静态 链接
1、空间与地址的分配
现在的链接器空间分配的策略基本上都采用 “相似段合并” 的方式。通过将所有相同类型的 section 合并到一起,例如将所有输入目标文件的 .text 合并(按顺序合并)到输出文件的 .text 节中;然后,链接器根据运行平台中进程虚拟地址空间的划分规则,为所有输入目标文件中定义的节和符号分配运行时内存地址;完成之后,程序中的每条指令和符号都有唯一的运行时内存地址了。链接器的空间分配示意如下:
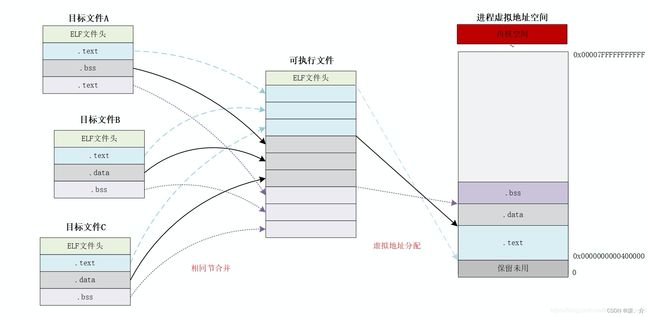
使用这种方法的链接器都采用两步链接的方法。
第一步,空间与地址分配。扫描所有的输入目标文件,获取她们各个段的长度、属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局符号表中。这一步,链接器将能够获得所有输入目标文件的段长度,并且将他们合并,计算出输出文件中各个段合并后的长度与位置,并建立映射关系。
第二步,符号解析与重定位。使用上一步收集的所有信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调试代码中的地址等。
下面我们以a.c、b.c两个文件为例进行讲解。首先,这两个源文件的编译和手动链接就很麻烦,耐下心来,先把这两个源文件的编译和链接搞清楚。
/* a.c */
extern int shared;
extern void swap(int *a, int *b);
int main()
{
int a = 100;
swap(&a, &shared);
}
/* b.c */
int shared = 1;
void swap(int *a, int *b)
{
*a^=*b^=*a^=*b;
}
gcc编译,然后ld去链接。链接过程中会报未定义引用错误。
liang@liang-virtual-machine:~/cfp$ gcc -c a.c b.c
liang@liang-virtual-machine:~/cfp$ ld -e main a.o b.o -o ab
a.o: In function `main':
a.c:(.text+0x44): undefined reference to `__stack_chk_fail'
实际上,我们手动调用 ld 链接器链接,其实没有链接什么库文件,所以自然会报这个未定义引用,最简单的办法就是把这个默认的栈相关的检查给关了,解决办法不是在链接过程中,而是在编译时加参数“-fno-stack-protector”,强制 gcc 不进行栈检查。
liang@liang-virtual-machine:~/cfp$ gcc -c -fno-stack-protector a.c b.c
liang@liang-virtual-machine:~/cfp$ ld -e main a.o b.o -o ab
liang@liang-virtual-machine:~/cfp$ ./ab
Segmentation fault (core dumped)
然而解决了未定义引用的问题,又蹦出来一个段错误——Segmentation fault。
编程语言一般都需要语言库,语言库的一个重要作用就是实现对操作系统 API 的封装,我们平时跑个小程序啥的本质上是把代码编译成可执行文件,然后以一个进程的方式运行该可执行文件。
而对于一个进程的开始和结束其实就是依靠操作系统提供的 API 来实现的,而如何调用操作系统的API呢?就是通过刚刚提到的语言库了,在我的测试环境下,C的语言库就是大名鼎鼎的GNU搞的Glibc。
简单地说,平时用到的那种 main 函数形式的程序,其实是依靠 Glibc 来实现的,那种程序真正的入口并非 main 函数,而是该库里面的_start 函数,由库负责初始化后调用 main 函数来执行程序的主体部分。
但是我们现在搞的这段代码,我并不想依赖 Glibc,是想尽量啥都不依赖。所以我们写这个 main 函数本质上没啥特殊的,跟平时我们常见的 main 函数不一样了,平时 main 函数那么特殊还是因为在依赖Glibc,Glibc指定入口就是 main 函数,所以它才特殊,现在我们不用 Glibc 了,入口其实是链接时候自己指定的,也就是上面出现过的 ld 的命令里 “-e main” 那个选项,所以这时候main函数其实不特殊了。
说回刚才的话题,既然不用 Glibc 了,那原来 main 函数结束后 Glibc 帮我们结束进程的活也没人干了呀,所以刚才运行的时候进程一直没结束,一直在往后边地址上跑,结果跑到不该去的地方就自然就 Segmentation fault。明白了原理其实解决方法也不难的,Glibc也不是神仙,它其实是通过调用操作系统的API “EXIT”实现的中断进程,我们现在只要自己搞一个函数实现同样的功能就好了,以下是加上这个功能的代码:
extern int shared;
void swap(int *a, int *b);
#define x86_64
#ifdef x86_64
void exit()
{
asm("movq $66,%rdi \n\t"
"movq $60,%rax \n\t"
"syscall \n\t");
}
#else
void exit()
{
asm("movl $42,%ebx \n\t"
"movl $1,%eax \n\t"
"int $0x80 \n\t");
}
#endif
int main()
{
int a = 100;
swap(&a, &shared);
exit();
}
这里面会涉及到内联汇编的知识,感兴趣的朋友可以自己学习学习,x86_64位和x86_32的汇编操作不一样,这一点要注意,上面代码中也有体现。下面给出相关链接,可以看一看。
系统调用约定
添加了exit()退出函数后,编译会报warning。这是因为 exit( ) 是C语言内置函数,有对应的__builtin_exit()内建函数。内建函数是编译器针对特定平台对代码所作的优化,会使代码的运行效率有很大提高。所以不加“-fno-builtin”参数,会默认把 “exit” 识别为内置函数,所以会报warning。解决的方法是加上“-fno-builtin”参数,默认不使用内建函数。
liang@liang-virtual-machine:~/cfp$ gcc -c -fno-stack-protector a.c b.c
a.c: In function ‘exit’:
a.c:5:6: warning: number of arguments doesn’t match built-in prototype
void exit()
^
编译、链接如下,发现终于正确了。
liang@liang-virtual-machine:~/cfp$ gcc -c -fno-builtin -fno-stack-protector a.c b.c
liang@liang-virtual-machine:~/cfp$ ld -e main a.o b.o -o ab
liang@liang-virtual-machine:~/cfp$ ./ab
Tips:这里关于内建函数和内置函数拓展一下
内置函数分为两类:
一类与标准c库函数对应,例如strcpy()有对应的__builtin_strcpy()内建函数;另一类是对库函数的拓展。
且所有的内置函数都是 inline 的
从这里我们其实也可以知道,所谓的内建, 其实可以理解为内置的一种~~,内建/内置函数,英文翻译都是 built-in function
gcc官方文档里面有一段话,大意是:对于内置函数,如果能对代码进行优化,gcc会优化代码,如果不能优化,往往就是直接调用同名的标准库函数。上边为什么会报错,因为调用了 exit 对应的内建函数去优化代码
1.1 符号地址的确定
到此为止,终于把这个两个源文件的编译和链接讲清楚了,下面我们进入正题。
liang@liang-virtual-machine:~/cfp$ objdump -h a.o
a.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000048 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000088 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000088 2**0
ALLOC
...
liang@liang-virtual-machine:~/cfp$ objdump -h b.o
b.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000004b 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000004 0000000000000000 0000000000000000 0000008c 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000090 2**0
ALLOC
3 .comment 00000036 0000000000000000 0000000000000000 00000090 2**0
CONTENTS, READONLY
...
liang@liang-virtual-machine:~/cfp$ objdump -h ab
ab: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000093 00000000004000e8 00000000004000e8 000000e8 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .eh_frame 00000078 0000000000400180 0000000000400180 00000180 2**3
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .data 00000004 00000000006001f8 00000000006001f8 000001f8 2**2
CONTENTS, ALLOC, LOAD, DATA
...
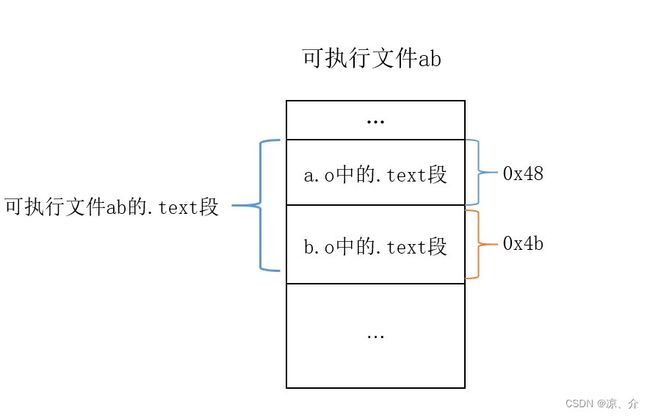
其中 VMA 表示 virtual memory address 即虚拟地址,LMA 表示 load memory address,即加载地址。我们暂且不关心文件偏移(File off)。我们看到,在链接之前,所有的 VMA 都是0,因为虚拟空间还没有分配。链接之后,可执行文件 ab 中的各个段都被分配到了虚拟地址,VMA不为0。从上述分析中我们也可以看出,“a.o”和“b.o”的代码段被先后叠加起来,合并成 “ab” 的一个.text段,加起来长度刚好是0x93。数据段也是如此。但是为什么给 ab 文件的 text 段分配到0x00000000004000e8地址呢,后面会有具体分析。
当空间分配阶段结束后,链接器按照前面介绍的空间分配方法进行分配,这时候输入文件中的各个段在链接后的虚拟地址就已经确定了。
当前面一步完成之后,链接器就开始计算各个符号的虚拟地址了。因为各个符号在段内的相对位置是固定的,所以这时候其实“main”、“shared”和“swap”的地址也已经是确定的了,只不过链接器需要给每个符号加上一个偏移,使它们能够调整到正确的虚拟地址。
liang@liang-virtual-machine:~/cfp$ objdump -d a.o
a.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <exit>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
...
0000000000000017 <main>:
17: 55 push %rbp
18: 48 89 e5 mov %rsp,%rbp
...
liang@liang-virtual-machine:~/cfp$ objdump -d b.o
b.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <swap>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
...
例如,我们可以用 objdump 查看目标文件 a.o,我们可以看到,exit 函数相对于.text 段的偏移为0x0,而main函数相对于 .text 段的偏移为0x17。而我们知道,最终可执行文件中的 .text 段的虚拟地址是 0x4000e8(objdump -h ab)。链接器根据最终可执行文件中的 .text 段的虚拟地址,就可以计算出main、exit函数的虚拟地址。
swap函数位于b.o中,通过反汇编b.o,我们可以看到 swap 函数相对 .text 段的偏移为0。而我们知道,链接器是按序、采用相似段合并的方法分配空间的,所以最终可执行文件的 .text 段中,a.o的 .text 段在b.o的 .text 段上面。事实也是如此,我们可以通过反汇编可执行文件ab看到。所以,swap函数的虚拟地址 = 可执行文件中 .text 段的虚拟地址 + a.o 中 .text 段大小。shared变量的虚拟地址是一样的计算方法。
| 符号 | 类型 | 虚拟地址 |
|---|---|---|
| main | 函数 | 0x4000e8 + 0x17 = 4000ff |
| swap | 函数 | 0x4000e8 + 0x48 = 400130 |
| exit | 函数 | 0x4000e8 + 0x0 |
| shared | 变量 | 0x6001f8 + 0x0 |
其实到这,这些个符号的地址就已经确定了。下面就是要根据这些符号地址,去修正相应的符号无效地址。
2、符号解析与重定位
2.1 重定位
反汇编查看a.o
liang@liang-virtual-machine:~/cfp$ objdump -d a.o
a.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <exit>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 c7 c7 42 00 00 00 mov $0x42,%rdi
b: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
12: 0f 05 syscall
14: 90 nop
15: 5d pop %rbp
16: c3 retq
0000000000000017 <main>:
17: 55 push %rbp
18: 48 89 e5 mov %rsp,%rbp
1b: 48 83 ec 10 sub $0x10,%rsp
1f: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
26: 48 8d 45 fc lea -0x4(%rbp),%rax
2a: be 00 00 00 00 mov $0x0,%esi
2f: 48 89 c7 mov %rax,%rdi
32: e8 00 00 00 00 callq 37 <main+0x20>
37: b8 00 00 00 00 mov $0x0,%eax
3c: e8 00 00 00 00 callq 41 <main+0x2a>
41: b8 00 00 00 00 mov $0x0,%eax
46: c9 leaveq
47: c3 retq
在完成空间和地址分配步骤以后,链接器就进入了符号解析与重定位步骤,这也是静态链接的核心内容。
我们可以很清楚的看到 “a.o” 的反汇编中,偏移为 0x2a 的 move 指令。

这里的share的地址为什么是0呢?因为当源代码“a.c”被编译成目标文件 a.o 时,编译器并不知道"shared"的地址。所以编译器就暂时把地址0看作“shared”的地址。
另一个偏移为 0x32 的指令,也是如此。这条指令表示对 swap 函数的调用。偏移为 0x3c 的指令,表示对 exit 函数的调用

这里call指令,是一条近地址相对位移调用指令,后面四个字节就是被调用的函数相对于调用指令的下一条指令的偏移量。
编译器无法确定的符号的地址,就由链接器来修正符号的地址。我们反汇编可执行文件ab,可以看到里面的符号地址已经被修正了。
liang@liang-virtual-machine:~/cfp$ objdump -d ab
ab: file format elf64-x86-64
Disassembly of section .text:
00000000004000e8 <exit>:
4000e8: 55 push %rbp
4000e9: 48 89 e5 mov %rsp,%rbp
4000ec: 48 c7 c7 42 00 00 00 mov $0x42,%rdi
4000f3: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
4000fa: 0f 05 syscall
4000fc: 90 nop
4000fd: 5d pop %rbp
4000fe: c3 retq
00000000004000ff <main>:
4000ff: 55 push %rbp
400100: 48 89 e5 mov %rsp,%rbp
400103: 48 83 ec 10 sub $0x10,%rsp
400107: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
40010e: 48 8d 45 fc lea -0x4(%rbp),%rax
400112: be f8 01 60 00 mov $0x6001f8,%esi
400117: 48 89 c7 mov %rax,%rdi
40011a: e8 11 00 00 00 callq 400130 <swap>
40011f: b8 00 00 00 00 mov $0x0,%eax
400124: e8 bf ff ff ff callq 4000e8 <exit>
400129: b8 00 00 00 00 mov $0x0,%eax
40012e: c9 leaveq
40012f: c3 retq
0000000000400130 <swap>:
400130: 55 push %rbp
400131: 48 89 e5 mov %rsp,%rbp
400134: 48 89 7d f8 mov %rdi,-0x8(%rbp)
400138: 48 89 75 f0 mov %rsi,-0x10(%rbp)
40013c: 48 8b 45 f8 mov -0x8(%rbp),%rax
400140: 8b 10 mov (%rax),%edx
400142: 48 8b 45 f0 mov -0x10(%rbp),%rax
400146: 8b 00 mov (%rax),%eax
400148: 31 c2 xor %eax,%edx
40014a: 48 8b 45 f8 mov -0x8(%rbp),%rax
40014e: 89 10 mov %edx,(%rax)
400150: 48 8b 45 f8 mov -0x8(%rbp),%rax
400154: 8b 10 mov (%rax),%edx
400156: 48 8b 45 f0 mov -0x10(%rbp),%rax
40015a: 8b 00 mov (%rax),%eax
40015c: 31 c2 xor %eax,%edx
40015e: 48 8b 45 f0 mov -0x10(%rbp),%rax
400162: 89 10 mov %edx,(%rax)
400164: 48 8b 45 f0 mov -0x10(%rbp),%rax
400168: 8b 10 mov (%rax),%edx
40016a: 48 8b 45 f8 mov -0x8(%rbp),%rax
40016e: 8b 00 mov (%rax),%eax
400170: 31 c2 xor %eax,%edx
400172: 48 8b 45 f8 mov -0x8(%rbp),%rax
400176: 89 10 mov %edx,(%rax)
400178: 90 nop
400179: 5d pop %rbp
40017a: c3 retq
我们通过前面的空间与地址分配可以得知,链接器在完成地址和空间分配之后就已经可以确定所有符号的虚拟地址了,那么链接器就可以根据符号的地址对每个需要重定位的指令进行地址修正。我们用 objdump 来反汇编输出程序“ab”的代码段,可以看到main函数的三个重定位入口都已经被修正到正确的位置了:
400112: be f8 01 60 00 mov $0x6001f8,%esi
...
40011a: e8 11 00 00 00 callq 400130
...
400124: e8 bf ff ff ff callq 4000e8
shared的地址为 0x6001f8,这个很好理解,因为 shared 变量的地址的确是 0x6001f8。
be f8 01 60 00
那么 swap 函数的虚拟地址为什么是 0x11 呢?这个和 call 指令有关
40011a: e8 11 00 00 00
0x400130 = 40011f (调用指令的下一条指令地址)+ 0x11(偏移)。这里 call 指令,是一条近地址相对位移调用指令。后面四个字节就是被调用的函数相对于调用指令的下一条指令的偏移量。
2.2 重定位表
链接器是怎么知道哪些指令是要被调整的呢?这些指令的哪些部分要被调整?怎么调整?比如上面例子中的 “mov” 指令和“call” 指令的调整方式就有所不同。事实上,在ELF文件中,有一个叫重定位表(Relocation Table)的结构专门用来保存这些与重定位相关的信息,我们在前面介绍ELF文件结构时已经提到过重定位表,它在ELF文件中往往是一个或多个段。
对于可重定位的ELF文件来说,它必须包含重定位表,用来描述如何修改相应的节的内容。对于每个要被重定位的ELF段都有一个对应的重定位表。如果 .text 段需要被重定位,则会有一个相对应叫 .rel.text 的段保存了代码节的重定位表;如果 .data 段需要被重定位,则会有一个相对应的 .rel.tdata 的段保存了数据节的重定位表。
我们可以使用objdump工具来查看目标文件中的重定位表:
liang@liang-virtual-machine:~/cfp$ objdump -r a.o
a.o: file format elf64-x86-64
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
000000000000002b R_X86_64_32 shared
0000000000000033 R_X86_64_PC32 swap-0x0000000000000004
000000000000003d R_X86_64_PC32 exit-0x0000000000000004
...
我们可以看到每个要被重定位的地方是一个重定位入口(Relocation Entry)。利用数据结构成员包含的信息,即可完成重定位。
重定位入口的偏移(Offset) 表示该入口在要被重定位的段中的位置,这里的0x2b是目标文件 a.o 代码段中 shared 指令地址部分的地址。0x33和0x3d是目标文件 a.o 代码段中 swap、exit 指令地址部分的地址。简单来说,就是需要修正的地方的地址。
typedef struct {
Elf32_Addr r_offset;
Elf32_Word r_info;
} Elf32_Rel;
typedef struct {
Elf64_Addr r_offset;
Elf64_Xword r_info;
} Elf64_Rel;
| r_offset | 此成员指定应用重定位操作的位置。不同的目标文件对于此成员的解释会稍有不同。对于可重定位文件,该值表示节偏移。重定位段说明如何修改文件中的其他节。重定位偏移会在第二节中指定一个存储单元。对于可执行文件或共享目标文件,该值表示受重定位影响的存储单元的虚拟地址。此信息使重定位项对于运行时链接程序更为有用。虽然为了使相关程序可以更有效地访问,不同目标文件的成员的解释会发生变化,但重定位类型的含义保持相同 |
|---|---|
| r_info | 重定位入口的类型和符号。这个成员的低8位表示重定位入口类型,高24位表示重定位入口的符号在符号表的下标。 因为各种处理器的指令格式不一样,所以重定位所修正的指令地址格式也不一样。每种处理器都有自己的一套重定位入口类型。对于可执行文件和共享目标文件来说,它们的重定位入口是动态链接类型的,请参考”动态链接“一章 |
2.3 符号解析
通过前面指令重定位的介绍,我们可以更加深层次地理解为什么缺少符号的定义会导致链接错误。其实重定位过程也伴随着符号解析过程,每个目标文件都可能定义一些符号,也可能引用到定义在其他目标文件的符号。重定位的过程中,每个重定位入口都是对一个符号的引用,那么当链接器需要对某个符号重定位时,它就要确定这个符号的目标地址。这时候链接器就会去查找由所有输入目标文件的符号表组成的全局符号表,找到相应的符号后进行重定位。
例如我们查看a.o的符号表
liang@liang-virtual-machine:~/cfp$ readelf -s a.o
Symbol table '.symtab' contains 12 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS a.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 6
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 5
8: 0000000000000000 23 FUNC GLOBAL DEFAULT 1 exit
9: 0000000000000017 49 FUNC GLOBAL DEFAULT 1 main
10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND shared
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND swap
"GLOBAL"类型的符号,除了main函数、exit函数是定义在代码段之外,其他两个“shared”和“swap”都是“UND”。这种未定义的符号都是因为该目标文件中有关它们的重定位项,所以在链接器扫描完所有输入目标文件之后,所有这些未定义的符号都应该能够在全局符号表中找到,否则链接器就报符号未定义错误。
2.4 指令修正方式
这一块我们暂不作讲解,感兴趣的可以自己 goole 一下
3、COMMON块
正如前面提到的,由于弱符号机制允许同一个符号的定义存在于多个文件中,所以可能会出现一个问题:如果一个弱符号定义在多个目标文件中,而它们的类型又不相同,那怎么办?到底实际被用到的是哪个?
多个符号定义类型不一致的几种情况如下:
- 两个或两个以上强符号类型不一致;
- 有一个强符号,其他都是弱符号,出现类型不一致;
- 两个或两个以上弱符号类型不一致。
对于上述三种情况,第一种情况是无需额外处理的,因为多个强符号定义本身就是非法的,链接器会报符号多重定义错误;链接器要处理的就是后两种情况
现在的编译器和链接器都支持一种叫 COMMON 块的机制,这种机制最早来源于 Fortran,细节不多说了,自己去了解。主要想表达的是,当不同的目标文件需要的 COMMON 块空间大小不一致时,以最大的那块为准。
现代的链接器在处理弱符号的时候,采用的就是与 COMMON 块一样的机制。我们的样例 SimpleSection.c 中,符号 global_uninit_var 就是一个弱符号,我们看一下它的相关信息:
...
12: 0000000000000004 4 OBJECT GLOBAL DEFAULT COM golbal_uninit_var
...
它的类型是 SHN_COMMON ,size 为 4。假设我们在另外一个文件中也定义了 global_uninit_var 变量。且未初始化,它的类型为 double,占 8 个字节,情况会怎样? 事实上按照 COMMON 类型的链接规则,最终链接后输出文件中, global_uninit_var 的大小以输入文件中最大的那个为准,即 global_uninit_var 所占的空间为 8 字节。我们可以验证一下,在另一个文件定义 double global_uninit_var,然后编译和本章的样例进行链接:然后 readelf -s 查看一下输出文件的符号表,找到 global_uninit_var 的相关信息,如下:
72: 0000000000601048 8 OBJECT GLOBAL DEFAULT 26 golbal_uninit_var
当然 COMMON 类型的链接规则是针对符号都是弱符号的情况,如果其中有一个符号为强符号,那么最终输出结果中的符号所占空间与强符号相同。值得注意的是,如果链接过程中有弱符号大小大于强符号,那么 ld 链接器会报如下警告:
/usr/bin/ld: Warning: alignment 4 of symbol `golbal_uninit_var' in /tmp/ccWbmtFc.o is smaller than 8 in /tmp/ccZVSY46.o
这种使用 COMMON 块的方法,实际上是一种类似“黑客”的取巧办法,直接导致需要 COMMON 机制的原因是编译器和链接器允许不同类型的弱符号存在。但本质原因还是链接器不支持符号类型,即链接器无法判断各个符号的类型是否一致,但是在每个输出文件的符号表中,都有 COMMON 块相应符号大小(每个输出文件编译的时候就生成了),链接器在所有需要链接的文件中,对相同符号名,选择大小最大的为准 。
通过上面对链接器处理多个弱符号的过程,我们可以知道,编译成目标文件时,如果包含了弱符号(未初始化的全局变量就是典型的弱符号),那么该弱符号最终所占的空间大小在此时是未知的,因为有可能其他编译单元中该符号所占的空间与本编译单元该符号占的空间大小不一致。所以编译器此时无法为该符号在 BSS 段分配空间,因为所需空间的大小未知。但是链接器在链接过程中就可以确定弱符号的大小了,它可以在最终输出文件的 BSS 段为其分配空间。所以,未初始化全局变量最终是被放在 BSS 段的。
GCC的“-fno-common”也允许我们把所有未初始化的全局变量不以 COMMON 块的形式处理,或者使用“__attribute__”扩展:
int global _attribute_((nocommon));一旦一个未初始化的全局变量不是以 COMMON 块的形式存在,那么它就相当于一个强符号,如果其他目标文件中还有一个同一个变量的强符号定义,链接时就会发生符号重定义错误。
4、静态库链接
4.1 静态库的链接
其实一个静态库可以简单地看成一组目标文件地集合,即很多目标文件经过压缩打包后形成地一个文件。比如我们在Linux中最常用地C语言静态库libc.a,它是glibc项目的一部分。
我们知道在一个C语言的运行库中,包含了很多跟系统功能相关的代码,比如输入输出、文件操作、时间日期、内存管理等。glibc本身是用C语言开发的,它由成千上百个C语言源代码文件组成,也就是说,编译完成以后有相同数量的目标文件,比如输入输出printf.o、scanf.o;文件操作有fread.o、fwrite.o等。把这些零散的目标文件直接提供给库的使用者,很大程序上会造成文件传输、管理和组织方面的不便,于是通常人们使用 “ar” 压缩程序将这些目标文件压缩到一起,并且对其进行编号和索引,以便于查找和检索,就形成了libc.a这个静态库文件。我们可以使用 “ar” 工具来查看这个文件包含了那些目标文件:
liang@liang-virtual-machine:/usr/lib/x86_64-linux-gnu$ ar -t libc.a
init-first.o
libc-start.o
sysdep.o
version.o
check_fds.o
libc-tls.o
elf-init.o
dso_handle.o
errno.o
errno-loc.o
iconv_open.o
iconv.o
iconv_close.o
gconv_open.o
...
使用objdump 和 grep 工具来查看libc.a的符号可以发现如下结果
liang@liang-virtual-machine:/usr/lib/x86_64-linux-gnu$ objdump -t libc.a | grep -w printf
reg-printf.o: file format elf64-x86-64
printf-prs.o: file format elf64-x86-64
printf.o: file format elf64-x86-64
0000000000000000 g F .text 000000000000009e printf
printf-parsemb.o: file format elf64-x86-64
printf-parsewc.o: file format elf64-x86-64
可以看到,“printf” 函数被定义在 “printf.o” 的目标文件中。这里我们似乎找到了最终的机制,那就是“Hello World”程序编译出来的目标文件只要和 libc.a 里面的 “printf.o” 链接在一起,最后就可以形成一个可用的可执行文件了。虽然很接近最后的答案了,但是还是会有问题。当具体去尝试的时候我们会发现,还是会报找不到其他符号的错误。这是因为,“printf.o” 又依赖其它的一些目标文件…
可以看到,如果单靠人工来完成链接一个“Hello World”小程序都这么费劲,那么一个大的工程就可想而知了。幸好 ld 链接器会处理着一切繁琐的事务,自动寻找所有需要的符号及他们所在的目标文件,将这些目标文件从“libc.a”中“解压”出来,最终将他们链接在一起成为一个可执行文件。
现在Linux系统上的库比我们想象的要复杂许多。当我们编译链接一个普通C程序的时候,不仅要用到C语言的libc.a,而且还有其它一些辅助性的目标文件和库。
- --verbose:打印出编译链接时的详细信息
- -static:默认情况下,gcc采用动态链接的方式连接第三方库,比如指定-lpng,链接程序就会去找libpng.so。指定了 -static 这个选项,gcc在链接时对项目所有的依赖库都尝试去搜索名为lib
.a的静态库文件,完成静态连接,如果找不到就报错。
liang@liang-virtual-machine:~/cfp$ gcc -static --verbose -fno-builtin Hello.c
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/5/lto-wrapper
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 5.4.0-6ubuntu1~16.04.12' --with-bugurl=file:///usr/share/doc/gcc-5/README.Bugs --enable-languages=c,ada,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-5 --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --with-system-zlib --disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo --with-java-home=/usr/lib/jvm/java-1.5.0-gcj-5-amd64/jre --enable-java-home --with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-5-amd64 --with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-5-amd64 --with-arch-directory=amd64 --with-ecj-jar=/usr/share/java/eclipse-ecj.jar --enable-objc-gc --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.12)
COLLECT_GCC_OPTIONS='-static' '-v' '-fno-builtin' '-mtune=generic' '-march=x86-64'
/usr/lib/gcc/x86_64-linux-gnu/5/cc1 -quiet -v -imultiarch x86_64-linux-gnu Hello.c -quiet -dumpbase Hello.c -mtune=generic -march=x86-64 -auxbase Hello -version -fno-builtin -fstack-protector-strong -Wformat -Wformat-security -o /tmp/ccbev2gR.s
GNU C11 (Ubuntu 5.4.0-6ubuntu1~16.04.12) version 5.4.0 20160609 (x86_64-linux-gnu)
compiled by GNU C version 5.4.0 20160609, GMP version 6.1.0, MPFR version 3.1.4, MPC version 1.0.3
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/local/include/x86_64-linux-gnu"
ignoring nonexistent directory "/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/5/include
/usr/local/include
/usr/lib/gcc/x86_64-linux-gnu/5/include-fixed
/usr/include/x86_64-linux-gnu
/usr/include
End of search list.
GNU C11 (Ubuntu 5.4.0-6ubuntu1~16.04.12) version 5.4.0 20160609 (x86_64-linux-gnu)
compiled by GNU C version 5.4.0 20160609, GMP version 6.1.0, MPFR version 3.1.4, MPC version 1.0.3
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: 8087146d2ee737d238113fb57fabb1f2
COLLECT_GCC_OPTIONS='-static' '-v' '-fno-builtin' '-mtune=generic' '-march=x86-64'
as -v --64 -o /tmp/ccXqEnrN.o /tmp/ccbev2gR.s
GNU assembler version 2.26.1 (x86_64-linux-gnu) using BFD version (GNU Binutils for Ubuntu) 2.26.1
COMPILER_PATH=/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/
LIBRARY_PATH=/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../lib/:/lib/x86_64-linux-gnu/:/lib/../lib/:/usr/lib/x86_64-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../:/lib/:/usr/lib/
COLLECT_GCC_OPTIONS='-static' '-v' '-fno-builtin' '-mtune=generic' '-march=x86-64'
/usr/lib/gcc/x86_64-linux-gnu/5/collect2 -plugin /usr/lib/gcc/x86_64-linux-gnu/5/liblto_plugin.so -plugin-opt=/usr/lib/gcc/x86_64-linux-gnu/5/lto-wrapper -plugin-opt=-fresolution=/tmp/ccx6TzCJ.res -plugin-opt=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_eh -plugin-opt=-pass-through=-lc --sysroot=/ --build-id -m elf_x86_64 --hash-style=gnu --as-needed -static -z relro /usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crt1.o /usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/5/crtbeginT.o -L/usr/lib/gcc/x86_64-linux-gnu/5 -L/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu -L/usr/lib/gcc/x86_64-linux-gnu/5/../../../../lib -L/lib/x86_64-linux-gnu -L/lib/../lib -L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib -L/usr/lib/gcc/x86_64-linux-gnu/5/../../.. /tmp/ccXqEnrN.o --start-group -lgcc -lgcc_eh -lc --end-group /usr/lib/gcc/x86_64-linux-gnu/5/crtend.o /usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crtn.o
下面我们讲解下这里面的三个关键步骤。
第一步是调用 cc1 程序,这个程序实际上就是GCC的C语言编译器,它将“Hello.c”编译成一个临时的汇编文件“/ccbev2gR.s”。
/usr/lib/gcc/x86_64-linux-gnu/5/cc1 -quiet -v -imultiarch x86_64-linux-gnu Hello.c -quiet -dumpbase
Hello.c -mtune=generic -march=x86-64 -auxbase Hello -version -fno-builtin
-fstack-protector-strong -Wformat -Wformat-security -o /tmp/ccbev2gR.s
然后调用 as 程序,as 程序是GNU的汇编器,它将“/tmp/ccbev2gR.s”汇编成临时目标文件“/tmp/ccXqEnrN.o”。这个“/tmp/ccXqEnrN.o”实际上就是前面的“Hello.o”。
as -v --64 -o /tmp/ccXqEnrN.o /tmp/ccbev2gR.s
接着最关键的是最后一部,GCC调用 collect2 程序来完成最后的链接。实际上 collect2 可以看作是 ld 链接器的一个包装,他会调用 ld 链接器来完成对目标文件的链接,然后再对链接结果进行一些处理,主要是收集所有与程序初始化相关的信息并且构造初始化的结构。在后面我们会介绍程序的初始化结构相关的内容,还会再介绍 collect2 程序。
/usr/lib/gcc/x86_64-linux-gnu/5/collect2 -plugin /usr/lib/gcc/x86_64-linux-gnu/5/liblto_plugin.so
-plugin-opt=/usr/lib/gcc/x86_64-linux-gnu/5/lto-wrapper -plugin-opt=-fresolution=/tmp/ccx6TzCJ.res -plugin-opt
=-pass-through=-lgcc -plugin-opt=-pass-through=-lgcc_eh -plugin-opt=-pass-through
=-lc --sysroot=/ --build-id -m elf_x86_64 --hash-style=gnu --as-needed -static -z
relro /usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crt1.o
/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crti.o /usr/lib/gcc/x86_64-linux-gnu/5/crtbeginT.o
-L/usr/lib/gcc/x86_64-linux-gnu/5 -L/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu
-L/usr/lib/gcc/x86_64-linux-gnu/5/../../../../lib
-L/lib/x86_64-linux-gnu -L/lib/../lib
-L/usr/lib/x86_64-linux-gnu -L/usr/lib/../lib
-L/usr/lib/gcc/x86_64-linux-gnu/5/../../.. /tmp/ccXqEnrN.o
--start-group -lgcc -lgcc_eh -lc --end-group /usr/lib/gcc/x86_64-linux-gnu/5/crtend.o
/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crtn.o
可以看到最后一步中,至少有下列几个库和目标文件被链接入了最终可执行文件:
crt1.o 、crti.o、crtbeginT.o、libgcc.a、libgcc_eh.a、libc.a、crtend.o、crtn.o
4.2 关于GCC
GCC官网
GCC, the GNU Compiler Collection。GCC的官网的开头一段话:
The GNU Compiler Collection includes front ends for C, C++, Objective-C, Fortran, Ada, Go, and D, as well as libraries for these languages (libstdc++,…). GCC was originally written as the compiler for the GNU operating system. The GNU system was developed to be 100% free software, free in the sense that it respects the user’s freedom.
翻译过来就是:
GNU Compiler Collection 包括 C、C++、Objective-C、Fortran、Ada、Go 和 D 的前端,以及这些语言的库(libstdc++,…)。 GCC 最初是作为 GNU 操作系统的编译器编写的。 GNU 系统被开发为 100% 自由软件,自由是因为它尊重用户的自由。
我们可以看到,GCC实际上是一个编译器套装,里面包含了各种的编译器,以及编译器自带的一些库。以gcc为例,我们最常使用的就是 gcc Hello.c -o Hello。短短这句话,其实包含了很多内容,比较重要的就是编译、汇编、链接三个步骤,就像前面静态库链接里面所讲的。
- 编译器:C语言通常用的是 cc1,C++用的是 cc1 pluse
- 汇编器:常见的就是 as
- 链接器:ld、colletc2(colletc2 会间接调用 ld)
我们可以把 gcc 理解成一个总的调度程序,它按照需求去调用cpp/cc1/as/collect2/ld等程序(cpp是预处理),完成对应四个过程。为什么要一个总的调度程序?
通过前面的讲解知道,虽然我们能够自己调用cpp/cc1/as/collect2/ld来完成四个过程,得到最后的可执行文件,但是如果我们都手动去执行这4个过程,就非常麻烦。有了gcc后,可以调用gcc一次性快速完成四个过程,gcc会自动调用cpp/cc1/as/collect2/ld来完成。一次性完成时,中间产生的.i/.s/.o都是临时文件,编译后会被自动删除,这些文件我们并不关心。使用gcc这个总调度程序,一次性完成所有过程时,编译速度非常快,用起来非常方便。
Tips:
Windows下我们常见的是MinGW编译器。
Windows下的MinGW,全称Minimalist GNU For Windows,是个精简的Windows平台C/C++、ADA及Fortran编译器,相比Cygwin而言,体积要小很多,使用较为方便。MinGW提供了一套完整的开源编译工具集,以适合Windows平台应用开发,且不依赖任何第三方C运行时库。
MinGW包括:
一套集成编译器,包括C、C++、ADA语言和Fortran语言编译器
用于生成Windows二进制文件的GNU工具的(编译器、链接器和档案管理器)
用于Windows平台安装和部署MinGW和MSYS的命令行安装器(mingw-get)
用于命令行安装器的GUI打包器(mingw-get-inst)
MinGW 可以理解为GCC在windows平台下的实现。但是MinGW使用Windows中的C运行库,因此用MinGW开发的程序不需要额外的第三方DLL支持就可以直接在Windows下运行,而且也不一定必须遵从GPL许可证;这同时造成了MinGW开发的程序只能使用Win32API和跨平台的第三方库,而缺少POSIX支持,大多数GNU软件无法在不修改源代码的情况下用MinGW编译。
5、链接过程控制
整个链接过程中除了需要确定链接的目标文件、静态库之外,还需要确定链接的规则和结果。大部分情况下,链接器使用默认的链接规则对目标文件进行链接的。但对于一些特殊要求的程序,比如内核、BIOS或者boot loader、嵌入式程序等,往往受限于一些特殊的条件,如需要指定输出文件的各个段虚拟地址、段的名称、段存放的顺序。其实除了上面这些信息之外,链接过程可能还需要确定:是否在可执行文件中保留调试信息、输出文件格式(动态链接库还是可执行文件)、是否导出某些符号以供调试器、程序本身或者其他程序使用等。这些都是可控制的。
5.1 链接控制脚本
前面我们在使用 ld 链接器的时候,没有指定链接脚本,其实 ld 在用户没有指定链接脚本的时候会使用默认链接脚本。我们可以使用下面命令行来查看 ld 默认链接脚本:
liangjie@liangjie-virtual-machine:~/Desktop$ ld -verbose
链接器一般提供多种方法来控制整个链接过程,以产生用户所需要的文件。一般有以下这三种方法:
- 使用命令行来给链接器指定参数,比如使用 ld 的-o、-e等参数就是这种方法
- 将链接指令存放到目标文件里面,编译器经常会通过这种方法向链接器传递指令。比如VISUAL C++编译器会把链接参数放在 PE 目标文件的.drectve段来传递参数
- 使用链接控制脚本,这种方法最为灵活、最为强大
5.2 链接脚本详解
这里就偷个懒,关于链接脚本如何使用等内容,读者可以自行查阅相关资料。链接脚本可单独作为一个章节后面讲解。
6、 BFD 库
不同的平台可能有不同的目标文件格式,即使同一个格式比如 ELF 在不同的软硬件平台都有着不同的变种。种种差异导致编译器和链接器很难处理不同平台之间的目标文件,特别是对于像 GCC 和 binutils 这种跨平台的工具来说,最好有一种统一的接口来处理这些不同格式之间的差异。
Binary File Descriptor library。BFD库是一个 GNU 项目,它的目标是希望通过一个统一的接口来处理不同的目标文件。BFD项目本身是 binutils 项目的一个子项目。BFD 把目标文件抽象成一个统一模型,比如在这个抽象模型中,最开始有一个描述整个目标文件总体信息的“文件头”,就跟我们实际的 ELF 文件一样,文件头后面是一系列的一段,每个段都有名字、属性和段的内容,同时还抽象了符号表、定位表、字符串表等类似的概念,使得 BFD 库的程序只要通过这个抽象的目标文件模型就可以实现操作所有 BFD 支持目标文件格式。
现在 GCC (更具体是GAS, GNU Assembler)、链接器ld、调试器 GDB 及 binutils 的其他工具都通过 BFD 库来处理目标文件,而不是直接操作目标文件。这样做的最大好处就是将编译器和链接器同具体的文件格式隔离开来。一旦我们需要支持一种新的目标文件格式,只须在 BFD 库中添加一种格式就可以了,而不需要修改编译器和链接器。
7、静态链接的顺序问题
链接器使用直接读取可重定位目标文件和静态库的方法完成链接工作。符号解析阶段,链接器会从左到右按照它们在编译器驱动程序命令行上出现顺序来扫描可重定位目标文件和静态库文件。在扫描的整个周期中,链接器会维护一个可重定位目标文件的集合(集合E中的文件最终会被合并起来形成可执行文件)。一个未解析的符号表U (即集合E中的目标文件中引用了符号,但集合E中所有目标文件都未定义该符号) ,以及已定义的符号集合D (即集合E中的所有目标文件中定义的符号集合) 。在扫描初始阶段,集合E、U和D都是空的。
对于命令行上的每个输入文件 f ,链接器会判断 f 是目标文件还是静态库。
- 如果 f 是目标文件,那么链接器把 f 添加到E,将文件 f 中的符号定义和引用(该引用在D中没有定义)分别添加到集合 D 和集合 U 中,并继续下一个输入文件。
- 如果 f 是静态库文件,那么链接器就尝试匹配 U 中未解析的符号和静态库成员定义的符号。静态库匹配顺序就是静态库的打包顺序,可使用 nm 指令查看静态库顺序。如果静态库文件中某个目标文件成员 m,定义了一个符号来解析 U 中的一个引用,那么就将目标文件 m 加入到 E 中,并且将 m 中的符号定义和引用 (该引用在集合D中不存在) 分别添加到集合 D 和集合 E 中。对于静态库文件中所有的成员目标文件都依次进行这个过程,并且循环多次直到集合 U 和 D 都不再发生变化。此时,静态库文件中任何不包含在 E 中的成员目标文件都会被直接丢弃,而链接器将继续处理下一个目标文件或库文件。
如果当链接器完成对命令行上输入文件的扫描后,U是非空的,那么链接器将会输出一个错误并终止。否则它会合并和重定位E中的目标文件,构建输出的可执行文件。
由上可知,GCC链接时对依赖库/目标文件的顺序是敏感的,是因为在解析过程中,先被解析的文件中定义的所有符号如果没有被集合E中的目标文件引用到 (即使一个符号被引用,也会添加到E中) ,该文件会被直接丢弃,而在后续文件中即使再有该符号的引用,但已经找不到该符号的定义了,所以链接器会报错。解决这一问题的方法一般是调整好依赖顺序,或者将所有的库文件打包成一个单独的库文件。
针对链接顺序的问题,gcc 也给出了两个可能的解决方法。
GCC传递给链接器 ld 可以同时使用 Xlinker 和 Wl 两种命令,这两个命令都可以正确传递给 ld 作为使用
- 使用 --whole-archive。链接参数“–whole-archive”来告诉链接器,将后面库中所有符号都链接进来(也就是不会丢弃库里面的任何目标文件),参数“-no-whole-archive”则是重置,以避免后面库的所有符号被链接进来。
- 使用 -Xlinker。Xlinker主要是解决静态库循环依赖问题。链接器在处理 “-(” 和 “-)” 之间的静态库时,是会重复查找这些静态库的,所以就解决了静态库查找顺序问题。不过,这种方式比人工提供了链接顺序的方式效率会低很多。例如:
liba.a 依赖 libb.a,同时,libb.a 依赖 liba.a
gcc main.cpp -Xlinker "-(" libb.a liba.a -Xlinker "-)"
在linux下,我们可以使用 man ld 来查看 ld 链接器的一些参数含义
-( archives -)
--start-group archives --end-group
The archives should be a list of archive files. They may be either
explicit file names, or -l options.
The specified archives are searched repeatedly until no new
undefined references are created. Normally, an archive is searched
only once in the order that it is specified on the command line.
If a symbol in that archive is needed to resolve an undefined
symbol referred to by an object in an archive that appears later on
the command line, the linker would not be able to resolve that
reference. By grouping the archives, they all be searched
repeatedly until all possible references are resolved.
Using this option has a significant performance cost. It is best
to use it only when there are unavoidable circular references
between two or more archives.