MQ公共特性介绍 (ActiveMQ, RabbitMQ, RocketMQ, Kafka对比)
本章介绍
本文主要介绍所有MQ框架都具备的公共特点,同时对比了一些目前比较主流MQ框架的优缺点,给大家做技术选型作参考。
文章目录
-
- 本章介绍
- MQ介绍
- 适用场景
-
- 异步通信
-
- 案例一
- 案例二
- 系统解耦
- 削峰填谷
- 广播通信
- 总结
- 缺点
- MQ对比
- APQP
-
- 历史
- AMQP是什么
MQ介绍
MQ,MessageQueue,消息中间件
从世界上第一个MQ的诞生历程来看,它最初是为了解决通信的问题。
消息队列,又叫做消息中间件。是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。
基于以上的描述,MQ具备几个主要特点:
1、是一个独立运行的服务。生产者发送消息,消费者接收消费,需要先跟服务器建立连接。
2、采用队列作为数据结构,有先进先出的特点。
3、具有发布订阅的模型,消费者可以获取自己需要的消息。
我们可以把MQ类比成邮局和邮差,它是用来帮我们存储和转发消息的。
适用场景
也可以认为是MQ的优势或者优点。
异步通信
同步的通信是什么样的?
发出一个调用请求之后,在没有得到结果之前,就不返回。由调用者主动等待这个调用的结果。
而异步是相反的,调用在发出之后,这个调用就直接返回了,所以没有返回结果。也就是说,当一个异步过程调用发出后,调用者不会马上得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
案例一
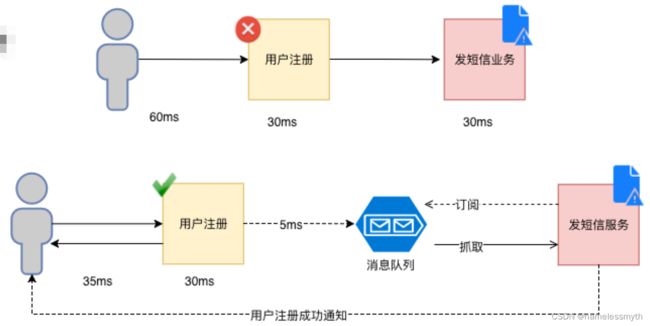
如下图:用户注册和发短信是2个服务,如果分别要30ms,使用同步的方式用户需要等待60ms,才会返回成功。
但如果使用了MQ,假设往MQ发送消息是5ms,那用户只需要等待35ms即可完成业务。
案例二
大家都用过手机银行的跨行转账功能。大家用APP的转账功能的时候,有一个实时模式,有一个非实时模式。
实时转账实际上是异步通信,因为这个里面涉及的机构比较多,调用链路比较长,本行做了一些列的处理之后,转发给银联或者人民银行的支付系统,再转发给接收行,接受行处理以后再原路返回。
所以转账以后会有一行小字提示:具体到账时间以对方行处理为准,也就是说转出行只保证了这个转账的消息发出。那为什么到账时间又这么快呢?很多时候我们转账之后,不用几秒钟对方就收到了。是因为大部分的MQ都有一个低延迟的特性,能在短时间内处理非常多的消息。
很多理财软件提现也是一样,先提交请求,到账时间不定。这个是用MQ实现系统间异步通信的一个场景。
异步通信不需要客户端等待,可以减少客服端性能消耗,大大地提升用户体验。
系统解耦
要将解耦,首先要理解什么是系统耦合。耦合是系统内部或者系统之间存在相互作用,相互影响,相互依赖。
在分布式系统中,一个业务流程涉及多个系统的时候,他们之间就会形成一个依赖关系。
以上面的注册功能为例,如果短信功能异常了,例如:欠费了,将引起用户注册失败,这就一种强耦合或者说依赖关系。
以12306网站退票为例,在传统的通信方式中,订单系统发生了退货的动作,那么要依次调用所有下游系统的API,比如调用库存系统的API恢复库存,因为这张火车票还要释放出去给其他乘客购买;调用支付系统的APIl,不论是支付宝微信还是银行卡,要把手续费扣掉以后,原路退回给消费者;调用通知系统API通知用户退货成功。
这个过程是串行执行的,如果在恢复库存的时候发生了异常,那么后面的代码都不会执行。由于这一系列的动作,恢复库存,资金退还,发送通知,本质上没有一个严格的先后顺序,也没有直接的依赖关系,也就是说,只要用户提交了退货的请求,后面的这些动作都是要完成的。库存有没有恢复成功,不影响资金的退还和发送通知。
如果把串行改成并行,我们有什么思路?
(多线程)
多线程或者线程池是可以实现的,但是每一个需要并行执行的地方都引入线程,又会带来线程或者线程池的管理问题。
所以,这种情况下,我们可以引入MQ实现系统之间依赖关系的解耦合引入MQ以后
订单系统只需要把退货的消息发送到消息队列上,由各个下游的业务系统自己创建队列,然后监听队列消费消息。
1、如果其他系统做了网络迁移,以前需要在订单系统配置和修改IP、端口、接口地址,现在不需要,因为它不需要关心消费者在网络上的什么位置,只需要配置MQ服务器的地址。
2、如果某一个下游系统宕机了或者在停机升级,调用接口超时会导致订单系统业务逻辑失败。引入MQ以后没有任何影响,消息保存在MQ服务器,什么时候下游系统恢复了自己去消费就OK了。
3、假如下游业务系统运行正常,但是消费出了问题,比如改代码该出问题了或者数据库异常,生产者也不会受到影响。因为它只关心一件事情,就是消息有没有成功地发送到MQ服务器。
(如果要确保消费成功或者确保数据一致性肯定要靠其他的手段来解决,后面会说)引入MQ以后,实现了系统之间依赖关系的解耦,系统的可扩展性和可维护性得到了提升。
削峰填谷
在很多的电商系统里面,有一个瞬间流量达到峰值的情况,比如京东的618,淘宝的双11,可能会达到百万甚至千万级的并发。普通的硬件服务器一般只能支撑大概200~500的并发,然后就会向最初的12306一样,动不动就服务器崩溃。
如果通过堆硬件的方式去解决,那么在流量峰值过去以后就会出现巨大的资源浪费。那要怎么办呢?一个饭店,在国庆期间一天有几万个人想去吃饭,为什么它不马上扩张门店呢?它的实际做法是什么?首先肯定不能拒绝顾客,说没位置了回家吧(排队啊)。
如果说要保护我们的应用服务器和数据库,限流也是可以的,但是这样又会导致订单的丢失,没有达到我们的目的。
为了解决这个问题,我们就可以引入MQ。MQ既然是Queue,一定有队列的特性,
我们知道队列的特性是什么?
(先进先出FIFO)
先进先出,有一个排队的模型。这个饭店它就有排队的通道,不会因为想吃饭的人太多了就把饭店鸡煲或者把服务员累趴。而且它还可以线上排队,你都不用一直站着。
我们可以先把所有的流量承接下来,转换成MQ消息发送到消息队列服务器上,业务层就可以根据自己的消费速率去处理这些消息,处理之后再返回结果。
如果要处理快一点,大不了就是增加几个消费者。就像火车站在春运期间会多开几个窗口处理购票请求。
广播通信
也叫数据分发,用于实现一对多通信。以订单系统退货为例,如果新增了积分系统,需要获取订单状态变化信息,只需要增加队列监听就可以了,生产者没有任何代码修改。
使用MQ做数据分发好处,无论是新增系统,还是移除系统,代码改造工作量较小。所以使用MQ做数据的分发,可以提高团队开发的效率。
总结
-
对于数据量大或者处理耗时长的操作,我们可以引入MQ实现异步通信,减少客户端的等待,提升响应速度,优化客户体验。
-
对于改动影响大的系统之间,可以引入MQ实现解耦,减少系统之间的直接依赖,提升可维护性和可扩展性。
-
对于会出现瞬间的流量峰值的系统,我们可以引入MQ实现流量削峰,达到保护应用和数据库的目的。
-
一对多的广播通信
缺点
对于一些特定的业务场景,MQ对于优化我们的系统性能还是有很大的帮助的。我们讲了这么多好处,以后只要是系统之间通信我全部用MQ,不再考虑HTTP接口和RPC调用,可以吗?
肯定不行。下面我们分析一下使用MQ会带来的一些问题。
第一个就是运维成本的增加。既然要用MQ,必须要分配资源部署MQ,还要保证它时刻正常运行。
第二个是系统的可用性降低。原来是两个节点的通信,现在还需要独立运行一个服务。虽然一般的MQ都有很高的可靠性和低延迟的特性,但是一旦网络或者MQ服务器出现问题,就会导致请求失败,严重地影响业务。
第三个是系统复杂性提高。作为开发人员,要使用MQ,首先必须要理解相关的模型和概念,才能正确地配置和使用MQ。其次,使用MQ发送消息必须要考虑消息丢失和消息重复消费的问题。一旦消息没有被正确地消费,就会带来数据一致性的问题。
所以,我们在做系统架构,选择通信方式的时候一定要根据实际情况来分析,不要因为我们说了这么多的MQ能解决的问题,就盲目地引入MQ。
MQ对比
Kafka、ActiveMQ、RabbitMQ、RocketMQ 有什么优缺点?
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,相对其他MQ较低。 | 万级,同ActiveMQ | 10 万级,支撑高吞吐 | 10 几万级,吞吐量非常高,甚至有文献称,可以达到单机百万级TPS。 |
| topic 数量对吞吐量的影响 | topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,延迟最低RabbitMQ 的一大特点 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失。支持事务 | 同 RocketMQ。支持事务 |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
| 资料文档 | 多。没有专门写activemq的书,网上资料多 | 多。有一些不错的书,网上资料多 | 少。没有专门写rocketmq的书,网上的资料良莠不齐,官方文档很简洁,但是对技术细节没有过多的描述 | 中,有kafka作者自己写的书,网上资料也有一些 |
| 开发语言 | java | Erlang | java | Scala+Java |
| 支持协议 | OpenWire、STOMP、REST、XMPP、AMQP | AMQP | 自定义 | 自定义(基于TCP) |
| 消息存储 | 内存、磁盘。支持少量堆积 | 磁盘。支持大量堆积 | 内存、磁盘、数据库。支持大量堆积 | |
| 集群方式 | 支持简单集群模式,比如’主-备’,对高级集群模式支持不好 | 支持简单集群,'复制’模式,对高级集群模式支持不好 | 常用多对’Master-Slave’ 模式,开源版本需手动切换Slave变成Master | 天然的‘Leader-Slave’无状态集群,每台服务器既是Master也是Slave |
APQP
历史
因为世界上第一个MQTIB实现了发布订阅(Publish/Subscribe)模型,消息的生产者和消费者可以完全解耦,这个特性引起了电信行业特别是新闻机构的注意。1994年路透社收购了Teknekron。
TIB的成功马上引起了业界大佬IBM的注意,他们研发了自己的IBM MQ (IBMWesphere——人民银行主导研发的二代支付系统用的就是IBM MQ)。后面微软也加入了这场战斗,研发了MSMQ。这个时候,每个厂商的产品是孤立的,大家都有自己的技术壁垒。比如一个应用订阅了IBM MQ的消息,如果有要订阅MSMQ的消息,因为协议、API不同,又要重复去实现。为什么大家都不愿意去创建标准接口,来实现不同的MQ产品的互通呢?跟现在微信里面不能打开淘宝页面是一个道理(商业竞争)。
JDBC协议大家非常熟悉吧?J2EE制定了JDBC的规范,那么那么各个数据库厂商自己去实现协议,提供jar包,在Java里面就可以使用相同的API做操作不同的数据库了。MQ产品的问题也是一样的,2001年的时候,SUN公司发布了JMS规范,它想要在各大厂商的MQ上面统一包装一层Java的规范,大家都只需要针对API编程就可以了,不需要关注使用了什么样的消息中间件,只要选择合适的MQ驱动。但是JMS只适用于Java语言,它是跟语言绑定的,没有从根本上解决这个问题(只是一个API)。
所以在2004年,几个大公司开始开发AMQP标准。2006年,AMQP规范发布了。
AMQP是什么
AMQP的全称是:Advanced Message Queuing Protocol,高级消息队列协议。本质上是一种进程间传递异步消息的网络协议。它是跨语言和跨平台的,不管是什么样的MQ服务器,不管是什么语言的客户端,只要遵循AMQP协议,就可以实现消息的交互。真正地促进了消息队列的繁荣发展。
AMQP是一个工作于应用层的协议,最新的版本是1.0版本。可以使用 WireShark等工具对RabbitMQ通信的AMQP协议进行抓包。
既然它是一种协议或者规范,不是RabbitMQ专门设计的,市面上肯定还有很多其他实现了AMQP协议的消息中间件,比如: OpenAMQ、 Apache Qpid、RedhatEnterprise MRG、AMQP Infrastructure、OMQ、Zyre。

既然它是一种协议或者规范,不是为某一种MQ框架专门设计的,市面上肯定还有很多其他实现了AMQP协议的消息中间件,比如:
OpenAMQ、Apache Qpid、Redhat、Enterprise MRG、AMQP Infrastructure、∅MQ、zyre。