吴恩达深度学习L1W2——实现简单逻辑回归
文章目录
-
-
- 一些笔记
- 写作业
-
- 导入数据
- 取出训练集、测试集
- 处理数据的维度
- 标准化数据
- sigmoid 函数
- 初始化参数w、b
- 前向传播、代价函数、梯度下降
- 优化
- 预测函数
- 模型整合
- 使用模型
- 绘制代价曲线
- 单个样本测试
- 不同alpha的比较
- 预测新图
-
根据笔记中的公式进行构造函数,之后使用模型进行预测
一些笔记


写作业
导入数据
import h5py
import numpy as np
# 训练集、测试集
train_data = h5py.File('./train_catvnoncat.h5', "r")
test_data = h5py.File('./test_catvnoncat.h5', "r")
# h5 格式类似字典,处理的话需要导入h5py包
for key in train_data.keys():
print(key)
# list_classes 类别
# train_set_x 猫片
# train_set_y 标签

查看一下训练集的格式
print(train_data['train_set_x'].shape)# 209个样本,64*64 三个通道
print(train_data['train_set_y'].shape) # 209个标签

测试集同理,50个样本
取出训练集、测试集
train_data_org=train_data['train_set_x'][:]
train_label_org=train_data['train_set_y'][:]
test_data_org=test_data['test_set_x'][:]
test_label_org=test_data['test_set_y'][:]
# 查看图片
import matplotlib.pyplot as plt
%matplotlib inline
# 在线显示图片 或者使用plt.show
plt.imshow(train_data_org[148])

处理数据的维度
从上面手写笔记可以看出,每个实例对应的输入应该只有一列,但是数据集中输入为(64,64,3),所以需要进行处理数据的维度
m_train=train_data_org.shape[0]
m_test=test_data_org.shape[0]
train_data_flatten=train_data_org.reshape(m_train,-1).T
test_data_flatten=test_data_org.reshape(m_test,-1).T
print(train_data_flatten.shape,test_data_flatten.shape)
![]()
标签的shape为(209,)需要处理成矩阵形式,使用上面reshape方法也可以,这里使用np中添加行
test_label_flatten=test_label_org[np.newaxis,:]
train_label_flatten=train_label_org[np.newaxis,:]
# 添加一行,将原来的(50,)变成(1,50)
#通常从二维数组里面抽取一列,取出来之后维度却变成了一维,如果我们需要将其还原为二维,就可以使用上述方法
# 也可以使用上面的reshape方法
print(test_label_flatten.shape,train_label_flatten.shape)
![]()
标准化数据
图片的三个RGB通道,位于0-255,标签的量级在0、1,需要将其归一化,进行÷255即可
train_data_stan=train_data_flatten/255
test_data_stan=test_data_flatten/255
sigmoid 函数
def sigmoid(z):
return 1/(1+np.exp(-z))
初始化参数w、b
n_dim = train_data_stan.shape[0]
w=np.zeros((n_dim,1))
b=0
前向传播、代价函数、梯度下降
def propagate(w,b,X,Y):
#前向传播
Z=np.dot(w.T,X)+b
A=sigmoid(Z)
# 代价函数
m=X.shape[1]
J=-1/m*np.sum(Y*np.log(A)+(1-Y)*np.log(1-A))
# 梯度下降
dw=1/m*np.dot(X,(A-Y).T)
db=1/m*np.sum(A-Y)
grands={
"dw":dw,
"db":db
}
return grands,J
优化
进行上述函数的多次迭代,进行梯度下降优化
def optimize(w,b,X,Y,alpha,n_iters,is_print):
costs=[]
for i in range(n_iters):
grads,J=propagate(w,b,X,Y)
dw=grads["dw"]
db=grads["db"]
w=w-alpha*dw
b=b-alpha*db
if i %100==0:
costs.append(J)
if(is_print):
print("n_iters is",i,"cost is",J)
grands={
"dw":dw,
"db":db
}
params={
"w":w,
"b":b
}
return grads,params,costs
预测函数
通过上面梯度下降得到的w、b优化好的前向传播函数,进行预测测试集的结果
def predict(w,b,X_test):
m = X_test.shape[1]
Y_prediction = np.zeros((1,m))#放预测值的矩阵
Z=np.dot(w.T,X_test)+b
A=sigmoid(Z)
for i in range(m):
if A[0, i] <= 0.5:
Y_prediction[0, i] = 0
else:
Y_prediction[0, i] = 1
return Y_prediction
模型整合
将上面的函数封装到model()函数里面,方便调用
def model(w,b,X_train,Y_train,X_test,Y_test,alpha,n_iters,is_print):
grads,params,costs=optimize(w,b,X_train,Y_train,alpha,n_iters,is_print)
w,b=params['w'],params['b']
##预测要在测试集上面预测,也要看在训练集上面的预测,来看看拟合程度
Y_train_prediction=predict(w,b,X_train)
Y_test_prediction=predict(w,b,X_test)
##看两个预测结果的准确率
print("train acc",np.mean(Y_train_prediction==Y_train)*100)
print("test acc",np.mean(Y_test_prediction==Y_test)*100)
ret={
'w':w,
'b':b,
'costs':costs,
'Y_train_prediction':Y_train_prediction,
'Y_test_prediction':Y_test_prediction,
'alpha':alpha
}
return ret
使用模型
ret=model(w,b,train_data_stan,train_label_flatten,test_data_stan,test_label_flatten,0.005,2000,True)

绘制代价曲线
plt.plot(ret['costs'])
plt.xlabel('100 iters')
plt.ylabel('cost')

单个样本测试
index = 18
plt.imshow(test_data_stan[:,index].reshape((64, 64, 3)))
#plt.imshow(test_data_org[index])
print ("y = " + str(test_label_flatten[0,index]) + ", you predicted ",int(ret["Y_test_prediction"][0,index]))

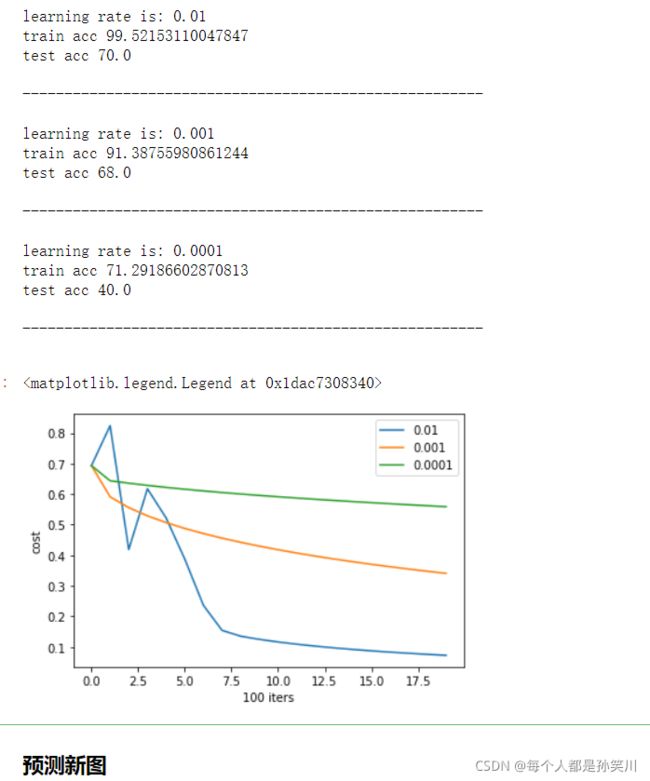
不同alpha的比较
alphas=[0.01,0.001,0.0001]
for i in alphas:
print ("learning rate is: " + str(i))
ret=model(w,b,train_data_stan,train_label_flatten,test_data_stan,test_label_flatten,i,2000,False)
print ('\n' + "-------------------------------------------------------" + '\n')
plt.plot(ret['costs'],label=str(i))
plt.xlabel('100 iters')
plt.ylabel('cost')
plt.legend()
预测新图
预测一下自己的图片
path='./1.jpg'
img=plt.imread(path)
plt.imshow(img)#img.shape (690,690,3)

#尺寸变换
from skimage import transform
img_tran=transform.resize(img,(64,64,3)).reshape(64*64*3,1)
#img_tran.shape (12288,1)
y=predict(ret['w'],ret['b'],img_tran)
print(y)#说明预测结果不是猫,EMMMM,正确率有点低,毕竟是最简单的神经网络了,www
![]()