sklearn实验1——使用感知器对鸢尾花数据分类
1、实验原理
- 感知器算法是最简单的可以学习的机器。感知器算法是很多更复杂算法的基础,如支持向量机和多层感知器人工神经网络。
- 感知器算法要求样本是线性可分的,通过梯度下降法有限次的迭代后就可以收敛得到一个解。 当样本非线性时,使用感知器算法不会收敛。为了使感知器算法在样本集不是线性可分时仍能得到收敛的解,可以在梯度下降过程中让步长按照一定的规则逐渐缩小,这样就可以强制算法收敛。
2、实验内容:
- 读取iris鸢尾花数据集,绘制散点图展示3类鸢尾花。
- 使用感知器算法区分山鸢尾(setosa)和维吉尼亚鸢尾(virginica),每次只使用两个特征进行划分,分别如下:
a: 使用花萼长度和花萼宽度两个特征
b: 使用花瓣长度和花瓣宽度两个特征
感知器算法的步长为 0.1,初始权重为 w = [ 1 , 1 ] T , w 0 = 0 w=[1,1]^T,w_0=0 w=[1,1]T,w0=0 - 输出结果并绘制分类器图
- 改变步长和初始权重,观察对算法的影响
3、实验代码
- 导入实验会用到的相关库
# 导入实验要用到的相关库
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
%matplotlib inline
- 加载鸢尾花数据集
# 加载数据集
iris_dataset = load_iris()
- 使用pandas DataFrame 格式查看数据集
df = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
df['label'] = iris_dataset.target
df

- 绘制数据集的散点图矩阵
# 将数据data转换为DataFrame格式
# 利用iris_dataset.feature_names中的字符串对数据列进行标记
iris_dataframe = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
# 利用DataFrame创建散点图矩阵,参数c表示按标签target着色
grr = pd.plotting.scatter_matrix(iris_dataframe, c=iris_dataset.target, figsize=(10, 10), marker='o',hist_kwds={'bins': 50}, s=50, alpha=.8)

矩阵的主对角线是每个特征的直方图,其他位置为通过两两特征绘制的散点图。
- 取出山鸢尾(setosa)和维吉尼亚鸢尾(virginica)的数据和标签
输入:
# 实验要求使用感知器算法区分山鸢尾(Iris-setosa)和维吉尼亚鸢尾(Iris-virginica)
# 取出setosa和virginaica的数据和标签
X = iris_dataset.data[list(range(50))+list(range(100,150))]
y = iris_dataset.target[list(range(50))+list(range(100,150))]
print(X.shape) # 查看X的形状
输出:
(100, 4)
- 选择特征
由于每次划分只是用两个特征,因此还需要对特征进行选择
输入:
X_a = X[:,[0,1]] # X_a:使用花萼长度和花萼宽度两个特征;
print(X_a.shape)
X_b = X[:,[2,3]] # X_b:使用花瓣长度和花瓣宽度两个特征。
print(X_b.shape)
输出:
(100, 2)
(100, 2)
- 画出数据分布
# 画出使用花萼长度和花萼宽度两个特征的点的数据的分布
plt.subplot(2, 1, 1)
plt.scatter(X_a[:50,0],X_a[:50,1], c='c',label='0')
plt.scatter(X_a[50:100,0],X_a[50:100,1], c='y', label='2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.title('Iris-setosa and Iris-virginica')
plt.legend()
plt.show()
# 画出使用花瓣长度和花瓣宽度两个特征的点的数据的分布
plt.subplot(2, 1, 2)
plt.scatter(X_b[:50,0],X_b[:50,1], c='c', label='0')
plt.scatter(X_b[50:100,0],X_b[50:100,1], c='y', label='2')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.title('Iris-setosa and Iris-virginica')
plt.legend()
plt.show()

- 划分训练集和测试集,并修改标签
# 划分训练集和测试集
X_a_train, X_a_test, y_a_train, y_a_test = train_test_split(X_a, y, test_size = 0.4, random_state = 1, stratify = y )
X_b_train, X_b_test, y_b_train, y_b_test = train_test_split(X_b, y, test_size = 0.4, random_state = 1, stratify = y )
# 将标签0改为-1,标签2改为1
y_a_train[y_a_train==0] = -1
y_a_train[y_a_train==2] = 1
y_a_test[y_a_test==0] = -1
y_a_test[y_a_test==2] = 1
y_b_train[y_b_train==0] = -1
y_b_train[y_b_train==2] = 1
y_b_test[y_b_test==0] = -1
y_b_test[y_b_test==2] = 1
- 自定义感知器模型
感知器模型的实现原理其实很简单,如下图所示:

我们可以使用 sklearn 提供感知器模型,也完全可以自己定义一个感知器模型,这里先使用自定义感知器模型进行训练,后面再使用官方提供的感知器模型。
# 自定义感知器模型
class MyPerceptron:
def __init__(self,w,b=0,eta=0.1):
"""初始化感知器模型的权重、偏置和学习率"""
self.w = np.array(w) # 初始化权重
self.b = b # 初始化偏置
self.eta = eta # 初始化学习率
def sign_y(self,xi):
"""计算w*x+b的值,即预测值y1,以便于乘以真实标记y判断是否误分类"""
y1 = np.dot(xi, self.w) + self.b
return y1
def train_ppt(self,X_train,y_train):
"""训练感知器模型"""
while True: # 下面定义了循环结束条件,只要还有误分类点,就会一直循环下去
wrong_count = 0 # 用于记录分类错误的点数
for i in range(len(X_train)):
xi = X_train[i]
yi = y_train[i]
if yi * self.sign_y(xi) <= 0: # 小于0,则表示该样本分类错误,需要更新w,b
self.w = self.w + self.eta * yi * xi
self.b = self.b + self.eta * yi
wrong_count += 1
if wrong_count == 0: # 定义函数结束条件,一次循环下来,误分类点为0,即所有点都正确分类了
return self.w,self.b
def accuracy(self,X_test,y_test):
"""精度计算函数,使用混淆矩阵计算"""
c_matrix = np.zeros((2,2))
for i in range(len(X_test)):
xi = X_test[i]
yi = y_test[i]
if yi * self.sign_y(xi) > 0:
if yi == -1:
c_matrix[0][0] += 1
elif yi == 1:
c_matrix[1][1] += 1
else:
if yi == -1:
c_matrix[1][0] += 1
elif yi == 1:
c_matrix[0][1] += 1
acc = (c_matrix[0][0] + c_matrix[1][1]) / c_matrix.sum()
return acc
def plot_result(self,X_00,X_01,X_20,X_21,X_test_0,X_test_1,title,xlabel,ylabel):
"""
可视化分类结果
X_00,X_01 分别表示第0类(setosa)数据的第一个特征和第二个特征
X_20,X_21 分别表示第2类(virginica)数据的第一个特征和第二个特征
X_test_0,X_test_1 分别表示测试数据的第一个特征和第二个特征
title 图形的标题
xlabel 图形的 x 轴的名称
ylable 图形的 y 轴的名称
"""
# 画出数据点,测试集的数据用黑色的外边标记出来
plt.scatter(X_00, X_01, c='c', label='0')
plt.scatter(X_20, X_21, c='y', label='2')
plt.scatter(X_test_0, X_test_1, c='None', edgecolors='k', label='test data')
# 利用w和b绘制分割直线
# 先计算直线最左侧的点的坐标 (x_1,y_1) 和最右侧点的坐标 (x_2,y_2),再通过这两点画出直线
x_1 = min(np.min(X_00), np.min(X_20))
y_1 = (-self.b - self.w[0] * x_1) / self.w[1]
x_2 = max(np.max(X_00), np.max(X_20))
y_2 = (-self.b - self.w[0] * x_2) / self.w[1]
plt.plot([x_1, x_2], [y_1, y_2])
plt.title(title, fontproperties='SimHei') # fontproperties参数是为了能够显示中文
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.legend() # 显示标签信息
plt.show()
- 使用花萼长度和花萼宽度两个特征训练
输入:
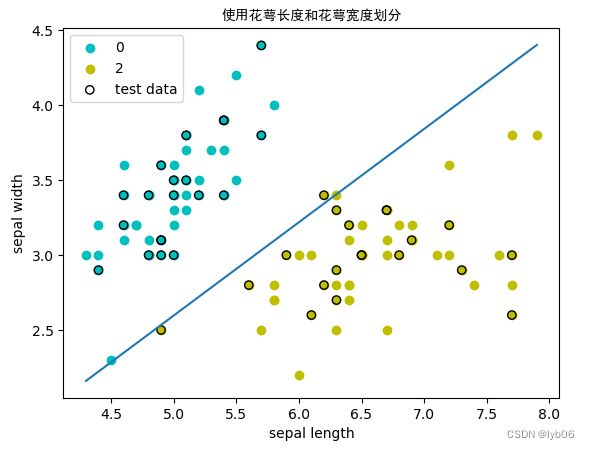
# 使用花萼长度和花萼宽度两个特征训练
print('使用花萼长度和花萼宽度两个特征训练:')
ppt1 = MyPerceptron(w=[1,1], b=0, eta=0.1) # 初始化模型,初始权重为[1,1]、偏置为0,学习率为0.1
w_1,b_1 = ppt1.train_ppt(X_a_train, y_a_train) # 训练模型,输出模型得到的权重和偏置
print('权重: w_1 = {}\n偏置: b_1 = {}'.format(w_1,b_1))
acc_1 = ppt1.accuracy(X_a_test, y_a_test) # 计算模型精度
print('精度: Acc = {}'.format(acc_1))
输出:
使用花萼长度和花萼宽度两个特征训练:
权重: w_1 = [ 3.72 -5.97]
偏置: b_1 = -3.1000000000000014
精度: Acc = 0.975
输入:
# 可视化分类效果
ppt1.plot_result(X_a[:50,0],X_a[:50,1],X_a[50:100,0],X_a[50:100,1],X_a_test[:,0],X_a_test[:,1],title='使用花萼长度和花萼宽度划分',xlabel='sepal length',ylabel='sepal width')
输出:
- 使用花瓣长度和花瓣宽度两个特征训练
输入:
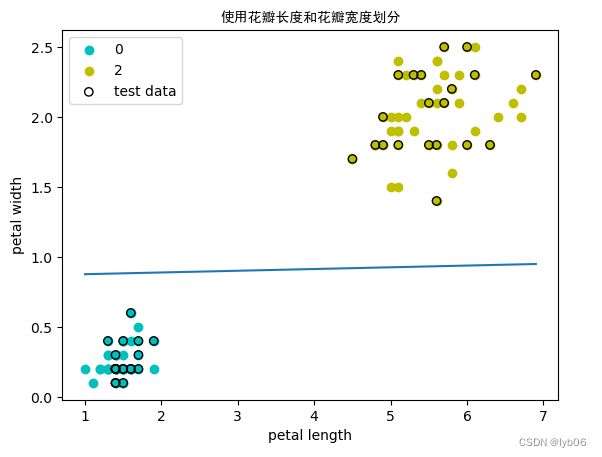
# 使用花瓣长度和花瓣宽度两个特征训练
print('使用花瓣长度和花瓣宽度两个特征训练:')
ppt2 = MyPerceptron(w=[1,1], b=0, eta=0.1) # 初始化模型,初始权重为[1,1]、偏置为0,学习率为0.1
w_2,b_2 = ppt2.train_ppt(X_b_train, y_b_train) # 训练模型,输出模型得到的权重和偏置
print('权重: w_2 = {}\n偏置: b_2 = {}'.format(w_2,b_2))
acc_2 = ppt2.accuracy(X_b_test, y_b_test) # 计算模型精度
print('精度: Acc = {}'.format(acc_2))
输出:
使用花瓣长度和花瓣宽度两个特征训练:
权重: w_2 = [-0.01 0.81]
偏置: b_2 = -0.7
精度: Acc = 1.0
输入:
# 可视化分类效果
ppt2.plot_result(X_b[:50,0],X_b[:50,1],X_b[50:100,0],X_b[50:100,1],X_b_test[:,0],X_b_test[:,1],title='使用花瓣长度和花瓣宽度划分',xlabel='petal length',ylabel='petal width')
输出:
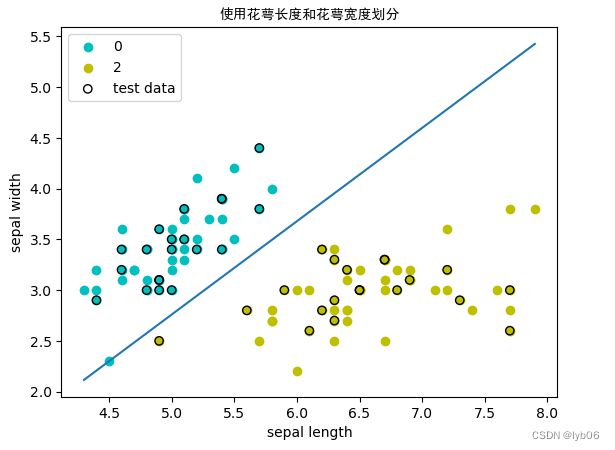
- 改变初始权重,观察对算法的影响
输入:
ppt1.w = np.array([-10,1])
ppt1.b = -2
w_1c,b_1c = ppt1.train_ppt(X_a_train, y_a_train)
print('权重: w_1c = {}\n偏置: b_1c = {}'.format(w_1c,b_1c))
acc_1c = ppt1.accuracy(X_a_test, y_a_test)
print('精度: Acc = {}'.format(acc_1c))
输出:
权重: w_1c = [ 0.8 -0.87]
偏置: b_1c = -1.5999999999999996
精度: Acc = 1.0
输入:
# 可视化分类效果
ppt1.plot_result(X_a[:50,0],X_a[:50,1],X_a[50:100,0],X_a[50:100,1],X_a_test[:,0],X_a_test[:,1],title='使用花萼长度和花萼宽度划分',xlabel='sepal length',ylabel='sepal width')
输出:
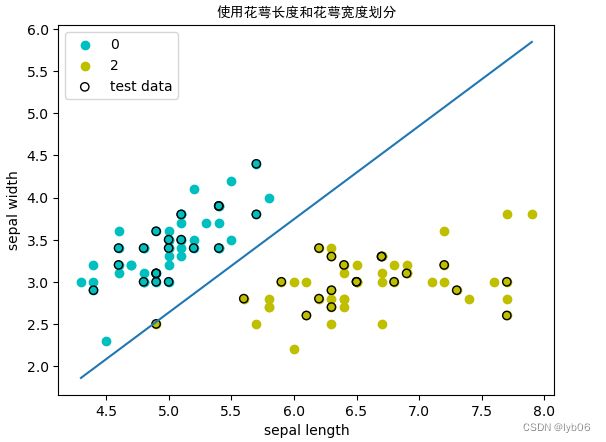
- 改变步长(学习率),观察对算法的影响
输入:
# 改变步长(学习率),观察对算法的影响。
ppt1.w = np.array([1,1])
ppt1.b = 0
ppt1.eta = 0.01
w_1c,b_1c = ppt1.train_ppt(X_a_train, y_a_train)
print('权重: w_1c = {}\n偏置: b_1c = {}'.format(w_1c,b_1c))
acc_1c = ppt1.accuracy(X_a_test, y_a_test)
print('精度: Acc = {}'.format(acc_1c))
输出:
权重: w_1c = [ 0.103 -0.093]
偏置: b_1c = -0.2700000000000001
精度: Acc = 1.0
输入:
# 可视化分类效果
ppt1.plot_result(X_a[:50,0],X_a[:50,1],X_a[50:100,0],X_a[50:100,1],X_a_test[:,0],X_a_test[:,1],title='使用花萼长度和花萼宽度划分',xlabel='sepal length',ylabel='sepal width')
输出:
- 使用sklearn提供的感知器模型
输入:
from sklearn.linear_model import Perceptron
# fit_intercept表示是否对截距进行估计
# n_iter_no_change在提前停止之前等待验证分数无改进的迭代次数,用于提前停止迭代
# eta0 学习率,决定梯度下降时每次参数变化的幅度
perceptron = Perceptron(fit_intercept=True, n_iter_no_change=40, eta0=0.1, shuffle=True)
perceptron.fit(X_a_train, y_a_train)
w = perceptron.coef_[0] # 注意输出的是二维数组,加上[0]后, w=[ 3.09 -4.93]
b = perceptron.intercept_ # b=-2.1
print(w)
print(b)
输出:
[ 3.09 -4.93]
[-2.1]
输入:
# 查看错误分类的样本数
y_a_pred = perceptron.predict(X_a_test)
miss_classified = (y_a_pred != y_a_test).sum()
print("MissClassified: ",miss_classified)
输出:
MissClassified: 0
输入:
# 查看得分
print("Accuracy Score : % .2f" % perceptron.score(X_a_test,y_a_test))
输出:
Accuracy Score : 1.00
输入:
# 可视化分类效果
# 画出数据点,测试集的数据用黑色的外边标记出来
plt.scatter(X_a[:50,0], X_a[:50,1], c='c', label='0')
plt.scatter(X_a[50:100,0], X_a[50:100,1], c='y', label='2')
plt.scatter(X_a_test[:,0], X_a_test[:,1], c='None', edgecolors='k', label='test data')
# 利用w和b绘制分割直线
# 先计算直线最左侧的点的坐标 (x_1,y_1) 和最右侧点的坐标 (x_2,y_2),再通过这两点画出直线
x_1 = min(np.min(X_a[:50,0]), np.min(X_a[50:100,0]))
y_1 = (-b - w[0] * x_1) / w[1]
x_2 = max(np.max(X_a[:50,0]), np.max(X_a[50:100,0]))
y_2 = (-b - w[0] * x_2) / w[1]
plt.plot([x_1, x_2], [y_1, y_2])
plt.title('使用花萼长度和花萼宽度划分', fontproperties='SimHei') # fontproperties参数是为了能够显示中文
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend() # 显示标签信息
plt.show()
输出:
