C++数据结构笔记(3)线性表的链式存储底层实现
本系列的帖子并不包含全部的基础知识,只挑一部分最核心的知识点总结,着重于具体的实现细节而并非理论的知识点总结,大家按需阅读学习。
链表的核心概念总结如下:
1.链式存储不需要连续的内存空间
2.链表由一系列的结点组成,每个节点包含两个域,分别是指针域和数据域
3.C语言中能指向任何类型的指针为空指针:void*
4.链表在具体实现时,不需要引入容量的概念。
话不多说,直接上代码,和前文顺序结构的实现方法一样,首先声明独立的LinkList.h头文件,如下:
#ifndef LINKLIST_H
#define LINKLIST_H
#include
#include
//链表结点
typedef struct LinkNode{
void* data;
//空指针,指向任何类型的数据
struct LinkNode* next;
}LinkNode;
//链表结构体
typedef struct LinkList{
LinkNode* head;
int size;
//对于链表来说,不需要有容量的定义
}LinkList;
//打印函数指针
typedef void(*PRINTLINKNODE)(void*);
//意义在于打印时可根据用户使用的类型自定义打印
//初始化链表
LinkList* Init_LinkList();
//指定位置插入元素
void Insert_LinkList(LinkList* list,int pos,void* data);
//删除指定位置的值
void RemoveByPos_LinkList(LinkList* list,int pos);
//获得链表的长度
int Size_LinkList(LinkList* list);
//根据指针查找
int Find_LinkList(LinkList* list,void* data);
//返回第一个节点的位置
void* Front_LinkList(LinkList* list);
//打印链表结点
void Print_LinkList(LinkList* list,PRINTLINKNODE print);
//释放链表内存
void FreeSpace_LinkList(LinkList* list); 需要注意的是,在本段头文件中声明了两个类型的结构体:即结点类型LinkNode和链表类型LinkList,原因是链表的元素(结点)必须包含地址域(指针);此外,与顺序表不同的是,链表并不需要预留初始的容量。
此外,void* data这个写法,保证链表类型中寸放的数据部局限于一种,可以在测试函数中由开发者自定义;对于typedef void(*PRINTLINKNODE)(void*),同理,开发者可以根据自定义的类型自由修改打印遍历的函数。
如下的LinkList.c文件中,实现了链表的各种具体操作,具体和顺序存储的思路类似。
引入头文件
#include"LinkList.h"初始化链表
//初始化链表
LinkList* Init_LinkList(){
LinkList* list=(LinkList*)malloc(sizeof(LinkList));
list->size=0;
//声明头结点,不需要用来保存数据信息
list->head=(LinkNode*)malloc(sizeof(LinkNode));
list->head->data=NULL;
list->head->next=NULL;
return list;
}注意,头指针在初始化时均为空,其实也可以直接省去头指针的定义,但如果不定义的话后期的处理会复杂化。
指定位置插入元素(重点)
//指定位置插入元素
void Insert_LinkList(LinkList* list,int pos,void* data){
if(list==NULL||data==NULL)
return;
//pos越界,则默认插入到尾部
if(pos<0||pos> list->size)
pos=list->size;
//创建新结点
LinkNode* newnode=(LinkNode*)malloc(sizeof(LinkNode));
newnode->data=data;
newnode->next=NULL;
//首先要找到原位置上的当前结点
LinkNode* pCurrent=list->head;
for(int i=0;inext;
//体现链表性质的一个操作
//即,不能通过下标访问元素,必须从头开始依次向后遍历,非常遗憾
//新结点入链表
newnode->next=pCurrent->next;
pCurrent->next=newnode;
list->size++;
} 上述写法是符合链表性质的一种定义,核心点在于,找到需要插入结点的位置pos上原本的结点,并保存下来,然后让新的结点指向原结点的后继结点,再将原结点的后继结点指向当前的新结点,如下图所示:
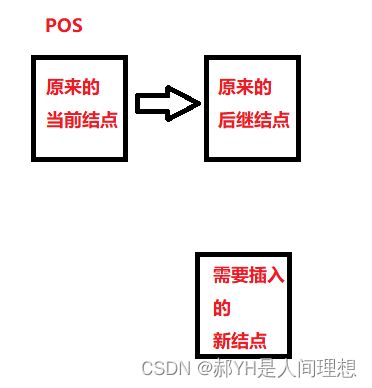
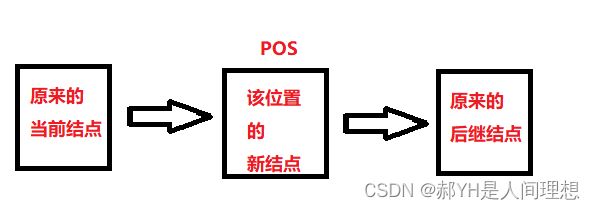
删除指定位置的值
void RemoveByPos_LinkList(LinkList* list,int pos){
if(list==NULL)
return;
if(pos<0||pos>= list->size)
return;
//查找删除结点的前一个结点!
LinkNode* pCurrent=list->head;
for(int i=0;inext;
//缓冲删除的结点
LinkNode* pDel=pCurrent->next;
pCurrent->next=pDel->next;
//删除结点的内存
free(pDel);
list->size--;
} 与插入结点的操作类似,区别在于需要额外开辟空间保存当前结点;此外,遍历时同样必须从头到尾;最后还要将链表的元素数量减一。
获得链表的长度
//获得链表的长度
int Size_LinkList(LinkList* list){
return list->size;
}根据指针查找结点元素
//根据指针查找
int Find_LinkList(LinkList* list,int pos){
if(list==NULL)
return -10;
if(pos<0||pos>= list->size)
return -10;
LinkNode* pCurrent=list->head->next;
//直接指向第一个有效数据
int i=0;
while(pCurrent!=NULL){
if(pCurrent!=NULL)
break;
i++;
pCurrent=pCurrent->next;
}
return i;
}返回第一个结点的位置
//返回第一个节点的位置
void* Front_LinkList(LinkList* list){
return NULL;
return list->head->next;
}打印链表中的结点
//打印链表结点
void Print_LinkList(LinkList* list,PRINTLINKNODE print){
if(list==NULL)
return;
LinkNode* pCurrent=list->head->next;
while(pCurrent!=NULL)
{
print(pCurrent->data);
pCurrent=pCurrent->next;
}
}释放链表内存
//释放链表内存
void FreeSpace_LinkList(LinkList* list){
if(list==NULL)
return;
LinkNode* pCurrent=list->head;
while(pCurrent!=NULL)
{
//缓存档期结点
LinkNode* pNext= pCurrent->next;
free(pCurrent);
pCurrent=pNext;
}
list->size=0;
free(list);
}
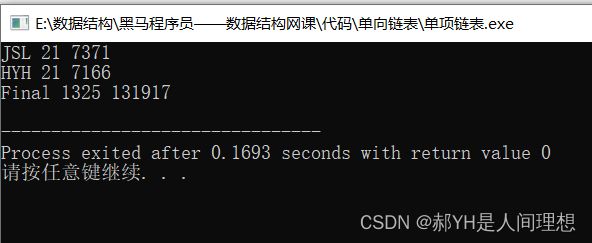
接下来通过main函数实现测试,运行结果如下图:
#include
#include
#include
#include "LinkList.h"
using namespace std;
//定义测试类型
typedef struct test{
char name[64];
int age;
int score;
}test;
//打印函数
void Myprint(void* data)
{
test* t=(test*)data;
//此时开发人员知道自己所定义的类型!
cout<<(t->name)<<" "<<(t->age)<<" "<<(t->score)<