【Pytorch】在实验室linux系统服务器上搭建自己的pytorch-gpu环境过程详解!一篇就足够!
最近要继续学pytorch,想了想不如直接在实验室的服务器上配一个环境吧,毕竟资源不能浪费,要用来搬砖(不是)!!!下面是总结的步骤。
1. 下载anaconda安装包
首先在Anaconda官网下载anaconda-linux的安装包,然后上传到服务器中。或直接在终端进入要存放下载包的目录,然后输入以下命令,系统会自动将资源条下载到当前目录。wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
2. 安装anaconda
在anaconda安装包目录下输入命令:bash Anaconda3-2020.07-Linux-x86_64.sh -p PATH -u,前面是安装包名字,后面是指定的安装路径。之后再一路yes就可了。
测试是否安装成功:
先输入:source ~/.bashrc #使更新后的环境变量立即生效
再输入:python
显示的python版本后面有Anaconda标识,代表安装成功
Python 3.8.3 (default, Jul 2 2020, 16:21:59)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
#退出python的命令交互行输入exit()回车就可以了。
3.创建并激活虚拟环境
大家最好养成良好的习惯,在虚拟环境中配置各种库和框架环境。在终端输入conda create --name NAME python=3.7 创建虚拟环境,其中NAME为你的虚拟环境名称[最好名称中带有版本号以区分,如pytorch-gpu-1.2.0]。创建完后可以输入conda info -e查看所有虚拟环境。
输入conda activate NAME进入虚拟环境中,接下来我们要在该环境中配置pytorch。
4.配置pytorch-gpu环境
(1)为了安装gpu版本,我们必须先安装并行计算框架CUDA和深度神经网络加速库cuDNN【其实可跳过,因为师姐之前已经装好了】
首先用命令watch nvidia-smi查看服务器的gpu情况。并根据表确定对应的CUDA版本


之后CUDA和cuDNN的安装参考别人的博客叭,反正我是没装啦(10.16)
Ubuntu18.04下安装深度学习框架Pytorch(GPU加速)
时隔一个月后的我又回来装了,所以干脆把这一部分也补全(dbq)
因为在github上跑一个模型的时候,总说这个错:
![]()
但我不知道实验室其它人到底把cuda装在哪,所以也就没法添加路径了。所以我只能自己老老实实装了【我很疑惑为什么我之前自己没装但是torch也能找到别人的cuda】
①安装cuda
根据我的显卡驱动版本,对应的我应该安装cuda10.0版本,

进入到下载路径去执行就好
./cuda_9.0.176_384.81_linux.run
安装过程中会有一系列的选项,要注意以下显卡驱动不用重新安装了,选no
Do you accept the previously read EULA? (accept/decline/quit): accept You are attemptingto install on an unsupported configuration. Do you wish to continue? ((y)es/(n)o) [ default is no ]: y
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 352.39? ((y)es/(n)o/(q)uit): n
Install the CUDA 10.0 Toolkit? ((y)es/(n)o/(q)uit): y
Enter Toolkit Location [ default is /usr/local/cuda-8.0 ]:
Do you want to install a symbolic link at /usr/local/cuda? ((y)es/(n)o/(q)uit): y Install the CUDA 8.0 Samples? ((y)es/(n)o/(q)uit): y Enter CUDA Samples Location [ default is /home/kyle ]:
接着配置环境变量,这应该就是我前面出现问题的地方。
1.打开用户目录下的bashrc文件
vi ~/.bashrc
2.在文末加入下面语句,添加环境变量,并激活
#cuda add
export CUDA_HOME=/cuda下载路径/cuda_10_2
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}
source ~/.bashrc
3.测试一下
输入:
nvcc -V
显示:、
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:03_CDT_2017
Cuda compilation tools, release 9.0, V9.0.176
②安装cudnn
同样找到与cuda对应版本的cudnn下载,可恶的是NVDIA要注册,还要,于是找到CSDN上的资源下载。
1.解压
tar -zxvf cudnn-10.0-linux-x64-v7.4.2.24.tgz
2.将解压后的lib和include这两个目录拷贝到cuda的对应bin和include目录下,即是所谓插入式设计,把cuDNN数据库添加CUDA里,cuDNN是CUDA的扩展计算库,不会对CUDA造成其他影响。
先进入压缩包解压后的路径,再执行下面的指令
cp -r lib/* /home/lq/cuda_10_0/bin/
cp -r include/* /home/lq/cuda_10_0/include/
到此,cuda和cudnn安装完成。
(2)安装pytorch-gpu
在pytorch官网中可以找到对应CUDA10.0版本的pytorch安装命令

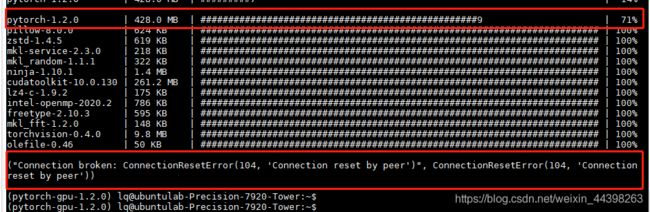
然后在终端直接输入该命令conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=10.0 -c pytorch就可以。但是你会发现速度极慢,上图!这大概是我等了一个多小时的结果吧。

解决的办法就是直接去官网手动下载包了。注意要下载两个,分别是torch和torchvision。文件名写出了pytorch版本号和python版本号。
下载到本地后上传至服务器。然后在虚拟环境中进入到存放目录,分别pip install一下就可了
$ pip install torch-1.2.0-cp37-cp37m-linux_x86_64.whl
$ pip install torchvision-0.4.0-cp37-cp37m-manylinux1_x86_64
大功告成,这一次我居然没有出一点点意外,真是sufu。最后我们来测试一下。
(pytorch-gpu_1.2.0) lq@ubuntulab-Precision-7920-Tower:~$ python
Python 3.7.9 (default, Aug 31 2020, 12:42:55)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> import torchvision
>>> torch.cuda.is_available()
True
PS:我没有关掉之前那个一句命令安装的终端,当我码完这篇博客,它变成了这样,还好我及时止损了emmmm
![]()
最后在pycharm中指定下环境就好了【在existing environment中指定】。

测试一下:
import torch as t
x = t.rand(5,3)
y = t.rand(5,3)
if t.cuda.is_available():
x = x.cuda()
y = y.cuda()
print(x+y)

最后祝大家搬砖顺利~
一些后续:最后实在忍不住回来吐槽一句,那个一句命令安装的——失败了…所以说鸡蛋不能放在一个篮子里,还是边自己手动安装好,有这时间留着造轮子它不香吗!
参考博客:
CUDA版本与显卡驱动版本的对应关系
linux下离线安装pytorch与测试
CUDA和cuDNN的下载1
CUDA和cuDNN的下载2与pycharm上的测试
cuda和cudnn的安装过程