MySQL体系结构及执行过程
一、MySQL体系结构
1、网络连接层
客户端连接器(Client Cnnectors):提供支持与MySQL服务器建立连接。
建立连接命令:mysql -h -u -p
-h指定MySQL服务的IP 若本地连接则不需要每一个连接均会保存用户权限,中途修改权限没用。只有再新建的连接才会使用新的权限。
查看已连接MySQL的客户端具体信息:
show processlist
MySQL与HTTP一样分为短连接与长连接:
// 短连接
连接 mysql 服务(TCP 三次握手)
执行sql
断开 mysql 服务(TCP 四次挥手)
&缺点:需要频繁建立连接和断开连接
// 长连接
连接 mysql 服务(TCP 三次握手)
执行sql
执行sql
执行sql
....
断开 mysql 服务(TCP 四次挥手)
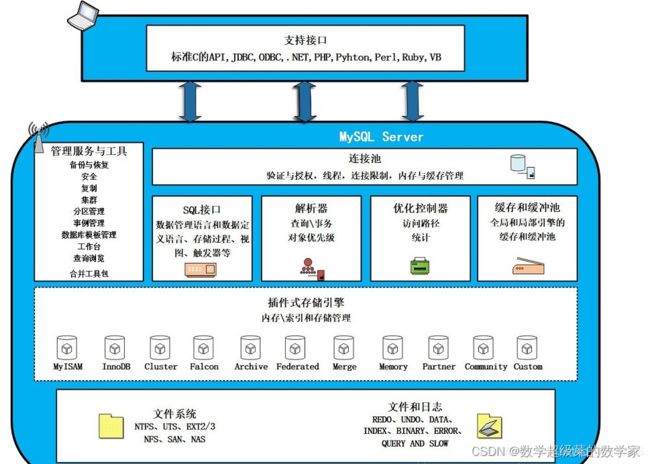
&缺点:长时间占用内存资源2、服务层(MySQL Server)
服务层执行过程:sql语句通过sql接口,服务器如果缓存cache有命中查询结果,直接读取数据。如果没有命中查询结果,由解析器进行sql语句的解析,预处理,经过优化器进行优化后提交给引擎层。通俗地说—>服务层告诉引擎层要做什么。
类比CPU先访问Cache,命中直接返回数据,不命中再访问主存。
连接池(Connection Pool)
存储和管理客户端与数据库的连接(再连接时-快),一个线程负责管理一个连接。
系统管理和控制工具(MS&U)
例如备份恢复、安全管理、集群管理等。
SQL接口(SQL Interface)
用于接收客户端发送的各种SQL命令,并且返回用户需要查询的结果。比如DML、DDL、存储过程、视图、触发器等。
解析器(Parser)
负责将请求的SQL解析生成一个"解析树"。然后根据MySQL规则进一步检查解析树是否合法。
*词法分析。MySQL 会根据你输入的字符串识别出关键字出来,构建出 SQL 语法树,这样方便后面模块获取 SQL 类型、表名、字段名、 where 条件等等。
*语法分析。根据词法分析的结果,语法解析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
查询优化器(Optimizer)
当“解析树”通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互。
此处已经是执行阶段:
- 预处理阶段:预处理器 检查SQL语句中表、字段是否存在;将*替换为所有列)
- 优化阶段:查询优化器 确定SQL语句查询方案。(如确定使用什么索引)
- 执行阶段:执行器 与存储引擎交互。有三种方式:
主键索引查询
全表扫描
索引下推
缓存(Cache&Buffer)
缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,权限缓存,引擎缓存等。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
3、存储引擎层
存储引擎层与底层系统文件交互,真正负责MySQL中数据存储与读取。如今默认innoDB。 记住MyISAM、innoDB、MEMORY三个就好了。

4、系统文件层
将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
二、SQL语句执行过程

- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将
select *中的*符号扩展为表上的所有列。 - 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
- 预处理阶段:检查表或字段是否存在;将
SQL的详细执行流程:数据库通常不会被单独使用,而是由其它编程语言通过SQL支持接口调用MySQL。由MySQL处理并返回执行结果。首先,其它编程语言通过SQL支持接口调用MySQL,MySQL收到请求后,会将该请求暂时放在连接池,并由管理服务与工具进行管理。当该请求从等待队列进入到处理队列时,管理器会将该请求传给SQL接口,SQL接口接收到请求后,它会将请求进行hash处理并与缓存中的数据进行对比,如果匹配则通过缓存直接返回处理结果;
否则,去文件系统查询:由SQL接口传给后面的解析器,解析器会判断SQL语句是否正确,若正确则将其转化为数据结构。解析器处理完毕后,便将处理后的请求传给优化器控制器,它会产生多种执行计划,最终数据库会选择最优的方案去执行。确定最优执行计划后,SQL语句交由存储引擎处理,存储引擎将会到文件系统中取得相应的数据,并原路返回。
对于更新比较频繁的表,查询缓存的命中率很低的,MySQL8.0后就不查询缓存了。 这里说的查询缓存是 server 层的,也就是 MySQL 8.0 版本移除的是 server 层的查询缓存,并不是 Innodb 存储引擎中的 buffer pool。
简化版:连接器处理连接 -> SQL接口接收SQL语句 -> 解析器解析SQL语句 ->
预处理器预处理 -> 查询优化器优化 -> 执行与存储引擎交互