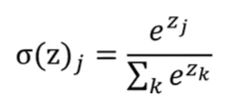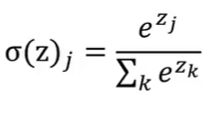人工智能 - 机器学习 - 深度学习概述
1. 人工智能
① 人工智能的四要素:数据、算法、算力、场景
人工智能的子领域:机器学习、计算机视觉、语音识别、机器人、数据挖掘、计算机图形学、人机交互
可视化、数据库技术、多媒体技术、知识工程、自然语言处理、信息检索与推荐
② 计算机视觉研究的主题:图像分类,目标检测、图像分割、目标跟踪、文字识别和人脸识别等。
算法开发框架:TensorFlow、Pytorch、PaddlePaddle、MindSpore;
Tensorflow 2.0正式版集成Keras 作为其高阶APl,由于其易移植性在工业界的应用广泛。
Pytorch 由于其易用性得到学术界的广泛认可;
2. 机器学习
① 机器学习解决的主要问题
分类:输入(标签值),构建模型输出是离散的类别值;比如图像分类
回归:给定输入,预测输出数值,输出是连续数值;比如预测证券价格、天气变化
聚类:大量未知标注的数据集,根据之间的相似度划分类别;比如图像检索、电商用户图像
② 机器学习分类
有监督学习:已知类别的样本,构建最优模型,对未知数据进行分类;例如分类,回归
无监督学习:算法对没有标记的样本直接进行建模,对于新来的样本按照相似程度进行归类;例如聚类
半监督学习:试图让学习器自动地对大量未标记数据进行利用以辅助少量有标记数据进行学习
强化学习:模型从环境到行为映射的学习,模型感知环境并做出行动,以使强化信号函数值最大;例如阿尔法狗
③ 机器学习的整体流程
数据收集:数据集(ImageNet),训练集,测试集,验证集(搜索模型最优的超参数)
数据清洗(脏数据):数据清理(数据清理),数据标准化(减少噪声),数据降维(简化数据不必要属性)
特征提取与选择:过滤法(filter),包装器(wapper),嵌入法(Embedded)
模型训练:机器学习分类
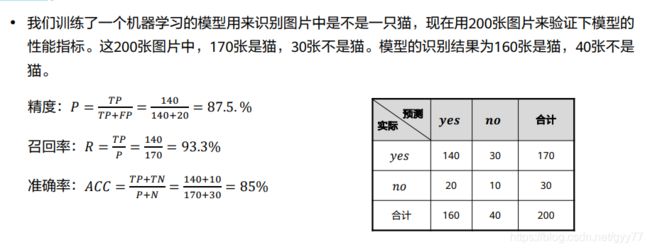
模型评估测试:回归:MAE,MSE,R2
分类:TP,TN,FP,FN(精度,召回率,准确率,错误率)
模型部署与整合:适用于新样本的能力称为泛化能力,也称为鲁棒性
训练误差:模型在训练集上的误差
泛化误差:在新样本上的误差
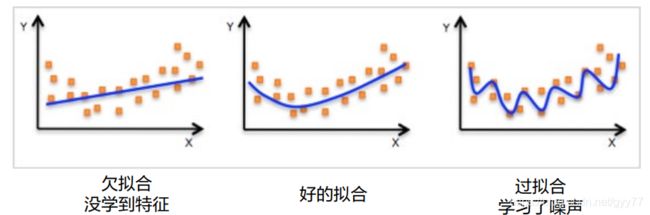
欠拟合:如果训练误差很大的现象
过拟合:训练误差很小而泛化误差较大的现象
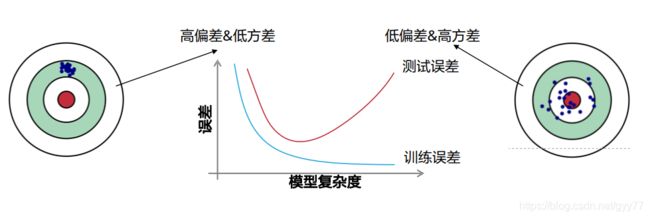
总误差:偏差2 + 方差 + 不可消解的误差
方差:模型在训练集上对小波动的敏感性的误差
偏差:模型的预测值与我们试图预测的正确值之间的差异

④ 机器学习训练方法
梯度下降:训练误差最低
,批量梯度下降BGD,随机梯度下降SGD,小批量梯度下降MBGD
超参数Batch:超参数由人工手动设定,参数有模型自动学习;
例如:训练神经网络的学习速率、迭代次数、批次大小、激活函数、神经元的数量
Lasso/Ridge回归当中的λ,支持向量机的c和σ超参数,KNN中的k,随机森林当中的树的棵数
超参数的调节方法:网格搜索:00 01 02 10 11 12 20 21 22 昂贵耗时
随机搜索:找出最佳超参数子集
交叉验证:训练集分为训练集和验证集;训练集对分类器进行训练,验证集测试模型(为了调节超参数)
k - 折交叉验证(K - CV):k组数据(k-1组训练集、1组验证集),得到k个模型,k也属于超参数
⑤ 机器学习的常见算法
有监督学习:分类、回归、逻辑回归、线性回归、SVM、神经网络、决策树、随机森林、GBDT、KNN、朴素贝叶斯
无监督学习:聚类、K-means、层次聚类、密度聚类、关联规则、PCA、GMM
线性回归:模型函数w b:
损失函数:
;多线性回归解决欠拟合:
; 正则项解决过拟合:
.
逻辑回归:
;加入了激活函数SoftMax概率之和为1:
决策树:叶子节点为决策结果:
;算法有ID3,C4.5,CART
SVM(支持向量机):点、直线、平面、超平面分割;核函数的内积相同(线性核函数、多项式函数、高斯核函数、Sigmoid核函数)
KNN(K最邻近算法):分类预测(多数表决法),回归预测(平均值法);K值越大越容易欠拟合,K值越小越过拟合
朴素贝叶斯:已知先验概率,去计算后验概率;P雨、P(伞/雨) -》 P(雨/伞)
举个栗子:
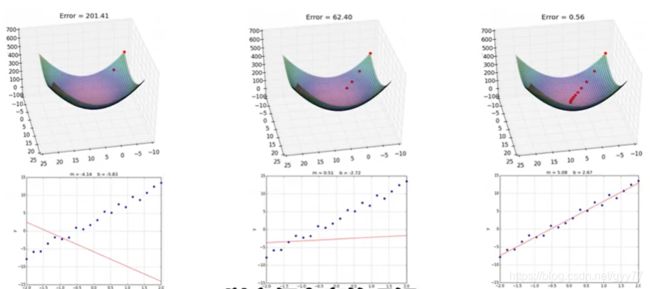
做一个回归任务,输入x房屋面积,输出y房屋价格,需要求出一元线性回归函数:
,首先构建损失函数的值最小:
,接着梯度下降算法通过迭代法(设置学习率和超参数)找到函数最小值
;
如果出现过拟合,我们可以使用带有正则项的LASSO回归或者Ridge回归,并调节超参数。
如果是欠拟合,我们可以使用更加复杂的回归模型,比如GBDT。

3. 深度学习
① 损失函数:通过梯度下降算法找到损失函数最小值
全局梯度下降算法(BGD):收敛特慢不常用
随机梯度下降算法(SGD):虽然快但容易陷入局部最小值
小批量梯度下降算法(MBGD):用一小批量更新w,b
激活函数:实现了神经网络的非线性表达能力
Sigmoid函数:存在梯度消失问题
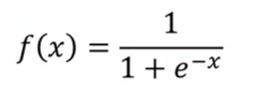
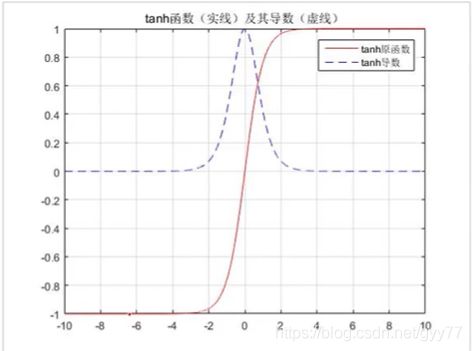
tanh函数:存在梯度消失问题
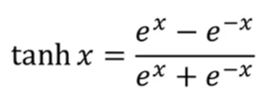
Softsign函数:存在梯度消失问题
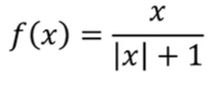
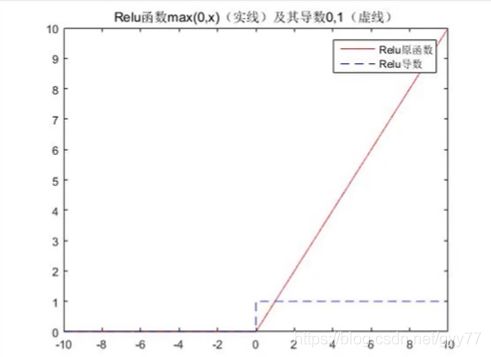
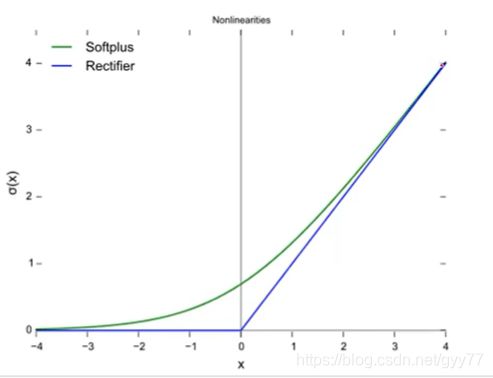
Rectified Linear Unit(ReLU)函数:特征选择;折点处做回归问题时不能更好的预则值
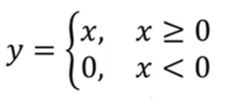
Softplus函数:对ReLU的不足进行更新
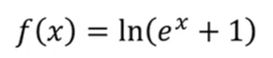
Softmax函数:经常用作多分类任务的输出层;每个输出结果取值都介于(0,1),总和为1
正则化:防止过拟合
L1正则:
,能够产生更加稀疏的模型,可以做特征选择,相当于拉普拉斯分布
L2正则:
,服从高斯先验分布
数据集合扩充:目标识别:将图片旋转缩放;语音识别:添加噪声;自然语言处理NLP:近义词替换;
Dropout:集成方法,随即丢弃输入样本
提前停止:当发现验证集数据的损失函数Loss上升时,提前停止迭代次数
优化器:加快算法收敛速度;避过局部极值;减小手工参数的难度找到最佳参数
动量优化器:
,0≤a<1 成为动量,学习率r以及动量α仍需手动设置
Adagrad优化器:
学习率自动更新;但分母变大会提前停止训练的模型
RMSprop优化器:
对RNN网络效果很好, 解决了过早结束的问题
Adam优化器:
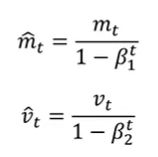
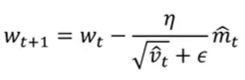
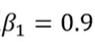
可以适当降低n
② 神经网络:由多个非常简单的处理单元彼此按某种方式相互连接而形成的计算机系统,该系统靠其状态对外部输入信息的动态响应来处理信息。
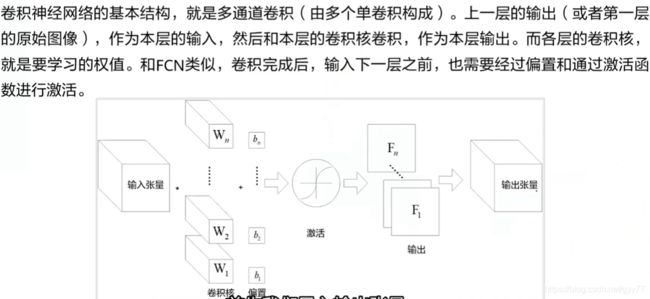
卷积神经网络CNN: 适合图像处理、识别、分类
卷积层:局部感知:局部像素联系较为紧密,局部信息综合起来就是全局信息
参数共享:卷积层中的卷积核扫描照片,卷积核参数固定不变
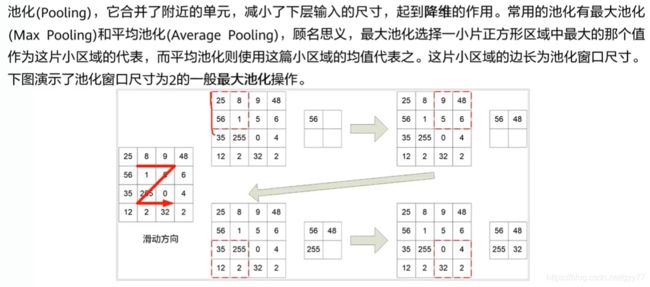
池化层:最大池化,平均池化
全连接层:分类器Softmax函数:
循环神经网络RNN:是一种通过隐藏层节点周期性;适合序列持续的数据,可以保存上下文数据
例如一帧帧图像组成的视频,一个个片段组成的音频存在梯度消失问题,对长时间记忆的信息会衰减
长短记忆网络LSTM:解决梯度消失问题,记忆单元中有tanh函数
GRU算法:解决梯度消失问题,比LSTM函数更少一些
生成对抗网络GAN:CNN和RNN对抗,生成器,判别器:图像生成、语义分割、文字生成、数据增强、聊天机器人信息检索
③ 常见问题
数据不平衡:各个类别的样本数目不均衡
梯度消失问题:梯度消失:当网络层数越多时,进行反向传播求导值越小,导致梯度消失。
梯度爆炸:当网络层数越多时,进行反向传播求导值越大,导致梯度爆炸。
解决方法:梯度剪切、正则、ReLu激活函数、LSTM神经网络
过拟合问题:模型在训练集表现优是但在测试集上表现较差