C++知识点总结
本贴为复习专用
已更新到C++11的lambda表达式
基础篇
- C++ 完全支持面向对象的程序设计,包括面向对象开发的四大特性:( 封装,抽象,继承,多态 )
- 标准的 C++ 由三个重要部分组成:
- (核心语言),提供了所有构件块,包括变量、数据类型和常量,
- (C++ 标准库),提供了大量的函数,用于操作文件、字符串
- (标准模板库(STL)),提供了大量的方法,用于操作数据结构
-
IDE编程步骤
-
①源代码:你手敲的代码
-
②编译器:用来编译源代码, 相当于翻译,把你的C++语言C语言翻译给电脑听,即对电脑讲机器语言,当然也是代码,这里把翻译过的代码叫目标代码,这一步也处理了预处理器包含的指令
-
③目标代码:被编译器编译过的源代码
-
④链接程序=启动代码+库代码+目标代码, 你的程序可能需要调用很多其他的代码来帮助你完成任务,所以需要把他们链接起来, 整合起来的代码就是可执行代码
-
⑤可执行代码, 最终代码即程序运行时的代码
-
-
文本编辑器包括 (Windows Notepad)、(OS Edit command)、(Brief)、(Epsilon)、(EMACS) 和( vim/vi)
-
文本编辑器的名称和版本在不同的操作系统上可能会有所不同。例如,(Notepad )通常用于 Windows 操作系统上,(vim/vi )可用于 Windows 和 Linux/UNIX 操作系统上。
-
-
C++ 程序的源文件通常使用扩展名( .cpp、.cp 或 .c), 大多数的 C++ 编译器并不在乎源文件的扩展名,但是如果您未指定扩展名,则默认使用 .cpp。
-
写在源文件中的源代码是人类可读的源。它需要"编译",转为机器语言,这样 CPU 可以按给定指令执行程序。
-
C++ 编译器用于把源代码编译成最终的可执行程序。
-
最常用的免费可用的编译器是 GNU 的 C/C++ 编译器,
-
如果您使用的是 Linux 或 UNIX,请在命令行使用下面的命令来检查您的系统上是否安装了 GCC:
-
如果您使用的是 Mac OS X,最快捷的获取 GCC 的方法是从苹果的网站上下载 Xcode 开发环境,并按照安装说明进行安装。一旦安装上 Xcode,您就能使用 GNU 编译器。
-
为了在 Windows 上安装 GCC,您需要安装 MinGW。为了安装 MinGW,请访问 MinGW 的主页 www.mingw.org,进入 MinGW 下载页面,下载最新版本的 MinGW 安装程序,命名格式为 MinGW-.exe。当安装 MinGW 时,您至少要安装 gcc-core、gcc-g++、binutils 和 MinGW runtime,但是一般情况下都会安装更多其他的项。添加您安装的 MinGW 的 bin 子目录到您的 PATH 环境变量中,这样您就可以在命令行中通过简单的名称来指定这些工具。当完成安装时,您可以从 Windows 命令行上运行 gcc、g++、ar、ranlib、dlltool 和其他一些 GNU 工具。
-
-
C++的扩展名往往是.cpp 在linux中往往是.cxx,目标代码文件是.o 可执行文件是.out
-
类是一种规范, 描述了你设计的新型数据结构, 对象就是类的实现,即根据这种规范所构造的数据结构, 换句话说,类描述了:(一种数据类型的全部属性包括了可使用它执行的操作), 而对象就是根据这些描述来创建的实体
-
函数可以来自函数库, 类也有类库,ostream和istream系列类就是一种类库,还有fstream系列类,类库不好听我们更喜欢叫系列类
-
预处理器
-
什么是预处理器呢?在主编译之前对源文件进行处理,你不需要进行特殊的操作来调用,只需要#即可
-
使用#Include编译指令,比如#include 就是把iostream文件添加到程序中,这是一种比较典型的预处理器操作,在源代码被编译之前,替换或添加文本
-
#include指令会把iostream文件中的内容和源代码一起发送给编译器,具体就是iostream中的全部文件会取代#include 这一行代码,并且不修改源代码文件,而是新生成一个复合文件
-
-
头文件=包含文件
-
iostream这种文件叫包含文件(常常被include包含在其他文件中) ,也叫头文件(常常在程序起始处)
-
C++有很多头文件,每个头文件都带来了一组特定的工具
-
C的头文件往往是.h扩展名, C++往往是没有扩展名,使用C的头文件时,你需要(去掉.h且在名前加c即cmath=math.h)
-
C用不同扩展名表示不同文件类型,C++取消所有扩展名
-
在应用程序中引用非标准库时,可以先去浏览一下这些包含文件,这是最好的文档信息,你可以掌握很多知识,这种行为是很好的习惯
-
-
名称空间
-
上述头文件去掉了.h其实不是这么简单,而是让没有.h的头文件包含了名称空间
-
名称空间编译指令using namespace 比如using namespace std; 这里是using编译指令
-
打断一下,你现在了解了两个编译指令了,一个是using一个是#include
-
-
头文件包含了名称空间, 名称空间包含了(所需要的类,函数,变量等的名字),想访问他们有如下两种方式以std为例
-
using std::cout; //通过using编译指令来声明了cout的来源是std名称空间
-
using namespace std; cout<<'a'<
-
-
-
cout预定义的对象,它懂得如何显示字符串,数字和字符等数据
-
cout是个对象,那是哪个类的对象呢????
-
插入运算符<<符号可以把信息流入到cout中即cout<<'a'
-
cout<<'a'就是把字符a从程序中流出去了, 而cout正是表示了这种输出流,cout对象的具体属性是在iostream头文件中定义的,属性包括了一个插入运算符<<, 可以把数据插入到输出流中
-
-
控制符endl,表示重启一行,如果把控制符endl也插入到输出流中,那你屏幕光标将会(直接跳到下一行的开头),endl控制符也是iostream头文件中定义的,同样名字也在std名称空间中
-
cout代表了输出流,所以并不能移动光标
-
cout是指代表了输出流,所以也不能产生空格,如果你需要空格,那就把空格插入到输出流中吧
-
-
C++程序可以看成一组函数, 而每个函数又是一组语句
-
声明语句创建了变量,作用就是:指出了(信息存储的具体位置)和(需要的内存空间大小)
-
(计算机存储数据时,必须要知道数据的存储位置和所占内存空间大小)
-
声明语句提供了(存储类型)和(位置标签),位置标签表示了具体位置,存储类型则代表了所占内存空间的大小信息
-
比如int num; int是整数类型,根据计算机系统不同,整数类型所占的内存空间(位数或字节数)也不同,而num则代表了上述内存空间的位置标签,num作为变量是可以改变的,就是内存空间存储的信息是可以修改的
-
不同的数据类型,则代表了不同的内存空间占用的大小数量
-
-
你不需要管这些底层的事情,编译器会帮你分配好内存并标记好位置
-
-
定义和声明最好根据函数和变量来分别讨论
-
对于变量而言:
-
变量的声明,指出存储位置和所需空间大小
-
变量的定义,指出存储位置和所需空间大小,且申请相应内存空间
-
-
对于函数而言:
-
函数的声明,相当于变量声明于变量,声明函数原型
-
函数的定义,给出函数的结构体
-
-
思考:声明、定义、引用三者各什么意思?是否有什么联系??
-
赋值语句=赋值运算符则可以对内存空间中存储的数据进行修改
-
代表输入流的cin对象,插入运算符>>为cin提供了流入方向
-
cout和cin都是智能对象,可以通过输入对象的类型而自动调整输入的数据类型
-
换行符\n, 换行符常用在字符串中,其实\n是一个字符,名称是换行符而已,
-
换行符\n和控制符endl的区别
-
显然是字符数量少了\n两个endl四个
-
endl能够保证在程序继续运行前刷新屏幕,也就是立即显示在屏幕上,而\n不能, 甚至有时候你要在输入信息后才会有提示
-
当然如果你只想要一个空行,两者都可以选择
-
cout<
-
cout<<"\n";
-
-
-
由于;标志着一条语句的结束, 所以你在一条语句中使用多少回车都是无法表示该语句的结束的,甚至是没有什么影响,所以在一条语句中,回车的作用=空格=制表符(多个空格)
-
这并不意味着你可以随意使用多个空格或者回车, 无论是C还是C++你都不能把空格,制表符,回车,放到元素中(比如变量名), 也不能放到字符串中,这很重要,cout<<"字符串中不能添加回车,不要换行"
-
-
标记和空白
-
一行代码中不可分割元素比如int 比如main等,都叫做标记,通常我们用空格制表符回车把两个标记分开({}就是用回车分开的)
-
有些可以通过一个空格来分开,有些不可以,比如 int main()你不要把回车插入到int和main中间
-
基础语法篇
- C++ 程序可以定义为(对象)的集合,这些对象通过(调用)的方法进行交互。现在让我们简要地看一下什么是类、对象,方法、即时变量。
- 对象 - 对象具有状态和行为。例如:一只狗的状态 - 颜色、名称、品种,行为 - 摇动、叫唤、吃。对象是类的实例。
- 类 - 类可以定义为描述对象(行为,状态的模板)。
- 方法 - 从基本上说,一个方法表示一种行为。一个类可以包含多个方法。可以在方法中写入逻辑、操作数据以及执行所有的动作。
- 即时变量 - 每个对象都有其独特的即时变量。对象的状态是由这些即时变量的值创建的。
- main() 是程序开始执行的地方
-
分号是语句结束符。也就是说,每个语句必须以分号结束。它表明一个逻辑实体的结束。
-
C++ 标识符是用来标识变量、函数、类、模块,或任何其他用户自定义项目的名称。一个标识符以字母 A-Z 或 a-z 或下划线 _ 开始,后跟零个或多个字母、下划线和数字(0-9)。
-
C++ 注释以 /* 开始,以 */ 终止。注释也能以 // 开始,直到行末为止。
| 类型 | 位 | 范围 |
|---|---|---|
| char | 1 个字节 | -128 到 127 或者 0 到 255 |
| unsigned char | 1 个字节 | 0 到 255 |
| signed char | 1 个字节 | -128 到 127 |
| int | 4 个字节 | -2147483648 到 2147483647 |
| unsigned int | 4 个字节 | 0 到 4294967295 |
| signed int | 4 个字节 | -2147483648 到 2147483647 |
| short int | 2 个字节 | -32768 到 32767 |
| unsigned short int | 2 个字节 | 0 到 65,535 |
| signed short int | 2 个字节 | -32768 到 32767 |
| long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| signed long int | 8 个字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| unsigned long int | 8 个字节 | 0 to 18,446,744,073,709,551,615 |
| float | 4 个字节 | +/- 3.4e +/- 38 (~7 个数字) |
| double | 8 个字节 | +/- 1.7e +/- 308 (~15 个数字) |
| long double | 16 个字节 | +/- 1.7e +/- 308 (~15 个数字) |
| wchar_t | 2 或 4 个字节 | 1 个宽字符 |
-
unsigned或signed改变范围不改变字节数, short 字节 *0.5, long字节*2,如short int 则字节为2, long int 字节为8
-
使用 (typedef) 为(一个已有的类型取)一个新的名字
-
使用 (sizeof()) 函数来获取各种数据类型的大小。
-
运算符sizeof返回类型或变量长度,单位是B字节
-
对变量操作时, 无需加括号,即int a = 0 ; cout<
-
对数据类型操作时,加括号,即cout<
-
sizeof运算符直接指出了整个数组的长度(有多少个元素就有多长)
-
sizeof运算符对指针进行操作时,得到的是指针的长度,即使指针指向的是个数组
-
strlen()函数则返回可见字符的个数,不包括'\0'空字符
-
-
枚举
-
枚举类型(enumeration)是C++中的一种派生数据类型,它是由用户定义的若干枚举常量的集合.如果一个变量只有几种可能的值,可以定义为枚举(enumeration)类型。所谓"枚举"是指将变量的值一一列举出来,变量的值只能在列举出来的值的范围内。
-
创建枚举,需要使用关键字 enum。
-
默认情况下,第一个名称的值为 0,第二个名称的值为 1,第三个名称的值为 2,以此类推。但是,您也可以给名称赋予一个特殊的值,只需要添加一个初始值即可。例如,在下面的枚举中,green 的值为 5。
-
在这里,blue 的值为 6,因为默认情况下,每个名称都会比它前面一个名称大 1,但 red 的值依然为 0。
-
代码中是两种不同的创建枚举的方法,第一种方法,name, age,width,height的值,是其下标值,如age下表是1,则age=1;
-
第二种方法,直接赋值,age就是18
-
注意,枚举的各个元素都是符号常量,并且指定的具体数值必须是整数,当然第一种情况默认赋值必然是整数
-
/*
enum 枚举名{
标识符[=整型常数],
标识符[=整型常数],
...
标识符[=整型常数]
} 枚举变量;
*/
enum color { red, green, blue} c ;
c = blue;
enum color { red, green = 5, blue};
enum person {name, age, width, height};
enum person0 {name = 1, age = 18, width =120, height=133232};变量
- 变量的名称可以由(字母、数字和下划线)字符组成。它必须以(字母或下划线)开头。大写字母和小写字母是不同的,因为 C++ 是大小写敏感的。
| 类型 | 描述 |
|---|---|
| bool | 存储值 true 或 false。 |
| char | 通常是一个字符(八位)。这是一个整数类型。 |
| int | 对机器而言,整数的最自然的大小。 |
| float | 单精度浮点值。单精度是这样的格式,1位符号,8位指数,23位小数。 |
| double | 双精度浮点值。双精度是1位符号,11位指数,52位小数。 |
| void | 表示类型的缺失。 |
| wchar_t | 宽字符类型。 |
使用( extern 关键字)在任何地方声明一个变量
- 左值(lvalue):指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边。
- 右值(rvalue):术语右值(rvalue)指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
-
强制类型转换(这里是简单地类型转换,还有更高级的操作在fstream类中)
-
static_cast<>运算符是强制类型转换符
-
static_cast (xjh)把xjh变量强制转换成int类型
-
- 变量定义和变量声明(针对的是变量)
- 声明(declaration):不分配内存。 而 定义:是在变量声明后,给它分配内存
- 上边说的声明是说,指明了存储位置和所需的内存空间大小,并没有申请内存空间
- 而函数,则需要定义前进行声明
- 变量声明=提供名字+存储类型,
- 变量定义=提供名字+存储类型+申请内存空间
- extern外部声明
-
// 变量声明 extern int a, b; extern int c; extern float f; // 函数声明 int func(); int main () { // 变量定义 int a, b; int c; float f; // 实际初始化 a = 10; b = 20; c = a + b; cout << c << endl ; f = 70.0/3.0; cout << f << endl ; // 函数调用 int i = func(); return 0; } // 函数定义 int func() { return 0; }
- 声明(declaration):不分配内存。 而 定义:是在变量声明后,给它分配内存
如果只声明不定义会怎么样呢?
#include
extern int a;
int main(void)
{
extern int b;
int a =0;
b=1;
std::cout<<"a:"<>>g++ main.cpp
/tmp/cctOXSfB.o: In function `main':
main.cpp:(.text+0x11): undefined reference to `b'
main.cpp:(.text+0x50): undefined reference to `b'
collect2: error: ld returned 1 exit status
常量
-
在 C++ 中,有两种简单的定义常量的方式:
- 使用 #define 预处理器。
-
预处理编译指令#define这里举个例子来说明
-
#define INT_MAX 32767
-
编译指令#define在编译前在程序中查找所有的INT_MAX,然后用32767替换。完成替换后,程序会被编译
-
当然预处理器仅仅替换独立的标记,而不会替换嵌入INT_MAX的标记,如PINT_MAX或UINT_MAX
-
-
- 使用 const 关键字。
- 用const的优点:会进行类型安全检查。而define没有安全检查,且可能会产生意料不到的错误。
- 使用 #define 预处理器。
-
整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。
- 整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。后缀可以是大写,也可以是小写,U 和 L 的顺序任意。
#include
using namespace std;
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main()
{
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
const int NUMBER = 10;
const float PRICE= 13.23;
double output = NUMBER * PRICE;
cout << output;
return 0;
}
/*
212 // 合法的
215u // 合法的
0xFeeL // 合法的
078 // 非法的:8 不是八进制的数字
032UU // 非法的:不能重复后缀
85 // 十进制
0213 // 八进制
0x4b // 十六进制
30 // 整数
30u // 无符号整数
30l // 长整数
30ul // 无符号长整数
*/ - 浮点常量
- 由整数部分、小数点、小数部分和指数部分组成。如3.14
- 当使用小数形式表示时,必须包含整数部分、小数部分,或同时包含两者。
- 当使用指数形式表示时, 必须包含小数点、指数,或同时包含两者。
- 带符号的指数是用 e 或 E 引入的。
- 由整数部分、小数点、小数部分和指数部分组成。如3.14
3.14159 // 合法的
314159E-5L // 合法的
510E // 非法的:不完整的指数
210f // 非法的:没有小数或指数
.e55 // 非法的:缺少整数或分数转义字符
| 转义序列 | 含义 |
|---|---|
| \ | \ 字符 |
| ' | ' 字符 |
| " | " 字符 |
| ? | ? 字符 |
| \a | 警报铃声 |
| \b | 退格键 back |
| \f | 换页符 form feed 换页 |
| \n | 换行符 newline换行 |
| \r | 回车 return |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ooo | 一到三位的八进制数 |
| \xhh . . . | 一个或多个数字的十六进制数 |
引用 &
- 引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。
-
引用和指针的三个不同:
-
不存在空引用。引用必须连接到一块合法的内存。(不存在空引用,存在空指针)
- 一旦引用被初始化为一个对象,就不能被指向到另一个对象。指针可以在任何时候指向到另一个对象。(引用不可二次多次指向,指针可以)
- 引用必须在创建时被初始化。指针可以在任何时间被初始化。
-
- 变量名称是变量附属在内存位置中的标签,可以把引用当成是变量附属在内存位置中的第二个标签,也就是说修改其一另一个值也会改变,因为对应的内存块的数值变了.
引用时要注意两个两个变量的类型要求保持一致,const引用const int类型将产生错误
#include
using namespace std;
int main ()
{
// 声明简单的变量
int i;
double d;
// 声明引用变量
int& r = i;
double& s = d;
i = 5;
cout << "Value of i : " << i << endl;
cout << "Value of i reference : " << r << endl;
d = 11.7;
cout << "Value of d : " << d << endl;
cout << "Value of d reference : " << s << endl;
return 0;
} - 在这些声明中,& 读作引用。因此,第一个声明可以读作 "r 是一个初始化为 i 的整型引用",第二个声明可以读作 "s 是一个初始化为 d 的 double 型引用"。
存储类
-
存储类定义 C++ 程序中变量/函数的范围(可见性)和生命周期。说明符放置在它们所修饰的类型之前
-
auto 存储类, auto 关键字用于两种情况:声明变量时根据初始化表达式自动推断:该变量的类型、声明函数时函数返回值的占位符。
可以使用STL中的 typeid(auto_name).name()来查看类型名
auto f=3.14; //double
auto s("hello"); //const char*
auto z = new auto(9); // int*
auto x1 = 5, x2 = 5.0, x3='r';//错误,必须是初始化为同一
cout<-
register 存储类用于定义存储在寄存器中而不是 RAM 中的局部变量。这意味着变量的最大尺寸等于寄存器的大小(通常是一个词),且不能对它应用一元的 '&' 运算符(因为它没有内存位置)。
-
寄存器只用于需要快速访问的变量,比如计数器。还应注意的是,定义 'register' 并不意味着变量将被存储在寄存器中,它意味着变量可能存储在寄存器中,这取决于硬件和实现的限制。
-
-
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
-
当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。
-
当 static 用在类数据成员上时,会导致仅有一个该成员的副本被类的所有对象共享。
-
-
extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。
-
当您有多个文件且定义了一个可以在其他文件中使用的全局变量或函数时,可以在其他文件中使用 extern 来得到已定义的变量或函数的引用。
-
extern 修饰符通常用于当有两个或多个文件共享相同的全局变量或函数的时候,
-
//File0
#include
int count ;
extern void write_extern();
int main()
{
count = 5;
write_extern();
}
//File1
#include
extern int count;
void write_extern(void)
{
std::cout << "Count is " << count << std::endl;
} 运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 把两个操作数相加 | A + B 将得到 30 |
| - | 从第一个操作数中减去第二个操作数 | A - B 将得到 -10 |
| * | 把两个操作数相乘 | A * B 将得到 200 |
| / | 分子除以分母 | B / A 将得到 2 |
| % | 取模运算符,整除后的余数 | B % A 将得到 0 |
| ++ | 自增运算符,整数值增加 1 |
A++ 将得到 11 |
| -- | 自减运算符,整数值减少 1 |
A-- 将得到 9 |
| && | 称为逻辑与运算符。如果两个操作数都非零,则条件为真。 |
(A && B) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。 |
(A || B) 为真。 |
| ! | 称为逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。 |
!(A && B) 为真。 |
| sizeof | sizeof 运算符返回变量的大小。例如,sizeof(a) 将返回 4,其中 a 是整数。 |
|
| Condition ? X : Y | 条件运算符。如果 Condition 为真 ? 则值为 X : 否则值为 Y。 |
|
| , | 逗号运算符会顺序执行一系列运算。整个逗号表达式的值是以逗号分隔的列表中的最后一个表达式的值。 |
|
| .(点)和 ->(箭头) | 成员运算符用于引用类、结构和共用体的成员。 |
|
| Cast | 强制转换运算符把一种数据类型转换为另一种数据类型。例如,int(2.2000) 将返回 2。 |
|
| & | 指针运算符 & 返回变量的地址。例如 &a; 将给出变量的实际地址。 |
|
| * | 指针运算符 * 指向一个变量。例如,*var; 将指向变量 var。 |
|
对于++和--,只要用对象,就进行自加自减,比如
int a = 0; int b = 0; a++; cout<
循环与判断
- 循环控制语句
- break 终止 loop 或 switch 语句,程序流将继续执行紧接着 loop 或 switch 的下一条语句。
- continue 引起循环跳过主体的剩余部分,立即重新开始测试条件.
- 判断语句(拿python笔记充数,逻辑是同样的)
-
? : 运算符 可以用来替代 if...else 语句。

Exp1 ? Exp2 : Exp3;- 如果 Exp1 为真,则计算 Exp2 的值,结果即为整个表达式的值。如果 Exp1 为假,则计算 Exp3 的值
函数参数
-
如果函数要使用参数,则必须声明接受参数值的变量。这些变量称为函数的形式参数。
形式参数就像函数内的其他局部变量,在进入函数时被创建,退出函数时被销毁。
当调用函数时,有两种向函数传递参数的方式:
| 传值调用 | 该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数对实际参数没有影响。 |
| 指针调用 | 该方法把参数的地址复制给形式参数。在函数内,该地址用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数。 |
| 引用调用 | 该方法把参数的引用复制给形式参数。在函数内,该引用用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数。 |
- 当您定义一个函数,您可以为参数列表中后边的每一个参数指定默认值。当调用函数时,如果实际参数的值留空,则使用这个默认值。
-
C++ 内置了丰富的数学函数,可对各种数字进行运算。下表列出了 C++ 中一些有用的内置的数学函数。为了利用这些函数,您需要引用数学头文件
| 序号 | 函数 & 描述 |
|---|---|
| 1 | double cos(double); 该函数返回弧度角(double 型)的余弦。 |
| 2 | double sin(double); 该函数返回弧度角(double 型)的正弦。 |
| 3 | double tan(double); 该函数返回弧度角(double 型)的正切。 |
| 4 | double log(double); 该函数返回参数的自然对数。 |
| 5 | double pow(double, double); 假设第一个参数为 x,第二个参数为 y,则该函数返回 x 的 y 次方。 |
| 6 | double hypot(double, double); 该函数返回两个参数的平方总和的平方根,也就是说,参数为一个直角三角形的两个直角边,函数会返回斜边的长度。 |
| 7 | double sqrt(double); 该函数返回参数的平方根。 |
| 8 | int abs(int); 该函数返回整数的绝对值。 |
| 9 | double fabs(double); 该函数返回任意一个浮点数的绝对值。 |
| 10 | double floor(double); 该函数返回一个小于或等于传入参数的最大整数。 |
#include
#include
using namespace std;
int main ()
{
// 数字定义
short s = 10;
int i = -1000;
long l = 100000;
float f = 230.47;
double d = 200.374;
// 数学运算
cout << "sin(d) :" << sin(d) << endl;
cout << "abs(i) :" << abs(i) << endl;
cout << "floor(d) :" << floor(d) << endl;
cout << "sqrt(f) :" << sqrt(f) << endl;
cout << "pow( d, 2) :" << pow(d, 2) << endl;
return 0;
} 随机数
-
随机数生成器,有两个相关的函数。一个是 rand(),该函数只返回一个伪随机数。生成随机数之前必须先调用 srand() 函数。
-
下面是一个关于生成随机数的简单实例。实例中使用了 time() 函数来获取系统时间的秒数,通过调用 rand() 函数来生成随机数:注意需要包含的库文件
#include
#include
#include
using namespace std;
int main ()
{
int i,j;
// 设置种子
srand( (unsigned)time( NULL ) );
/* 生成 10 个随机数 */
for( i = 0; i < 10; i++ )
{
// 生成实际的随机数
j= rand();
cout <<"随机数: " << j << endl;
}
return 0;
} 数组
- C++ 支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。
-
如何数组声明?
typeName arrayName[arraySize]; -
其中typeName是你元素类型, arrayName是你的自定义数组名,arraySize是你自定义数组长度(不能是变量必须是const)即元素总个数
-
举例说明数组的复合意义?float xjh[1228]; 这里的xjh类型不是数组,而是float数组, 要这么说:"你要建立一个int数组或者float数组"
-
数组从0开始索引并用[下标]来索引
-
数组赋值也不被允许,即int xjh[3] = {1,2,2,8};int xjh1[3] = {1,2,2,8};xjh1 = xjh;这种操作不被允许,只能通过下标访问元素来对某个元素进行赋值,修改等
-
所有的数组都是由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。
-
声明数组,需要指定元素的类型和元素的数量,type arrayName [ arraySize ];
-
这叫做一维数组。arraySize 必须是一个大于零的整数常量,type 可以是任意有效的 C++ 数据类型。
-
-
初始化数组
-
可以逐个初始化数组,也可以使用一个初始化语句
-
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0};大括号 { } 之间的值的数目不能大于我们在数组声明时在方括号 [ ] 中指定的元素数目
-
如果您省略掉了数组的大小,数组的大小则为初始化时元素的个数。
double balance[] = {1000.0, 2.0, 3.4, 7.0, 50.0};快速初始化,举例如int数组 int xjh[3] = {1,2,2,8}; 即利用{}来对元素对位初始化
-
注意{}只能在初始化时使用,若int xjh[3]; 然后再xjh[3] = {1,2,2,8};则不被允许
-
-
-
数组元素可以通过数组名称加索引进行访问。元素的索引是放在方括号内,跟在数组名称的后边。
-
数组赋值,只能元素对元素,不能数组名对数组名,如下操作是非法的
int array[3] = {1,2,3}; int array1 = array;二维数组
-
int data[3][4] = {{1,2,3,4}, {5,6,7,8}, {1,2,3,4}}; int (*data)[4];先看data,显然我们知道data是个数组名,也是个指针,常规的int data[];是说data是个int数组,data也是个指向int类型的指针
-
这里的data是什么呢? data是 一个指针,这个指针指向的是个数组,这个数组是由4个int类型元素构成的,即int (*data) [4] ;这样太晦涩难懂了, 也可以这样int data[][4];意义完全相同,这里都表明了data不是数组而是指针
思路:
1⃣️int data[][3];可以看成int (*data)[3],即data是个指针,指向一个包含了3个int的数组
2⃣️指针完全可以用作数组名,例如int* ptr; ptr[1];,那么data则可以当做数组名,从而int data[][3];
-
这里明白了,那么如何传递数组的长度呢?
-
显然int data[][4]对行数是没有限制的,只是明确了列数要是4,即data指针指向的每个数组长度是4
-
-
同样的,函数对C风格字符串没有办法传递和返回,我们直接用string更合适
-
函数指针,函数指针这里交给指针笔记记录
-
二维数组和指向数组的指针
-
二维数组=指向数组的指针,因为指针名完全可以当成数组名来使用,数组名也可以当成指针来使用
-
double (*ptr)[4]; double arr[][4]; // arr[][4] 换一个写法 (*arr)[4] //(*ptr)[4] 完全可以把ptr当成数组名来使用 ptr[][4]
-

字符串
基于数组的字符串即C-style stringC⻛格字符串
- 字符串实际上是使用 null 字符 '\0' 终止的一维字符数组。因此,一个以 null 结尾的字符串,包含了组成字符串的字符。
-
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'}; char greeting[] = "Hello"; //上述两个语句是一样的效果
| 序号 | 函数 & 目的 |
|---|---|
| 1 | strcpy(s1, s2); 复制字符串 s2 到字符串 s1。 |
| 2 | strcat(s1, s2); 连接字符串 s2 到字符串 s1 的末尾。 |
| 3 | strlen(s1); 返回字符串 s1 的可见长度。(不包含NULL字符,即'\0') |
| 4 | strcmp(s1, s2); 如果 s1 和 s2 是相同的,则返回 0;如果 s1s2 则返回值大于 0。 |
| 5 | strchr(s1, ch); 返回一个指针,指向字符串 s1 中字符 ch 的第一次出现的位置。 |
| 6 | strstr(s1, s2); 返回一个指针,指向字符串 s1 中字符串 s2 的第一次出现的位置。 |
| 7 | sizeof(s1);返回整个数组的长度,包括任何字符 |
- 'S'是字符常量,相当于83的另一个写法
- "S"是字符串,字符串"S"双引号表示,他是两个字符,即'S'和'\0',而且,"S"表示的其实是字符串所在的内存地址(地址在C++中是一个独立类型,你要用这种眼光去审视地址)
- istream中的类cin提供了面向行的类成员函数getline()和get()
- getline()从输入队列中读取输入内容, 遇到换行符停止读取,同时将换行符丢弃
- getline(name,20) 读取19个元素和一个换行符
- get()从输入队列中读取输入内容,遇到换行符停止读取,同时将换行符返还给输入队列
- 如果想提出换行符,可以利用空参数的cin.get(),它可以读取任何字符,用它来处理换行符,为下一行做准备
- getline()从输入队列中读取输入内容, 遇到换行符停止读取,同时将换行符丢弃
注意区分cin.get()和getline(),前者是类方法,后者是函数
get与getline区别
char arr[100];
cout<<"输入一段文字:"<get与getline有两个参数,第一个参数是用来存储的数组名称,第二个参数代表着读取的字节数。
输入:asdfg 回车
get:只读取asdfg不读取回车,会导致下一个读取输入时第一个读取“回车”。
getline:getline读取asdfg回车,并将回车转换为“\0”读取,所以最终读取的是“asdfg\0”输入序列中无回车,下一个读取将会正常读取。
-
字符串输入,cin对象的解释
-
cin对象通过使用空白,即空格,制表符(多个空格)换行符, 来确定字符串的结束位置, 这说明cin对象在输入流中每次只读取一个单词, 读取单词后就把它放到数组中并自动添加空字符
-
基于string类库的字符串
-
首先你要包含string类库文件(头文件), string类的名称在标准名称空间std中,std::string即可完成引用
-
String类的对象来存储字符串,String类的设计让程序可以自动处理字符串的大小
-
数组不能赋值,但是String类对象可以,string s1;string s2; s1=s2;是允许的
-
还可以通过+来进行拼接合并,这里是无缝合并
-
通过类方法.size()可以快速获得String类对象的长度
C++ 日期 & 时间
- C++ 标准库没有提供所谓的日期类型。C++ 标准库没有提供所谓的日期类型。需要在 C++ 程序中引用 头文件。
指针
在学习指针时,首先要知道()的优先级高于 [] , 且 [] 的优先级高于*
明确这一点,可以对包含指针的语句分析时,抽丝剥茧,快速理解复杂的语句。
| A.B 直接成员运算符 |
A为对象或者结构体,访问A的成员B,若A是指针则不适用 |
| A->B间接成员运算符 | A为指针,->是成员提取,A->B是提取A中的成员B,且A只能是指向类,结构的指针 |
| :: | 作用域运算符,A::B表示作用域A中的名称B, A是命名空间,类,结构 |
| : | 表示继承 |
| :: | 作用域解析 | 作用域解析最优先 小中括号是二三 成员访问后增减 地址后边解引用 |
| () | 小括号 | |
| [] | 中括号,数组 | |
| -> | 成员访问 | |
| ++ | 后缀自增 | |
| -- | ||
| ! | 非 | |
| ~ | 位非 | |
| + | 正,加 | |
| - | ||
| ++ | 前缀自增 | |
| -- | ||
| & | 地址 | |
| * | 解除引用(指针) | |
- 指针是一个变量,存储的是地址信息
- P的值是地址
- *P的值是指向的数据值,完全可以把*P看成一个普通变量
- 获取地址值&
- 对于普通变量,想要获得该变量的地址,需要用地址运算符&,即&a表示的就是变量a的地址,和P一个意思
- *运算符也被称为是解除引用运算符
- 声明指针
- 指针的声明必须,指定指向的数据类型,如 int * p;
- 这里的*p 的数据类型是int,
- p是指向int类型的指针
- int *p 强调*p是个int类型,把 *p 看成普通int类型变量
- int* p强调int*是一种类型,即p是指向int类型的指针,强调的是int* ,把int*看成一种数据类型
- 指针的声明必须,指定指向的数据类型,如 int * p;
double * p; //定义声明了一个指向double类型的指针p
double* p; //定义声明了一个指向double类型的指针p,强调p是指向double类型的指针变量
double *p; //定义声明了一个指向double类型的指针p,强调*p是double类型- 指针初始化
- Question: 初始化的是指针地址还是指针指向的数据值?
- 初始化的是指针存储的地址
- int *p = &a ;
- Question: 初始化的是指针地址还是指针指向的数据值?
- 指针可以用关系运算符进行比较,如 ==、< 和 >。如果 p1 和 p2 指向两个相关的变量,比如同一个数组中的不同元素,则可对 p1 和 p2 进行大小比较。
- &运算符注意点
- 对数组名进行&操作时,得到的是整个数组的地址,而不是第一个元素的地址(数组名=第一个元素的地址,无需&运算符),虽然这两个地址是相同的,但是操作起来时会有明显差异,如下:
- &array[2]得到的是一个2字节的内存块的地址值,而&array则是一个20个字节内存块的首地址
内存分配
栈区(stack):栈区的空间由操作系统自动分配和释放,该部分主要用于存放函数的参数值、局部变量等,比如声明在函数中的一个局部变量int b,系统就会自动在栈中为b开辟空间。栈区的操作方式类似于数据结构中栈(这也许是造成许多人混淆的地方,正如有的人所说,我们可以把数据结构的栈理解成某个技术,而内存的栈正好用到了该技术,但二者其实并不一样)。另外需要注意的是,在windows下,栈是向低地址扩展的数据机构,是一块连续的内存区域。也就是说栈顶的地址和栈的最大容量是系统预先设定好的,比如在windows下,栈的大小为2MB(也有的说是1MB,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间,将会提示overflow。总之就是说栈的空间是有限的。
堆区(heap):堆区空间一般由程序员分配和释放(需要注意堆区与数据结构中的堆是两回事,其分配方式类似于链表),比如,在C中用malloc函数--- p1 = (char*) malloc(10); 在C++中用new,都将分配堆区空间。不过要注意p1本身是在栈中。
静态数据区:全局变量和静态变量都存放于该区。初始化的全局变量和初始化的静态变量放在一块区域,未初始化的全局变量和未初始化的静态变量放在相邻的另一区域。程序结束后由系统自动释放。
代码区:该区用于存放函数体的二进制代码。
- 存储类型
- 自动存储
- 在函数内部定义或{}内的常规变量,使用自动存储空间,使用自动存储类型的变量叫自动变量,其使用的存储空间成为栈
- 自动变量其实是局部变量,随函数调用诞生,结束消亡
- 栈即LIFO后入先出
- 静态存储
- 程序执行期间都存在的存储方式,可以通过函数体or {} 外定义它,也可以通过声明变量时使用关键字static
- 只要程序活着,静态变量就一直存在
- 动态存储
- 运算符new和delete管理一个内存池,相当于自动存储的栈,但这里叫做堆,栈和堆事独立分开的
- 动态存储在程序运行时按需分配内存,用完就删除
- 自动存储
- 模版类vector
- vector也是一种动态数组,同样是new和delete管理内存的,但vector是自动完成的
- vector name(number);
- vector name;
- 指针和运算符
- 指针算术上述已有所述,这里结合自增运算符
- *++p,这里表示先把p的地址值增加1个单位的字节数,再结合*解除运算符
- *p++,同理
- ++*p,这里是把*p直接看成普通变量,再结合++自增运算符
- (*p)++ 这里是把*p看成普通变量
指针 vs 数组
数组名是一个常量指针
指向数组的指针
牢记下边两个恒等式 arr为数组名,p为数组名地址值赋值的指针, p=arr
左边是数组表示法,右边是指针表示法
arr[i] == *(p+i)
&arr[i] == p + i
- 一个指向数组开头的指针,可以通过使用指针的算术运算或数组索引来访问数组(就是上述两个式子)
- 指针和数组并不是完全互换的,数组名相当于一个指针常量,其值为数组0号元素的首地址。
- 不可改变数组名的值,但指针变量可以进行运算
- 指针运算符 * 应用到 数组var上是完全可以的,但修改var存储的值是非法的,只能修改var代表的数组的数组成员的值。
- 例外:sizeof运算符对数组名取长度,返回的是整个数组长度
#includeusing namespace std; const int MAX = 3; int main () { int var[MAX] = {10, 100, 200}; int *ptr; ptr = var; for (int i = 0; i < MAX; i++) { *var = i; // 这是正确的语法 var++; // 这是不正确的 ptr++; //TRUE, 指针加1个int单位字节,从而指向了下一个元素 } return 0; } - 数组名等于第0个元素的首地址
- arr和&arr[0]相同,第0个元素首地址
- arr和&arr虽然值相同,但是arr是第0个元素首地址,而&arr是整个数组首地址
- 当赋给指针进行算术运算时,前者将增减一个元素内存字节大小,而后者将增减一个数组字节大小
- 创建一个指向数组的指针
- 下边代码中:
- pa是个指针,指向数组0元素首地址
- pb是个指针,和pa相同
- pbb是个指针,与pa,pb同值,但pbb指向的是整个数组
- pc是个指针,指向一个包含了100个double的数组
- pd是个数组,该数组包含了100个double*指针元素
- 下边代码中:
double arr[100];
double *pa = arr;
double *pb = &arr[0];
double *pbb = &arr;
double (*pc)[100];
double *pd[100];new运算符分配内存
- 在C语言中,使用库函数malloc()来分配内存,在C++中也兼容,但是推荐使用new运算符来分配内存
- new运算符的操作流程:
- ①在运行阶段为一个int值即int类型的数据,该数据没有名字,即无内存标签,为这个数据来分配未命名的内存(这个int类型数据是占内存空间的,只不过没有为这个内存空间打标签)
- ②分配未命名的内存,同时利用指针访问这个内存块
- ③我只需要告诉new,我需要创建一个什么类型的数据即可
- ④new运算符会自动找到一个合适的内存块,并返回内存块的地址
- ⑤总而言之,我只需要告诉new数据类型即可,new会把一个对应的内存块地址交给一个指针
- int * ptr = new int;
- 前后两个数据类型要对应,这里是int
- Q:指针初始化和new分配内存有什么区别呢?
- int * p = &a; 指针初始化,可以通过非指针变量来访问数据,即通过a来修改内存块中的数值,也可以通过*p来修改
- int * ptr = new int; new分配内存只能通过*ptr来修改访问数据
- Q:对地址你了解多少呢?
- 地址是内存块的名字,变量则是内存块的标签
- 注意:地址只是内存块的第一个bit的名,比如x01010101,如果是int类型,那么加32就是该内存块的最后一个bit的地址名
new运算符创建动态数组
- 当数据量很大时,应避免使用常规数组,字符串,结构等,应尽量使用new运算符来创建动态数组
- 场景: 当你写程序时,发现不确定是否使用数组,那么用不用数组全看输入什么数据,这时候就需要了解一下静态联编和动态联编的问题
- 静态联编: 在编译时分配内存,不管程序是否调用数组,都会占据相应的内存空间
- 动态联编: 在编译时不分配内存,即在运行时根据程序是否调用而创建相应大小的内存空间,创建的长度和实际长度相同,这种特殊的数组叫做dynamic array动态数组\
- int *ptr_dynamic_array = new int[11];
- []表示元素个数
- new返回数组第一个元素的地址
- 使用完毕时,要使用delete运算符释放数组,直接delete ptr_dynamic_array
- 动态数组的使用,只需要把指针当作数组名来用即可,比如ptr_dynamic_array[10]
- new运算符的补充
- 通过new运算符可以创建动态数组,也可以创建动态结构和动态类,原理和new创建动态数组一样,即在运行时按需分配内存块,返回内存块首地址
- inflatable * ps = new inflatable;
- *ps是个inflatable结构类型的指针,inflatable*和int*一个道理
- 这里补充一下,如果你的指针是个结构,那么成员的访问就需要用成员运算符->来访问
指针算术
- 指针+1,这里+1表示增加1个指针指向类型的内存字节数,比如int * p; p+1表示p存的地址值增加8个字节
- 数组,地址,指针
#includeusing namespace std; int main() { int arr[3] = {0,1,2}; cout< - 变量指针可以递增,数组不能递增,数组可以视为一个常量指针。
- 数组名是其第一个元素的地址值,指针变量存放的也是地址值,所以指针变量可以当作数组名使用。
- 对数组名进行&取地址,需要注意:
- 对数组名取地址,&tell得到的是整个数组的地址,即得到的是一个数组所占内存块的块地址,&tell
- 对数组名取地址后,&tell 所可以赋值的指针,则是指向了一个包含了10个元素的数组
- 将&tell + 2那么,地址必然增加的是20
- 对数组第一个元素取地址,&tell[0] 就是一个元素所占内存块的块地址,往往默认为是数组名tell
- 把数组名tell看成指针,由于tell就是&tell[0],那么tell就是一个指向short类型的指针常量,
- 将tell+1,那么地址增加2个字节
- 对数组名取地址,&tell得到的是整个数组的地址,即得到的是一个数组所占内存块的块地址,&tell
- 因此对于数组和指针,既可以使用数组表示法,也可以使用指针表示法。
int main(){
double * ptr = new double;
ptr[1] = 100.21;
cout<<*(ptr+1)<
using namespace std;
const int MAX = 3;
int main ()
{
int var[MAX] = {10, 100, 200};
int *ptr;
// 指针中最后一个元素的地址
ptr = &var[MAX-1];
for (int i = MAX; i > 0; i--)
{
cout << "Address of var[" << i << "] = ";
cout << ptr << endl;
cout << "Value of var[" << i << "] = ";
cout << *ptr << endl;
// 移动到下一个位置
ptr--;
}
return 0;
}
Address of var[3] = 0xbfdb70f8
Value of var[3] = 200
Address of var[2] = 0xbfdb70f4
Value of var[2] = 100
Address of var[1] = 0xbfdb70f0
Value of var[1] = 10
#include
using namespace std;
int main()
{
int max = 3;
int* ptr = new int[max];
*ptr = 5;
ptr[1] = 11;
ptr[2] = 12;
for(int i=0;i<3;i++)
{
cout<<"ptr["< 辨析:
short (*pas)[20];
short *pas[20];
int *ar2[4];
int (*ar2)[4];
//解析
//牢记优先级() [] *
short (*pas)[20]; //pas是指针,指向由20个short元素组成的数组的指针
short *pas[20]; //pas是个数组,包含了20个指向short类型指针的数组
int *ar2 [4]; //ar2是个数组,表示由4个int指针组成的数组
//-1-参考int arr[4];表示arr是个int数组,长度为4
//-2-int* ar2[4];表示ar2是个int*数组,长度为4,只不过元素都是只想int的指针
int (*ar2) [4];//ar2是个指针,指向一个包含了4个int的数组
//-1-先看括号里面,(*ar2),表示ar2是个指针
//-2-再看括号外面,int ()[4];表示名为()的int数组,长度为4指针和const
- const表示常量,对于指针而言,有两个目标,一个是指针存的地址值,另一个是指针指向的变量值
- 直接举栗子说明
// NO.1 right
int age = 30;
const int * p = &age; //无法通过p修改age,age自身可修改
// NO.2 right
const int age = 30;
const int * ptr = &age; //无法通过ptr修改age,age自身不可修改
// NO.3 false
const int age = 30;
int *ptr = &age; //可通过ptr修改age,age自身不可修改,矛盾,ERROR
- 接下来辨析如下四种类型,主要是指针常量, 指针变量,和常量,变量之间的关系辨析
- int* 指针 不能用const int变量来初始化,反之可以
#include
using namespace std;
int main() {
/*当对象是变量或者常量时,思考const的存在或不同位置,能否导致指针自身和指针指向的对象 改变?*/
int num = 10; //当对象是int变量
int test = 1;
int * num_ptr0 = # // TRUE, *num_ptr0,可修改,num_ptr0可修改,num可修改
const int * num_ptr1 = # // TRUE, *num_ptr1常量不可修改,num_ptr1可修改,num可修改
int * const num_ptr2 = # // TRUE, *num_ptr2可以修改, num_ptr2不可修改,num可修改
const int* const num_ptr3 = # // TRUE, *num_ptr3常量不可修改, num_ptr3常量不可修改,num可修改
const int price = 100; //当对象是int常量
int * price_ptr0 = &price; //ERROR, 指针指向类型和指向对象类型不匹配, nt类型的实体不能用const int来初始化,反之可以
const int *price_ptr1 = &price; //TRUE,
int * const price_ptr2 = &price; //ERROR, 指针指向类型和指向对象类型不匹配, int类型的实体不能用const int来初始化,反之可以
const int* const price_ptr3 = &price; //TRUE
return 0;
} - 在变量声明的时候,如果没有确切的地址可以赋值,为指针变量赋一个 NULL 值是一个良好的编程习惯。赋为 NULL 值的指针被称为空指针。
- 如需检查一个空指针,您可以使用 if 语句,
#include
using namespace std;
int main ()
{
int *ptr = NULL;
cout << "ptr 的值是 " << ptr ;
return 0;
}
ptr 的值是 0
if(ptr) /* 如果 ptr 非空,则完成 */
if(!ptr) /* 如果 ptr 为空,则完成 */ 函数指针
指向函数的指针
- 获取函数的地址
- 直接使用函数名(注意区分函数名和函数返回值),如下,think为函数名,think()为函数返回值。
process(think);
process(think());- 声明函数指针与初始化赋值
- 牢记优先级() [] * 的顺序为从高到低
- 需指定函数的返回类型、特征标(直接将函数声明的函数名用指针替换即可,如下)
double pam(int);
double (*f)(int);
f = pam;- 函数指针的调用
- 直接把(*f)或者f作为函数名pam来用,都可以,注意(*f)的括号()
double pam(int);
double (*f)(int);
f = pam;
double x = pam(4);
double y = (*f)(4);
double z = f(4);- 辨析
double pam(int);
double *f1(int);
double (*f2)(int);
int arr[10];
int *p = &arr[0];
int *a = arr;
int *b = &arr;
int *c[10] = &arr;
int (*d)[10] = &arr;
上述代码中:
f1是个函数,返回值类型是个double* 指针
f2是个指针,指向了一个函数,类型就是double (*)(int);
p是个指针,指向数组arr的0号元素首地址
a是个指针,和p一样(数组名arr就是0号元素首地址)
b是个指针,虽然和a一样的值,但指向的是整个数组内存块的首地址,当b进行+1运算时,会增加整个数组内存字节数大小
c是个数组,包含了10个int* 指针元素的数组
d是个指针,指向了一个包含10个int元素的数组
深入学习函数指针
(下一节函数篇也有涉及)
函数原型
在函数原型中,特征标即参数列表有如下规则:
- arr[] 和 *arr 等价(仅作为特征标时可以这么做)
- 可以省略标识符 const double ar[] 简化为 const double [], const double *arr 同理const double *(仅在函数声明时可以,函数定义时不可以省略!)
包含函数指针的数组
const double * (*pa[3])(const double *,int) = {f1,f2,f3};
语句书写思路:先写出返回类型和特征标 const double * ()(const double*, int) 再向()内填写一个包含指针的数组表达式*pa[3]
指向包含函数指针数组的指针
const double * (*(*pa)[3])(const double *, int) = &pa;语句书写思路:先写出返回类型和特征标const double * ()(const double *, int)再向()内追加 一个 指向包含指针元素的数组的 指针表达式*(*pa)[3]
结构篇
- 数组允许定义可存储相同类型数据项的变量,结构允许您存储不同类型的数据项。
- 可以定义指向结构的指针,方式与定义指向其他类型变量的指针相似,把 & 运算符放在结构名称的前面
- 指针访问结构的成员,必须使用 -> 运算符
struct Books *struct_pointer;
struct_pointer = &Book1;
struct_pointer->title;- 更简单的定义结构的方式,您可以为创建的类型取一个"别名". 现在,您可以直接使用 Books 来定义 Books 类型的变量,而不需要使用 struct 关键字(一般情况下即使不引用也是可以忽略strcut关键字来定义结构对象的)
//previous
struct Books
{
string name;
int book_id;
};
struct Books Book1;
Books newBook;
newBook.name = "abcd";
//now
typedef struct Books
{
string name;
int book_id;
}BOOKS;
BOOKS Book1, Book2;为了访问结构的成员,我们使用成员访问运算符(.)
struct type_name {
member_type1 member_name1;
member_type2 member_name2;
member_type3 member_name3;
.
.
} object_names;
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
typedef struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
}Books;函数篇
文章使用Q&A问题回答形式,内容涉及C++函数部分。
函数基础
- Q:使用函数的基本步骤?
- 提供函数定义,提供函数原型,调用函数
- Q:库函数是什么
- 库函数是已经定义好和编译好的函数,在标准库 头文件中定义相关原型,在程序中包含该头文件后,正确调用库函数即可
- 例如C库头文件cstring中有strlen()函数
- 库函数是已经定义好和编译好的函数,在标准库 头文件中定义相关原型,在程序中包含该头文件后,正确调用库函数即可
//calling.cpp
#include
void simple(); //原型
int main(){
simple(); //调用
return 0;
}
//定义
void simple(){
cout<<"ok"< - Q:什么是void函数
- 没有返回值的函数
- 通常可以使用void函数执行某种操作,例如打印计算次数等。
- 没有返回值的函数
- Q:有返回值的函数应该注意什么?
- 1.必须有return返回语句,
- 2.返回的类型不能是数组,但可以将数组作为结构和对象的成员来返回。
- 1.必须有return返回语句,
- Q:若函数包含了多条retrun返回语句将会如何?
- 遇到第一条retrun返回语句后结束该函数。
- Q:为什么一定要有函数原型?
- 原型描述了函数到编译器的接口,将函数的返回值和特征标告诉编译器,编译器会检查该函数,从而降低出错率。
- Q:原型的书写语法是什么?
- 原型是一条语句,以;结束
- 原型可省略变量名,只保留类型列表 double cube(int, double, long);
- 原型是一条语句,以;结束
- Q:什么是按值传递?
- 将实参复制给形参,形参会得到内存分配,其存储持续性为自动,随函数存亡。
- Q:什么是形参,实参?
- 传递给函数的值是实参,接受实参的变量是形参。
- Q:函数参数传递的顺序是?
- 从左到右一次赋值给相应形参,不可跳过。
- Q:若函数参数中存在多个同类型参数,如3个int,则如何书写参数列表?
- 必须分别指定类型int a,int b, int c,不可组合声明int a,b,c
- Q:什么是递归?
- 自己调用自己,但main()不可。
- 递归需包含终止条件,否则将无限递归,一般把递归调用放在if语句中
- 和下楼梯一样,逐层下,逐层回。
- 自己调用自己,但main()不可。
- Q:写一个按下q键,循环终止的代码
#include
int main(){
char ch;
cin >> ch;
while(ch !='q'){
return -1;
}
return 0;
} 函数和数组
- Q:函数如何用指针来处理数组?
- 当且仅当,在函数原型中,int &arr 和 int arr[] 含义相同,即arr是个int*类型。
- arr存储的是数组的第一个元素首地址
- 在函数原型外,无法通过int arr[]来声明指针
- 当且仅当,在函数原型中,int &arr 和 int arr[] 含义相同,即arr是个int*类型。
- Q:数组名的指针表示法和数组表示法是什么?
- 数组表示法 int arr[] 指针表示法 int * arr
- Q:将数组作为参数传递给函数的结果是什么?
- 没有将数组整个传递给函数,而是传递了数组的地址,和包含元素的类型以及元素的个数。
- 按值传递常规变量时,函数会复制实参给形参,不会使用实参数据,传递数组时,函数将直接使用数组原始数据。
- Q:是否违反函数不能传递数组的规则?
- 不违反,传递的是地址值,并不是数组整体本身。
- 没有将数组整个传递给函数,而是传递了数组的地址,和包含元素的类型以及元素的个数。
- Q:数组名和指针的相关性是好事吗?
- 是的,将节省复制数组的时间。
- Q:对函数传递数组时,应传递哪些元素?
- 数组的地址,和长度
//prototype
void fillArray(int arr[], int size);
void fillArray(int* arr, int size);
void fillArray(int [], int);
void fillArray(int*,int);
- Q: 如何防止函数修改数组数据?
- 使用关键字const
//prototype
void show_array(const double [], long);
void show_array(const double arr[], long n);
void show_array(const double *,long);函数和二维数组
- Q:如何表示二维数组?
- C++中函数传递二维数组时,需传递行数参数,同时需要指明具体列数。下边就是size行4列的数组。
//prototype
void show_array(int (*arr)[4], int size);
void show_array(int arr[][4], int size);
void show_array(int (*)[4], int);
void show_array(int [][4], int);- Q:创建一个返回指针的函数,说明使用场景。
- 返回字符串数组时,函数无法返回一个C风格字符串本体,但可以返回它的地址值,即一个指针变量。
char* builder(char c,int n){
char* pstr = new char[n+1];
pstr[n] = '\0';
while(n-->0){
pstr[n] = x;
}
return pstr;
}函数和结构
- Q:如何传递结构到函数中?
- 结构与数组不同,结构对象将被视为一个整体,即一个普通变量
- 按值传递结构,将复制实参给形参
- 按指针传递,则可以通过指针间接访问结构对象,直接传递结构地址,利用&地址运算符
- 按引用传递,则可以直接访问结构对象
- 结构与数组不同,结构对象将被视为一个整体,即一个普通变量
- Q:按指针传递结构,应注意什么?(假设结构名为place,结构对象为bank)
- 调用函数时,将结构的地址传递&place,而不是结构本体
- 函数形参应为指向结构的指针place*,若不想修改结构,则 const place*
- 利用指针访问结构对象成员时,应使用间接访问运算符->而不是直接访问运算符.
- 调用函数时,将结构的地址传递&place,而不是结构本体
- Q:若函数想修改指针传递的结构,那么如何高效的返回结构?
- 传递两个指针给函数,一个指向原结构,另一个指向修改后的结构。
- 注意!函数不返回结构,而是通过指针来直接修改,该命题是个伪命题,不要返回结构。
- 传递两个指针给函数,一个指向原结构,另一个指向修改后的结构。
void rect_to_polar(const rect* pxy,polar* pda){
cout<<"begain"<distance = (pxy->x + pxy->y);
pda->angle = atan2(pxy->y,pxy->x);
cout<<"OK"< 函数和string对象
- Q:string对象和C风格字符串的区别?
- string对象和结构相似,两个对象可以彼此赋值。但C风格字符串本质是数组,无法直接赋值。
函数指针
(上述,指针相关专题也有涉及)
- Q:什么是函数指针?
- 指向函数的指针。
- Q:如何获取函数的地址?
- 函数名本身就是地址
- 区分函数think()和函数名think,think表示函数地址,think()则是函数调用(返回值)
- 函数名本身就是地址
- Q:如何声明函数指针?
- 直接将函数原型中的函数名替换成(*ptr)
double pam(int);
double (*ptr_f)(int);- Q:如何利用指针去调用函数?
- 有两种方法
- 方法一:*pf(5)
- 方法二:pf(5)
- 有两种方法
#include
double pam(int);
void estimate(int lines, double (*pf)(int));
int main(){
using namespace std;
double (*pff)(int);
pff = pam;
cout<<"pff(4)="<>code;
cout<<"estimate="< 案例分析
- Q:创建一个包含3个函数指针的数组
const double * (*pa[3]) (const double * , int);
- Q:如何调用上述数组的元素?
- 为什么px是const double *类型? 因为函数的返回值是const double*类型
const double * px = pa[0](av,3); const double * py = (*pa[2])(av,4);
- 为什么px是const double *类型? 因为函数的返回值是const double*类型
- Q:创建一个指针,该指针指向包含3个函数指针的数组
-
const double * (*(*pa)[3]) (const double * ,int);
-
- Q:如何通过上述指针来调用函数
-
const double * px = (*pa)[0](av,3); const double * py = *(*pa)[2](av,4);
-
内联函数
-
编译过程最终是生成可执行文件,然后运行,在运行程序时,操作系统将可执行文件,即这些机器语言指令装载到内存中,然后按照指令的地址逐步执行,有时候遇到循环或者条件分支语句时会跳着执行,函数调用也会从一个地址跳到函数所在的首地址,函数结束则返回
-
当程序跳转到函数地址时,即程序在函数调用后会立即存储该指令的地址,然后把函数参数放到堆栈内存池中,然后直接跳到函标记函数起点的内存块处开始执行函数代码,最后函数结束就跳回去了。
-
来回的跳跃并记录跳跃位置,需要太多的开销了,因此C++提供了内联函数,无需跳跃,但需要更多内存,即如果程序再10个不同的地方调用同一个内联函数,则这个内敛函数将有10个副本
-
使用: 函数声明或定义前加关键字inline即可
- Q:程序是如何调用函数的?
- -1-运行程序后,OS将指令载入内存,每条指令都占用内存空间
- -2-逐步按逻辑执行指令,遇到函数调用时,则跳到函数的地址处,执行函数体指令,结束后返回跳转位置
- -3-当执行到函数调用指令时,程序会立刻存储指令的内存地址,将函数参数复制到堆栈中,跳转到函数地址,执行完毕后,读取之前存的内存地址,跳回。反复跳转会有一定的开销,因此小函数可使用内联函数。
- Q:什么是内联函数?
- 编译器将函数体的代码替换调用函数指令,无需跳转,直接逐步执行函数体中的指令,代价是占据更多内存,但节省时间。
- Q:如何定义内联函数?
- 关键字inline
- -1在函数声明前加上关键字inline
- -2在函数定义前加上关键字inline
-
inline double square(double x) {return x*x;}
- 关键字inline
- Q:如何调用内联函数?
-
#includeinline double square(double x){return x*x*;} int main(){ using namespace std; double a,b; double c = 0.294; a = square(c); b = square(a); cout<<"a="< - Q:什么是引用?
- C++的一种复合类型,引用变量
- 引用变量是对另外一个变量起个新名字,即对其内存添加一个新标签。
- 引用变量常作为函数的形参,使得函数直接使用变量原始数据,而不是其副本,也就省去了按值传递复制给形参变量的步骤
- C++的一种复合类型,引用变量
- Q:如何使用引用?
- 地址运算符重载&,用来声明引用,下述int&表示指向int的引用,rodents的类型是int&
-
int rats; int & rodents = rats;
-
- 地址运算符重载&,用来声明引用,下述int&表示指向int的引用,rodents的类型是int&
- Q:引用和指针的区别?
- 声明引用变量时,必须初始化,而普通指针变量无需,但const指针变量和引用变量一样,声明时要初始化。
- Q:函数参数传递数据的方法有哪几种?
- 共三种,分别是:
- -1-按值传递,直接将实参复制给形参,无法修改原数据;
- -2-按指针传递,通过指针变量,间接访问数据本身,间接修改原数据;
- -3-按引用传递,通过引用变量,直接访问数据本身,直接修改原数据。
- 共三种,分别是:
- Q:三种函数参数传递方法的使用场景
- 传递结构时,指针*or引用&,且不想修改时,const* or const&
- 传递类对象时,使用引用&,且不修改时,const&
- 传递数组时,使用指针*,且不想修改时,const*
double cube (double); double square(double*); double atan(double&);- Q:如何判断函数参数是通过哪种方法传递数据的?
- 只能通过函数原型或者函数定义,查看特征标来判断。
- Q:如何在使用 引用传递时,禁止函数修改原数据?
- 使用const关键字
-
double square(const double &);
-
- 使用const关键字
- Q:创建一个返回类型和参数都是引用类型的函数。
-
#includestruct free_throws{ std::string name; int made; int attempts; float percent; }; free_throws & accumulate(free_throws&, const free_throws); int main(){ free_throws ini = {"ini",0,0}; free_throws one = {'A',1,11}; free_throws two = {'B',2,22}; free_throws team = {"all",0,0}; free_throws good = {"good",100,100}; free_throws fact_all; accumulate(team,one); fact_all =accumulate(team,two); cout<
-
- Q:如果返回值不是引用,那么返回的是什么?
- 返回值是引用时,retrun返回自身,不是引用时,return A返回的是A的拷贝,A会复制给一个临时内存位置,调用程序将使用它,结束后释放。
- 上述代码中,fact_all =accumulate(team,two); 直接把team复制给fact_all, 如果返回的不是引用类型,那么先把team复制到一个临时位置,然后再复制给fact_all
- Q:能否返回一个临时变量的指针?
- 应避免,因为该临时变量在函数结束后将释放其内存空间
-
const free_throws & clone2 (free_throws & ft){ free_throws newguy; newgy = ft; return newgy; //禁止这么写! }
- Q:如何禁止给accmiulate()返回的引用变量赋值?
- accumulate(ini,team) = good; //由于accumulate返回的是引用,因此good覆写ini
- 只需要将accumulate修改成:
const free_throws & accumulate(free_throws&, const free_throws&);
- 只需要将accumulate修改成:
- accumulate(ini,team) = good; //由于accumulate返回的是引用,因此good覆写ini
- Q:什么时候函数参数使用引用类型?
- -1-想修改调用函数中的数据对象
- -2-想提高程序运行速度
默认参数
- Q:什么是默认参数?
- 当函数调用时,输入实参少于参数个数时,其他参数则使用默认参数值。
- 当默认参数被输入实参时,自动使用实参值。
- Q:如何设置默认参数?
- 必须通过函数原型,且通过从右向左的顺序,将值赋给函数原型中的参数。(即要为某个参数添加默认值,必须保证他右边的全部参数都有默认值)
char * left(const char* str, int n =1); -
在函数定义部分中则无需上述。
//.cpp #includechar * left(const char* str, int n = 1): int main(){ } char * left(const char* str, int n){ char* p =new char[n+1]; retrun p; }
- 必须通过函数原型,且通过从右向左的顺序,将值赋给函数原型中的参数。(即要为某个参数添加默认值,必须保证他右边的全部参数都有默认值)
- Q:默认参数的作用?
- 允许使用不同参数个数来调用同一个函数,但要求参数输入时要从左向右顺序输入,不跳跃,不间隔。未传递实参的参数,使用默认参数。
函数重载
- Q:什么是多态?
- 多态:多种形式
- Q:什么是函数的特征标?
- 函数特征标:参数的个数、类型和排列顺序。
- Q:函数重载的条件:
- 函数特征标不同
- 其中类型和类型引用不作区分,且const和非const也不作区分
- 函数特征标不同
- Q:什么时候考虑使用函数重载?
- 函数执行的算法相同,但处理的数据类型不同时
-
术语:多态和重载,指的是同一回事,就是同一物体的多种形式
-
函数多态=函数重载,即允许函数有多种形式,即有多个同名函数,多态是函数多态,重载其实是函数名称重载
-
无论多态还是重载,意义就是,名字相同,参数列表不同
-
函数特征标:函数的参数列表,如果两个函数, 参数数目,参数类型,参数排列顺序,三者都相同,那么他们的特征标相同,显然这里和参数变量的名称无关
-
C++允许定义函数名称相同的函数, 条件就是其特征标不同
double cube(double x); double cube(double &x); //看起来特征标是不同的,其实,类型引用和类型本身是同一特征标 double long(double x); long long long(double x); //显然这里的long函数是不允许被重载的,因为特征标是相同的,即返回值类型并不是特征标之一函数重载很棒,但不要滥用,仅在函数执行基本基本相同任务,但对象的数据类型不同时,可以考虑函数重载
函数模板
- Q:什么是范型?
- 非具体类型
- Q:什么是函数模板?
- 函数模板是通用的函数描述,通过范型来定义函数,将类型参数化。
- 模板并不创建函数,而是告诉编译器如何定义函数
- 根据函数模板来定义函数,得到的函数根据输入参数的类型,来自动将ABC替换成其类型。
- Q:如何创建模板?
- template
- 使用两个关键字,template 和 typename或者使用class替代typename
- 必须使用<>
- 类型名任意命名
- Q:程序如何匹配由重载模板定义的函数 ?
- 根据函数参数特征标
-
函数模板是通用的函数描述, 使用"泛型"来定义声明函数,这里的"泛型"可以用具体类型替换,比如int, double, long等,具体方法就是通过具体的类型如double作为参数, 传递给模板,编译器就会自动生成该类型函数
-
另外的名字,①函数模板这种编程方法,也叫作通用编程,因为没有具体化, ②函数具体类型是由参数来表示的,这种模板特性也叫参数化类型
-
如何创建函数模板??利用关键字template和typename,注意这里typename也是个关键字,区分我们之前的这是我们自己为方便而写的一个概括而已
函数模板的核心: 抛开具体的变量类型, 着重关注数据处理的算法.
意思是变量用T统一代替
-
templatevoid mySwap(S a, S b) { S c; c = a; a = b; b = c; } //案例2: template xjh* findTrueFriend(xjh* friend1, int age) { if(age>10) { cout<<*friend1<
函数模板也不能总是乱用,就像函数重载,函数重载是在函数执行基本相同任务时,对象类型不同可以用函数重载,而函数模板则是在执行完全相同任务时,如果对象类型不同,则用函数模板
-
函数重载的基本相同告诉我们,并非要执行完全相同的计算方法即算法,所以函数模板也可以进行重载,即模板重载
-
void xjh(AnyType &a, AnyType &b) 这里的函数模板,其实你也可以叫模板函数, 的特征标是AnyType &,AnyType &
-
模板的实例化和具体化
-
在代码中包含函数模板本身并不会生成函数定义,这个模板的工作只是用于生成函数定义的方案.就是说当编译器通过具体的类型来使用模板时,得到的是模板的实例, 这个模板的实例才是函数的定义声明
-
联想变量的初始化,那么我们的模板能不能在创建模板时初始化一个类型呢?可以
-
- Q:创建一个模板,并对其重载
-
#includetemplate void swap(A&, A&); //模板重载 template void swap(A*, A*, int); int main(){ int i = 10, j = 20; swap(i,j); int d1[3] = {0,1,2}; int d2[3] = {3,4,5}; swap(d1,d2,3); return 0; } template void swap(A& a, A& b){ A temp; temp = a; a = b; b = temp; } template void swap(A*a, A*b, int n){ A temp; for (int i=0; i
-
函数的构建模板如下
typeName functionName(parametersList); void mian(){} typeName functionName(parametersList) { statements return value; } //retrun无法返回数组,但可以是结构,类对象,或者可以把数组作为结构和类对象的成员返回 //函数参数也不能是数组函数无法返回数组,函数参数也不能是数组,但是可以通过结构、类来使用数组,或者在参数重吧
定义函数时参数列表的变量是形参,调用函数时,是实参,实参一直存在(当然这里是普通变量,new则另说),形参,在函数被调用时,计算机为形参分配内存,函数结束时,释放这些内存块,所以形参叫局部变量,他们的作用域仅在该函数内部
typeName fucntion(int param1, &prama2){} void main() { int a = 10; int b =11; function(a, &b); } //a和b都是实参,param1和param2都是形参把数组和函数结合在一起
等等!不是说参数不能是数组,且retrun无法返回数组吗???难道只是做参数传递吗??No
int functionArray(int array[], int n); //这里的array[]实际上是个指针,还记得指针和数组名其实是一个东西吗?-
是的, int array[]表示一个数组, 而方括号是空的,则表示可以传递任何长度的数组给函数functionArray(),其实是错误的, 这里的array是指针!!!但是你把他看成数组又何妨呢?
-
另外,如果你想通过函数来处理数组, 你最好把数组名,数组类型和数组的长度都告诉函数
如果你想让函数可以修改传进来的数组
void function(double arr[], int n){}如果不想让函数修改传进来的数组
void function(const double arr[], int n){}运算符的多态
函数有重载,即函数的多态,运算符也有,即运算符重载,运算符的多态.函数在的重载想让你用相同函数名完成基本差不多的操作.
运算符也有重载,实际上你已经学习过了,比如*即是乘号,也是地址运算符,根据运算符左右目来确定具体功能
我们知道函数重载可以自己定义,那运算符其实也可以
如何进行运算符重载?利用operator现有运算符(参数), 这里operator是个函数,不同的是,你需要在函数名后紧跟你需要重载的运算符,比如operator+()
//time.h class time { private: int hours; int munutes; public: time(); time(int h, int m = 0); void AddMin(int m); void AddHr(int h); void Reset(int h=0, int m=0); time sum(const time & t) const; void Show() const; // 加const表明,该函数只能是只读的,不能修改私有变量的值。加强安全性。 } //endif 这里sum的参数运用了&运算符重载,即引用 //把stock::sum()函数利用运算符+的重载来实现 //time.h class time { private: int hours; int munutes; public: time(); time(int h, int m = 0); void AddMin(int m); void AddHr(int h); void Reset(int h=0, int m=0); time operator+(const time & t) const; void Show() const; }当使用operator+成员函数时, 你也可以通过对象用.运算符来调用该方法函数,你也可以直接用+运算符来操作该
int main() { total = coding.operator+(fixing); total1 = coding + fixing; }类
对象和类
直接成员运算符.
间接成员运算符->
作用域解析符::
- Q:面向对象编程的特性是什么?
- 抽象
- 封装和数据隐藏
- 多态
- 继承
- 代码的可重用性
- Q:如何使用OOP面向对像编程思想?
- 从用户角度考虑对象
- 描述对象所需的数据
- 描述用户和数据交互所需的操作
- 完成接口,确定接口实现和数据存储
- 创建程序
- 从用户角度考虑对象
- Q:指定基本类型将完成哪些工作?
- 决定数据对象需要的内存数量
- 决定如何解释内存中的位
- 决定使用对数据对象使用的方法/操作
- Q:什么叫类?
- 类是将数据抽象出来,转换成用户自定义类型的一个C++工具
- 该工具将数据表示和数据操作方法 组合成一个 整洁的包
- Q:类的组成?
- 类声明:描述了该类的基本构成(常在.h中)
- 描述数据部分,由数据成员组成
- 描述公有接口部分,由成员函数组成(函数原型)
- 类方法定义:实现了该类的具体操作细节(常在.cpp中)
- 描述如何实现上述成员函数(函数定义)
- 类声明:描述了该类的基本构成(常在.h中)
- Q:如何理解接口?
- 接口可以简单的理解成函数原型,所谓细节实现则对应函数定义
- 接口可以快速让用户知道如何使用该方法来实现某种操作,而不必去学习该方法完成某种操作的原理。
- Q:类是如何实现数据隐藏的?
- 通过对成员设置访问权限,即公有和私有
- Q:什么是封装,数据隐藏?
- 将实现细节放在一起,并将细节和抽象分开,称为封装。
- 将类函数定义放在.cpp文件中,类函数声明放在.h中,也是一种封装。
- 防止程序直接访问数据称为数据隐藏,也是一种封装,将实现的细节放在了私有部分,比如私有函数set_tot()
- 将实现细节放在一起,并将细节和抽象分开,称为封装。
- Q:数据隐藏的作用?
- 防止直接访问数据
- 无需了解数据表示方法,直接用即可
- 只需要知道如何使用成员函数,了解成员函数功能,无需知道成员函数实现的细节。
- 当有更好的算法时,可直接修改成员函数实现细节,无需修改接口,使得维护梗方便。
- Q:如何访问隐藏的数据?
- 只能通过公有函数或者友元函数来访问私有成员
- Q:类是如何实现公有私有成员的?
- 通过类作用域,类定义中的名称作用域都是整个类,出了该类则无效,即不能从外部访问类成员,因为这些成员在外部是无效的
- 通过对象,使用成员运算符或作用域解析符,来调用公有函数,在公有函数中也就到了类作用域中,于是可以访问该作用域中的成员。
- Q:类声明的构成?
-
class stock{ private: char company[30]; int shares; double share_val; double total_val; void set_tot() { total_val = shares*share_val; } public: stock(); ~stock(); void acquire(const char*, int, double); void buy(int, double); void sell(int,double); void update(double); void show(); }
-
- Q:如何利用数据隐藏的思想创建类?
- 数据项放在私有部分,类接口(成员函数/原型)放在公有部分。
- Q:类对象默认访问权限是??
- 私有
- Q:类和结构的主要区别是?
- 类的默认访问权限是公有,类则是私有
- Q:类成员函数和常规函数的异同是?
- 相同点:都有函数头和函数体、返回类型、参数和原型
- 不同点:
- 成员函数定义时,需要用作用域解析运算符::来表明 该函数所属的类
- 公有成员函数可以直接访问类的私有成员
- Q:能否在类声明中直接定义函数?
- 可以,此时函数直接转换成内联函数,上述代码中的set_tot()函数就是如此。
- Q:类对象是如何分配内存空间的?
- 每个类对象都有自己的存储空间,存储内部变量和类成员,创建新类对象时,为其内部变量和类成员开辟新内存空间;
- 同一类的对象,共享该类的方法,即每个方法只有一个副本,创建新类对象时不开辟新内存空间。
对象、数据、和成员函数- Q:为什么不能像结构一样初始化类对象?
- 因为结构的成员访问权限是公开的,而类的成员访问权限是私有的
- Q:如何对类对象进行初始化?
- 使用创建构造函数
- Q:为什么一定要创建一个构造函数
- 即使不定义构造函数,程序也会自动定义一个默认构造函数,因为创建对象时总会调用构造函数
- 该默认构造函数,不接受任何参数,不执行任何操作
- 即使不定义构造函数,程序也会自动定义一个默认构造函数,因为创建对象时总会调用构造函数
- Q:什么是类构造函数?默认构造函数呢?
- 类的成员函数,专门用于构造新对象,初始化。
- 当没有提供显示初始值时,用默认构造函数来创建对象
- 没定义构造函数时,程序会自动添加默认构造函数
- 定义构造函数后,务必书写添加默认构造函数
- Q:构造函数的特点?
- 没有返回值,且无需将返回值声明为void类型。(构造函数没有生命类型)
- 函数名和类名同名,
- 参数名不能是数据成员名,即一般数据成员添加前缀m_或者后缀_
- Q:如何定义默认构造函数?
- 定义了构造函数时,只能采用如下方法的一种
- 方法1:把已有的构造函数的所有参数提供默认值
- 方法2:无参数
- 未定义构造函数时,无需定义默认构造函数
- 定义了构造函数时,只能采用如下方法的一种
//stock10.h #ifndef STOCK10_H_ #define STOCK!0_H_ #includeclass Stock{ private: public: Stock(const std::string & co, long n = 0, double pr = 0.0);//构造函数 //注意此处不是默认构造函数,因为co没有提供默认值 Stock();//无参数的默认构造函数 //Stock(const std::string & co = "Error",long n = 0, double pr = 0.1); //提供全部参数默认值的默认构造函数 ~Stock(); }; //stock10.cpp #include #include"stock10.h" Stock::Stock(){ cout<<"无参数默认构造函数"< - Q:如何调用构造函数?
- 隐式调用默认构造函数不加()
-
//显式调用 //构造函数 Stock food = Stock("word",1,0.0); //默认构造函数 Stock food = Stock(); //隐式调用 //构造函数 Stock food("word",2,2.01); //默认构造函数 Stock food; Stock *p_food = new Stock; Stock fc_food(); //fc_food()就是一个返回Stock类型的函数
-
- 隐式调用默认构造函数不加()
- Q:构造函数和默认构造函数的作用区别在哪?
- 构造函数可以根据用户提供的数据值来初始化类成员
- 默认构造函数只能通过程序定义好的值来初始化类成员
- Q:什么是析构函数
- 在程序创建好类对象后,会通过调用一个成员函数(析构函数)自动跟踪该对象,直到过期为止,过期时,通过析构函数完成清理对象的任务。
- Q:如何定义析构函数
- 无返回值
- 在函数名前加~
- ~Stock();
- 当构造函数中使用了new来给类对象成员赋值时,必须在析构函数中使用delete释放所开的内存。
- Q:什么时候调用析构函数?
- 当创建的是静态存储类对象时,程序结束时自动调用
- 当创建的是自动存储类对象时,代码块执行完自动调用
- 当创建的是动态存储类对象时,即通过new关键字创建的,需要用delete关键字来调用析构函数,删除对象。
- Q:对象可以相互赋值吗?如何实现?
- 可以,给类对象赋值时,会把一个对象的成员赋值给另一个
- 方法:
- 对已存在的对象,通过构造函数赋予新的值
- 构造函数会创建一个临时的对象,把该对象的内容赋值给已存在的对象,完成赋值,后自动调用析构函数删除该临时对象。
- 直接stock2 = stock1;
- 使用大括号{}提供参数,匹配对应的构造函数,初始化赋值
- 对已存在的对象,通过构造函数赋予新的值
//区分对象的初始化和赋值 Stock stock1 = Stock(); Stock stock2 = Stock("word",1,1.22); Stock stock3(); Stock stock3; stock2 = Stock("new",0,0.0); Stock stock4 = stock1; stock3 = stock4;- Q:如何使类成员函数无法修改类对象的数据?
- 在该函数名后追加const关键字,这种函数被成为const成员函数
- const成员函数无法修改被隐式访问数据的对象(被隐式访问的对象,简单理解成调用它的对象)
-
class Stock{ { private: public: void show() const; }
- Q:何时使用const成员函数?
- 只要成员函数设计时未修改对象,则都应声明称const成员函数
- Q:能否使用成员函数访问两个对象?
- 可以,通过成员函数可以隐式访问调用该函数的对象,显式访问传递给函数的对象
-
top = stock1.topval(stock2); //隐式访问stock1,显式访问stock2 top = stock2.topval(stock1); //同理
- Q:对象隐式访问和显示访问的区别??
- 在成员函数中,被隐式访问的对象无需通过.直接成员运算符来访问成员,而显式访问的对象,需要使用.成员运算符来访问成员
-
const Stock& Stock::topval(const Stock& s) const{ if(s.total_val > total_val){ return s; } else{ return *this; } }
- Q:上述中的this指针是什么?
- 所有类方法都会将this指针设置成调用它的对象地址
- 每个类方法包括构造函数和析构函数,都有一个this指针
- 上述的const成员函数无法修改被隐式访问的对象,实际是因为this被限定成了const
- Q:在上边的代码中,total_val是谁的数据成员?
- 是调用该topval()方法的对象的成员,total_val是this->total_val的简写而已。
- Q:如何声明一个对象数组?初始化呢?赋值呢?
- 和声明标准数据类型的数组用法一致
-
Stock array[10];//未显式初始化,则每个对象都会调用默认构造函数 double a = array[0].total_val; Stock arr0[2] = { Stock('a'); Stock('b'); Stock('c'); } //使用构造函数初始化数组成员对象,必须对每一个数组成员都初始化
- Q:能否在类声明中,直接定义一个常量?
- 不能,因为类声明不会创建对象,在创建对象前没有存储值的空间
- 但可以通过
- 枚举,但不提供枚举名(因为只是为了创建符号常量,不创建枚举类型变量)
- static关键字,static关键字声明的量有自己的静态存储空间,并不存储在类对象中。
使用类(类的设计技巧)
运算符重载
- Q:如何对运算符重载?
- 使用运算符函数,格式如下:
- operatorop(argument-list)
- op表示有效的运算符,比如* / % []等,[]是数组索引运算符,new也是运算符
- operator是关键字
- (argument-list)是参数列表
-
//mytime1.h #ifndef MYTIME1_H_ #define MYTIME1_H_ class Time{ private: int hours; int minutes; public: Time(); Time(int h, int m = 0); ~Time(); Time operator+(const Time &t) const; }; #endif //mytime1.cpp #include#include "mytime1.h" //运算符重载 Time operator+(const Time &t) const{ Time sum; sum.minutes = minutes + t.minutes; return sum; }
- 使用运算符函数,格式如下:
- Q:类方法中,运算符重载的使用和成员函数的调用有什么区别?
- 可以利用成员访问符.来调用运算符函数,也可以使用重载的运算符
- 被重载的运算符,在表示法中,运算符左侧的对象是调用对象,右侧的是参数传递的对象,即左侧为被隐式访问的对象,右侧是显式访问的对象
- 可以利用成员访问符.来调用运算符函数,也可以使用重载的运算符
total = coding.operator+(fixing); total = coding + fixing;- Q:能否将上述被重载的+运算符,用来实现多个对象的连加?为什么?
- 可以。因为+运算符是自左向右结合,每结合一次就相当于调用一次运算符函数
-
t4 = t1 + t2 + t3; t4 = t1.operator+(t2 + t3); t4 = t1.operator+(t2.operator+(t3));
友元函数
- Q:什么是友元函数?
- 可以访问类私有成员的非成员函数。
- 显然不能通过对象来调用
- Q:如何创建友元函数?
- 原型放在类声明中,且声明前添加关键字friend(即使在类声明中,但不是成员函数,不能成员运算符调用)
- 函数定义时不使用::限定符,且不添加关键字friend(不是成员函数无需限定符,但访问权限和成员函数一致)
- Q:重载运算符时,能否将运算符函数作为友元函数?和作为成员函数的区别是什么?
- 可以
- 运算符函数是成员函数时:一个操作数通过this指针隐式传递访问,另一个操作数作为参数显式传递访问
- 运算符函数是友元函数时:两个操作数都通过参数显示传递访问。
- Q:能否将一个函数,即作为友元函数,又作为成员函数?
- 不能,将产生二义性错误
类的自动转换(暂时不看)
- Q:程序是如何对内置类型进行转换的?
- 若两种类型兼容,则自动转换成接收变量的类型
- 不兼容不自动转换,如整数和指针
- Q:如何强制类型转换?
- int* p = (int*) 10; 这是把10强制转换成int*类型
- Q:为什么单参数构造函数可以通过给对象直接赋值的方法来初始化对象的某个参数?
- 通过隐式转换:Stonewt(double)创建一个临时对象,并将19.222作为初始化值,然后把临时对象复制给对象mycat,自动完成不需要强制转换。且只有一个参数的构造函数才能作为转换函数
-
//stonewt.h #ifndef STONEWT_H_ #define STONEWT_H_ class Stonewt{ private: double stone; public: Stonewt(double lbs); Stonewt(): ~Stonewt(); }; #endif //stonewt.cpp #include#include "stonewt.h" Stonewt::Swtonwt(double lbs){ stone = lbs; } //main.cpp #include #include "stonewt.h" int main(){ Stonewt mycat; mycat = 19.222; }
-
- 通过隐式转换:Stonewt(double)创建一个临时对象,并将19.222作为初始化值,然后把临时对象复制给对象mycat,自动完成不需要强制转换。且只有一个参数的构造函数才能作为转换函数
- Q:单参数如何关闭用作自动类型转换函数的特性?
- 使用explicit(不隐晦的)关键字关闭该特性,关闭这种隐式转换后,仍然可以使用显示强制类型转换。
-
//stonewt.h #ifndef STONEWT_H_ #define STONEWT_H_ class Stonewt{ private: double stone; public: explicit Stonewt(double lbs); Stonewt(): ~Stonewt(); }; #endif //stonewt.cpp #include#include "stonewt.h" Stonewt::Swtonwt(double lbs){ stone = lbs; } //main.cpp #include #include "stonewt.h" int main(){ Stonewt mycat; mycat = 19.222; //ERROR mycat = Stonewt(19.2); //Right mycat = (Stonewt) 192.2; //Right }
- Q:使用构造函数进行类型转换的局限是什么?
- 只能从某种类型转换到 该构造函数所属类的类型,反之必须使用另一个特殊的函数:转换函数
- Q:什么是转换函数?
- 自定义的强制类型转换,可以像使用强制类型转换一样使用该函数进行类型强制转换
- Q:如何声明定义转换函数?如何实现类类型转换成指定类型的?
- 格式:
- operator typeName()
- 通过typeName指明了要转换成的类型,比如operator int() 就是将类类型转换成int类型,通过对象调用该函数,直接访问成员,将其转换成int类型,无需参数。
- 转换函数必须满足:
- 必须是类方法
- 不能指定返回类型
- 不能有参数
-
//stonewt1.h #ifndef STONEWT1_H_ #define STONEWT1_H_ class Stonewt{ private: enum {Lbs_per_stn = 14}; int stone; double pds_left; double pounds; public: Stonewt(double lbs); Stonewt(int stn, double lbs); Stonewt(); ~Stonewt(); //转换函数 operator int() const; operator double() const; }; #endif //stonewt1.cpp Stonewt::operator int() cosnt{ return int (pounds + 0.5); //将成员pounds转换成int类型 } Stonewt::operator double() const{ return pounds; //将 } //main.cpp #include#include "stonewt1.h" int main()
- 格式:
类和动态内存分配
- Q:静态类成员有什么特点?
- static关键字声明
- 无论创建了多少类对象,始终创建一个静态类变量副本,多个对象共享一个静态成员。(可以把静态成员和方法看成家中的电话,多人共用)
- static 不能在类声明和其.h文件中初始化,因为类声明只描述如何创建内存,但不创建内存空间。(const整数类型或者枚举型可以初始化,上文提到过)
- 可以在方法文件.cpp中,单独初始化,但需要用作用域运算符::指明所属类,且初始化时无需static关键字
- Q:分析下方程序,为什么构造函数调用次数最终是-2次?
- Q:用一个类对象初始化另一个类对象时,会有什么后果?
- 可以实现对象的复制,但编译器会自动生成一个构造函数(复制构造函数),创建一个对象副本。该复制构造函数与程序员定义好的构造函数无关。
- Q:如何使用复制构造函数?
- 格式Class_name(const Class_name &);
- 举例MyStock(const Mystock &);
- Q:复制构造函数什么时候被调用?
- 只要产生了对象副本,都将调用复制构造函数
- 新建一个对象并将其初始化同类对象时,复制构造函数被调用
- 如:将新对象显示初始化为已有对象
- 如:对对象使用=运算符,来赋值时
- 如:对象按值参数传递,函数直接返回对象,都将产生对象副本,都将调用复制构造函数
-
//假设StringBad一个类 StringBad motto = StringBad("test",1.2); //下面四种声明都将调用复制构造函数StringBad(const StringBad&); StringBad ditto(motto); StringBad metoo = motto; StringBad also = StringBad(motto); StringBad * pStringBad = new StringBad(motto);
- Q:比较使用构造函数,默认构造函数,复制构造函数的不同
-
int main(){ Stock food = Stock("word",1,0.0); //显式,构函 Stock food = Stock(); //显式,默认构函 Stock food("word",2,2.01); //隐式,构函 Stock food; //隐式,默认构函 Stock *p_food = new Stock; //隐式,默认构函 Stock fc_food(); //函数 Stock milk(food); //复制构函 Stock water = milk; //复制构函 Stock air = Stock(fodd); //复制构函 Stock * pStock = new Stock(food); //复制构函 return 0; }
-
类声明
//test1.h 注意这里是头文件 class stock { private: std::string company; long shares; double share_val; double total_val; void set_tot(){cout<<"fuck"<通常C++程序员,把接口(类定义)放在头文件中,如上程序,而类方法的定义则在包含上述头文件的源代码文件中,那类定义和类方法定义是如何具体关联在一起的呢??
- 接口/封装
类的思想,把公有接口和实现细节分开,把实现细节放在一起并将他们和抽象分开,即术语封装.
上述的数据隐藏也是一种封装,把实现的细节隐藏在私有部分中也是封装.
类的公有接口表示了设计的抽象组件,如上述的public中的很多个void函数就是对数据操作的方法函数,就是从具体的数据中抽象出来的一种数据操作方法,这些个方法函数声明被放在了.h头文件中, 而这种方法的具体算法,即函数体的结构实现却是在含有.h头文件的源代码文件中实现的.这也是一种封装,即把实现细节和抽象分开
类和结构有什么差别吗?
是的,就目前来看,好像没有什么区别,只不过class是具有public和private的struct,
class和struct最大的、唯一的区别在于, class默认访问的是private而struct默认访问的是public.是的, 结构在C++中进行了扩展,它也可以有class的一些特性了比如public和private
C++通常把类来描述数据和相关操作,而结构仅用来纯粹的表示数据对象
- 如何实现类的成员函数呢?
类的成员函数/方法函数/方法,和普通的函数一样有函数声明,有返回值,有参数,有函数体,
区别:
1.函数声明被放在了头文件,而函数具体定义被放在含有头文件的源代码中
2.定义函数成员时,需要用作用域解析符 :: 来标出函数所属的类
当然,类方法可以访问类的private成员(这是我们上边说好的)
类的实现一般包含了3个文件:头文件创建类,定义文件实现类函数,主程序文件调用引用类。
//实现类的成员函数,就是在包含了头文件的源代码中去定义函数体 double stock::acquire() { "在类方法函数的定义中,你可以随便调用任何一个成员变量" } float stock::buy() { ... } double stock::spell(int a, int b, double sum) { ... } long stock::output(std::string str, name, int age) { ... }- 成员的访问,公有还是私有
OOP的主要目标之一就是对于数据的隐藏,所以组成类接口的成员函数在公有部分,而数据项往往在private部分
为什么成员函数不能放在private部分?因为如果函数在private上就无法通过类对象直接调用成员函数了
如果我非要在类声明中定义一个函数,即类方法的函数体在类声明中了,而且在private中,会怎样? 只要是在类声明中定义的函数,都是内联函数即,自动转成inline函数,在类声明中的函数有个特点:短小精悍
//类声明,即头文件中 //举例说明类声明 //test1.h 注意这里是头文件 class stock { private: std::string company; long shares; double share_val; double total_val; void set_tot(){cout<<"fuck"<扩展思路,我也可以在类声明下边定义一个内联函数,只需要指定对应的类就行了,如下
//举例说明类声明 //test1.h 注意这里是头文件 class stock { ... }; inline void stock::set_tot() { cout<<"fuck"<类对象初始化-构造函数
由于类的数据项是隐藏的,所以无法像int类型或者结构那样可以定义时初始化,毕竟数据访问是私有的,不能够直接访问
- 类构造函数就是为了初始化而产生的,C++提供了一个特殊的成员函数,即类构造函数,专门用于构造新对象,作用就是把具体的值赋给数据成员
-
C++对这种特殊的成员函数提供了 名称和适用语法, 我们需要提供方法定义
-
这类函数的名称和类的名称相同,即stock类中有个成员函数是stock()
-
这种特殊的成员函数即构造函数,是没有返回值的
-
-
-
创建这种特殊函数即构造函数,这种函数的参数名不能和类的数据成员名相同,因此,应对类的数据成员加前缀m_
构造函数的声明
//创建一个构造函数,需要两部分,即声明和定义 //声明 //class.h stock(const string & co, long n =0, double pr =0.0); //注意,此处的co并没有给出默认值 //定义 //project.cpp stock::stock(const string & co, long n, double pr) { "在类方法中,你可以随便调用任何一个成员变量" company =co; if (n < 0) { cout<<"fuck"<构造函数的调用
构造函数如何使用呢?怎么避免没有使用类而只是在使用构造函数呢??
- 显示调用构造函数
stock food = stock("world", 250, 12.2); //第一个stock是类,创建了对象food,第二个stock是类构造函数- 隐式调用构造函数
stcok food("world",250,122.2); //这里的stock是类,创建了对象food- 结合new来动态创建且初始化
stock *food_ptr = new stock("world",250,122.2); //第一个stock是类,创建了对象指针,第二个stock是类构造函数注意! 普通的类可以通过对象用.运算符来访问类函数,但是无法访问类构造函数,即构造函数用来创建对象,但不同通过对象来调用
~析构函数
构造函数用来初始化对象,而析构函数用来清理对象,构造函数可通过new来分配内存,,析构函数则用delete完成内存释放,如果没有用new那么析构函数则没有什么任务可做了.
析构函数很特殊,即在类的名字前加~就是它的名字了,如stock类的析构函数是~stock()
和构造函数一样,析构函数没有返回值和声明类型语句,不同的是析构函数也没有参数
析构函数的声明——如何使用析构函数
析构函数若不担任任何重要工作,可以将它写成不执行任何操作的函数
stock::~stock() {}析构函数的调用——什么时候用析构函数
编译器决定,通常不会显式调用析构函数
同理,如果我们没有提供析构函数,编译器将自动声明一个析构函数(注意是声明),然后发现有删除对象的代码后,则自动定义一个默认的析构函数(这里才是定义)
构造函数和析构函数都是把声明放在头文件中的,而具体的函数定义是在源代码中的
//stock.h头文件 class stock { private: std::string company; long share; double share_val; void set_tot(){cout<<"fuck"<//stock.cpp源代码 #include#include "stock.h" stock::stock() { std::cout<<"这里是默认构造函数"< 可以利用大括号{}进行初始化吗??
stock test1 = {"test1", 100, 2.2}; stock test2 {"test2",200.3.4}; stock test{}前两个直接调用stock::stock(const std::stirng &co, long n=0, double pr=0.0)
最后一个直接调用stock::stock()
修改类的数据成员
this指针可以帮到你
什么意思呢?就是你的private的数据是只能通过public成员函数来访问的,但无法修改,如何去修改这个数据呢?
类继承
-
C++提供了比修改代码更好的方法来扩展和修改类,那就是类的继承
-
可以从已有的类派生出新的类,派生类继承了原有的特征,包括全部方法函数
-
原有的类叫基类, 派生的类叫派生类,或者说继承的类叫做派生类
-
-
基类
-
利用符号 : 来指出RP类的基类是TTP类,加上public表示这是个公有基类,RP作为派生类又叫做公有派生类
-
派生类的对象会包含基类对象
-
公有派生类会拥有基类的全部公有成员和私有部分,但基类的私有部分,派生类并不是可以随意访问
-
派生类继承了基类的实现, 即基类的数据成员
-
派生类继承了基类的方法,即基类的接口
-
class TTP { ... } class RP: public TTP { ... }派生类
知道了基类和派生类的关系,那我们在派生类的定义中到底需要加什么东西呢???
-
属于派生类自己的构造函数
-
追加非基类即额外的数据成员和成员函数
派生类构造函数
派生类不能直接访问基类的私有成员,必须通过基类的方法(函数)进行访问。
Q:我们的构造函数是用来对类成员进行初始化的, 无法访问这些数据成员,我们就无法通过派生类的构造函数来进行数据的初始化了,
A:需要你的派生类构造函数必须使用基类的构造函数
基类对象应该在程序进入派生类构造函数之前创建, 要创建派生类对象,你就必须要先创建基类对象
注意这里并不是说要创建两个对象, 而是C++利用了列表初始化语法来完成了这个操作,怎么完成的?看下边
RatedPlayer::RatedPlayer(unsigned int r , const string & fn, const strng & ln, bool ht):TableTennisPlayer(fn, ln, ht) { //派生类 :: 派生类构造函数(参数) : 基类构造函数(基类参数) ... } //基类成员初始化列表 :TableTennisPlayer(fn, ln, ht), 这是调用了基类的构造函数 //这里可能晦涩难懂, 举个例子 RatedPlayer xjh(1123, "M", "duck", true);首先RatedPlayer构造函数, 把xjh对象的参数都给了RatePlayer的构造函数的形参r, fn, in, ht这四个,然后这个形参又作为实参,传递给了TableTennisPlayer的形参fn in ht,于是创建好了一个基类对象,并且你的xjh的参数都存储在了基类对象中,然后, 程序进入了RatedPlayer构造函数的函数体, 执行函数体的语句
创建派生类对象——>派生类构造函数——>对象参数给构造函数的形参——>构造函数形参作为实参给基类构造函数——>基类构造函数创建基类对象——>派生类对象的初始化参数全部存储在该基类对象中——>完成上述创建派生类对象必须创建基类对象的要求
必须首先创建基类对象, 但是像上述代码中, 你不写:TableTennisPlayer(fn, in, ht)这个基类构造函数,程序会自动调用程序
使用派生类
使用派生类,你必须要把基类和派生类的声明放在一起,当然也可以通过#include方法放在不同的.h头文件中, 也可以放在一个头文件中
类的接口定义可以单独放在一个.cpp文件中,只需要你的源代码和这个.cpp文件都包含了上述头文件,就行. 而你的头文件,无需包含源代码和.cpp文件
//tabletenn1.h 头文件 using namespace std; using namespace string; class TableTennisPlayer { ... } class RatedPlayer : public TableTennisPlayer { ... } //tableten1.cpp 接口源文件 #include "tabletenn1.h" TableTennisPlayer::TableTennisPlayer () {} //这里都是两个类的函数结构定义程序 //main.cpp 主程序源文件 #include "tabletenn1.h" int main() { //直接使用类 TableTennisPlayer xjh1(...); RatedPlayer xjh2(...); }使用与设计类
学习了定义和简单的使用类,了解了两个成员函数析构函数和构造函数,这些都是类的通用原理,接下来开始学习类的设计技术
创建类对象
注意! 每个创建的对象,都有自己的内存块,这里可以联想普通变量,类是int类型,而对象就是int类型的数据对象,比如int name=0;
#include#include "test1.h" int main(){ stock xjh;//创建类对象 xjh.acquire(); xjh.buy(); xjh.spell(); xjh.output(); // 对于指针 stock * ptr = new stock; ptr->buy(); ptr->spell(); } 本章对C++编程的思想有明显的提升,特别是文末的代码,应着重学习。
单独编译
- Q:什么是单独编译?
- C++鼓励将组件函数放在独立的文件中,通过单独编译这些文件,将他们连接成可执行的程序
- 如果修改了其中的一个文件,那么可以通过重新编译该文件,然后再与其他文件链接即可。
- Q:如何避免把程序放在多个文件中引出的问题?
- C++提供了#include来处理这种问题,将一些声明放在头文件中,然后在每个源代码中包含这个头文件即可
- 需要修改时,只修改头文件
- 函数原型也可以放入头文件
- Q:高效组织程序结构的方法是?
- 把程序分成三个部分
- -1-头文件:包含了结构声明,和使用结构的原型(结构声明不创建变量,可在头文件中)
- 函数原型,内联函数
- 结构、类、模板声明
- 使用#define或const定义的符号常量
- -2-源代码:与结构相关的函数定义代码
- -3-源代码:包含调用结构相关函数的代码(一般是main主程序)
- -1-头文件:包含了结构声明,和使用结构的原型(结构声明不创建变量,可在头文件中)
- 把程序分成三个部分
- Q:程序预处理时""和<>的区别?
- 如果文件用<>来包含,那么编译器将在存储标准头文件的主机系统的文件系统中查找该文件。
- 如果是""包含的,那么编译器首先检查当前工作目录或者源代码目录,如果没有则在标准位置中查找
- 所以,当包含自己的头文件到程序中时,应使用""
- Q:如何避免同一文件多次包含一个头文件?
- 在同一个文件中只能将包含一次同一个头文件
- 在头文件中使用预处理器编译指令#ifndef来避免,
- 即当前没有使用预处理器编译指令#define定义名称COORDIN_H_时,才处理#ifndef和#endif之间的语句
-
//coordin.h #ifndef COORDIN_H_ #define COORDIN_H_ struct polar{ double distance; double angle; }; void show_polar(polar& ); #endif
存储持续性、作用域和链接性
用{}包含的语句,视为在同一个代码块中,一个代码中的变量的存储特性是自动的,即随着{}的结束而释放内存。
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由os回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区)(static)—全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后有系统释放。
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放。
5、程序代码区—存放函数体的二进制代码。
- Q:常用的三种存储数据的方法
- 自动存储持续性(自动变量)
- 函数体或代码块中的变量,执行相应代码块时创建,结束释放
- 存储位置称为栈(LIFO)
- 静态存储持续性(静态持续变量)
- 程序运行整个过程都存在
- 函数定义外的变量
- 使用关键字static定义的变量
- 程序运行整个过程都存在
- 动态存储持续性(动态变量)
- 用new运算符分配,用delete运算符释放或程序结束释放
- 内存位置称为堆heap
- 自动存储持续性(自动变量)
- Q:什么是作用域?
- 作用域描述了名称在文件的多大范围内可见
- 局部作用域,只在代码块{}中可见
- 自动变量的作用域为局部
- 全局作用域,即文件作用域在定义位置到文件结尾都可用
- Q:什么是链接性
- 链接性描述了名称如何在不同文件内共享
- 链接性为外部,则在文件间共享
- 链接性为内部,则只能在该文件中的函数共享
- 无链接性,则只在当前代码块内可访问。
- 自动变量没有链接性
- 链接性描述了名称如何在不同文件内共享
- Q:变量的作用域有哪些?
- 局部(局部变量)
- 函数体或代码块中的变量,作用域为代码块
- 自动变量,作用域为代码块中
- 位于函数原型作用域即()内部的参数变量
- 类声明中的成员变量,作用域为整个类
- 名称空间中声明的变量,作用域是整个名称空间
- 全局(全局变量)
- 局部(局部变量)
- Q:函数的作用域
- 整个类、名称空间,不可能是局部因为不可能在{}代码块中定义函数。
- Q:栈是什么
- 程序对自动变量进行管理时,会留出一段内存空间,将其视为栈,即后入先出。
- 程序使用两个指针管理栈,一个指向栈顶,一个指向栈底。
- Q:关键字register什么意思
- C++中register只表示这个变量是自动变量。
- Q:声明三种不同链接性的静态持续变量
int global = 100; //静态持续变量,外部链接性,全局作用域 static int one_file = 50; //静态持续变量,内部链接性,全剧作用域 int main(){ } void function1(int n){ static int count = 0; //静态变量,无链接性,局部作用域 int llama = 0; //自动变量,无链接性,局部作用域 }- Q:如何快速判断变量的存储类型、作用域、链接性
- 判断存储持续性
- {}内部是自动变量
- static声明的是静态变量,不在{}的也是静态变量
- new声明的是动态变量
- 判断作用域:
- {}内的都是局部
- {}外的是全局
- 判断链接性:
- {}中的没有链接性
- {}外:
- 加了static的是内部链接性
- 加了const的也是内部
- 没有static也没有const的是外部链接性
- 判断存储持续性
- 如何创建一个外部链接的常量?
-
extern const int states = 50;
-
- Q:什么是单定义规则? 如何实现?
- 变量只能定义一次
- 提供两种变量声明来实现:
- 定义声明,简称定义,分配内存空间
- 引用声明,简称声明,不分配内存空间,使用extern关键字且不初始化,否则是定义声明
- Q:引用声明和定义外部链接性的常量的区别?
- 引用声明是由于单定义规则,其他文件使用时必须用关键字extern且不初始化。
- 当常量想要变成外部链接性时,需要用extern const来定义声明,允许初始化,但只有一个文件可以对它初始化,因为他是常量。
- Q:如何在多个文件中使用同一个变量?
- 根据单定义规则,只能在一个文件中定义该变量,其他文件想使用,只能通过引用声明来使用。
- step1在文件中定义声明一个链接性是外部的变量
- step2在其他文件中引用声明该变量
- step3这几个文件需要一起编译
//file1.cpp #includedouble warming = 0.32321; int main(){ } //file2.cpp #include extern double warming; int main(){ } - Q:函数的存储持续性是什么?
- 所有函数的存储持续性都是静态的,因为不允许函数在{}代码块中定义函数。
- Q:默认情况下,函数的链接性是?
- 外部链接性
- Q:如何修改函数的链接性?
- 关键字extern指出函数是另一个文件定义的(类似变量的单定义规则)
- 关键字static将函数设置成内部链接性,需在原型和定义中均用static关键字
- Q:动态内存的释放由谁控制?有什么意义?
- new和delete
- 可以在一个函数定义中用new来创建,在另一个函数定义中用delete释放
- Q:如何使用new运算符初始化动态变量
-
//对于内置标量,用new 类型名(初始值) int* pi = new int(6); double* pd = new double(12.1); //对于结构或数组,用new 结构名/数组名 {初始值} struct where {double x, double y, double z}; where* one = new where{1.2, 1.2, 1.1}; int* ar = new int[4] {1,2,3,4};
-
- Q:什么是定位new运算符?
- new往往会自动在堆中寻找合适的内存空间,也可以在指定的内存块中寻找合适的内存空间
- Q:如何使用定位new运算符
- step1包含new头文件
- step2使用new(变量A) 变量B;即在变量A的内存块中,寻找适合B的内存块来创建变量B
#includestruct chaff{ char dross[20]; int slag; }; char buffer1[50]; char buffer2[100]; int main(){ chaff *p1,*p2; int *p3,*p4; p1 = new chaff; p2 = new int[20]; p3 = new(buffer1) chaff; p4 = new(buffer2) int[20]; return 0; } 名称空间
- Q:什么是名称空间?
- 名称可以是变量、函数、结构、类和相关对象的成员,项目越大名称越多,同名的可以能性越高,冲突的概率也变大,因此C++提供了名称空间工具,用来控制名称的作用域。
- Q:什么是声明区域?
- 即可以在其中进行声明的区域
- 如函数外的区域,可以声明全局变量,该变量的声明区域是所在文件全部区域。
- 再如函数内的区域,可以声明局部变量,该变量的所属声明区域是所在代码块区域。
- 即可以在其中进行声明的区域
- Q:C++是如何管理这些声明区域的?
- -1- C++对全局变量和局部变量的规则定义一种名称空间层次
- -2- 每个层次都是一块声明区域,每个声明区域都可以声明名称,但是区域内的名称独立于其他区域的名称。
- Q:如何创建名称空间
- 使用关键字namespace
- 名称空间可以是全局的,也可以在另一个名称空间中,但不能在{}代码块中
- Q:名称空间一般在什么文件中,它可以包含什么?
- 一般在头文件中
- 包含内容参照头文件
- Q:如何向已有的名称空间Jill中添加名称?
-
namespace Jill { char* goose(const char*); }
-
- Q:如何访问名称空间中的内容?
- 作用域解析符::,来限定名称所属的名称空间
-
Jill::goose();
- Q:什么是未限定,那限定呢?
- 未被装饰的名称,叫做未限定的名称,如goose;
- 包含名称空间的名称为限定的名称,如Jill::goose;
- Q:using声明和using编译指令的作用
- using声明:使得特定的标注符可用
- using Jill::fetch;
- using编译指令使得整个名称空间可用,using编译指令由using namespace 空间名组成
- using namespace Jill;
- using声明:使得特定的标注符可用
- Q:using声明和using编译指令的区别?
- using声明更安全
- Q:如何规范使用名称空间?
- -1- 尽可能的使用在名称空间中声明的变量,而不用外部全局变量或静态全局变量
- -2- 如果开发了一个函数库或者类库,应将其放在一个名称空间中
- -3- 不要在头文件中使用using编译指令,
- -4- 导入名称时,尽可能不使用using编译指令,而选择作用域解析符 或 using声明
- -5- 使用using声明时,尽可能将其放在局部声明区域内,而不是全局。
- Q:使用名称空间书写一个程序
首先给出头文件
//namesp.h #includenamespace pers{ //设置一块名为pers的声明区域 struct Person{ std::string fname; std::string lname; }; void getPerson(Person&); void showPerson(const Person&); } namespace debts{ //设置一块名为debts的声明区域 using namespace pers; //将pers名称空间的名称在当前声明区域内有效 struct Debt{ Person name; double amount; }; void getDebt(Debt&); void showDebt(const Debt); double sumDebts(const debt ar[], int n); } 其次给出相关函数定义的源代码
//namesp.cpp #include#include "namesp.h" namespace pers{ using std::cout; using std::cin; void getPerson(Person &rp){ cout<<"Enter first name:"; cin>>rp.fname; cout<<"Enter last name:"; cin>>rp.lname; } void showPerson(const Person& rp){ std::cout< 最后给出调用的main主程序
#include#include "namesp.h" int main(){ using debts::Debt; //将头文件namesp.h中的第2个名称空间debts的Debt在当前声明区域有效 using debts::showDebt; Debt golf = { {"Benny","Goatsniff"}, 120.0 }; showDebt(golf); return 0; } 虚函数
多态是面向对象的三大特征之一,其它两大特征分别
是 封装 和 继承
所谓 多态,简单来说,就是当发出一条命令时,不同的对象
接收到同样的命令后所做出的动作是不同的
静态多态和动态多态
静态多态
静态多态,也叫 早绑定
看如下实例:
class Rect { public: int calcArea(int width); int calcite(int width, int height); };定义一个矩形类:Rect,其中有两个同名成员函数:calcArea(),显然
二者互为重载(名字相同,参数可辨)
当实例化一个 Rect 的对象后,就可以通过对象分别调用这两个函数,
计算机在编译时,就会自动调用对应的函数
int main() { Rect rect; rect.calcArea(10); rect.calcArea(10,20); return 0; }即程序运行之前,在编译阶段就已经确定下来到底要使用哪个函数,
可见:很早就已经将函数编译进去了,称这种情况为早绑定或静态多态
动态多态
动态多态,也叫晚绑定
看如下实例:
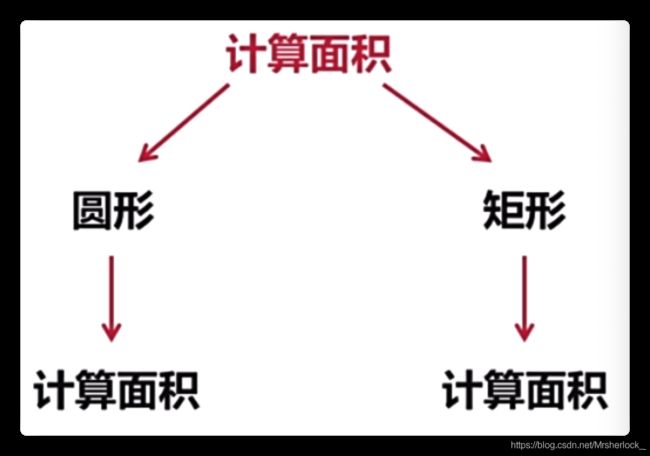
当前要计算面积,于是分别给圆形和矩形下达计算面积的指令,
作为圆形来说,它有自己计算面积的方法,作为矩形来说,它
也有自己计算面积的方法
显然,两种计算面积的方法肯定不同,即对不同对象下达相同
指令,却做着不同的操作,称之为晚绑定或动态多态
动态多态是有前提的,它必须以封装和继承为基础。
在封装中,将所有数据封装到类中,在继承中,又将封装着的各个类使其形成
继承关系
只有以封装和继承为基础,才能谈到动态多态,动态多态
最起码有两个类,一个子类,一个父类,只有使用三个类
时,动态多态才表现的更为明显
看如下实例:
定义一个形状类:Shape,它有一个计算面积的成员函数:calcArea()
再定义一个圆类:Circle,它公有继承了形状类 Shape,并有自己的构造函数和计算面积的函数
再定义一个矩形类:Rect,它公有继承了形状类 Shape,并有自己的构造函数和计算面积的函数
class Shape { public: double calcArea() { cout<<"calcArea"<在使用时:
int main() { Shape* s1 = new Circle(4.0); Shape* s2 = new Rect(3.0,5.0); s1->calcArea(); s2->calcArea(); return 0; } >>calcArea >>calcArea可以使用父类指针指向子类对象,但结果却不尽如人意,因为调用到
的都是父类的计算面积的函数,即会打印出两行calcArea
如果想要实现动态多态,就必须使用 虚函数
用virtual 修饰成员函数,使其成为 虚函数
如下:在父类中,把想要实现多态的成员函数前加上virtual 关键字,使其成为虚函数,
在定义子类Circle 时,给计算面积的同名函数也加上virtual 关键字,不加也可以,会自动添加
class Shape { public: virtual double calcArea() { cout<<"calcArea"<使用父类指针指向子类对象,调用函数时,调用的就是对应子类的计算面积函数
即: 调用谁的函数,看谁初始化的
Shape* s1 = new Cricle(4.0); //后续调用virtual时,将调用Circle类的如下:
int main() { Shape* s1 = new Circle(4.0); Shape* s2 = new Rect(3.0,5.0); s1->calcArea(); s2->calcArea(); return 0; } >> 50.24 >> 15.0final和override
final
final修饰虚函数
C++ 中增加了 final 关键字来限制某个类不能被继承,或者某个虚函数不能被重写
如果使用 final 修饰函数,只能修饰虚函数,并且要把final关键字放到类或者函数的后面,这样就能阻止子类重写父类的这个函数了
class Base { public: virtual void test() { cout << "Base class..."; } }; class Child : public Base { public: void test() final { cout << "Child class..."; } }; class GrandChild : public Child { public: // 语法错误, 不允许重写 void test() { cout << "GrandChild class..."; } };final修饰类
使用 final 关键字修饰过的类是不允许被继承的,也就是说这个类不能有派生类。
应在类的名字后添加final关键字
class Base { public: virtual void test() { cout << "Base class..."; } }; class Child final: public Base { public: void test() { cout << "Child class..."; } }; // error, 语法错误 class GrandChild : public Child { public: };override
overide修饰虚函数
override 关键字确保在派生类中声明的重写函数与基类的虚函数有相同的签名,同时也明确表明将会重写基类的虚函数,这样就可以保证重写的虚函数的正确性,也提高了代码的可读性,和 final 一样这个关键字要写到方法的后面。使用方法如下:
class Base { public: virtual void test() { cout << "Base class..."; } }; class Child : public Base { public: void test() override { cout << "Child class..."; } }; class GrandChild : public Child { public: void test() override { cout << "Child class..."; } };函数签名 :
C++中的函数签名(function signature):包含了一个函数的信息,包括函数名、参数类型、参数个数、顺序以及它所在的类和命名空间。
普通函数签名并不包含函数返回值部分,如果两个函数仅仅只有函数返回值不同,那么系统是无法区分这两个函数的,此时编译器会提示语法错误。
函数签名用于识别不同的函数,函数的名字只是函数签名的一部分。在编译器及链接器处理符号时,使用某种名称修饰的方法,使得每个函数签名对应一个修饰后名称(decorated name)。编译器在将C++源代码编译成目标文件时,会将函数和变量的名字进行修饰,形成符号名,也就是说,C++的源代码编译后的目标文件中所使用的符号名是相应的函数和变量的修饰后名称。
C++编译器和链接器都使用符号来识别和处理函数和变量,所以对于不同函数签名的函数,即使函数名相同,编译器和链接器都认为它们是不同的函数。
不同的编译器厂商的名称修饰方法可能不同,所以不同的编译器对于同一个函数签名可能对应不同的修饰后名称。
Lambda表达式
lambda 表达式定义了一个匿名函数,并且可以捕获一定范围内的变量。lambda 表达式的语法形式简单归纳如下:
[capture](params) opt -> ret {body;};其中 capture 是捕获列表,params 是参数列表,opt 是函数选项,ret 是返回值类型,body 是函数体。
分别阐述上述名称:
capture 捕获列表 []: 捕获一定范围内的变量,
默认状态下 lambda 表达式无法修改通过按值方式捕获外部变量,如果希望修改这些外部变量,需要通过引用的方式进行捕获。
[] - 不捕捉任何变量
[&] - 捕获外部作用域中所有变量,并作为引用在函数体内使用 (按引用捕获)
[=] - 捕获外部作用域中所有变量,并作为副本在函数体内使用 (按值捕获), 拷贝的副本在匿名函数体内部是只读的
[=, &foo] - 按值捕获外部作用域中所有变量,并按照引用捕获外部变量 foo
[bar] - 按值捕获 bar 变量,同时不捕获其他变量
[&bar] - 按引用捕获 bar 变量,同时不捕获其他变量
[this] - 捕获当前类中的 this 指针,让 lambda 表达式拥有和当前类成员函数同样的访问权限, 如果已经使用了 & 或者 =, 默认添加params参数列表 (): 和普通函数的参数列表一样,如果没有参数参数列表可以省略不写。
opt 选项, 不需要可以省略
- mutable: 可以修改按值传递进来的拷贝(注意是能修改拷贝,而不是值本身)
- exception: 指定函数抛出的异常,如抛出整数类型的异常,可以使用 throw ();
auto f = [](){return 1;} // 没有参数, 参数列表为空 auto f = []{return 1;} // 没有参数, 参数列表省略不写 int a = 0; auto f1 = [=] {return a++; }; // error, 按值捕获外部变量, a是只读的 auto f2 = [=]()mutable {return a++; }; // ok
ret返回值类型:在 C++11 中,lambda 表达式的返回值是通过返回值后置语法来定义的。body函数体:函数的实现,这部分不能省略,但函数体可以为空。
补充:
1⃣️C++11 中允许省略 lambda 表达式的返回值,
一般情况下,不指定 lambda 表达式的返回值,编译器会根据 return 语句自动推导返回值的类型,但需要注意的是 labmda表达式不能通过列表初始化自动推导出返回值类型。
// ok,可以自动推导出返回值类型 auto f = [](int i) { return i; } // error,不能推导出返回值类型 auto f1 = []() { return {1, 2}; // 基于列表初始化推导返回值,错误 }2⃣️为什么通过值拷贝的方式捕获的外部变量是只读的:
lambda表达式的类型在C++11中会被看做是一个带operator()的类,即仿函数。
按照C++标准,lambda表达式的operator()默认是const的,一个const成员函数是无法修改成员变量值的。
mutable 选项的作用就在于取消 operator () 的 const 属性。3⃣️对于没有捕获任何变量的 lambda 表达式,还可以转换成一个普通的函数指针
using func_ptr = int(*)(int); // 没有捕获任何外部变量的匿名函数 func_ptr f = [](int a) { return a; }; // 函数调用 f(1314); - Q:什么是引用?
-