初识mysql数据库之索引操作
目录
一、索引的查看
二、主键索引
1. 创建主键索引
2. 删除主键索引
3. 主键索引的特点
三、唯一键索引
1. 创建唯一键索引
2. 删除唯一键索引
3. 唯一键索引的特点
四、普通索引
1. 创建普通索引
2. 删除普通索引
3. 普通索引的特点
五、复合索引
1. 复合索引的概念
2. 复合索引的创建
3. 复合索引的作用
4. 索引最左匹配原则
六、索引创建规则
一、索引的查看
当创建好索引后,我们当然要知道我们到底有没有成功创建索引。因此, 在创建索引前,我们先来看看如何查看索引。要查看索引有三种方法,分别是"show key from 表名;"、"show index from 表名;“和“desc 表名;”。其中第三种方法看到的信息比较简略。前两种方法看到的信息都是一样的。

当我们查看索引后,就可以看到如上信息。这些数据中的重要信息都在上图中标识好了。假设我们现在有如下表:
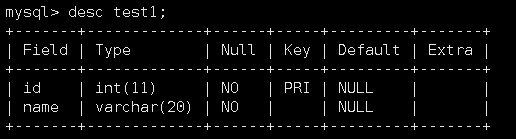
查看它的索引信息:
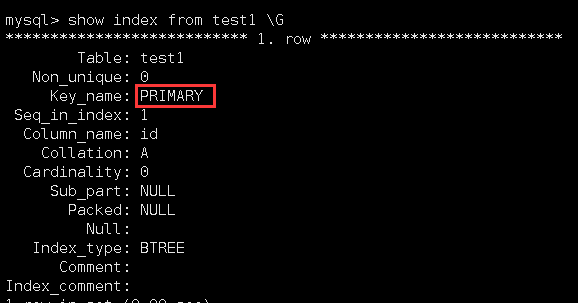
可以看到,它当前就有一个主键索引。
二、主键索引
对于什么是主键索引,在上一篇文章“理解索引”中已经解释过了,这里就不再赘述。
1. 创建主键索引
要创建主键索引很简单,当在表中的某列添加primary key属性时,mysql就会自动将这一列的数据视为key值,然后根据这一列的数据来构建索引。
因此,根据添加primary key的不同时机,就分为三种创建方式:

在这里面,前两种方式都没什么可说的,但是第三种方式就可以介绍一下。现在有如下一个test1表没有主键索引:
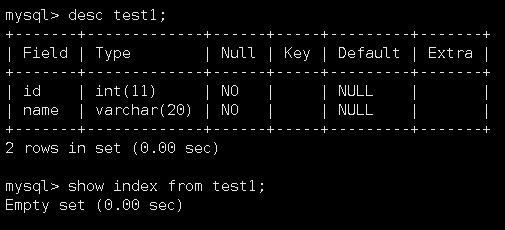
这个表当前是已经创建好了的。因此,我们再向它添加primary key属性:
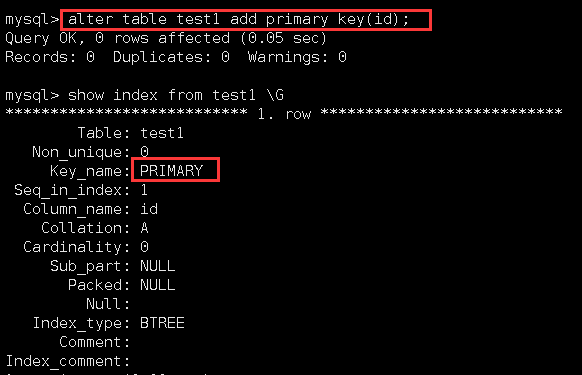
可以看到,当向表添加了primary key属性后,它就自动拥有了主键索引。
2. 删除主键索引
我们知道,主键索引其实就是用带有primary key属性的列数据当key值。因此,要删除主键索引,只需要将primary key属性去掉即可。即直接使用“alter table 表名 drop primary key;”指令删除表的primary key即可删除主键索引。
以上文中的test1表为例,删除它的主键,然后查看索引信息:
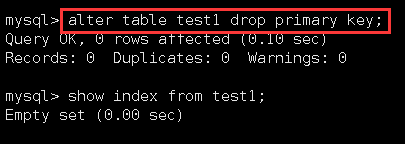
此时就什么都没有了。
3. 主键索引的特点
主键索引的特点,基本上就是主键的特点。
(1)一个表中,最多有一个主键索引。
(2)主键索引的效率高(主键不可重复)。
(3)创建主键索引的列,它的值不能为null,且不能重复。
(4)主键索引的列基本上是int。
除了最后一个特点,其他三个特点其实就是主键的特点衍生而来的。
三、唯一键索引
1. 创建唯一键索引
大家应该知道,在一个表中,除了用primary key可以给列添加主键外,还可以用unique或unique key给列添加唯一键。因此,所谓的唯一键索引,其实就是表内的数据带有唯一键,将带有唯一键属性的列作为key值构建B+树。
和主键索引一样,创建唯一键索引的方式有三种:

和主键差不多,唯一键索引也是在你对某列数据添加唯一键属性后,mysql就会自动以该列数据为key值构建B+树。前两种方式我们都比较熟悉了,这里介绍一下第三种方法。
准备如下一个test1表:
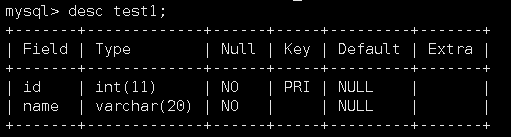
在这个表中已经带有一个主键索引了。我们再给name列添加唯一键:

添加完后查看它的索引信息:
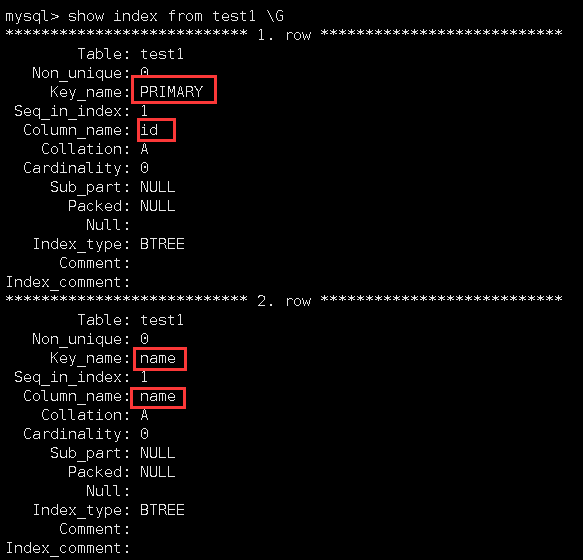
可以看到,此时test1表就有了两个索引,一个是主键索引,以id列为索引;另一个是唯一键索引,以name列为索引。在上一篇文章中介绍过一个表示可以拥有多个索引的,这里就不再过多介绍。
2. 删除唯一键索引
要删除唯一键索引,就不是和删除主键索引那样可以直接删除unique(name)了:

可以看到,出现了报错。
要删除唯一键索引,就需要使用“alter table 表名 drop index 唯一键索引名”:

注意,drop index后面跟着的是唯一键索引名,即Key_name后面的名字,而不是Column_name后面的名字:
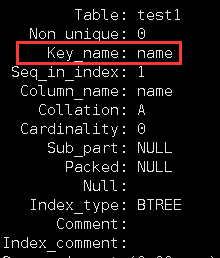
3. 唯一键索引的特点
唯一键索引的特点和唯一键的特点是差不多的:
(1)一个表中,可以有多个唯一键索引。对应一个表中可以有多个唯一键。
(2)查询效率高。
(3)如果在某一列建立唯一键索引,必须保证这列不能有重复数据。对应有唯一键属性的列数据不能重复。
(4)如果一个唯一键索引上指定not null,等价于主键索引。
四、普通索引
1. 创建普通索引
普通索引,其实就是对不带有键属性的列设置索引。设置方法同样有三种:

第一种方法和主键索引与唯一键索引是一样的,不同的是将键换成了index。不过多介绍。
第二种方法就是在表创建后通过alter语句添加索引。这里介绍一下。准备好如下一张test1表:
用alter语句给name列添加普通索引:
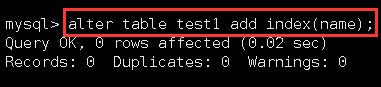
添加完后,查看它的索引信息:
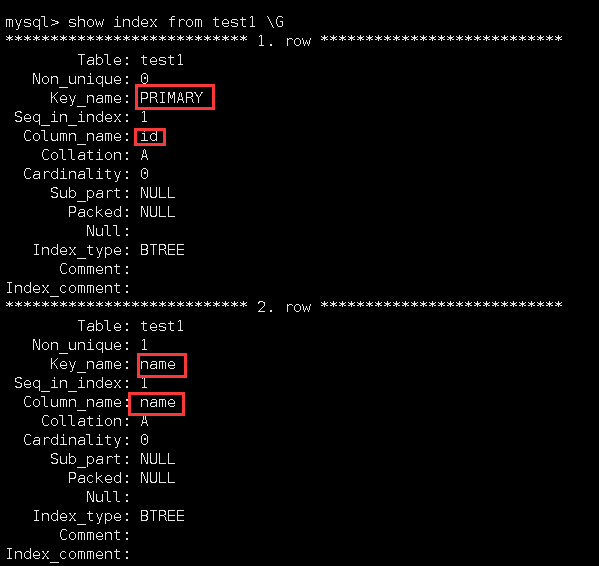
同样是两个索引。其中第一个是主键索引,原因就是这张表内原来就带有主键。第二个就是普通索引。不再过多解释。
第三种方法也是在表创建好后用的,语法其实就是“create index 指定索引名 on 表名(列名);”这种方法可以给普通索引指定一个索引名字:

查看它的索引信息:
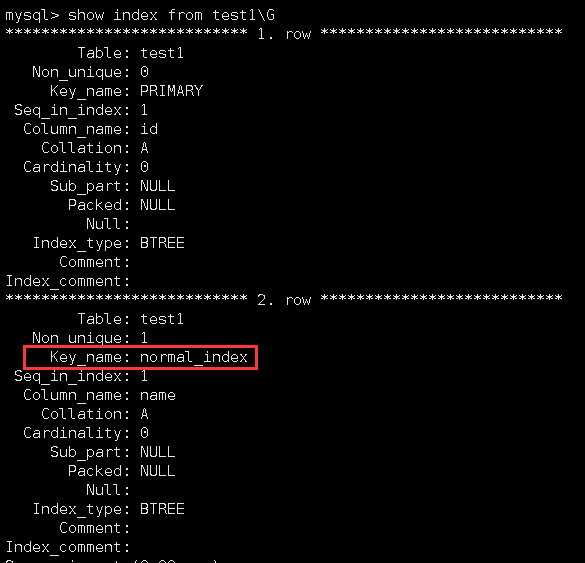
可以看到,此时的索引名就是我们刚刚指定的名字。
2. 删除普通索引
删除普通索引的方法和删除唯一键索引的方法是一样的,都是“alter table 表名 drop index 索引名;”

到这里大家应该可以发现,唯一键索引和普通索引在查看索引信息的内容和删除索引的方式上都是一样的。因此我们说,唯一键索引其实就是比较特殊的普通索引。区别只是唯一键索引会对数据的唯一性有要求,而普通索引则对列数据没有唯一性要求。
3. 普通索引的特点
(1)一个表中可以有多个普通索引。普通索引在实际开发中用的比较多。
(2)普通索引中作为key值的列数据允许重复。如果某些需要创建索引,但是该列有重复值,就应该使用普通索引。
五、复合索引
1. 复合索引的概念
如果我们遇到某种情况,需要我们将多列数据看成一个整体创建索引,是否可行呢?答案当然是可行的。因此,复合索引其实就是将多列数据看做一个整体创建出来的索引,它的本质依然是普通索引。
2. 复合索引的创建
以普通索引为例。我们先准备如下一个test1表:
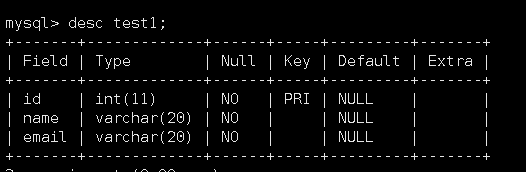
在这个表中,name和email列都没有设置索引。我们现在就将这两列看成一个整体设置索引:

查看它的索引信息:
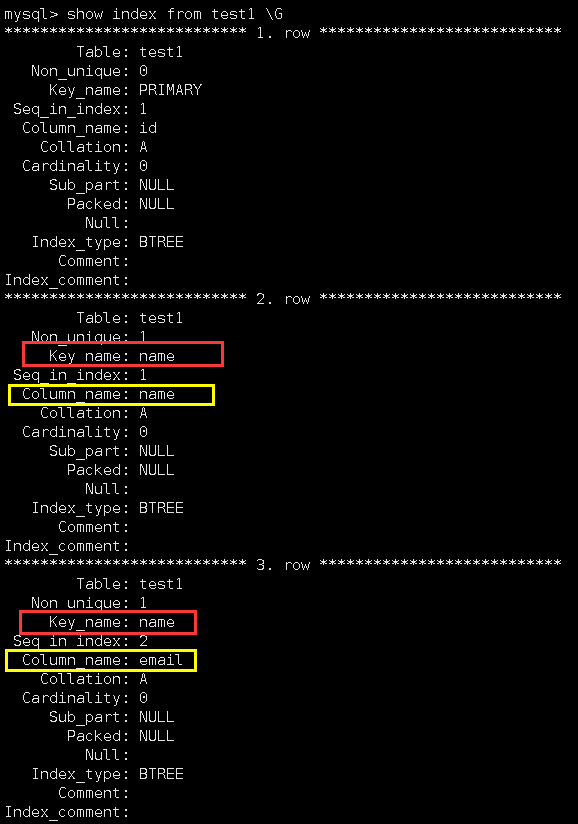
可以看到,此时就查看到了三张索引信息。但是大家要注意,在这两张索引信息中,虽然使用的列不同,但是它们的索引名都是name。这就意味着,在用多个列作为一个索引时,是默认用写在index后面的括号内的第一列充当列名的。如果删除这个列名,就会将这个索引整体删除:
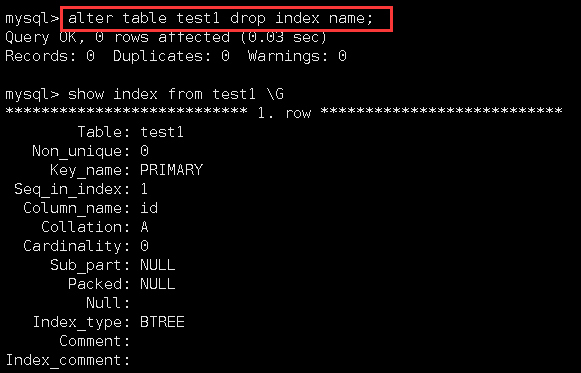
此时就只剩一个主键索引了。
通过上面的例子大家就应该可以发现,在用多个列充当一个索引时,其实只创建了棵B+树,这个B+树中的key值其实就是这些列的数据组合。
3. 复合索引的作用
此时有人可能就会疑惑了,这个复合索引有什么用呢?大家知道,如果一个表中在有主键索引的情况下创建普通索引,这个普通索引中的叶子节点内除了用于构建B+树的key值外,就是主键值,用于在需要时到主键索引中找数据。同时我们也知道,在一个没有主键索引的表中,mysql会默认生成一份主键索引用于构建B+树,因此,无论有没有主动用primary key,表中都必然存在primary key,区别只是在于是否看得到和是否能显式的用。
因此,表中的普通索引所构建的B+树中是必然只有key值和主键值。假设有如下一张test1表:
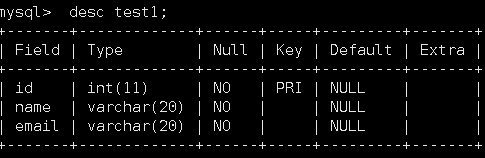
如果用name列构建普通索引,当我们搜索以name为条件搜索数据且只需要name时,mysql就是到name的B+树中拿到对应的key值然后返回;但如果在要name的同时,还需要email的数据,此时就会触发回调查询,mysql会通过name构建的B+树的叶子节点内保存的主键值跳转到主键值构建的B+树内找对应数据。很明显,这里就会有一个效率损耗。
但如果用name和email同时作为索引构建B+树,当需要name的数据时,mysql就会到它们构建的B+树中搜索并直接返回key值中的name;而如果既需要name有需要email,mysql同样是到B+树中搜索key值并返回。此时就省去了回调查询,提高了查询效率。
4. 索引最左匹配原则
在使用复合索引时要注意一个点,那就是用复合查询构建的B+树在比对key值的时候,是从左往右比对。
这就意味着,如果你构建索引时是按照“name,email”的顺序填入index的括号内的话,你在到这个B+树中查询数据时,name可以匹配key值;name + email也可以匹配key值;但是email就无法匹配key值,因为email无法与key值中的最左值name相匹配。
这就是索引最左匹配原则。
六、索引创建规则
(1)比较平凡作为查询条件的字段应该创建索引。
(2)唯一性太差的字段不适合单独创建索引,即使它可能频繁作为查询条件。
(3)更新非常频繁的字段不适合创建索引。更新频繁就意味着索引中的key值也需要频繁更新,降低效率。
(4)不会出现在where子句中的字段不应该用于创建索引。索引的目的就是快速查询,如果某些字段完全不会出现在where中,即意味着它很少别作为查询条件,就算它的数据的重复率很低,也不应该创建索引。
总的来讲,就是高频率出现,低频率被修改,唯一性很好的列,就很适合作为索引。