基于Python+Pytest+Selenium的自动化测试之PO模式简介
在实际的软件研发过程中,往往会存在项目时间紧张、待测工作量大,待测的功能点较多,但是团队测试人员有限,难以全部测试覆盖的问题。针对问题,我们可以通过自动化测试去解决一些测试工作中遇到的实际问题,把一些工作写成代码,交给机器去处理和执行,解放测试人员,让代码帮助人去执行测试,从而达到提升测试效率的目的。而以低成本的方式选择合适的自动化测试框架,并且在项目中解决一些实际问题,就显得尤为重要。
本文结合笔者的一些实践,将基于Python+Pytest+Selenium的自动化测试实践简要总结,做一些介绍。
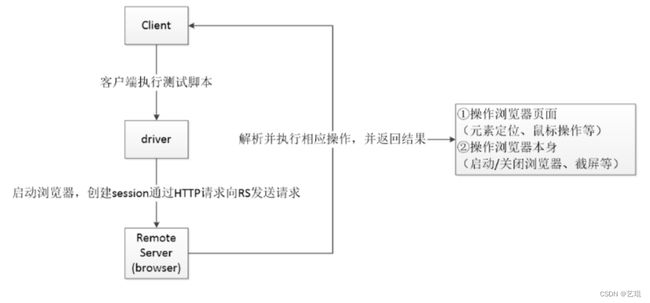
测试脚本启动浏览器驱动(driver)时,Selenium WebDriver会启动相应的浏览器,启动完成后,WebDriver会将浏览器绑定到特定端口形成一个浏览器实例,测试脚本创建session通过HTTP请求向远程控制服务器(Remote Server,简称RS)发送请求,由RS进行解析并完成相应操作并返回结果
二、环境要求
◆Python:3.0以上版本
◆安装selenium:pip3 install selenium
◆安装Chrome浏览器及chromedriver(放在python的主目录中)
三、基于python使用pytest+selenium框架下PO模式测试框架
1、PO模式简介
◆Page Object Model 页面对象模型,用来管理维护一组页面元素的对象库
◆在PO下,应用程序的每一个页面都有一个对应的Page类
◆每一个Page类维护着该页面的元素集和操作这些元素的方法


2、PO模式解读
官网:https://github.com/SeleniumHQ/selenium/wiki/PageObjects
- The public methods represent the servives that the page offers
◆使用公共方法来代表页面提供的服务
◆基类(基础服务:页面的基础的操作:点击元素、输入内容等)
◆页面类:登录,不同页面中增删改查等方法 - Try not to expose the internals of the page
◆避免暴露页面的内部细节,比如元素定位值、元素的定位方法等,隔离测试用例与业务层面和页面对象 - Generally don’t make assertions
◆PO本身通常不应进行判断或断言,判断和断言为测试的一部分,应始终在测试的代码内,而不是在PO中,PO用来包含页面的表示形式,以及页面通过方法提供的服务,但是与PO无关的测试代码不应包含其中 - Methods return other PageObjects
◆方法返回其他页面对象,进行页面间的关联
例如:登录→首页 首页→其他页面。 - Need not represent an entire page
◆PO不一定需要代表整个页面,定义所需要实现的业务部分,也可用于表示页面上的组件,若在自动化测试的页面中包含多个组件,每个组件都有单独的页面对象,可提高可维护性 - Different results for the same action are modelled as different methods
◆相同的操作(不同的数据)带来的不同的结果可以封装为不同的方法
3、项目架构
◆common:公共模块,如基类、定位器、浏览器
◆configs:项目配置等
◆docs:项目文档
◆outFiles:logs、reports、screenshots
◆pageObject:页面对象
◆testCases:测试用例
◆testDatas:测试数据
◆utils:工具模块
4、基类的封装
◆获取浏览器方法get_driver()
◆通过参数控制浏览器的默认类型(兼容性测试)
◆通过参数控制浏览器的模式,有头/无头
◆通过参数控制隐式等待时间
◆单例实现(参数化登录用例避免打开多个页面后进行)
◆元素定位:存储在yaml文件中
以类名区分页面,将对应页面元素定位存储在类名下,在basePage中定义不同页面对应不同元素
◆操作页面元素方法:
- 定位单个元素get_element
- 定位多个元素get_elements
- 在元素上输入文本(添加清除已有内容)
- 点击元素
- 获取单个元素文本(添加异常保护)
- 获取多个元素文本
- 点击元素加入等待时长(需要在页面刷新/切换等场景下使用)
5、操作层pageObject
- loginPage:定义打开页面、登录页面方法→返回mainpage页面类
- mainPage:定义主页面进入到不同页面中的方法
→不同页面类返回当前页面类 - otherPage:其他页面类,类中包含功能方向操作方法
6、业务层——测试用例
-
将文件、数据存储在yaml文件或excel表格中
-
利用数据驱动获取数据并传参
-
编写测试用例,可用allure.step添加测试步骤说明
-
进行断言,验证所有的测试结果是否符合预期结果
7、生成报告 -
在cmd中pip install allure
-
在测试用例中import allure、import os
-
运行时添加生成测试报告用例pytest.main([‘-sv’, ‘–alluredir’, ‘./report’])
-
可指定报告存储的位置,例如存储在当前文件夹中:
os.system(‘allure generate ./report -o ./report/report --clean’)