clickhouse分布式查询降级为本地查询
在基于 clickhouse 做类数仓建模时通常的做法是在本地创建物化视图,然后使用分布式表做代理对外提供服务。我们知道 clickhouse 对于 DQL 内部实现了分布式,而对于 DDL 则需要我们自动实现比如:
drop table table_name on cluster cluster_name;
来实现分布式 DDL,但对于
select count() from distributed_table_name;
此类分布式表的查询会自动执行分布式查询并在查询入口节点汇总最终数据,即 MPP 架构。
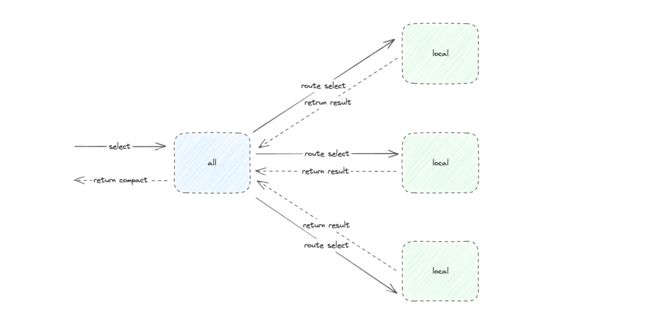
在 clickhouse 中本地表通常以 local 结尾,而代理它们的分布式表通常以 all 结尾(只是规范)
但在一些特殊情况下,上述的分布式查询会降级为本地查询,此时对分布式表的查询会随机路由到一张代理的本地表中导致该 SQL 的返回结果在反复横跳即为诡异

一、问题复现
1.1 知识点复习
这里先复习一下本文所涉及到的知识点或概念:副本和分片
在 clickhouse 中用户可以将所有节点按照自己的需求组成不同应用场景的集群,可以将所有节点组成一个单一集群也可以划分成多个小集群。副本和分片的区别在于:
- 从功能层面说:副本是防止数据丢失,增加数据冗余;分片是实现数据的水平切分,提高查询效率
- 从数据层面说:副本之间的数据是完全相同的;分片之间的数据是完全不同的
clickhouse 目前支持副本的表引擎只有 MergeTree Family,其格式为 Replicated*MergeTree,同时副本表需要依赖 zookeeper 实现个节点数据同步的协同工作,这里配置集群、zookeeper以及复制表是如何工作的就不做过多介绍。集群的信息通过下面的命令查看
select * from system.clusters;
结果如下

创建复制表需要在原 MergeTree 表的基础上额外指定 zookeeper 路径(分片信息)和副本信息
engine = ReplicatedMergeTree(path:String, replica:String [, columns:any])
path一致表示它们是同一个分片,后面的 replica 标记为不同的副本,通常 replica 填写本机 ip 或主机名
下面创建一个 3 分片 2 副本的 MergeTree 表作为本次问题复现的 ODS 表
create table event_local on cluster cluster
(
ldtime Datetime,
ip IPv4
) engine = ReplicatedMergeTree('/clickhouse/tables/default/{shard}/event_local', '{replica}')
order by ldtime
partition by toYYYYMMDD(ldtime);
说明:
{shard}和{replica}是 clickhouse 的宏,在配置文件中指定的可以通过下面的 sql 查看
select *
from system.macros;
结果如下

同时 path 也存在一定的约束,通常是/clickhouse/tables/数据库名称/分片编号/表名
on cluster cluster是标记该 DDL 为分布式 DDL 且最后的 cluster 为集群名称上面截图所示,因此该 DDL 语句会被发送到 cluster 的集群中所有节点去执行,省去了我们手动去各个节点执行的步骤。同时该分布式 DDL 也会展示所有节点的响应,执行 SQL 的入口节点会等待所有节点创建完将信息返回用户(默认最大等待时间为 180s,超过后会转入后台进行)
当然也可以使用 remote 查询所有节点宏信息
select *
from remote('chi-settings-01-cluster-0-0', 'system', 'macros', 'username', 'password')
where macro in ('replica', 'shard')
union all
select *
from remote('chi-settings-01-cluster-0-1', 'system', 'macros', 'username', 'password')
where macro in ('replica', 'shard')
union all
select *
from remote('chi-settings-01-cluster-1-0', 'system', 'macros', 'username', 'password')
where macro in ('replica', 'shard')
union all
select *
from remote('chi-settings-01-cluster-1-1', 'system', 'macros', 'username', 'password')
where macro in ('replica', 'shard')
union all
select *
from remote('chi-settings-01-cluster-2-0', 'system', 'macros', 'username', 'password')
where macro in ('replica', 'shard')
union all
select *
from remote('chi-settings-01-cluster-2-1', 'system', 'macros', 'username', 'password')
where macro in ('replica', 'shard');
随机向三个分片中写入一定量的数据,可以观察副本数据的同步
# chi-settings-01-cluster-0-0
insert into event_local
values (toDateTime('2023-07-01 00:00:00'), '192.168.0.1'),
(toDateTime('2023-07-01 00:00:00'), '192.168.0.1'),
(toDateTime('2023-07-01 00:00:00'), '192.168.0.1'),
(toDateTime('2023-07-02 00:00:00'), '192.168.0.2');
# chi-settings-01-cluster-1-1
insert into event_local
values (toDateTime('2023-07-03 00:00:00'), '192.168.0.3'),
(toDateTime('2023-07-03 00:00:00'), '192.168.0.3'),
(toDateTime('2023-07-04 00:00:00'), '192.168.0.4');
# chi-settings-01-cluster-2-0
insert into event_local
values (toDateTime('2023-07-05 00:00:00'), '192.168.0.5'),
(toDateTime('2023-07-06 00:00:00'), '192.168.0.6');
根据分片的特性 event 全量数据应该是各个分片的 compact 因此我们需要一张分布式表来代理所有的副本分片表
create table event_all
(
ldtime Datetime,
ip IPv4
) engine = Distributed('{cluster}', 'default', 'event_local', rand());
rand() 为分片健,当数据通过分布式表写入时,会根据分片健将数据写入不同的分片中。分片健要求是一个整型数值,可以是表字段或返回整型的函数。
注:生产中分布式表通常只做查请求,不做写请求。因为如果对分布式表执行写请求每条数据都需要在 clickhouse 中计算所属分片效率不高,建议的做法是业务测做”分库分表“将数据直接写入对应的本地表不让 clickhouse 来做自动分片。
1.2 复现问题
对 event_all 查询结果如下
select * from event_all order by ldtime;
2023-07-01 00:00:00,192.168.0.1
2023-07-01 00:00:00,192.168.0.1
2023-07-01 00:00:00,192.168.0.1
2023-07-02 00:00:00,192.168.0.2
2023-07-03 00:00:00,192.168.0.3
2023-07-03 00:00:00,192.168.0.3
2023-07-04 00:00:00,192.168.0.4
2023-07-05 00:00:00,192.168.0.5
2023-07-06 00:00:00,192.168.0.6
该 SQL 是执行了分布式查询,对于副本表 clickhouse 会按照一定策略读取其中一个副本读取数据,具体的副本表读写流程不是这篇文章重点。下面开始复现问题
简化一下需求,实时统计每个 ip 出现的个数。正常数仓可能会这么做
create materialized view mv_ip_count
engine = SummingMergeTree(num)
order by ip
populate
as
select ip, count() as num
from event_all
group by ip;
192.168.0.1,3
192.168.0.2,1
192.168.0.3,2
192.168.0.4,1
192.168.0.5,1
192.168.0.6,1
这样的结果是没有问题的,但是生产中不是所有的需求都可以这么做。因为之所以创建分布式表是因为数据量很大,需要做分片。那么对于处理后的数据量依然很大的需求我们就不能通过查询分布式表来创建物化视图,因为这样做该物化视图所有的数据都会存储在该节点上。
为了解决这个问题就需要各个节点去统计自己存储在本地的数据,然后再创建一张分布式表对外提供统一的服务,sql 如下
create materialized view mv_ip_count_local on cluster cluster
engine = SummingMergeTree(num)
order by ip
populate
as
select ip, count() as num
from event_local
group by ip;
create table mv_ip_count_all
(
ip IPv4,
num UInt64
) engine = Distributed('{cluster}', 'default', 'mv_ip_count_local', rand());
当我们用 mv_ip_count_all 进行二次聚合时
select sum(num) from mv_ip_count_all;
其值在 4、3、2 间反复横跳,正确答案应该是 9。这就很纳闷了
二、问题解决
这种情况定位出来就是触发了本地查询,反复横跳的数据是各个节点本地查询结果。产生这个问题的原因是下面这个 sql
create materialized view mv_ip_count_local on cluster cluster
engine = SummingMergeTree(num)
order by ip
populate
as
select ip, count() as num
from event_local
group by ip;
首先这个 sql 会被分布式执行,但是 event_local 它是一个副本表,该 sql 执行结束后每个节点都会有一张毫无关联的 SummingMergeTree 表,此时我们又创建了分布式表来代理,造成的后果就是分布式表的数据量暴增 n 倍,n 为副本个数。
当我们基于分布式表做二次聚合时,clickhouse 或许也发现了这个问题,如果按照正常的 mpp 架构来执行这个 sql 得到的结果就是正确个数的 n 倍,显然这样错误的结果是 clickhouse 无法接受的,因此它将分布式 sql 降级为本地 sql 如文章开头的图二流程。
或许 clickhouse 觉得这样的错误结果比 mpp 流程得到的结果要更容易接受吧,虽然这两个结果都存在问题
分析到这里解决方案也就浮出水面了,就是让 SummingMergeTree 保持和 event_local 一样的副本分片关系即可,即创建具有副本功能的 SummingMergeTree 表
create materialized view mv_ip_count_local
on cluster cluster
engine = ReplicatedSummingMergeTree('/clickhouse/tables/default/{shard}/mv_ip_count_local', '{replica}', num)
order by ip
as
select ip, count() as num
from event_local
group by ip;
分布式表正常创建即可,最终问题解决。
三、总结
出现这个问题本质上是对 clickhouse 的副本分片表、分布式表不熟练,同时 clickhouse 在赋予用户极高自由度的同时也给用户带来了很多心智负担。clickhouse 分布式表还存在很多错误的使用方式,例如基于分布式表做聚合或连接操作时存在大坑,这点后面有时间可以单独出一篇博客来说明。虽然在使用过程中产生过很多匪夷所思的结果,但当分析完原因并成功解决后又会觉得 clickhouse 这么做很合理,它依然是一款极其优秀且强大的 olap 数据库