推荐系统环境搭建
推荐系统环境搭建
- 一、Hadoop伪分布式搭建
-
- 1、 环境配置
-
- 1.1、配置jdk
- 1.2、修改主机名
- 2 、安装Hadoop
-
- 2.1、上传并解压Hadoop
- 2.2 、免密配置
- 2.3 、配置Hadoop配置文件
- 2.4 、启动伪集群
- 二、flume安装部署
-
- 1、上传并解压 flume
- 2、修改配置
- 3、配置flume
- 三、Kafka安装部署
-
- 1、安装部署zookeeper
-
- 1.1、上传并解压 zookeeper
- 1.2、配置环境变量
- 1.3、启动zookeeper
- 2、部署Kafka
-
- 2.1、上传并解压 Kafka
- 2.2、修改配置
- 2.3、配置环境变量
- 2.4、启动zookeeper
-
- 2.3、启动Kafka
- 2.5、测试
- 四、flume连接Kafka
-
- 1、修改flume配置
- 2、启动flume
- 3、启动kafka的消费者看是否接收到flume传输的数据
一、Hadoop伪分布式搭建
1、 环境配置
1.1、配置jdk
(1)版本jdk1.8.0_181
(2)将 JDK 导入到 /home/zx/opt 目录下面的 software 文件夹下面
(3)解压 JDK 到/home/zx//opt/module 目录下
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /home/zx/opt/module/
(4)配置 JDK 环境变量
- 在/etc/profile.d/目录下创建my_env.sh
- 在my_env.sh中添加如下内容
#JAVA_HOME
#JAVA_HOME
export JAVA_HOME=/home/zx/opt/module/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
- source 一下/etc/profile 文件,让新的环境变量 PATH 生效
source /etc/profile
- 测试 JDK 是否安装成功
java -version
出现以下画面就是成功

1.2、修改主机名
# 1. 修改主机名
sudo hostnamectl set-hostname zengxi
# 2. 编辑/etc/hosts文件 使新主机名与内部ip对应
vim /etc/hosts
2 、安装Hadoop
2.1、上传并解压Hadoop
(1)版本hadoop-2.7.5
(2)将 hadoop 导入到 /home/zx/opt 目录下面的 software 文件夹下面
(3)解压 hadoop 到/home/zx//opt/module 目录
tar -zxvf hadoop-2.7.5.tar.gz -C /home/zx/opt/module/
(4)配置 JDK 环境变量
- 在my_env.sh中添加如下内容
#HADOOP_HOME
export HADOOP_HOME=/home/zx/opt/module/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
记得重新运行 source /etc/profile 命令
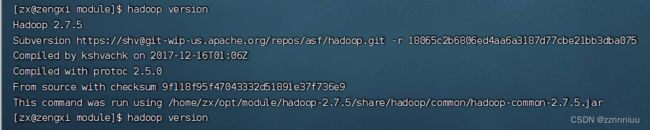
(5)查看hadoop是否安装成功
hadoop version
2.2 、免密配置
(1)生成公钥和私钥
ssh-keygen -t rsa
#然后一直敲回车就行
(2)然后复制密钥到本机
cd /home/zx/.ssh
ssh-copy-id localhost
此时 ssh localhost 就不用使用密码了
2.3 、配置Hadoop配置文件
(1)配置hadoop-env.sh ,主要是配置java的环境变量
cd $HADOOP_HOME/etc/hadoop
# 修改export JAVA_HOME=${JAVA_HOME}为export JAVA_HOME=/home/zx/opt/module/jdk1.8.0_181

(2)配置core-site.xml
vim core-site.xml
# 配置如下内容
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://zengxi:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zx/opt/module/hadoop-2.7.5/data/tmp</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>zx</value>
</property>
</configuration>
(3)开始配置hdfs-site.xml
vim hdfs-site.xml
# 配置如下内容
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>zengxi:50070</value>
</property>
<!-- 设置副本数为1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(4)开始配置 yarn-site.xml
vim yarn-site.xml
# 配置如下内容
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(5)配置 mapred-site.xml
# 将mapred-site.xml.template 修改为mapred-site.xml
vim mapred-site.xml
# 配置如下内容
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.4 、启动伪集群
(1)格式化namenode 注意:第一次启动才需要
hdfs namenode -format
(2)启动 HDFS
cd /home/zx/opt/module/hadoop-2.7.5/sbin
./start-dfs.sh
(3)启动yarn
./start-yarn.sh
(4)启动全部
./start-all.sh
(5)查看是否启动成功
jps

访问http://ip:50070可出现如下画面
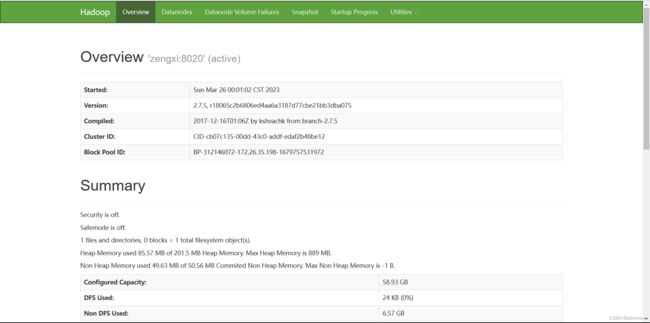
访问http://ip:8088可出现如下画面

二、flume安装部署
1、上传并解压 flume
(1)版本apache-flume-1.9.0-bin
(2)将 flume导入到 /home/zx/opt 目录下面的 software 文件夹下面
(3)解压 flume到/home/zx//opt/module 目录
tar -zxvf apache-flume-1.9.0-bin -C /home/zx/opt/module/
2、修改配置
(1)进入apache-flume-1.9.0-bin/conf 下
(2)将flume-env.sh.template 重命名为 flume-env.sh
(3)编辑flume-env.sh 文件 将export JAVA_HOME=/home/zx/opt/module/jdk1.8.0_181
cd apache-flume-1.9.0-bin/conf
mv flume-env.sh.template flume-env.sh
vim flume-env.sh
#一下为 flume-env.sh 文件编辑内容
export JAVA_HOME=/home/zx/opt/module/jdk1.8.0_181
(4)检查flume是否安装成功
cd apache-flume-1.9.0-bin
bin/flume-ng version
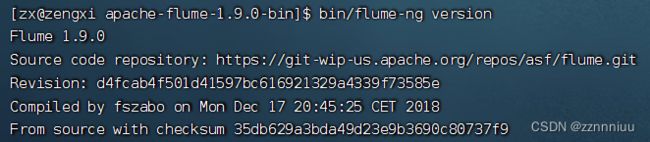
出现以下内容就是安装成功
3、配置flume
(1)创建flume-conf.properties文件
vim flume-conf.properties
# 以下为 flume-conf.properties 内容
#agent中各组件的名字
##表示agent中的source组件
a1.sources = r1
##表示的是下沉组件sink
a1.sinks = k1
##agent内部的数据传输通道channel,用于从source将数据传递到sink
a1.channels = c1
#描述和配置source组件:r1
##netcat用于监听一个端口的
#a1.sources.r1.type = netcat
##配置的绑定地址,这个机器的hostname是master,所以下面也可以配置成master
#a1.sources.r1.bind = master
##配置的绑定端口
#a1.sources.r1.port = 44444
# TAILDIR 是用于监听文件变化
a1.sources.r1.type = TAILDIR
#偏移量文件
a1.sources.r1.positionFile = /home/zx/opt/module/apache-flume-1.9.0-bin/data/taildir_position.json
#文件的组,可以定义多种
a1.sources.r1.filegroups = f1 f2
#第一组监控的是test1文件夹中的什么文件:.log文件
a1.sources.r1.filegroups.f1 = /home/zx/website/logs/.*log
#第二组监控的是test2文件夹中的什么文件:以.txt结尾的文件
a1.sources.r1.filegroups.f2 = /home/zx/website/logs/.*txt
#a1.sources.r1.type = exec
#a1.sources.r1.command = tail -F /home/zx/website/logs/test.log
#a1.sources.r1.shell = /bin/sh -c
#描述和配置sink组件:k1
a1.sinks.k1.type = logger
##描述和配置channel组件,此处使用时内存缓存的方式
#下面表示的是缓存到内存中,如果是文件,可以使用file的那种类型
a1.channels.c1.type = memory
#表示用多大的空间
a1.channels.c1.capacity = 1000
#下面表示用事务的空间是多大
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系,因为source和sink依赖channel来传递数据,所以要分别指定用的是哪个channel。
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(2)启动flume
cd apache-flume-1.9.0-bin
bin/flume-ng agent -c conf -f conf/flume-conf.properties -n a1 -Dflume.root.logger=INFO,console
![]()
控制台打印出了test.log的内容
(3)向test.log 中添加内容,看flume是否能采集到
echo "b" >> test.log
echo "c" >> test.log

采集成功
三、Kafka安装部署
Kafka部署分单节点单Broker部署、单节点多Broker部署、集群部署多节点多Broker)
1、安装部署zookeeper
Kafka强依赖zookeeper,如果想要使用Kafka,就必须安装zookeeper,因为是单节点的Kafka,所以在安装zookeeper时也只需要单节点即可。但kafka3.0之后自带zookeeper,不需要自己安装zookeeper
1.1、上传并解压 zookeeper
注意:如果安装Kafka在3.0之后无需做此步
(1)版本zookeeper-3.4.6.tar.gz
(2)将 zookeeper导入到 /home/zx/opt 目录下面的 software 文件夹下面
(3)解压 zookeeper到/home/zx//opt/module 目录
tar -zxvf zookeeper-3.4.6.tar.gz -C /home/zx/opt/module/
(4)进入zookeeper的conf目录下
(5)拷贝zoo_sample.cfg文件重命名为zoo.cfg,然后修改dataDir属性
cd conf/
cp zoo_sample.cfg zoo.cfg
(6)修改zoo.cfg
vim zoo.cfg
#以下为修改内容
# 数据的存放目录
dataDir==/home/zx/opt/module/zookeeper-3.4.6/data
# 端口,默认就是2181
clientPort=2181
1.2、配置环境变量
sudo vim /etc/profile.d/my_env.sh
# start 在my_env.sh 中添加的内容
# ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/home/zx/opt/module/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# end
source /etc/profile
1.3、启动zookeeper
zkServer.sh start # 启动命令
zkServer.sh stop # 停止命令
验证是否启动成功
jps -m

zookeeper启动成功·
2、部署Kafka
2.1、上传并解压 Kafka
(1)版本 kafka_2.12-3.0.2
(2)将 Kafka导入到 /home/zx/opt 目录下面的 software 文件夹下面
(3)解压 Kafka到/home/zx//opt/module 目录
tar -zxvf kafka_2.12-3.0.2 -C /home/zx/opt/module/
2.2、修改配置
(1)进入kafka的config目录下,有一个server.properties,修改配置如下
cd config/
vim server.properties
# 以下为server.properties中的配置
# 监听
#listeners=PLAINTEXT://:9092
# 允许外部端口连接
listeners=PLAINTEXT://0.0.0.0:9092
# 配置外部代理地址,便于远程访问
advertised.listeners=PLAINTEXT://ip:9092
# 日志目录
log.dirs=/home/zx/opt/module/kafka_2.11-0.11.0.0/logs
# 配置zookeeper的连接(如果不是本机,需要该为ip或主机名)
zookeeper.connect=localhost:2181
2.3、配置环境变量
sudo vim /etc/profile.d/my_env.sh
# start 在my_env.sh 中添加的内容
# KAFKA_HOME
export KAFKA_HOME=/home/zx/opt/module/kafka_2.11-0.11.0.0
export PATH=$PATH:$KAFKA_HOME/bin
# end
source /etc/profile
2.4、启动zookeeper
# 启动kafka中的zookeeper(后台启动)
zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties
# 停止zookeeper
zookeeper-server-stop.sh
2.3、启动Kafka
# 前台启动命令
kafka-server-start.sh $KAFKA_HOME/config/server.properties
# 后台启动
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
# 停止命令
kafka-server-stop.sh

启动成功
2.5、测试
#创建topic kafka3
kafka-topics.sh --create --topic test1 --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
#创建topic kafka3以前版本
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test1
#删除topic
kafka-topics.sh --delete --bootstrap-server localhost:9092 --topic name
#查看topic
kafka-topics.sh --list --bootstrap-server localhost:9092
#生产消息
kafka-console-producer.sh --topic test1 --bootstrap-server localhost:9092
#消费消息
kafka-console-consumer.sh --topic test1 --from-beginning --bootstrap-server localhost:9092
若能成功生产消息和消费消息即安装成功


成功生成消费
四、flume连接Kafka
1、修改flume配置
vim flume-conf.properties
#注释掉
#描述和配置sink组件:k1
#a1.sinks.k1.type = logger
#增加
# KAFKA_sinks
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = recommender
a1.sinks.k1.brokerList = localhost:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
2、启动flume
cd apache-flume-1.9.0-bin
# 前台启动
bin/flume-ng agent -c conf -f conf/flume-conf.properties -n a1 -Dflume.root.logger=INFO,console
# 后台启动
nohup bin/flume-ng agent -c conf -f conf/flume-conf.properties -n a1 -Dflume.root.logger=INFO,console &
3、启动kafka的消费者看是否接收到flume传输的数据
# 查看flume是否启动
jps -m
#消费消息
kafka-console-consumer.sh --topic test1 --from-beginning --bootstrap-server localhost:9092