FROM <表名>;
其中,SELECT子句中列举了希望从表中查询出的列的名称,而FROM子句则指定了选取出数据的表的名称。
从表中选取符合条件的数据
WHERE语句
当不需要取出全部数据,而是选取出满足“商品种类为衣服”“销售单价在1000日元以上”等某些条件的数据时,使用WHERE语句。
SELECT 语句通过WHERE子句来指定查询数据的条件。在WHERE 子句中可以指定“某一列的值和这个字符串相等”或者“某一列的值大于这个数字”等条件。执行含有这些条件的SELECT语句,就可以查询出只符合该条件的记录了。
SELECT <列名>, ……
FROM <表名>
WHERE <条件表达式>;
比较下面两者输出结果的不同:
-- 用来选取product type列为衣服的记录的SELECT语句
SELECT product_name, product_type
FROM product
WHERE product_type = '衣服';
-- 也可以选取出不是查询条件的列(条件列与输出列不同)
SELECT product_name
FROM product
WHERE product_type = '衣服';
结果:输出的结果中前面是两列,后面是一列
相关法则
- 星号(*)代表全部列的意思。
- SQL中可以随意使用换行符,不影响语句执行(但不可插入空行)。
- 设定汉语别名时需要使用双引号(")括起来。
- 在SELECT语句中使用DISTINCT可以删除重复行。
- 注释是SQL语句中用来标识说明或者注意事项的部分。分为1行注释"-- “和多行注释两种”/* */"。
-- 想要查询出全部列时,可以使用代表所有列的星号(*)
SELECT * from product;
-- SQL语句可以使用AS关键字为列设定别名(用中文时需要双引号(“”))。
SELECT product_id as id,
product_name as name,
purchase_price as "进货单价"
FROM product;
-- 使用DISTINCT删除product_type列中重复的数据
SELECT distinct product_type
FROM product;
2.2 算术运算符和比较运算符
算术运算符
SQL语句中可以使用的四则运算的主要运算符如下:
| 含义 | 运算符 |
|---|---|
| 加法 | + |
| 减法 | - |
| 乘法 | * |
| 除法 | / |
比较运算符
| 运算符 | 含义 |
|---|---|
| = | 和 ~ 相等 |
| <> | 和 ~ 不相等 |
| >= | 大于等于 ~ |
| > | 大于 ~ |
| <= | 小于等于 ~ |
| < | 小于 ~ |
-- 选取出sale_price列为500的记录
SELECT product_name, product_type
FROM product
WHERE sale_price = 500;
常见法则
- SELECT子句中可以使用常数或者表达式。
- 使用比较运算符时一定要注意不等号和等号的位置。
- 字符串类型的数据原则上按照字典顺序进行排序,不能与数字的大小顺序混淆。
- 希望选取NULL记录时,需要在条件表达式中使用IS NULL运算符。希望选取不是NULL的记录时,需要在条件表达式中使用IS NOT NULL运算符。
-- SQL语句中也可以使用运算表达式
SELECT product_name, sale_price, sale_price * 2 AS "sale_price x2"
FROM product;
-- WHERE子句的条件表达式中也可以使用计算表达式
SELECT product_name, sale_price, purchase_price
FROM product
WHERE sale_price - purchase_price >= 500;
/* 对字符串使用不等号
首先创建chars并插入数据
选取出大于‘2’的SELECT语句*/
-- DDL:创建表
CREATE TABLE chars
(chr CHAR(3)NOT NULL,
PRIMARY KEY(chr));
-- 选取出大于'2'的数据的SELECT语句('2'为字符串)
SELECT chr
FROM chars
WHERE chr > '2';
-- 选取NULL的记录
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NULL;
-- 选取不为NULL的记录
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NOT NULL;
2.3 逻辑运算符
NOT 运算符
想要表示 不是…… 时,除了前文的<>运算符外,还存在另外一个表示否定、使用范围更广的运算符:NOT。
NOT不能单独使用,必须和其他查询条件组合起来使用。如下例:
选取出销售单价大于等于1000日元的记录
select product_name,product_type,sale_price
from product
where sale_price>=1000;

select product_name,product_type,sale_price
from product
where not sale_price>=1000;

可以看出,通过否定销售单价大于等于 1000 日元 (sale_price >= 1000) 这个查询条件,选取出了销售单价小于 1000 日元的商品。也就是说 NOT sale_price >= 1000 与 sale_price < 1000 是等价的。
值得注意的是,虽然通过 NOT 运算符否定一个条件可以得到相反查询条件的结果,但是其可读性明显不如显式指定查询条件,因此,不可滥用该运算符。
AND运算符和OR运算符
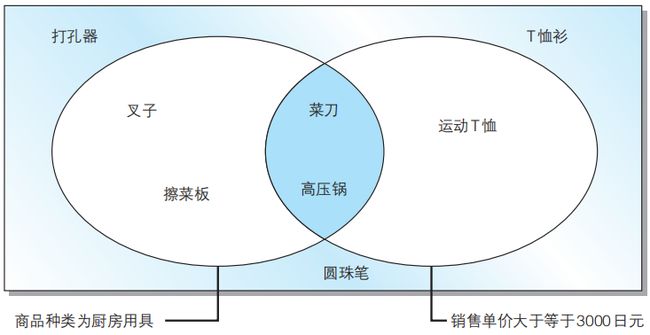
当希望同时使用多个查询条件时,可以使用AND或者OR运算符。
AND 相当于“并且”,类似数学中的取交集;
OR 相当于“或者”,类似数学中的取并集。
如下图所示:
AND运算符工作效果图
OR运算符工作效果图
通过括号优先处理
如果要查找这样一个商品,该怎么处理?
“商品种类为办公用品”并且“登记日期是 2009 年 9 月 11 日或者 2009 年 9 月 20 日” 理想结果为“打孔器”,但当你输入以下信息时,会得到错误结果
-- 将查询条件原封不动地写入条件表达式,会得到错误结果
SELECT product_name, product_type, regist_date
FROM product
WHERE product_type = '办公用品'
AND regist_date = '2009-09-11'
OR regist_date = '2009-09-20';
错误的原因是 AND 运算符优先于 OR 运算符 ,想要优先执行OR运算,可以使用 括号 :
-- 通过使用括号让OR运算符先于AND运算符执行
SELECT product_name, product_type, regist_date
FROM product
WHERE product_type = '办公用品'
AND ( regist_date = '2009-09-11'
OR regist_date = '2009-09-20');
运算符优先级请参考下图

真值表
复杂运算时该怎样理解?
当碰到条件较复杂的语句时,理解语句含义并不容易,这时可以采用真值表来梳理逻辑关系。
什么是真值?
本节介绍的三个运算符 NOT、AND 和 OR 称为逻辑运算符。这里所说的逻辑就是对真值进行操作的意思。真值就是值为真(TRUE)或假 (FALSE)其中之一的值。
例如,对于 sale_price >= 3000 这个查询条件来说,由于 product_name 列为 ‘运动 T 恤’ 的记录的 sale_price 列的值是 2800,因此会返回假(FALSE),而 product_name 列为 ‘高压锅’ 的记录的sale_price 列的值是 5000,所以返回真(TRUE)。
AND 运算符两侧的真值都为真时返回真,除此之外都返回假。
OR 运算符两侧的真值只要有一个不为假就返回真,只有当其两侧的真值都为假时才返回假。
NOT运算符只是单纯的将真转换为假,将假转换为真。
真值表

查询条件为P AND(Q OR R)的真值表

那该如何表示呢?
这时真值是除真假之外的第三种值——不确定(UNKNOWN)。一般的逻辑运算并不存在这第三种值。SQL 之外的语言也基本上只使用真和假这两种真值。与通常的逻辑运算被称为二值逻辑相对,只有 SQL 中的逻辑运算被称为三值逻辑。
三值逻辑下的AND和OR真值表为:

练习题
1、编写一条SQL语句,从 product(商品) 表中选取出“登记日期(regist_date)在2009年4月28日之后”的商品,查询结果要包含 product name 和 regist_date 两列。
SELECT product_name ,regist_date
FROM product
WHERE regist_date>2009-4-28;
2、请说出对product 表执行如下3条SELECT语句时的返回结果。
SELECT *
FROM product
WHERE purchase_price = NULL;
SELECT *
FROM product
WHERE purchase_price <> NULL;
SELECT *
FROM product
WHERE product_name > NULL;
3条SELECT语句都是这个结果

概念上,NULL意味着“没有值”或“未知值”,且它被看作与众不同的值。为了测试NULL,你不能使用算术比较 操作符例如=、<或!=。相反使用IS NULL和IS NOT NULL操作符。
3、上面章节中的SELECT语句能够从 product 表中取出“销售单价(sale_price)比进货单价(purchase_price)高出500日元以上”的商品。请写出两条可以得到相同结果的SELECT语句。执行结果如下所示:
SELECT product_name,sale_price,purchase_price
FROM product
WHERE not sale_price-purchase_price<500;
select product_name,sale_price,purchase_price
from product
where sale_price-purchase_price >= 500;
2.4 对表进行聚合查询
聚合函数
SQL中用于汇总的函数叫做聚合函数。以下五个是最常用的聚合函数:
- SUM:计算表中某数值列中的合计值
- AVG:计算表中某数值列中的平均值
- MAX:计算表中任意列中数据的最大值,包括文本类型和数字类型
- MIN:计算表中任意列中数据的最小值,包括文本类型和数字类型
- COUNT:计算表中的记录条数(行数)
如:
-- 计算销售单价和进货单价的合计值
SELECT sum(sale_price),sum(purchase_price)
FROM product;
-- 计算销售单价和进货单价的平均值
SELECT avg(sale_price),AVG(purchase_price)
from product;
-- 计算全部数据的行数(包含 NULL 所在行)
SELECT COUNT(*)
FROM product;
使用 DISTINCT 进行删除重复值的聚合运算
当对整表进行聚合运算时,表中可能存在多行相同的数据,比如商品类型(product_type 列)。
在某些场景下,就不能直接使用聚合函数进行聚合运算了,必须搭配 DISTINCT 函数使用。
比如:要计算总共有几种咖啡类型在售,该怎么计算呢?
如前所述,DISTINCT 函数用于删除重复数据,应用 COUNT 聚合函数之前,加上 DISTINCT 关键字就可以实现需求。
聚合函数应用法则
- COUNT 聚合函数运算结果与参数有关,COUNT(*) / COUNT(1) 得到包含 NULL 值的所有行,COUNT(<列名>) 得到不包含 NULL 值的所有行。
- 聚合函数不处理包含 NULL 值的行,但是 COUNT(*) 除外。
- MAX / MIN 函数适用于文本类型和数字类型的列,而 SUM / AVG 函数仅适用于数字类型的列。
- 在聚合函数的参数中使用 DISTINCT 关键字,可以得到删除重复值的聚合结果。
2.5 对表进行分组
GROUP BY语句
之前使用聚合函数都是会将整个表的数据进行处理,当你想将进行分组汇总时(即:将现有的数据按照某列来汇总统计),GROUP BY可以帮助你:
SELECT <列名1>,<列名2>,<列名3>,....
FROM <表名>
GROUP BY <列名1>,<列名2>,<列名3>,....;
看一看是否使用GROUP BY语句的差异:
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type;

-- 不含GROUP BY
SELECT product_type,COUNT(*)
FROM product
注:这里会报错:In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column ‘shop.product.product_type’; this is incompatible with sql_mode=only_full_group_by
因为查询语句意义不明,所以无法返回一个关系比较合理的表,为了使返回结果合理,需要明确以什么为分组依据,此时用到group by语句

这样,GROUP BY 子句就像切蛋糕那样将表进行了分组。在 GROUP BY 子句中指定的列称为聚合键或者分组列。
聚合键中包含NULL时
将进货单价(purchase_price)作为聚合键举例
SELECT purchase_price, COUNT(*)
FROM product
GROUP BY purchase_price;
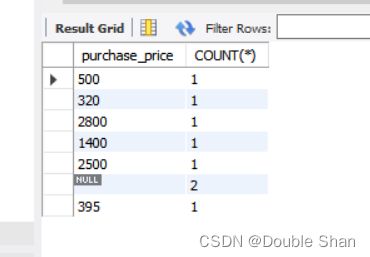
此时会将NULL作为一组特殊数据进行聚合运算。
GROUP BY书写位置
GROUP BY的子句书写顺序有严格要求,不按要求会导致SQL无法正常执行,目前出现过的子句顺序为:
- SELECT ➡️ 2. FROM ➡️ 3. WHERE ➡️ 4. GROUP BY
其中前三项用于筛选数据,GROUP BY对筛选出的数据进行处理
在WHERE子句中使用GROUP BY
SELECT purchase_price, COUNT(*)
FROM product
WHERE product_type = '衣服'
GROUP BY purchase_price;

常见错误
- 在聚合函数的SELECT子句中写了聚合键以外的列使用COUNT等聚合函数时,SELECT子句中如果出现列名,只能是GROUP BY子句中指定的列名(也就是聚合键)。
- 在GROUP BY子句中使用列的别名SELECT子句中可以通过AS来指定别名,但在GROUP BY中不能使用别名。因为在DBMS中 ,SELECT子句在GROUP BY子句后执行。
- 在WHERE中使用聚合函数原因是聚合函数的使用前提是结果集已经确定,而WHERE还处于确定结果集的过程中,所以相互矛盾会引发错误。 如果想指定条件,可以在SELECT,HAVING(下面马上会讲)以及ORDER BY子句中使用聚合函数。
2.6 用HAVING得到特定的分组
前面学习了如何得到分组聚合结果,现在大家思考一下,如何得到分组聚合结果的部分结果呢?
将表使用 GROUP BY 分组后,怎样才能只取出其中两组?
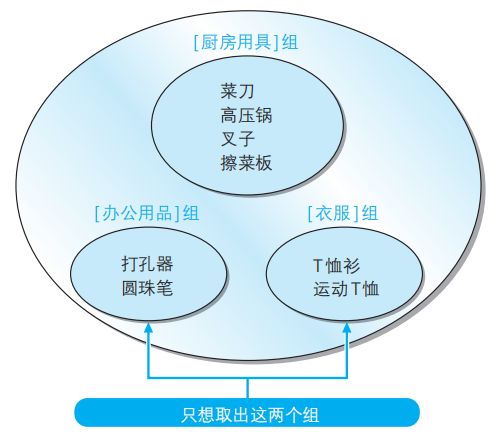
这里 WHERE 不可行,因为,WHERE子句只能指定记录(行)的条件,而不能用来指定组的条件(例如,“数据行数为 2 行”或者“平均值为 500”等)。
可以在 GROUP BY 后使用 HAVING 子句。
HAVING 的用法类似 WHERE。
值得注意的是:HAVING 子句必须与 GROUP BY 子句配合使用,且限定的是分组聚合结果,WHERE 子句是限定数据行(包括分组列),二者各司其职,不要混淆。
HAVING特点
HAVING子句用于对分组进行过滤,可以使用常数、聚合函数和GROUP BY中指定的列名(聚合键)。
-- 常数
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type
HAVING COUNT(*) = 2;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kUFODrRR-1690284630420)(C:\Users\Ga\AppData\Roaming\Typora\typora-user-images\image-20230725162214476.png)]
错误形式
-- 错误形式(因为product_name不包含在GROUP BY聚合键中)
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type
HAVING product_name = '圆珠笔';
2.7 对查询结果进行排序
ORDER BY
在某些场景下,需要得到一个排序之后的结果,比如运动员在奥运赛场的得分,组委会用得分倒序结果来判定金银铜牌到底花落谁家。而 SQL 语句执行结果默认随机排列,想要按照顺序排序,需使用 ORDER BY 子句。
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
ORDER BY <排序基准列1> [ASC, DESC], <排序基准列2> [ASC, DESC], ……
其中,参数 ASC 表示升序排列,DESC 表示降序排列,默认为升序,此时,参数 ASC 可以缺省。
如下代码将得到按照销售价格倒序排列的查询结果:
-- 降序排列
SELECT product_id, product_name, sale_price, purchase_price
FROM product
ORDER BY sale_price DESC;
如果有多列排序需求,只需在 ORDER BY 子句中依次书写排序列 + 排序参数即可,详见如下代码:
详见如下代码:
-- 多个排序键
SELECT product_id, product_name, sale_price, purchase_price
FROM product
ORDER BY sale_price, product_id;
需要特别说明的是:由于 NULL 无法使用比较运算符进行比较,也就是说,无法与文本类型,数字类型,日期类型等进行比较,当排序列存在 NULL 值时,NULL 结果会展示在查询结果的开头或者末尾。
-- 当用于排序的列名中含有NULL时,NULL会在开头或末尾进行汇总。
SELECT product_id, product_name, sale_price, purchase_price
FROM product
ORDER BY purchase_price;
ORDER BY 子句中使用别名
前文讲GROUP BY中提到,GROUP BY 子句中不能使用SELECT 子句中定义的别名,但是在 ORDER BY 子句中却可以使用别名。为什么在GROUP BY中不可以而在ORDER BY中可以呢?
这是因为 SQL 在使用 HAVING 子句时 SELECT 语句的执行顺序为:
FROM → WHERE → GROUP BY → SELECT → HAVING → ORDER BY
其中 SELECT 的执行顺序在 GROUP BY 子句之后,ORDER BY 子句之前。
当在 ORDER BY 子句中使用别名时,已经知道了 SELECT 子句设置的别名,但是在 GROUP BY 子句执行时还不知道别名的存在,所以在 ORDER BY 子句中可以使用别名,但是在GROUP BY中不能使用别名。
ORDER BY 遇上 NULL
在MySQL中,NULL 值被认为比任何 非NULL 值低,因此,当顺序为 ASC(升序)时,NULL 值出现在第一位,而当顺序为 DESC(降序)时,则排序在最后。
如果想指定存在 NULL 的行出现在首行或者末行,需要特殊处理。
使用如下代码构建示例表:
CREATE TABLE user (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
date_login DATE,
PRIMARY KEY (id)
);
INSERT INTO user(name, date_login) VALUES
(NULL, '2017-03-12'),
('john', NULL),
('david', '2016-12-24'),
('zayne', '2017-03-02');
既然排序时,NULL 的值比 非NULL 值低(可以理解为 0 或者 -∞),那么我们在排序时就要对这个默认情况进行特殊处理以达到想要的效果。
一般有如下两种需求:
- 将
NULL值排在末行,同时将所有非NULL值按升序排列。
对于数字或者日期类型,可以在排序字段前添加一个负号(minus)来得到反向排序。(-1、-2、-3....-∞)
SELECT *
FROM user
ORDER BY -date_login DESC;
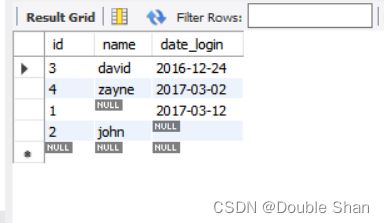
对于字符型或者字符型数字,此方法不一定能得到期望的排序结果,可以使用 IS NULL 比较运算符。另外 ISNULL( ) 函数等同于使用 IS NULL 比较运算符。
-- IS NULL
SELECT * FROM user
ORDER BY name IS NULL ASC,name ASC;
-- ISNULL()
SELECT * FROM user
ORDER BY ISNULL(name) ASC,name ASC;
上述语句先使用 ISNULL(name) 字段进行升序排列,而只有当 name 列值为 NULL 时,ISNULL(name) 才为真,所以其排到末行,而 name ASC 则实现了 非NULL 值升序排列
还可以使用 COALESCE 函数实现需求
SELECT * FROM user
ORDER BY COALESCE(name, 'zzzzz') ASC;

- 将
NULL值排在首行,同时将所有非NULL值按倒序排列。
对于数字或者日期类型,可以在排序字段前添加一个负号(minus)来实现。(-∞...-3、-2、-1)
SELECT * FROM user
ORDER BY -date_login ASC;

对于字符型或者字符型数字,此方法不一定能得到期望的排序结果,可以使用 IS NOT NULL 比较运算符。另外 !ISNULL( ) 函数等同于使用 IS NOT NULL 比较运算符
-- IS NOT NULL
SELECT * FROM user
ORDER BY name IS NOT NULL ASC,name DESC;
-- !ISNULL()
SELECT * FROM user
ORDER BY !ISNULL(name) ASC,name DESC;
上述语句先使用 !ISNULL(name) 字段进行升序排列,而只有当 name 列值不为 NULL 时,!ISNULL(name) 才为真,所以其排到说行,而 name DESC 则实现了 非NULL 值降序排列。
还可以使用 COALESCE 函数实现需求
SELECT * FROM user
ORDER BY COALESCE(name, 'zzzzz') DESC;

练习题
1、请指出下述SELECT语句中所有的语法错误
SELECT product_id, SUM(product_name)
--本SELECT语句中存在错误。
FROM product
GROUP BY product_type
WHERE regist_date > '2009-09-01';
这里很明显就错了,where是对行进行处理,group by是对分组进行处理,所以where不应该在其之后,执行顺序应该是:from-> where ->group by->select
2、请编写一条SELECT语句,求出销售单价( sale_price 列)合计值大于进货单价( purchase_price 列)合计值1.5倍的商品种类。执行结果如下所示。
product_type | sum | sum
-------------+------+------
衣服 | 5000 | 3300
办公用品 | 600 | 320
SELECT product_type,sum(sale_price),sum(purchase_price)
FROM product
group by product_type
Having sum(sale_price)>sum(purchase_price)*1.5;

3、此前我们曾经使用SELECT语句选取出了product(商品)表中的全部记录。当时我们使用了 ORDER BY 子句来指定排列顺序,但现在已经无法记起当时如何指定的了。请根据下列执行结果,思考 ORDER BY 子句的内容。
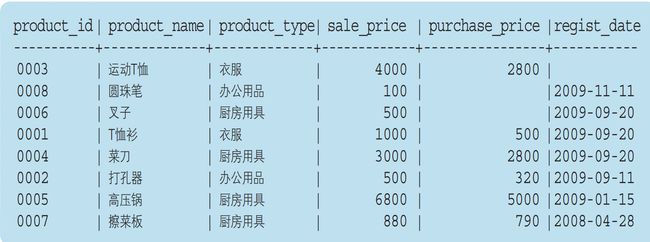
肯定是把日期按照升序排列,但是regist_date会加负号,然后降序。