使用IDEA-Big Data Tools连接远程Spark服务器
使用IDEA连接远程Spark服务器
- 场景
- 步骤
-
- 搭建Spark集群
- 远程连接Spark
-
- 内容说明
- 执行过程
参考:
How to submit code to a remote Spark cluster from IntelliJ IDEA(并没有答案)
Big-Data-Tools: Run applications with Spark Submit
使用 Docker 快速部署 Spark + Hadoop 大数据集群
场景

使用 主机S1 的Docker搭建了Spark集群,其中
主机A:
- Spark-Master
- 端口映射:
22->2010(*SSH端口映射)
主机B:
- Spark-Worker1
主机C:
- Spark-Worker2
使用主机S2的IDEA远程连接 主机A,进行Spark开发。
主机S2 是 Ubuntu系统,Window系统可能以下步骤有出入。
步骤
搭建Spark集群
具体,可以看这篇文章:使用 Docker 快速部署 Spark + Hadoop 大数据集群
远程连接Spark
这里使用到了IDEA的一个插件Big Data Tools。
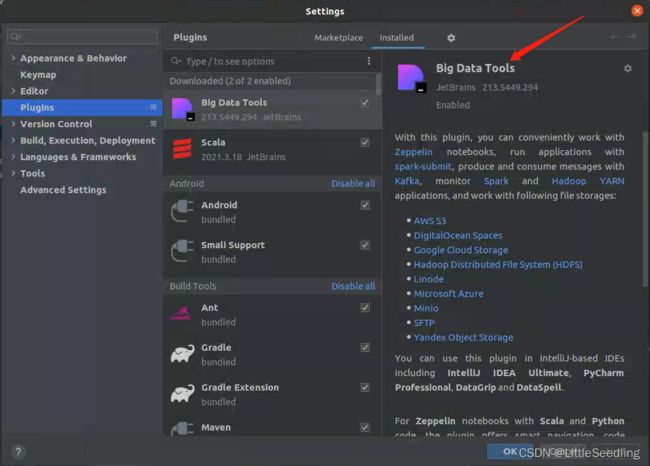
步骤也可以参考:Big-Data-Tools: Run applications with Spark Submit
安装完成之后,重启IDEA。
这时候IDEA右上角,Edit Configurations。
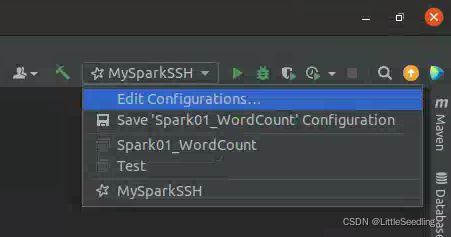
点击左上角的+(Add New Configuration),找到Spark Submit-SSH。

接着,把需要填的东西填上即可。
这里有个add options,把SSH Options勾上。
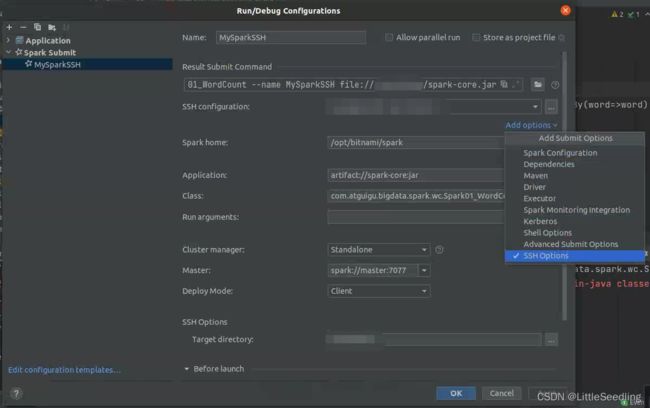
内容说明
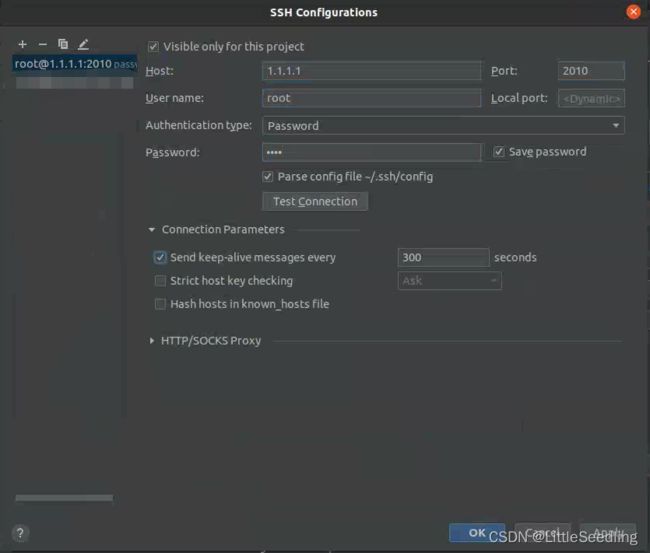
SSH configuration: 指明SSH远程连接的server服务器的配置。
这里的server我们选择主机A,即Spark-Master服务器。
注意:Spark-Master服务器需要启动SSH服务。
Spark home: 指明server中Spark所在目录。
Application: 指我们需要提交的任务。这里是以jar包的形式。
有三个选项:
- Upload File
- Server File
- IDEA Artifact
这里选择Upload File,或者IDEA Artifact即可。
我选的是IDEA Artifact。
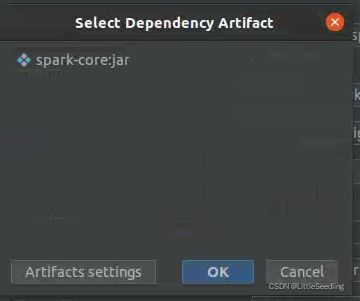
如果没有,就点Artifacts settings。
点击右上角+,选择JAR->From modules with dependencies。
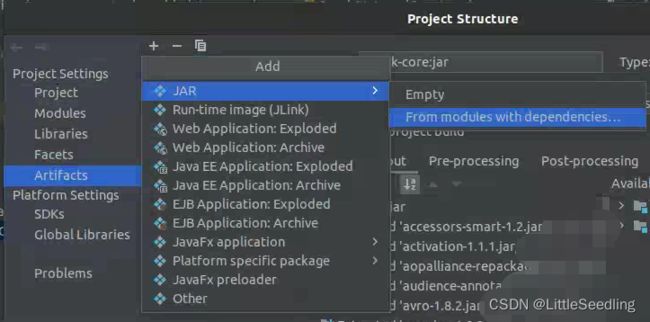
填好后,点击OK。
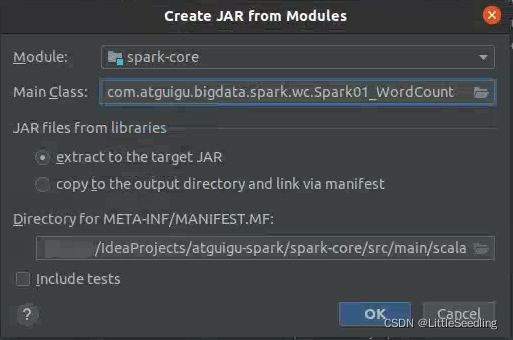
把Include in project build勾上。

2022.02.23补充:
如果选择的是Upload File,自己选择可运行的jar。
其中,pom.xml需要添加依赖。
<build>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.1.0version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>your main classmainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
在命令窗口运行mvn clean package,打包好的jar会在/target目录下,选择...-jar-with-dependencies的那个jar。
Class: 指明Application运行的主类,即程序入口。
注意:先build一下project。
如果Application中选择了IEAD Artifact,这里IDEA可能不会自己找,需要自己手动填写。
比如,我这里的主类是Spark01_WordCount,右键,选择Copy Path/Reference -> Copy Reference。

填到Class中即可。
Cluster manager: 指明Spark的运行模式。
这里选择Standalone。
Master: 指明Spark Master的地址。
Deploy Model: 指明Spark Deply Mode
这里选择Client,如果选择Cluster可能看不到具体输出。
SSH Options - Target directory: 指,存放上传jar包的server路径。
在Before launch中,我们把Bulid ... jar提前。

在Result Submit Command我们可以看见 待执行的命令。
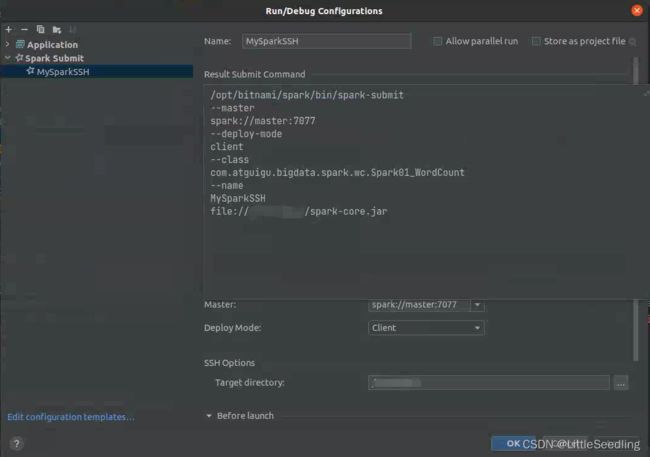
点击OK,配置完成!
执行过程
选择run即可。

执行流程:
Build Artifact jarSSH连接Server(这里是Spark-Master)Upload jar到Server的Target directory目录下。- 在Server上,执行
Result Submit Command命令。IDEA会把输出传回。
这样,就可以愉快地在IDEA上进行Spark开发啦!