使用tensorflow和densenet神经网路实现语谱图声纹识别,即说话人识别。
介绍
本文介绍一种使用tensorflow框架和densenet神经网路实现声纹语谱图识别算法,即说话人识别。本文侧重一种解决方案的思路,仅做了小批量数据的简单验证,收敛效果良好,还没有做大量数据集的验证,后期会做一些实际的验证,请持续关注。如果乐意与我交流,文章后面有联系方式,随时欢迎。
代码地址
码云:https://gitee.com/lizhigong/VoiceprintRecognition
整体思路
语音抽样数据->声音语谱图->卷积神经网络->centerloss 实现语音信息的分类,包括语音识别和声纹识别。
软件架构
软件架构说明
1.开发框架使用的TensorFlow
2.神经网络架构使用的densenet
Densenet介绍
先说一下Densenet的优点,我们为什么要学习Densenet。
DenseNet作为另一种拥有较深层数的卷积神经网络,具有如下优点:
(1) 相比ResNet拥有更少的参数数量.
(2) 旁路加强了特征的重用.
(3) 网络更易于训练,并具有一定的正则效果.
(4) 缓解了gradient vanishing和model degradation的问题.
很多的专业术语我一开始也不是很理解,刚开始看的时候总是看的一脸懵逼。其实很简单,多看几遍,自己动手写写试试就可以了。而且很多的网络不需要和原创论文中做的一模一样,只需要根据自己的想象和理解,进行修改删减,搭建适合自己实验和学习使用的就可以了。在这里我们只需要知道这个Densenet是一个很先进的网络,性能,准确率高,参数量少。但是使用时觉得因为Densenet参数虽然少,但是它注重的是对特征图的加工而产生的深层网络,所以内存使用方面并不少。
当然我的理解不一定完全正确,下面谈谈我的理解,如有错误的地方,欢迎指正。
Densenet最关键的理解就是两张图:

这张图是Densenet块中的结构,每个densnet块中的特征图尺寸都是一样的。1x1 和 3x3的卷积层交替使用。 1x1卷积层是为了适配input层或者上一层的特征图数量,3x3的卷积层是为了提炼当前深度的特征,数量固定。比如有一组输入特征图64张宽40高40表示为 40x40x64。经过1x1x64x16卷积以后当前深度的40x40x64特征图适配成40x40x16在用3x3x16x16的卷积层进行卷积。然后经过上一层的拼接40x40x64 + 40x40x16合成40x40x80的特征图送到下一层。一个块内循环操作。
因为整个densenet很深,所以每一层卷积核参数量不需要很大就可以完成任务。这也是为什么一个很深的densent参数量却可以很少。

这张图是Densenet的整体结构,里面含有多个densent块,每个块处理后的特征图需要pooling降低维度,减少特征图数量。减少数量使用的还是1x1卷积层,一般降低成一半,降低特征图维度用的max-pooling。
最后的输出,可以用1x1卷积加全局平均池化层,把每个特征图平均池化成一个特征参数,这样有三个好处 1,不用全连接层,大大减少参数量,2,对输入图片尺寸不敏感,输入尺寸可以是任意尺寸。3、可以训练的时候训练的是小的图,使用的时候可以把整张图作为输入,最后的全局池化层改为avg-pooling。一次性识别出大图中的多个目标。
Densnet的详细介绍可以参考原文https://blog.csdn.net/sigai_csdn/article/details/82115254。
关于loss 本次实验使用的是普通的softmax。 如果想实现one-shot,可以插入一个全连接层,联合center-loss训练(这是我的改进想法,还没做实验)。
语谱图介绍:
语谱图就是语音频谱图,一般是通过处理接收的时域信号得到频谱图,因此只要有足够时间长度的时域信号就可。专业点讲,那是频谱分析视图,如果针对语音数据的话,叫语谱图。语谱图的横坐标是时间,纵坐标是频率,坐标点值为语音数据能量。由于是采用二维平面表达三维信息,所以能量值的大小是通过颜色来表示的,颜色深,表示该点的语音能量越强。
简单的说,语谱图就是能把声音转换成图片的一种技术。声音转换成图片,在用我们很熟悉的卷积神经网络来处理他们非常擅长的这些图片。就可以完美的解决神经网络"听力"的问题。
为了直观的表示,贴出几张实验过程中生成的语谱图:
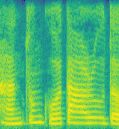

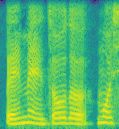
是不是有那么点像指纹,当然说话内容不同,语谱图也不一样,这三张图就是来自于同一个人说话的语谱图,你看不出任何相同点。但是Densenet可以,是不是很神奇,一起来研究一下吧。
本人公开的代码训练流程:
(1)下载数据集CommonVoice 网址https://voice.mozilla.org/zh-CN/datasets。输入邮箱即可免费下载。
(2)下载后解压到当前文件夹下。
(3)运行VoiceToImg.py中的CommonVoiceSplit()将validated.tsv中标注的mp3文件按人分割目录。分割后可以手工筛选一下,这里学习使用,仅保留20人的数据其余的删除掉,我这里找的都是有5段mp3语音的文件夹(注,文件夹要重命名01~20)
(4)运行VoiceToImg.py中的ChangeMp3ToWavToImg()将mp3文件批量转换成大量语谱图,每个语谱图代表大概1.5秒的声音,内含声纹特征。
(5)运行ImgToDataset.py将语谱图打包成训练集和测试集image.train.FRecord,image.test.FRecord。
(6)运行MyDenseNet.py的train(),开始训练,训练次数可自行配置,网络超参数可调整,深度,densenet块的层数。使用说明
- mp3转换语谱图的过程需要先转换成wav文件,使用pydub,可以直接pip安装。pyhub依赖ffmpeg,使用Anaconda的朋友可以conda install -c conda-forge ffmpeg安装。
- mp3转换后的wav需要降采样,使用librosa,可以直接pip安装。
- 本人新手,代码是近期学习的一些心得体会做的,里面也有一些注释和用法,希望结识一些好汉共同学习,也希望各路高手不吝赐教。
- 本人QQ306128847,希望一起学习,共同进步的朋友加我。