记一次对Ghidra反编译的修复
前言
Ghidra是NSA在2019年开源的逆向工具,可以说从开源发布开始,就基本成了开源界唯一可以与 IDA
竞争的存在,其它的工具多少总是欠点意思。不过从实际情况来看,虽然
Ghidra一直在积极维护,但是现在的Bug情况跟IDA相比,也还是差点意思。不过,开源的好处,就是可以自己研究自己修复,在我这次参加Defcon资格赛过程中碰到问题的时候,我决定,自力更生,于是有了下面的经历。
##问题
最开始发现问题是在逆Rust的时候,IDA 在逆Rust的时候一向有点问题,这次更是出现了分析出来 500
多个参数的情况,实在让人有点难受。于是我觉得尝试下ghidra ,但是打开发现,虽然没有了 500 多个参数,但是情况也好不了太多,出现了奇妙的情况:

相比之下IDA就没有这种奇怪的东西:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cSGA1AYd-1690267282860)(https://image.3001.net/images/20210620/1624195056_60cf3ff06e3e25f7d0662.png!small)]
我找了半天,当时也没能发现 0x178a97 、0x178aa9
之类的玩意儿是从哪里来的,但是这肯定是个比较严重的问题,因为这基本让反编译没法看了。比赛期间没有办法,只能继续用IDA了。但是赛后这个问题是肯定要处理处理的。
##反编译的原理
反编译基本都可分为这么几步:
基础准备
基础准备:一般就是由反汇编器 来完成的几个步骤,包括:
1. 加载镜像:将文件中的代码、数据分析出来,从而知道内存中某个地址对应文件中的什么数据。
2.
代码识别+反汇编+代码提升(lifting):猜测哪些地方应该是机器代码,然后对机器代码进行解码得到汇编语言,同时还可以将汇编语言进行代码提升,也就是liting,得到中间语言
。之后的分析一般就发生在中间语言上,这样可以避免直接对不同架构的汇编代码进行处理,从而可以方便地支持多架构。
控制流图获取
控制流图获取:这部分开始就是反编译器的工作了(一般来说是)。首先就是需要进行控制流图的获取,控制流图是一种图结构,图上的每一个节点叫做一个基本块
,也就是会连续执行的指令。例如以下的汇编程序:mov eax, 1add ebx, eax ; 假设 ebx 是外部的输入cmp ebx, 0x10jne label1mov ebx, 0x20jmp endlabel1:mov ebx, 0x30end:xor eax, eax这一段程序如果画成控制流图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XTbb28Qk-1690267282860)(https://image.3001.net/images/20210620/1624195622_60cf4226af0c03c9445f4.png!small)]
每一个基本块一旦进入就一定会执行到结尾。这样做之后,就会让分析更加方便,因为以前我们只能以一句汇编为一个单位进行分析,现在就可以一个基本块为一个单位进行分析了。另外,有了图的结构,也比较清晰的知道一个基本块之后可以走到什么分支了。最后的控制流恢复也和这个步骤息息相关。
SSA 生成
SSA,Static Single
Assignment,中文叫做静态单赋值,是说,每一个变量都只应该被赋值一次(只写入一次)。怎么做到呢?就是将变量进行改名,例如eax被写了两次,那么第一次写入,假设是
mov eax, 1 就可以表示为eax_0 = 1 ,第二次用到的eax,假设是add eax, 1 就会表示为eax_1 = eax_0 + 1
这样,一看到eax_1就知道是第二个,不会是第一个了。
但是如果出现分支,就会有一点问题,例如这样的程序:cmp ebx, 100jne L1mov eax, 1jmp endL1:mov eax, 2end:add ebx, eax
如果重新命名eax_1 = 1jmp endL1:eax_2 = 2end:ebx_1 = ? ; 这里出现了问题,应该是 eax_1 还是 eax_2?
所以在SSA里边,我们会加入一个特殊的语句,叫做phi,有时候也叫做phi-node(phi
节点),他的作用就是将分支导致的多个变量进行合并,例如上面的程序就可以被写作:if ebx_0 != 100 then jmp L1eax_1 = 1jmp endL1:eax_2 = 2end:eax_3 = phi(eax_1, eax_2)ebx_1 = eax_3
SSA的目的是让分析更加高效便捷,因为在分析的时候,你用到的变量都可以很清楚的知道是由哪一条语句进行定义的,而不需要往前挨个去找(因为只有一条语句可以定义,所以就很清楚是哪一条,就不需要全部找一遍才能确认)。
变量恢复
即,将变量进行分析恢复,这也是本次Bug的修复重点。变量分为多种可能,包括栈上的变量、寄存器里的变量等等。栈上的变量目前所使用的方法一般是找到栈指针,查看其在函数内开辟了多少空间(加、减了多大的偏移),然后对于用到这一段空间的认为是可能的变量。
类型恢复
在变量恢复之后,会进行类型恢复,也就是“猜”恢复出来的变量可能是什么类型,如果实在猜不出来,就猜一个大小,这个大小可以根据是怎么使用的来确定。例如:加载一个位于rsp
- 0x30的 8 个字节,就会认为这个位置所对应的变量的大小是 8
个字节。至于是指针还是整数还是浮点数,这就需要利用后续对这个变量的其他使用方式来确定了。
控制流恢复
即,将控制流图打上标记,确认控制流图所对应的程序结构,例如在上面控制流图示例中所对应的就应该是 if-else语句。
这一部分一般是通过图匹配算法来实现的,也就是根据图长什么样子来确定是什么语句。
AST 恢复
在控制流图打上标记之后,就可以进行AST(Abstract Syntax
Tree,抽象语法树)恢复了。这一部分将基本块里的内容进行转换,转换成高级语言的形式,以及根据控制流恢复的结果,决定应该使用什么条件语句、循环语句等进行表达。
输出高级语言
最后就是将AST恢复的结果打印出来。就得到了我们看到的结果了。
##Pcode
在了解ghidra的反编译之前,必须先了解ghidra的中间语言:p-code。和其他所有的中间语言一样,这个中间语言和MIPS之类的架构比较接近,指令数量不多。
总结一下pcode中的重点概念:
1. 地址空间(Address Space):所有的变量都必须存在于一个地址空间中,这个地址空间可能是真实的也可能是虚拟的。典型的地址空间包括a. ram,内存地址空间,就和我们理解的内存是同一个东西,在ram地址空间中的偏移量一般就是指在内存中的那个地址。b.
register,寄存器内存空间,这一点特殊一点,在pcode中将所有的寄存器拉通来看,然后给每一个寄存器都标在特定偏移量的地方,例如在 x86-64 下的
rsp 就是在register空间中,offset 为 32 的 8
个字节。这样的好处是不用再特殊处理寄存器范围重叠的问题,这个问题在x86下很常见,例如esp其实是rsp的低 8
字节。利用这种方式,表示esp就没有难度了,可以表示为offset也为 32 ,不过大小为 4 个字节的 “变量”(varnode)。c.
const:常量地址空间,是虚拟的,里边的offset直接被认为是值。例如立即数0xdeadbeef,就表示为
const地址空间,offset为0xdeadbeef的变量(varnode)。d.
unique:特殊地址空间,用于生成临时值的(在ghidra内部使用)。e. stack:特殊地址空间,用来表示栈帧(在ghidra内部使用)。
2. varnode:即pcode所使用的变量,varnode包含地址空间(Address Space)、偏移量、大小,三个属性。
3. opcode:操作符,基本和常见的类似,例如INT_ADD, INT_SUB,
BRANCH,这里就不详细列举了,基本上看见名字也能猜出来是什么意思。不过需要注意的是,除了在ghidra中显示pcode时能看到的操作符以外,还有部分操作符是ghidra内部使用的,例如
MULTIEQUAL(phi指令),这一部分并不会显示在ghidra当中,只在反编译器内部使用。
##Ghidra 的反编译引擎
Ghidra 的反编译器是使用 C++
编写的,位于Ghidra/Features/Decompiler/src/decompiler/cpp/目录,代码中有两套接口,一套是ghidra客户端接口,是和ghidra的java部分一起使用的,还有一个命令行接口,是在调试的时候使用的(虽然实际情况调起来并不是很方便)。C++ 反编译器和Java层通过在 stdio 上实现的二进制协议实现(和languageserver比较像,但是languageserver用了json-
rpc,是文本协议,会好调试一些),其中的大量的数据交换使用了xml的格式,然而这个 xml 的格式文档似乎并不是特别全,需要看代码才能理解其中的很多含义。所以,ghidra的反编译过程实际上是由java层和C++层不断交互完成的,其中需要交互的数据主要是java层用户指定的一些数据(例如用户定义了一个变量的名字、类型,那么反编译引擎就需要考虑到这个问题)。
反编译过程的具体步骤可以看coreaction.cc文件中的ActionDatabase::universalAction,其中定义了反编译的步骤,在ghidra的反编译引擎中,每一个操作被定义为一个Action,一个函数的数据记录在Funcdata中,一个Action一般就是对Funcdata中的数据进行操作。除此以外,还有一系列优化效果的规则,定义为Rule,一个Rule会在特定的IR指令上进行操作,对IR进行修改。
由于反编译引擎内容比较多,没有办法在这里彻底解决,我们就在后续的调试步骤中去讲解所需要利用到的代码啦。
##调试环境准备
Ghidra的反编译器调试没有什么文档,基本上都是自己摸索的。首先是开发环境,ghidra所推荐的开发环境是天杀的Eclipse,但是都 1202 年了,反正我是不想用Eclipse了。我选择的开发环境是vscode,开发环境的准备应该 IDEA也差不多,我纯粹是因为要处理Java 和 C++ (甚至 C++
还更多一些),所以选了vscode。配置ghidra的Java部分环境,其实大多和官方开发文档差不多,但是官方并没有说vscode或者IDEA应该如何配置。我目前的方式配置就多了一步,添加了一个启动方式,在vscode下配置大概是这样:{ “type”: “java”, “name”: “Launch Ghidra”, “request”: “launch”, “projectName”: “Framework Utility”, “mainClass”: “ghidra.GhidraLauncher”, “vmArgs”: “-Djava.system.class.loader=ghidra.GhidraClassLoader -DbinaryPath=build/classes/java/main:build/resources/main/:bin/default/::src/main/resources/”, “classPaths”: [“${workspaceFolder}\Ghidra\Framework\Utility\build\classes\java\main”], “args”: “ghidra.GhidraRun” }
这个配置需要添加在launch.json中的configurations里。主要是设置主类、vm参数、class路径还有启动时候的参数。这几点设置完之后就可以正常下断点啦。
编译的话,通过gradle classes可以进行编译, 不要开vscode插件里的自动build
,虽然不知道为什么,但是我发现开了之后他会一直在build。(2019年我在开发的时候发现ghidra的gradle对license文件的处理,导致会有没办法缓存class的问题,不知道现在这个问题还存在不存在,说不定也是这个问题导致的)
所以基本的流程就是:
-
修改java代码
-
修改cpp代码
-
跑gradle classes编译java层
-
跑gradle buildNatives_win64或gradle buildNatives_linux64或gradle buildNatives_osx64编译C++层
-
利用vscode或IDE 启动调试
不过这里说的是对java层开发的方式。
如果是C++层,还可以使用反编译器提供的命令行接口,事实上我在调试中更多的是使用的命令行接口,因为可以直接gdb。
命令行接口可以在cpp那个目录下,执行 make decomp_dbg 进行编译,得到一个decomp_dbg文件,打开之后会有一个decomp>
的提示符,就可以在这里输入命令了。注意这个功能目前看来应该只在linux上支持(倒不是说别的系统不能用,只是你可能需要处理一大堆依赖……感觉没这个必要,直接搞个虚拟机跑就好了)。
这个提示符的命令没什么文档,我是通过看代码了解用法的,当然还是有一些诡异的输出实在是看不懂。
代码位于consolemain.cc(main 函数,也定义了 load/save/restore几条命令)、ifacedecomp.hh/cc
(反编译相关命令)。
然而,我用到的就只有:
• load file XXX XXX是路径,加载一个二进制文件
• load addr XXX XXX是地址,加载特定地址
• decompile进行反编译
• print C打印C出来。
不过,有命令行之后,就可以gdb跑起来了!还是可以的。
(和d8的调试体验相比,应该还是差很多的,后续可能我会加一些调试的功能,不然确实调起来不太方便)
##开始调试!
好了!那么就让我们进入到正题!
第一步,当然是要处理下程序,不然这么大的Rust程序,该怎么调试呢?所以需要找到关键点,也就是到底是哪一步出现了这个问题。
所以我选择使用nasm自己写汇编代码,模拟出Rust程序上栈帧的处理,最后发现这样一个程序可以最小化的出现问题:; test program for ghidra decompiler; nasm -felf64 test.S && ld test.oglobal_starttest_func:retsection .text_start:push rbpmov rbp, rsppush r15push r14push r13push r12push rbxand rsp, -0x1000 ; 罪魁祸首!就它!mov rax, 0x1c000sub rsp, raxmov rax, 1mov qword [rsp + 0xa020], raxmov qword [rsp + 0xa028], raxlea r12, [rsp + 0xa020]mov rdi, r12mov esi, 0x1call test_funcpop rbxpop r12pop r13pop r14pop r15pop rbpret
其中最关键的就是一句and rsp, -0x1000,如果没有这一句,就完全分析正常。
对比下正常情况:
 加了and之后:
加了and之后:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IOWOIzq4-1690267282861)(https://image.3001.net/images/20210620/1624196188_60cf445c14337e2d90f15.png!small)]
提取出来之后,发现这个问题其实并不只是在Rust反编译中会出现,还会在栈上有变量的情况下出现,这个
issue就提到了这个问题,2019年就存在了,可是一直没有人修复(甚至都没人回复)。
这一步完成之后,至少调试是有可能的了。下面就需要找出来这个问题的原因。
这个原因如果是猜测的话,还是比较好思考的,因为在没有and对齐的时候,栈帧的大小是固定的,能够通过加法减法(都是常量)算出来栈帧的大小,但是加了and之后,就不知道这个大小应该是多大了,所以分析就出了问题。(因为这个时候,栈帧的大小理论上是个范围,例如and
rsp, -0x1000 那么栈帧的大小就可以在 0x1000大小范围内浮动,虽然经验上直接把浮动范围去掉其实也没问题)
不过,想要在这么大的代码中,找到这个点,还是比较困难的。于是我开始了我的调试。首先,CTF
惯例,有文档先得看文档,文档其实是在代码里的,docmain.hh和
doccore.hh两个文件伪装成了代码,其实直接就是文档。看完文档之后,我知道了一些东西:
Heritage这个名词,对应的是SSA转换
反编译步骤是个大循环,中间可能一个步骤会进行多次
变量恢复是在SSA转换之后的
实话讲,这个时候我还不知道栈上变量恢复是在哪里处理的,所以我就先从SSA开始看,因为里边有个奇怪的函数叫做
Heritage::discoverIndexedStackPointers
,然而调试起来之后发现似乎没什么关系,因为我一开始觉得是因为里边没有出现对AND指令的处理,于是根据函数里的处理方式,把AND指令的处理给加上了,结果加上之后才发现没有什么用。好吧,看来这一点是没看对。
然后又是漫长的看代码过程,因为代码量比较大,所以我其实也没有从头到尾的去看,而是通过各种搜索关键字,去找到可能相关的代码区域。因为我是在调试具体Bug,所以目标比较明确,如果是以学习为目的,就不应该这么看了。
通过一通搜索,我找到了restructure varnode这个action,发现了一些问题。这个action的主要工作就是调用
ScopeLocal::restructureVarnode函数(varmap.hh/cc),这个函数的工作分配给了MapState::gatherVarnodes 、MapState::gatherOpen 和 MapState::gatherSymbols
,最后调用了ScopeLocal::restructure。
其中有关的部分在gatherOpen和gatherVarnodes。gatherOpen在正常情况下,应该分析出好几段栈空间对应的 open
RangeHint ,其中的处理逻辑在AliasChecker::gather -> AliasChecker::gatherInternal ->
AliasChecker::gatherAdditiveBase 。
这里也默认base只会出现在加、减法中,所以没有出现对and
的判断。如果在这里加上对and的判断,会发现分析出了栈数组,但是这个栈数组并没有和程序中使用到的栈变量结合起来。也就是会出现类似于:int func() {char uStackxx[1024];stackVar = stackVarxxx & 0xfffffffffffff000;// …}其中的uStackxx在程序中完全没有用到。
和正常程序对比调试了一下发现,在MapState::gatherVarnodes时,是没有检查到使用到的几个变量的,也就是说,使用到的几个变量没有被认为是在
spacebase (也就是栈)上。所以,没有出现open 的 RangeHint 和 varnode交叉的情况,从而并没有联系起来。
虽然这个点并不是我需要的点,但是在这一次调试之中,我发现了一个问题:其实第一次MapState::gatherVarnodes本来就没什么作用(将正常和不正常程序对比调试可以发现),到第二次的时候才出现的作用,也就是分析流程循环的第二轮,MapState::gatherVarnodes
才应当有作用。这就说明,并不一定是之前的action没能分析出来栈变量的问题,还可能是之后的action的问题。
所以,我将范围扩大到在heritage 、restructureVarnodes action之后,然后找到了相关的action
:RuleLoadVarnode和 RuleStoreVarnode。
这两个action(其实是Rule)应该就是分析的主要了,他们都会经过RuleLoadVarnode::checkSpacebase ->
RuleLoadVarnode::vnSpacebase -> RuleLoadVarnode::correctSpacebase
(ruleaction.cc) 的检查。调试发现,没能分析出来的变量所对应的 store/load在correctSpacebase的检查中失败了 。
所以问题应该就在这里了。失败的位置在于 !vn->isSpacebase 也就是这里判断出来了变量对应的varnode 没有被认为是栈变量。
在vnSpacebase中有检查,如果是CPUI_INT_ADD的code,会检查其define的op所对应的参数 0
是不是正确的Spacebase,这个值应该是rsp,是应该返回正常的,但是事实上这里的检查失败了,失败在vn->isInput()
这里,认为不是input。
这个isInput是什么意思呢?通过查看注释,可以发现这个判断是说这个 varnode 是不是 ssa 的 input
node,也就是是不是在这个函数的“外面”给进来的。
断在heritage.cc:2163 也就是 Heritage::renameRecurse 里的循环获取到op = *oiter
之后,发现CPUI_INT_ADD 指令的时候,两个对比程序都是 isInput() == false ,这就说明后续其实应该有地方修改了isInput()
的结果,或者修改 inrefs (也就是 opcode 访问到的 varnode )。
通过下watchpoint 查看inrefs 处的第一个元素,发现通过data.opSetInput 和 对应的clear input 设置了新的
input ,第一次设置的内容打印出来看(p vn->isInput() )发现依然是 false ,直到第二次的时候才发现是 true
了,这个时候通过backtrace 查看到设置的函数是RuleAddMultCollapse !
查看了一下,发现这个函数是用来做常量折叠的,然而他把涉及到栈指针的常量也折叠了,经过这个折叠之后,如果input
是栈指针+(或减)得到的,这个时候就会直接和栈指针搭上关系了,所以才会出现isInput() == true 。
到这里这个Bug的原因就找到了,是因为decompiler假设所有的栈指针相对访问经过常量折叠之后都会与栈指针直接相关,由于按位与运算的存在,导致常量折叠做不完了。然后因为SSA,所以除了第一个rsp被认为是栈指针,后面都是等着常量折叠过去的。结果一个and,折叠不过去了就断开了,后面的rsp就不认为是栈指针了。
##解决问题
最后的解决其实并不算很完美,我自己添加了一个Rule ,将 AND 的其中一个值是spacebase
(也就是会开辟一个子空间的,例如栈帧)的情况进行了处理,直接将对齐操作忽略掉了。
为了解决这个问题,我还对比了一下IDA的操作,发现IDA 虽然没有出这个问题,但是也好不到哪去。
IDA的结果:

多了一个莫名其妙的alloca出来。
另外:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LRfDApYO-1690267282861)(https://image.3001.net/images/20210620/1624196365_60cf450d19cb44f89ac2d.png!small)]
看起来分析还是有点问题的,但是如果看栈空间就会发现,其实也是直接把and操作给忽略了,那么我这么改应该就问题不大啦。
最后的效果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f0QgqA0N-1690267282862)(https://image.3001.net/images/20210620/1624196386_60cf4522149a19cb63fd7.png!small)]
在Rust上运行的效果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IigWd1PS-1690267282862)(https://image.3001.net/images/20210620/1624196405_60cf453528b746123fd83.png!small)]
(还有好多问题,但是至少前面奇怪的保存返回地址的语句没了)
##后记
Ghidra 虽然实现了类似 IDA的功能,但是从Bug情况来看,确实还有太多太多值得改进的地方。另外,ghidra 的官方对PR
、issue的反应并不算太快,似乎他们一直有自己内部的安排在做。想要达到和IDA匹敌的地步确实还有很长的路要走。
我们正在尝试对ghidra进行改进,后续可能以发行版(更快的 fix 、一些方便使用的插件、默认配置)的方式对ghidra进行再发布。
代码已经开源在 [https://github.com/StarCrossPortal/bincraft],欢迎大家保持关注~
没了)
##后记
Ghidra 虽然实现了类似 IDA的功能,但是从Bug情况来看,确实还有太多太多值得改进的地方。另外,ghidra 的官方对PR
、issue的反应并不算太快,似乎他们一直有自己内部的安排在做。想要达到和IDA匹敌的地步确实还有很长的路要走。
我们正在尝试对ghidra进行改进,后续可能以发行版(更快的 fix 、一些方便使用的插件、默认配置)的方式对ghidra进行再发布。
代码已经开源在 [https://github.com/StarCrossPortal/bincraft],欢迎大家保持关注~
最后
分享一个快速学习【网络安全】的方法,「也许是」最全面的学习方法:
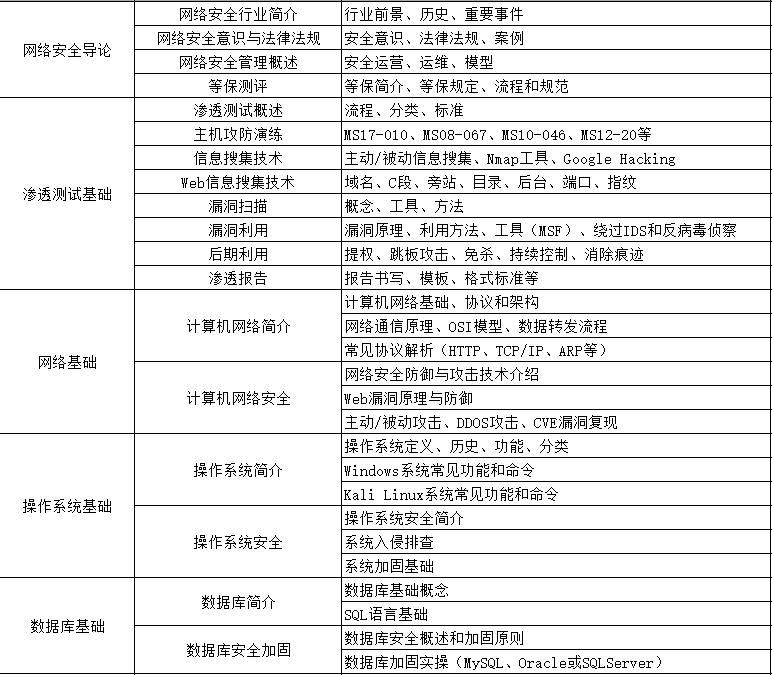
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k。
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
想要入坑黑客&网络安全的朋友,给大家准备了一份:282G全网最全的网络安全资料包免费领取!
扫下方二维码,免费领取

有了这些基础,如果你要深入学习,可以参考下方这个超详细学习路线图,按照这个路线学习,完全够支撑你成为一名优秀的中高级网络安全工程师:

高清学习路线图或XMIND文件(点击下载原文件)
还有一些学习中收集的视频、文档资源,有需要的可以自取:
每个成长路线对应板块的配套视频:

当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

因篇幅有限,仅展示部分资料,需要的可以【扫下方二维码免费领取】