强大的向量数据库:Milvus

在推荐系统中,向量的最邻近检索是极为关键的一步,特别是在召回流程中。一般常用的如Annoy、faiss都可以满足大部分的需求,今天再来介绍另外一个:Milvus
Milvus
Milvus不同于Annoy、faiss这类型的向量检索工具,它更是一款开源向量数据库,赋能 AI 应用和向量相似度搜索。
涉及的术语
- Filed:类似表字段,可以是结构化数据,当然还可以是向量;
- Entity:一组Filed,类似表的一条数据;
- Collection:一组Entity,类似于表;
亮点
- Milvus不单单是向量检索工具,而是向量数据库,能对不同业务的向量隔离,分开存储;
- 提供可视化管理工具;
- 支持带过滤条件的向量混合检索。
前言提示
本文介绍的是官方最新版本2.0.0rc4:https://milvus.io/cn/docs/v2.0.0/home,因为新增了许多强大的功能,所以尝鲜实验了一把。但2.x还在迭代中,并不是稳定版本。实验后,也发现存在一些问题,如有时无法查询,而1.x则不存在这些问题。
所以,大家实际使用最好是用最新的稳定版本1.1.1,不过缺少一些功能。https://milvus.io/cn/docs/v1.1.1/home
具官网表明,2.x的稳定版本也即将上线,到时再更新2.X版本投入生产环境。
| Milvus 2.0 | Milvus 1.x | |
|---|---|---|
| 架构 | 云原生 | 共享存储 |
| 可扩展性 | 500+ 个节点 | 1 - 32 个读节点,1 个写节点 |
| 持久性 | 对象存储 (OSS)、分布式文件系统 (DFS) | 本地磁盘、网络文件系统 (NFS) |
| 可用性 | 99.9% | 99% |
| 数据一致性 | 多种一致性StrongBounded StalenessSessionConsistent prefix | 最终一致 |
| 数据类型支持 | 向量数据标量数据字符串与文本 (开发中) | 向量数据 |
| 基本操作 | 插入数据删除数据 (开发中)、数据查询相似最邻近(ANN)、搜索基于半径的最近邻算法(RNN) (开发中) | 插入数据删除数据相似最邻近(ANN)搜索 |
| 高级功能 | 标量字段过滤Time Travel多云/地域部署数据管理工具 | MishardsMilvus DM 数据迁移工具 |
| 索引类型 | Faiss、Annoy、Hnswlib、RNSG、ScaNN (开发中)、On-disk index (开发中) | Faiss、Annoy、Hnswlib、RNSG |
| SDK | PythonGo (开发中)Java (开发中)RESTful (开发中)C++ (开发中) | Python、Java、Go、RESTful、C++ |
| 当前状态 | 预览版本。预计 2021 年 8 月发布稳定版本。 | 长期支持(LTS)版本 |
Docker安装
安装milvus之前:docker安装
如果安装了docker,但没有docker-compose的话,可以通过pip进行安装。https://docs.docker.com/compose/install/
pip install docker-compose
单机版安装
这里介绍docker的安装方式,官方还提供了使用Kubernetes安装
-
下载docker镜像文件
wget https://raw.githubusercontent.com/milvus-io/milvus/ecfebff801291934a3e6c5955e53637b993ab41a/deployments/docker/standalone/docker-compose.yml -O docker-compose.yml没办法的可以自己新建docker-compose.yml文件,然后填入以下内容:
version: '3.5' services: etcd: container_name: milvus-etcd image: quay.io/coreos/etcd:v3.5.0 volumes: - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd minio: container_name: milvus-minio image: minio/minio:RELEASE.2020-12-03T00-03-10Z environment: MINIO_ACCESS_KEY: minioadmin MINIO_SECRET_KEY: minioadmin volumes: - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data command: minio server /minio_data healthcheck: test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"] interval: 30s timeout: 20s retries: 3 standalone: container_name: milvus-standalone image: milvusdb/milvus:v2.0.0-rc4-20210811-bdb8396 command: ["milvus", "run", "standalone"] environment: ETCD_ENDPOINTS: etcd:2379 MINIO_ADDRESS: minio:9000 volumes: - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus ports: - "19530:19530" depends_on: - "etcd" - "minio" networks: default: name: milvus -
拉取镜像并启动
docker-compose up -d
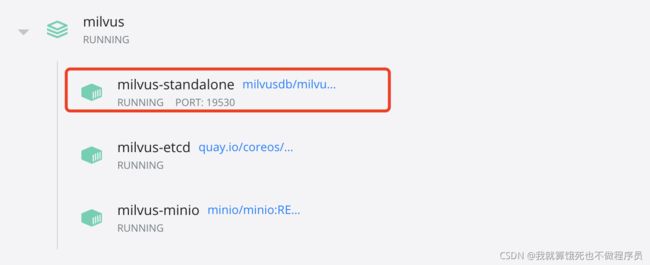
这条是启动命令,第一次运行时需要联网拉取以下三个镜像:

启动的服务默认端口是19530,包括以下三个docker容器:
分布式版安装
https://milvus.io/cn/docs/v2.0.0/install_cluster-docker.md
Python SDK
安装依赖
pip install pymilvus-orm==2.0.0rc4
官网说明最新版本需要python3.6以上,但实际测试,需要python3.8才能成功安装(主要是pandas的版本要求比较高)
连接milvus服务
from pymilvus_orm import connections, FieldSchema, CollectionSchema, DataType, Collection
# 连接milvus服务器
connections.connect(host='localhost', port='19530')
##创建collection
collection必须要有一个filed是主键,一个filed是存储向量,另外还可以创建其他类型的filed
field_name = "example_field"
def create_collection():
"""
创建集合collection
:return:
"""
collection_name = "example_collection"
from pymilvus_orm import Collection, CollectionSchema, FieldSchema, DataType
# 主键
field_id = FieldSchema(name="field_id", dtype=DataType.INT64, is_primary=True, auto_id=True)
# 向量检索的field
field = FieldSchema(name=field_name, dtype=DataType.FLOAT_VECTOR, dim=8)
cat_id = FieldSchema(name="cat_id", dtype=DataType.INT64)
schema = CollectionSchema(fields=[field_id, field, cat_id], description="example collection")
collection = Collection(name=collection_name, schema=schema)
print(pymilvus_orm.utility.get_connection().has_collection(collection_name))
print(pymilvus_orm.utility.get_connection().list_collections())
return collection
collection还可以将数据存储在不同的分区。默认是有一个"Default partition"的分区,不指定分区的话,都会存储在default分区。
def create_partition(collection: Collection):
"""
为collection创建分区
:param collection:
:return:
"""
partition_name = "example_partition"
partition = collection.create_partition(partition_name)
print(collection.partitions)
print(collection.has_partition(partition_name))
插入数据
插入数据可以根据实际需要,是否插入到特定的分区。
- 当前版本数据格式只能是list,numpy的ndarray也不行;
- 如果主键设置自增
auto_id=True,则无需添加主键的值了; - 数据插入之后,它是存储在内存中,还需要将其传输到磁盘中,下次可以继续使用。
def insert(collection: Collection, partition_name=None):
"""
插入数据
:param partition_name: 指定插入的分区
:param collection:
:return:
"""
# 由于主键field_id设置自增,所以无需插入
mr = collection.insert([
# 只能是list
np.random.random([10000, 8]).tolist(), # 向量
np.random.randint(0, 10, [10000]).tolist() # cat_id
], partition_name=partition_name)
print(mr.primary_keys)
# 插入的数据存储在内存,需要传输到磁盘
pymilvus_orm.utility.get_connection().flush([collection.name])
创建索引
为向量对应的filed创建索引,目的就是实现高效的向量邻近搜索。
目前支持的索引类型包括:

def create_index(collection: Collection):
"""
为向量检索的field 创建索引
:param collection:
:return:
"""
index_param = {
"metric_type": "L2",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024}
}
collection.create_index(field_name=field_name, index_params=index_param)
print(collection.index().params)
查询
除了一般的向量搜索,milvus还支持带表达式的标量过滤功能。
例如下方代码中,就增加expr="cat_id==2"条件:即只在cat_id为2的向量中进行检索(上面创建了名称为cat_id的filed)。
但是目前还不支持字符串的过滤功能,官方后续会增加;
支持关系运算符(如==, >)、逻辑运算符(AND &&, OR ||)和IN运算符。
def search(collection: Collection, partition_name=None):
"""
向量检索
:param collection:
:param partition_name: 检索指定分区的向量
:return:
"""
# 将collection加载到内存
collection.load()
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
# 向量搜索
result = collection.search(data=np.random.random([5, 8]).tolist(),
anns_field=field_name, param=search_params, limit=10,
partition_names=[partition_name] if partition_name else None)
print(result[0].ids)
print(result[0].distances)
# 表达式:只检索cat_id为2的向量
result = collection.search(data=np.random.random([5, 8]).tolist(),
anns_field=field_name, param=search_params, limit=10,
expr="cat_id==2")
print(result[0].ids)
print(result[0].distances)
删除数据
目前支持以下三种删除操作
def drop(collection: Collection):
# 删除collection
collection.drop()
# 删除索引
collection.drop_index()
# 删除分区
collection.drop_partition("partition_name")
释放
def release(collection: Collection = None):
# 从内存中释放collection
if collection:
collection.release()
# 断开与服务器的连接,释放资源
connections.disconnect("default")
其他SDK
1.x版本支持:

2.x版本目前只有python,其他还在开发中
可视化管理
milvus的强大之处,还在于它提供了可视化的管理工具。
也是以docker的形式进行安装和启动:
docker run -p 8000:3000 -e HOST_URL=http://{ your machine IP }:8000 -e MILVUS_URL={your machine IP}:19530 milvusdb/milvus-insight:latest
注意:这里的IP不能写localhost,否则可能会出现连接问题。
-
查看load到内存的collection

-
查看collection的结构和分区,还支持删除和导入操作

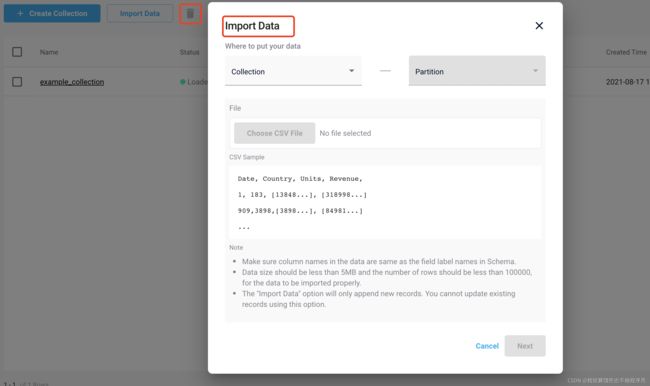
- 在线向量检索

后续功能
其实,到这里,milvus已经足够强大,但他们还在持续支持许多强大的新功能。


