LVS集群系统网络核心原理分析
http://blog.chinaunix.net/uid-20565550-id-303648.html
LVS文章荟萃
LVS集群技术
LVS集群技术
作者:FunBSD
最后更新:2005年5月18日目录
- Preface
- IPVS
- HeatBeat
- Ldirectord
- Patch
- Scripts
- Reference
Preface
集群技术主要分为三大类:
- 高可用性(High Available Cluster),例:Linux-HA
- 负载均衡(Load balancing Cluster),例:LVS、MOSIX
- 高性能计算(High Performance Computing),例:Beowulf
我们这里使用RedHat AS 3.x,LVS,Linux-HA,Ldirectord,构造一个高可用的负载均衡集群系统。如图:
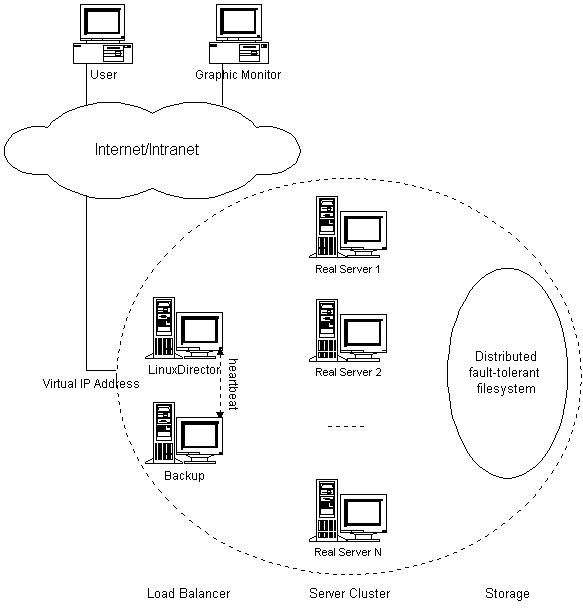
各层的作用:
- Load Balancer(负载均衡器):
Load Balancer是整个集群系统的前端,负责把客户请求转发到Real Server上。
Backup是备份Load Balancer,当Load Balancer不可用时接替它,成为实际的Load Balancer。
Load Balancer通过Ldirectord监测各Real Server的健康状况。在Real Server不可用时
把它从群中剔除,恢复时重新加入。 - Server Array(服务器群):
Server Array是一组运行实际应用服务的机器,比如WEB, Mail, FTP, DNS, Media等等。
在实际应用中,Load Balancer和Backup也可以兼任Real Server的角色。 - Shared Storage(共享存储):
Shared Storage为所有Real Server提供共享存储空间和一致的数据内容。
各服务器IP分配:
Virtual IP: 192.168.136.10 Load Balancer: 192.168.136.11 Backup: 192.168.136.12 Real Server 1: 192.168.136.101 Real Server 2: 192.168.136.102 Real Server 3: 192.168.136.103 IPVS
IPVS是LVS集群系统的核心软件,它的主要作用是:
- 安装在Load Balancer上,把发往Virtual IP的请求转发到Real Server上。
IPVS的负载均衡机制有三种,这里使用IP Tunneling机制:
- Virtual Server via NAT
- Virtual Server via IP Tunneling
- Virtual Server via Direct Routing
IPVS的负载调度算法有十种:
- 轮叫(Round Robin)
- 加权轮叫(Weighted Round Robin)
- 最少链接(Least Connections)
- 加权最少链接(Weighted Least Connections)
- 基于局部性的最少链接(Locality-Based Least Connections)
- 带复制的基于局部性最少链接(Locality-Based Least Connections with Replication)
- 目标地址散列(Destination Hashing )
- 源地址散列(Source Hashing)
- 最短期望延迟(Shortest Expected Delay)
- 无须队列等待(Never Queue)
IPVS安装主要包括三方面:
- 在Load Banlancer上安装IPVS内核补丁
- 在Load Banlancer上安装IPVS管理软件
- 在Real Server上安装ARP hidden内核补丁
关于如何编译内核请参考其他文档,这里使用从UltraMonkey下载的已编译好的内核。
在Load Banlancer、Backup和Real Server上使用同一内核,IPVS和ARP hidden都已编译在这个内核里:
wget http://www.ultramonkey.org/download/2.0.1/rh.el.3.0/RPMS/mkinitrd-3.5.13-1.um.1.i386.rpm wget http://www.ultramonkey.org/download/2.0.1/rh.el.3.0/RPMS/kernel-2.4.21-27.0.2.EL.um.1.i686.rpm wget http://www.ultramonkey.org/download/2.0.1/rh.el.3.0/RPMS/kernel-smp-2.4.21-27.0.2.EL.um.1.i686.rpm rpm -Fhv mkinitrd-3.5.13-1.um.1.i386.rpm rpm -Fhv kernel-2.4.21-27.0.2.EL.um.1.i686.rpm在Load Banlancer和Backup上安装IPVS管理软件:
wget http://www.linuxvirtualserver.org/software/kernel-2.4/ipvs-1.0.10.tar.gz
tar zxf ipvs-1.0.10.tar.gz
cd ipvs-1.0.10/ipvs/ipvsadm
make installchkconfig --del ipvsadm
配置IPVS(/etc/sysconfig/ipvsadm),添加Real Server:
-A -t 192.168.136.10:80 -s rr
-a -t 192.168.136.10:80 -r 192.168.136.11:80 -i
-a -t 192.168.136.10:80 -r 192.168.136.12:80 -i
-a -t 192.168.136.10:80 -r 192.168.136.101:80 -i
-a -t 192.168.136.10:80 -r 192.168.136.102:80 -i
-a -t 192.168.136.10:80 -r 192.168.136.103:80 -i相关链接:
Kernel:http://www.kernel.org/
IPVS和IPVSadm:http://www.linuxvirtualserver.org/software/ipvs.html
ARP hidden:http://www.ssi.bg/~ja/#hidden注意事项:
1. Kernel,IPVS,IPVSadm,ARP hidden之间的版本必须对应。
2. 自己编译内核时,从http://www.kernel.org/下载标准内核源文件,不要使用发行版的内核源文件。
3. Kernel 2.4.28和2.6.10及以上版本已内置IPVS,有些Linux发行版也在其内核里编译了IPVS。
4. ARP hidden可以用arp_ignore/arp_announce或者arptables代替HeartBeat
HeartBeat是Linux-HA的高可用性集群软件,它的主要作用是:
- 安装在Load Balancer和Backup上,运行于active/standby模式。
当Load Balancer失效时,Backup自动激活,成为实际的Load Balancer。 - 切换到active模式时,按顺序启动Virtual IP、IPVS和Ldirectord。
切换到standby模式时,按顺序关闭Ldirectord、IPVS和Virtual IP。
HeartBeat串口线连接测试方法:
在Load Balancer上:cat < /dev/ttyS0
在Backup上:echo hello > /dev/ttyS0
修改主机名(/etc/hosts):
127.0.0.1 localhost.localdomain localhost
192.168.136.11 loadbalancer
192.168.136.12 backup
安装:
groupadd -g 694 haclient
useradd -u 694 -g haclient hacluster
rpm -ivh /mnt/cdrom/RedHat/RPMS/glib2-devel-*
wget http://www.packetfactory.net/libnet/dist/libnet.tar.gz
tar zxf libnet.tar.gz
cd libnet
./configure
make
make install
wget http://www.linux-ha.org/download/heartbeat-1.99.4-tar.gz
tar zxf heartbeat-1.99.4.tar.gz
cd heartbeat-1.99.4
./ConfigureMe configure --disable-swig --disable-snmp-subagent
make
make install
cp doc/ha.cf doc/haresources doc/authkeys /etc/ha.d/
cp ldirectord/ldirectord.cf /etc/ha.d/
chkconfig --add heartbeat
chkconfig --del ldirectord主配置文件(/etc/ha.d/ha.cf):
#debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0
keepalive 2
deadtime 30
warntime 10
initdead 120
udpport 694
baud 19200
serial /dev/ttyS0
mcast eth0 225.0.0.1 694 1 0
# 当主节点恢复后,是否自动切回
auto_failback on
# stonith用来保证共享存储环境中的数据完整性
#stonith baytech /etc/ha.d/conf/stonith.baytech
# watchdog能让系统在出现故障1分钟后重启该机器。这个功能可以帮助服务器在确实停止心跳后能够重新恢复心跳。
# 如果使用该特性,则在内核中装入"softdog"内核模块,用来生成实际的设备文件,输入"insmod softdog"加载模块。
# 输入"grep misc /proc/devices"(应为10),输入"cat /proc/misc | grep watchdog"(应为130)。
# 生成设备文件:"mknod /dev/watchdog c 10 130" 。
#watchdog /dev/watchdog
node loadbalancer
node backup
# 默认heartbeat并不检测除本身之外的其他任何服务,也不检测网络状况。
# 所以当网络中断时,并不会进行Load Balancer和Backup之间的切换。
# 可以通过ipfail插件,设置'ping nodes'来解决这一问题。详细说明参考hearbeat文档。
#ping 192.168.136.1 172.16.0.1
ping_group group1 192.168.136.1 192.168.136.2
respawn root /usr/lib/heartbeat/ipfail
apiauth ipfail gid=root uid=root
# 其他一些插件可以在/usr/lib/heartbeat下找到
#apiauth ipfail uid=hacluster
#apiauth ccm uid=hacluster
#apiauth cms uid=hacluster
#apiauth ping gid=haclient uid=alanr,root
#apiauth default gid=haclient资源文件(/etc/ha.d/haresources):
loadbalancer lvs IPaddr::192.168.136.10/24/eth0 ipvsadm ldirectord 认证文件(/etc/ha.d/authkeys),选取一种认证方式,这个文件的权限必须是600:
auth 1
1 crc
#2 sha1 sha1_any_password
#3 md5 md5_any_password相关链接:
Linux-HA:http://www.linux-ha.org ldirectord
安装HeartBeat过程中,已经自动安装了Ldirectord,它的作用是:
- 监测Real Server,当Real Server失效时,把它从Load Balancer列表中删除,恢复时重新添加。
配置(/etc/ha.d/ldirectord.cf):
# Global Directives
checktimeout=3
checkinterval=1
fallback=127.0.0.1:80
autoreload=yes
logfile="/var/log/ldirectord.log"
quiescent=yes
# A sample virual with a fallback that will override the gobal setting
virtual=192.168.136.10:80
real=192.168.136.11:80 ipip
real=192.168.136.12:80 ipip
real=192.168.136.101:80 ipip
real=192.168.136.102:80 ipip
real=192.168.136.103:80 ipip
fallback=127.0.0.1:80 gate
service=http
request="test.html"
receive="Test Page"
virtualhost=www.funbsd.net
scheduler=rr
#persistent=600
#netmask=255.255.255.255
protocol=tcp在每个Real Server的中添加监控页:
echo "Test Page" >> /var/www/html/test.html Patch
在启动集群系统之前,我们认为包括Load Balancer和Backup在内的所有服务器都是Real Server。
在服务器上添加以下脚本/etc/init.d/tunl,用来配置tunl端口,应用arp补丁:
#!/bin/sh
# chkconfig: 2345 70 10
# description: Config tunl port and apply arp patchVIP=192.168.136.10
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo "Tunl port starting"
ifconfig tunl0 $VIP netmask 255.255.255.255 broadcast $VIP up
echo 1 > /proc/sys/net/ipv4/ip_forward
echo 1 > /proc/sys/net/ipv4/conf/all/hidden
echo 1 > /proc/sys/net/ipv4/conf/tunl0/hidden
;;
stop)
echo "Tunl port closing"
ifconfig tunl0 down
echo 1 > /proc/sys/net/ipv4/ip_forward
echo 0 > /proc/sys/net/ipv4/conf/all/hidden
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac如果有多个Virutal IP,可以使用tunl0:0,tunl0:1...。
chmod 755 /etc/init.d/tunl
chkconfig --add tunl在Load Balancer和Backup上,这个脚本的启动级必须先于heartbeat,关闭级必须后于heartbeat。
Scripts
在HeartBeat资源文件(/etc/ha.d/haresources)中定义了实现集群所需的各个软件的启动脚本。
这些脚本必须放在/etc/init.d或者/etc/ha.d/resource.d目录里,启动顺序不能变:
loadbalancer lvs IPaddr::192.168.136.10/24/eth0 ipvsadm ldirectord IPaddr的作用是启动Virutal IP,它是HeartBeart自带的一个脚本。
ipvsadm的作用是在启动的时候把所有Real Server加入群中。
ldirectord的作用是启动ldirectord监控程序。
lvs的作用是为启动Load Balancer做准备,关闭tunl端口,取消arp补丁:
#!/bin/sh
# chkconfig: 2345 90 10
# description: Preparing for Load Balancer and Real Server switchingVIP=192.168.136.10
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo "Preparing for Load Balancer"
ifconfig tunl0 down
echo 1 > /proc/sys/net/ipv4/ip_forward
echo 0 > /proc/sys/net/ipv4/conf/all/hidden
;;
stop)
echo "Preparing for Real Server"
ifconfig tunl0 $VIP netmask 255.255.255.255 broadcast $VIP up
echo 1 > /proc/sys/net/ipv4/ip_forward
echo 1 > /proc/sys/net/ipv4/conf/all/hidden
echo 1 > /proc/sys/net/ipv4/conf/tunl0/hidden
;;
*)
echo "Usage: lvs {start|stop}"
exit 1
esacchmod 755 /etc/ha.d/resource.d/lvs 启动集群系统:
/etc/init.d/heartbeat start Reference
http://www.linuxvirtualserver.org/
http://www.linux-ha.org/
http://www.ultramonkey.org/
http://www.linuxts.com/modules/sections/index.php?op=viewarticle&artid=375
http://www.yesky.com/SoftChannel/72341302397632512/20040311/1776261.shtml
http://www-900.ibm.com/developerWorks/cn/linux/theme/special/index.shtml#cluster
LVS手册
- LVS手册是为了给LVS用户和开发者提供一个完整的参考手册。也希望大家提供LVS相关的好文章以及使用经验。
手册
如何给出合理的框架和有效的设计方法,来建立高性能、高可伸缩、高可用的网络服务,这是摆在研究者和系统设计者面前极富挑战性的任务。下面文章就是围绕这一任务展开的。- 可伸缩网络服务的设计与实现
文章
- LVS文章荟萃
关于用LVS搭建web服务器集群
- 文嵩您好!大家好!我想使用LVS搭建一个web服务器集群,用于解决我们一个项目中突发访问量过大导致的服务器宕机问题。我的实验环境是:实验室几台普通的PC机(配置不太相同),一个10M的HUB,PC机安装的系统是RedHat9.0,内核版本是2.4.20,web服务器为Apache2.0。我现在设计的步骤是: 1、重新下载内核 2、然后打上LVS补丁 linux-2.4.20-ipvs-1.0.8.patch.gz ipvs-1.0.8.tar.tar 3、配置核心选项 4、重新编译内核 5、重启系统 6、安装ipvsadm-1.21-4.src.rpm 7、调试 想请教一下:这样的实验环境可不可以?实验步骤可不可行? 另外:我想采用基于内容的负载分配机制,请问: web服务器的内容应该怎样部署?(应用系统需要在一两天的时间内完成几万名学生的网上选课) LVS中基于内容的负载均衡机制是怎样的?可以和IP负载均衡配合使用么? (注:关于数据库服务器的集群另外有人在做,暂且认为使用单台高性能机器作为数据库服务器呵呵) 谢谢:)
利用集群技术实现Web服务器的负载均衡
本文出自《网管员世界》2002年第10期“系统维护”栏目
集群和负载均衡的概念集群(Cluster)
所谓集群是指一组独立的计算机系统构成的一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信。应用程序可以通过网络共享内存进行消息传送,实现分布式计算机。负载均衡(Load Balance)
网络的负载均衡是一种动态均衡技术,通过一些工具实时地分析数据包,掌握网络中的数据流量状况,把任务合理均衡地分配出去。这种技术基于现有网络结构,提供了一种扩展服务器带宽和增加服务器吞吐量的廉价有效的方法,加强了网络数据处理能力,提高了网络的灵活性和可用性。特点
(1)高可靠性(HA)。利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务。
(2)高性能计算(HP)。即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分析、化学分析等。
(3)负载平衡。即把负载压力根据某种算法合理分配到集群中的每一台计算机上,以减轻主服务器的压力,降低对主服务器的硬件和软件要求。LVS系统结构与特点
1. Linux Virtual Server:简称LVS。是由中国一个Linux程序员章文嵩博士发起和领导的,基于Linux系统的服务器集群解决方案,其实现目标是创建一个具有良好的扩展性、高可靠性、高性能和高可用性的体系。许多商业的集群产品,比如RedHat的Piranha、 Turbo Linux公司的Turbo Cluster等,都是基于LVS的核心代码的。
2. 体系结构:使用LVS架设的服务器集群系统从体系结构上看是透明的,最终用户只感觉到一个虚拟服务器。物理服务器之间可以通过高速的 LAN或分布在各地的WAN相连。最前端是负载均衡器,它负责将各种服务请求分发给后面的物理服务器,让整个集群表现得像一个服务于同一IP地址的虚拟服务器。
3. LVS的三种模式工作原理和优缺点: Linux Virtual Server主要是在负载均衡器上实现的,负载均衡器是一台加了 LVS Patch的2.2.x版内核的Linux系统。LVS Patch可以通过重新编译内核的方法加入内核,也可以当作一个动态的模块插入现在的内核中。
负载均衡器可以运行在以下三种模式下:
(1)Virtual Server via NAT(VS-NAT):用地址翻译实现虚拟服务器。地址转换器有能被外界访问到的合法IP地址,它修改来自专有网络的流出包的地址。外界看起来包是来自地址转换器本身,当外界包送到转换器时,它能判断出应该将包送到内部网的哪个节点。优点是节省IP 地址,能对内部进行伪装;缺点是效率低,因为返回给请求方的流量经过转换器。
(2)Virtual Server via IP Tunneling (VS-TUN):用IP隧道技术实现虚拟服务器。这种方式是在集群的节点不在同一个网段时可用的转发机制,是将IP包封装在其他网络流量中的方法。为了安全的考虑,应该使用隧道技术中的VPN,也可使用租用专线。 集群所能提供的服务是基于TCP/IP的Web服务、Mail服务、News服务、DNS服务、Proxy服务器等等.
(3)Virtual Server via Direct Routing(VS-DR):用直接路由技术实现虚拟服务器。当参与集群的计算机和作为控制管理的计算机在同一个网段时可以用此法,控制管理的计算机接收到请求包时直接送到参与集群的节点。优点是返回给客户的流量不经过控制主机,速度快开销少。
以四台服务器为例实现负载均衡:安装配置LVS
1. 安装前准备:
(1)首先说明,LVS并不要求集群中的服务器规格划一,相反,可以根据服务器的不同配置和负载状况,调整负载分配策略,充分利用集群环境中的每一台服务器。如下表:
Srv Eth0 Eth0:0 Eth1 Eth1:0
vs1 10.0.0.1 10.0.0.2 192.168.10.1 192.168.10.254
vsbak 10.0.0.3 192.168.10.102
real1 192.168.10.100
real2 192.168.10.101
其中,10.0.0.2是允许用户访问的IP。
(2)这4台服务器中,vs1作为虚拟服务器(即负载平衡服务器),负责将用户的访问请求转发到集群内部的real1,real2,然后由real1,real2分别处理。 Client为客户端测试机器,可以为任意操作系统。
(3)所有OS为redhat6.2,其中vs1 和vsbak 的核心是2.2.19, 而且patch过ipvs的包, 所有real server的Subnet mask 都是24位, vs1和vsbak 的10.0.0. 网段是24 位。
2.理解LVS中的相关术语
(1) ipvsadm :ipvsadm是LVS的一个用户界面。在负载均衡器上编译、安装ipvsadm。
(2) 调度算法: LVS的负载均衡器有以下几种调度规则:Round-robin,简称rr;weighted Round-robin,简称wrr;每个新的连接被轮流指派到每个物理服务器。Least-connected,简称lc;weighted Least-connected,简称wlc,每个新的连接被分配到负担最小的服务器。
(3) Persistent client connection,简称pcc,(持续的客户端连接,内核2.2.10版以后才支持)。所有来自同一个IP的客户端将一直连接到同一个物理服务器。超时时间被设置为360秒。Pcc是为https和cookie服务设置的。在这处调度规则下,第一次连接后,所有以后来自相同客户端的连接(包括来自其它端口)将会发送到相同的物理服务器。但这也会带来一个问题,因为大约有25%的Internet 可能具有相同的IP地址。
(4) Persistent port connection调度算法:在内核2.2.12版以后,pcc功能已从一个调度算法(你可以选择不同的调度算法:rr、wrr、lc、wlc、pcc)演变成为了一个开关选项(你可以让rr、 wrr、lc、wlc具备pcc的属性)。在设置时,如果你没有选择调度算法时,ipvsadm将默认为wlc算法。 在Persistent port connection(ppc)算法下,连接的指派是基于端口的,例如,来自相同终端的80端口与443端口的请求,将被分配到不同的物理服务器上。不幸的是,如果你需要在的网站上采用cookies时将出问题,因为http是使用80端口,然而cookies需要使用443端口,这种方法下,很可能会出现cookies不正常的情况。
(5)Load Node Feature of Linux Director:让Load balancer 也可以处理users 请求。
(6)IPVS connection synchronization。
(7)ARP Problem of LVS/TUN and LVS/DR:这个问题只在LVS/DR,LVS/TUN 时存在。
3. 配置实例
(1) 需要的软件包和包的安装:
I. piranha-gui-0.4.12-2*.rpm (GUI接口cluster设定工具);
II. piranha-0.4.12-2*.rpm;
III. ipchains-1.3.9-6lp*.rpm (架设NAT)。
取得套件或mount到光盘,进入RPMS目录进行安装:
# rpm -Uvh piranha*
# rpm -Uvh ipchains*
(2) real server群:
真正提供服务的server(如web server),在NAT形式下是以内部虚拟网域的形式,设定如同一般虚拟网域中Client端使用网域:192.168.10.0/24 架设方式同一般使用虚拟IP之局域网络。
a. 设网卡IP
real1 :192.168.10.100/24
real2 :192.168.10.101/24
b.每台server均将default gateway指向192.168.10.254。 192.168.10.254为该网域唯一对外之信道,设定在virtual server上,使该网域进出均需通过virtual server 。
c.每台server均开启httpd功能供web server服务,可以在各real server上放置不同内容之网页,可由浏览器观察其对各real server读取网页的情形。
d.每台server都开启rstatd、sshd、rwalld、ruser、rsh、rsync,并且从Vserver上面拿到相同的lvs.conf文件。
(3) virtual server:
作用在导引封包的对外主机,专职负责封包的转送,不提供服务,但因为在NAT型式下必须对进出封包进行改写,所以负担亦重。
a.IP设置:
对外eth0:IP:10.0.0.1 eth0:0 :10.0.0.2
对内eth1:192.168.10.1 eth1:0 :192.168.10.254
NAT形式下仅virtual server有真实IP,real server群则为透过virtual server.
b.设定NAT功能
# echo 1 >; /proc/sys/net/ipv4/ip_forward
# echo 1 >; /proc/sys/net/ipv4/ip_always_defrag
# ipchains -P forward MASQ
c.设定piranha 进入X-window中 (也可以直接编辑/etc/lvs.cf )
a).执行面板系统piranha
b).设定“整体配置”(Global Settings) 主LVS服务器主机IP:10.0.0.2, 选定网络地址翻译(预设) NAT路径名称: 192.168.10.254, NAT 路径装置: eth1:0
c).设定虚拟服务器(Virtual Servers) 添加编辑虚拟服务器部分:(Virtual Server)名称:(任意取名);应用:http;协议: tcp;连接:80;地址:10.0..0.2;装置:eth0:0; 重入时间:180 (预设);服务延时:10 (预设);加载监控工具:ruptime (预设);调度策略:Weighted least-connections; 持续性:0 (预设); 持续性屏蔽: 255.255.255.255 (预设); 按下激活:实时服务器部分:(Real Servers); 添加编辑:名字:(任意取名); 地址: 192.168.10.100; 权重:1 (预设) 按下激活
另一架real server同上,地址:192.168.10.101。
d). 控制/监控(Controls/Monitoring) 控制:piranha功能的激活与停止,上述内容设定完成后即可按开始键激活piranha.监控器:显示ipvsadm设定之routing table内容 可立即更新或定时更新。
(4)备援主机的设定(HA)
单一virtual server的cluster架构virtual server 负担较大,提供另一主机担任备援,可避免virtual server的故障而使对外服务工作终止;备份主机随时处于预备状态与virtual server相互侦测
a.备份主机:
eth0: IP 10.0.0.3
eth1: IP 192.168.10.102 同样需安装piranha,ipvsadm,ipchains等套件
b.开启NAT功能(同上面所述)。
c.在virtual server(10.0.0.2)主机上设定。
a).执行piranha冗余度 ;
b).按下“激活冗余度”;
冗余LVS服务器IP: 10.0.0.3;HEARTBEAT间隔(秒数): 2 (预设)
假定在…秒后进入DEAD状态: 5 (预设); HEARTBEAT连接埠: 539 (预设)
c).按下“套用”;
d).至“控制/监控”页,按下“在当前执行层添加PULSE DEAMON” ,按下“开始”;
e).在监控器按下“自动更新”,这样可由窗口中看到ipvsadm所设定的routing table,并且动态显示real server联机情形,若real server故障,该主机亦会从监视窗口中消失。
d.激活备份主机之pulse daemon (执行# /etc/rc.d/init.d/pulse start)。
至此,HA功能已经激活,备份主机及virtual server由pulse daemon定时相互探询,一但virtual server故障,备份主机立刻激活代替;至virtual server 正常上线后随即将工作交还virtual server。LVS测试
经过了上面的配置步骤,现在可以测试LVS了,步骤如下:
1. 分别在vs1,real1,real2上运行/etc/lvs/rc.lvs_dr。注意,real1,real2上面的/etc/lvs 目录是vs2输出的。如果您的NFS配置没有成功,也可以把vs1上/etc/lvs/rc.lvs_dr复制到real1,real2上,然后分别运行。确保real1,real2上面的apache已经启动并且允许telnet。
2. 测试Telnet:从client运行telnet 10.0.0.2, 如果登录后看到如下输出就说明集群已经开始工作了:(假设以guest用户身份登录)
[guest@real1 guest]$——说明已经登录到服务器real1上。
再开启一个telnet窗口,登录后会发现系统提示变为:
[guest@real2 guest]$——说明已经登录到服务器real2上。
3. 测试http:从client运行iexplore http://10.0.0.2
因为在real1 和real2 上面的测试页不同,所以登录几次之后,显示出的页面也会有所不同,这样说明real server 已经在正常工作了。
集群LVS+GFS+ISCSI+TOMCAT
作者: hosyp 发表于:2006-02-15 21:24:28
LVS是中国人发起的项目,真是意外呀!大家可以看http://www.douzhe.com/linuxtips/1665.html
我是从最初的HA(高可用性)开始的,别人的例子是用VMWARE,可以做试验但不能实际应用,我又没有光纤卡的Share Storage,于是就选用ISCSI,成功后又发现ISCSI+EXT3不能用于LVS,倒最后发现GFS可用,我最终成功配成可实际应用的LVS,前后断断续续花了四个月,走了很多弯路。我花了三天时间写下这篇文章,希望对大家有用。
这里要感谢linuxfans.org、linuxsir.com、chinaunix.com以及其它很多网站,很多资料都是从他们的论坛上找到的。参考文档及下载点
a.http://www.gyrate.org/misc/gfs.txt
b.http://www.redhat.com/docs/manuals/enterprise/RHEL-3-Manual/cluster-suite/index.html
http://www.redhat.com/docs/manuals/csgfs/admin-guide/index.html
c.ftp://ftp.redhat.com/pub/redhat/linux/updates/enterprise/3ES/en/RHGFS/SRPMS
d.http://distro.ibiblio.org/pub/linux/distributions/caoslinux/centos/3.1/contrib/i386/RPMS/LVS结构图: eth0=10.3.1.101 eth0:1=10.3.1.254 Load Balance Router eth1=192.168.1.71 eth1:1=192.168.1.1 | | | | Real1 Real2 eth0=192.168.1.68 eth0=192.168.1.67 (eth0 gateway=192.168.1.1) eth1=192.168.0.1---eth1=192.168.0.2 (双机互联线) | | GFS ISCSI Share storage eth0=192.168.1.1241.Setup ISCSI Server
Server: PIII 1.4,512M, Dell 1650,Redhat 9,IP=192.168.1.124
从http://iscsitarget.sourceforge.net/下载ISCSI TARGET的Source code
(http://sourceforge.net/project/showfiles.php?group_id=108475&package_id=117141)
我选了iscsitarget-0.3.8.tar.gz,要求kernel 2.4.29
从kernel.org下载kernel 2.4.29,解开编译重启后编译安装iscsitarget-0.3.8:
#make KERNELSRC=/usr/src/linux-2.4.29
#make KERNELSRC=/usr/src/linux-2.4.29 install
#cp ietd.conf /etc
#vi /etc/ietd.conf
# Example iscsi target configuration # # Everything until the first target definition belongs # to the global configuration. # Right now this is only the user configuration used # during discovery sessions: # Users, who can access this target # (no users means anyone can access the target) User iscsiuser 1234567890abc Target iqn.2005-04.com.my:storage.disk2.sys1.iraw1 User iscsiuser 1234567890abc Lun 0 /dev/sda5 fileio Alias iraw1 Target iqn.2005-04.com.my:storage.disk2.sys1.iraw2 User iscsiuser 1234567890abc Lun 1 /dev/sda6 fileio Alias iraw2 Target iqn.2005-04.com.my:storage.disk2.sys2.idisk User iscsiuser 1234567890abc Lun 2 /dev/sda3 fileio Alias idisk Target iqn.2005-04.com.my:storage.disk2.sys2.icca User iscsiuser 1234567890abc Lun 3 /dev/sda7 fileio Alias icca
说明:password 长度必须不小于12个字符, Alias是别名, 不知为何这个别名在Client端显示不出来.
分区:我只有一个SCSI盘,所以:
/dev/sda3: Share storage,容量越大越好 /dev/sda5: raw1, 建Cluster要的rawdevice, 我给了900M /dev/sda6: raw2, 建Cluster要的rawdevice, 我给了900M /dev/sda7: cca, 建GFS要的,我给了64M (/dev/sda4是Extended分区,在其中建了sda5,6,7)
#Reboot,用service iscsi-target start启ISCSI server(我觉得比建议的好,可以
用service iscsi-target status看状态)
2.Setup ISCSI Client(on two real server)
Server: PIII 1.4,512M, Dell 1650,Redhat AS3U4(用AS3U5更好),2.4.21-27.EL
#vi /etc/iscsi.conf
DiscoveryAddress=192.168.1.124 OutgoingUsername=iscsiuser OutgoingPassword=1234567890abc Username=iscsiuser Password=1234567890abc LoginTimeout=15 IncomingUsername=iscsiuser IncomingPassword=1234567890abc SendAsyncTest=yes
#service iscsi restart
#iscsi-ls -l
..., 精简如下:
/dev/sdb:iraw2
/dev/sdc:iraw1
/dev/sdd:idisk
/dev/sde:icca
注意: 在real server中ISCSI device的顺序很重要,两个real server中一定要一样,如不一样
就改ISCSI Server中的设置,多试几次
3.Install Redhat Cluster suite
先下载Cluster Suite的ISO, AS3的我是从ChinaUnix.net找到的下载点, 安装clumanager和
redhat-config-cluster。没有Cluster Suite的ISO也没关系,从
ftp://ftp.redhat.com/pub/redhat/linux/updates/enterprise/3ES/en/RHCS/SRPMS/下载
clumanager-1.2.xx.src.rpm,redhat-config-cluster-1.0.x.src.rpm,编译后安装,应该更好:
#rpm -Uvh clumanager-1.2.26.1-1.src.rpm
#rpmbuild -bs /usr/src/redhat/SPECS/clumanager.spec
#rpmbuild --rebuild --target i686 /usr/src/redhat/SRPMS/clumanager-1.2.26.1-1.src.rpm
还有redhat-config-cluster-1.0.x.src.rpm,也装好
4.Setup Cluster as HA module
详细步骤我就不写了,网上有很多文章,我也是看了别人的文章学会的,不过人家是用VMWARE,
而我是用真的机子+ISCSI,raw device就是/dev/sdb,/dev/sdc, 然后就
mount /dev/sdd /u01, mkfs.ext3 /u01 ......
设好后会发现ISCSI有问题:同时只能有一个Client联接写盘,如果
两个Client同时联ISCSI的Share Storge,一个Client写,另一个Client是看不到的,而且此时文
件系统已经破坏了,Client重联ISCSI时会发现文件是坏的,用fsck也修复不了。
ISCSI真的是鸡肋吗?
NO!从GOOGLE上我终于查到ISCSI只有用Cluster File System才能真正用于Share Storage!
而Redhat买下的GFS就是一个!
5.Setup GFS on ISCSI
GFS只有Fedora Core4才自带了,而GFS又一定要用到Cluster Suite产生的/etc/cluster.xml文件,
我没见FC4有Cluster Suite,真不知Redhat给FC4带GFS干嘛,馋人吗?
好,闲话少说,下载:c处的GFS-6.0.2.20-2.src.rpm, 按a处的gfs.txt编译安装,不过关于
cluster.ccs,fence.ccs,nodes.ccs的设置没说,看b的文档,我总算弄出来了,都存在
/root/cluster下,存在别的地方也行,不过我不知道有没有错,我没有光纤卡,文档又没讲ISCSI
的例子,不过GFS能启动的。
#cat cluster.ccs
cluster { name = "Cluster_1" lock_gulm { servers = ["cluster1", "cluster2"] heartbeat_rate = 0.9 allowed_misses = 10 } }
注:name就是Cluster Suite设置的Cluster name, servers就是Cluster member的Hostname,别忘
了加进/etc/hosts;allowed_misses我开始设为1,结果跑二天GFS就会死掉,改为10就没死过了。
#cat fence.ccs
fence_devices{ admin { agent = "fence_manual" } }
#cat nodes.ccs
nodes { cluster1 { ip_interfaces { hsi0 = "192.168.0.1" } fence { human { admin { ipaddr = "192.168.0.1" } } } } cluster2 { ip_interfaces { hsi0 = "192.168.0.2" } fence { human { admin { ipaddr = "192.168.0.2" } } } } }
注:ip就是心跳线的ip
这三个文件建在/root/cluster下,先建立Cluster Configuration System:
a.#vi /etc/gfs/pool0.cfg
poolname pool0
minor 1 subpools 1
subpool 0 8 1 gfs_data
pooldevice 0 0 /dev/sde1
b.#pool_assemble -a pool0
c.#ccs_tool create /root/cluster /dev/pool/pool0
d.#vi /etc/sysconfig/gfs
CCS_ARCHIVE="/dev/pool/pool0"再Creating a Pool Volume,就是我们要的共享磁盘啦,
a.#vi /etc/gfs/pool1.cfg
poolname pool1
minor 2 subpools 1
subpool 0 128 1 gfs_data
pooldevice 0 0 /dev/sdd1
b.#pool_assemble -a pool1
c.#gfs_mkfs -p lock_gulm -t Cluster_1:gfs1 -j 8 /dev/pool/pool1
d.#mount -t gfs -o noatime /dev/pool/pool1 /u01
下面是个GFS的启动脚本,注意real1和real2必须同时启动lock_gulmd进程,第一台lock_gulmd
会成为Server并等Client的lock_gulmd,几十秒后没有响应会fail,GFS启动失败。Redhat建议
GFS盘不要写进/etc/fstab。
#cat gfstart.sh
#!/bin/sh depmod -a modprobe pool modprobe lock_gulm modprobe gfs sleep 5 service iscsi start sleep 20 service rawdevices restart pool_assemble -a pool0 pool_assemble -a pool1 service ccsd start service lock_gulmd start mount -t gfs /dev/pool/pool1 /s02 -o noatime service gfs status6. Setup Linux LVS
LVS是章文嵩博士发起和领导的优秀的集群解决方案,许多商业的集群产品,比如RedHat的Piranha,Turbolinux公司的Turbo Cluster等,都是基于LVS的核心代码的。
我的系统是Redhat AS3U4,就用Piranha了。从rhel-3-u5-rhcs-i386.iso安装piranha-0.7.10-2.i386.rpm,ipvsadm-1.21-9.ipvs108.i386.rpm (http://distro.ibiblio.org/pub/linux/distributions/caoslinux/centos/3.1/contrib/i386/RPMS/) 装完后service httpd start & service piranha-gui start,就可以从http://xx.xx.xx.xx:3636管理或设置了,当然了,手工改/etc/sysconfig/ha/lvs.cf也一样。
#cat /etc/sysconfig/ha/lvs.cf
serial_no = 80 primary = 10.3.1.101 service = lvs rsh_command = ssh backup_active = 0 backup = 0.0.0.0 heartbeat = 1 heartbeat_port = 1050 keepalive = 6 deadtime = 18 network = nat nat_router = 192.168.1.1 eth1:1 nat_nmask = 255.255.255.0 reservation_conflict_action = preempt debug_level = NONE virtual lvs1 { active = 1 address = 10.3.1.254 eth0:1 vip_nmask = 255.255.255.0 fwmark = 100 port = 80 persistent = 60 pmask = 255.255.255.255 send = "GET / HTTP/1.0\r\n\r\n" expect = "HTTP" load_monitor = ruptime scheduler = wlc protocol = tcp timeout = 6 reentry = 15 quiesce_server = 1 server Real1 { address = 192.168.1.68 active = 1 weight = 1 } server Real2 { address = 192.168.1.67 active = 1 weight = 1 } } virtual lvs2 { active = 1 address = 10.3.1.254 eth0:1 vip_nmask = 255.255.255.0 port = 21 send = "\n" use_regex = 0 load_monitor = ruptime scheduler = wlc protocol = tcp timeout = 6 reentry = 15 quiesce_server = 0 server ftp1 { address = 192.168.1.68 active = 1 weight = 1 } server ftp2 { address = 192.168.1.67 active = 1 weight = 1 } }
设置完后service pulse start, 别忘了把相关的client加进/etc/hosts
#iptables -t mangle -A PREROUTING -p tcp -d 10.3.1.254/32 --dport 80 -j MARK --set-mark 100
#iptables -t mangle -A PREROUTING -p tcp -d 10.3.1.254/32 --dport 443 -j MARK --set-mark 100
#iptables -A POSTROUTING -t nat -p tcp -s 10.3.1.0/24 --sport 20 -j MASQUERADE
运行以上三行命令并存入/etc/rc.d/rc.local,用ipvsadm看状态:
#ipvsadm
IP Virtual Server version 1.0.8 (size=65536) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.3.1.254:ftp wlc -> cluster2:ftp Masq 1 0 0 -> cluster1:ftp Masq 1 0 0 FWM 100 wlc persistent 60 -> cluster1:0 Masq 1 0 0 -> cluster2:0 Masq 1 0 0
注意:a.Firewall Mark可以不要,我反正是加了,文档说有https的话加上,值我选了100,
b.Virtual IP别加进/etc/hosts,我上过当,80端口时有时无的,
c.eth0:1,eth1:1是piranha产生的,别自己手工设置,我干过这画蛇添足的事,网上有
些帖子没说清,最后是看Redhat的文档才弄清楚的。
d.The LVS router can monitor the load on the various real servers by using
either rup or ruptime. If you select rup from the drop-down menu, each real
server must run the rstatd service. If you select ruptime, each real server
must run the rwhod service.Redhat的原话,就是如选rup的监控模式real server上
都要运行rstatd进程,如选ruptime就要运行rwhod进程。
e.Real Server同Router相联的网卡的Gateway必须是Router的那块网卡的VIP,举本例:
Router的eth1同两个real server的eth0相联,如VIP eth1:1=192.168.1.1,则real
server 的eth0的Gateway=192.168.1.1echo "1" > /proc/sys/net/ipv4/ip_forward
7.Setup TOMCAT5.59+JDK1.5(用Redhat自带的Apache)
a.#tar xzvf jakarta-tomcat-5.5.9.tar.gz
#mv jakarta-tomcat-5.5.9 /usr/local
#ln -s /usr/local/jakarta-tomcat-5.5.9 /usr/local/tomcat
b.#jdk-1_5_0_04-linux-i586.bin
#mv jdk1.5.0_4 /usr/java
#ln -s /usr/java/jdk1.5.0_4 /usr/java/jdk
c.#vi /etc/profile.d/tomcat.sh
export CATALINA_HOME=/usr/local/tomcat
export TOMCAT_HOME=/usr/local/tomcat
d.#vi /etc/profile.d/jdk.sh
if ! echo ${PATH} | grep "/usr/java/jdk/bin" ; then JAVA_HOME=/usr/java/jdk export JAVA_HOME export PATH=/usr/java/jdk/bin:${PATH} export CLASSPATH=$JAVA_HOME/lib fi
e.#chmod 755 /etc/profile.d/*.sh
f.重新用root登录,让tomcat.sh和jdk.sh起作用,
#tar xzvf jakarta-tomcat-connectors-jk2-src-current.tar.gz
#cd jakarta-tomcat-connectors-jk2-2.0.4-src/jk/native2/
#./configure --with-apxs2=/usr/sbin/apxs --with-jni --with-apr-lib=/usr/lib
#make
#libtool --finish /usr/lib/httpd/modules
#cp ../build/jk2/apache2/mod_jk2.so ../build/jk2/apache2/libjkjni.so /usr/lib/httpd/modules/
g.#vi /usr/local/tomcat/bin/catalina.sh
在# Only set CATALINA_HOME if not already set后加上以下两行:
serverRoot=/etc/httpd
export serverRoot
h.#vi /usr/local/tomcat/conf/jk2.properties
serverRoot=/etc/httpd
apr.NativeSo=/usr/lib/httpd/modules/libjkjni.so
apr.jniModeSo=/usr/lib/httpd/modules/mod_jk2.so
i.#vi /usr/local/tomcat/conf/server.xml,在前加上以下几行,建了两个VirtualPath:myjsp和local,一个指向share storage,一个指向real server本地
j.#vi /etc/httpd/conf/workers2.properties
#[logger.apache2] #level=DEBUG [shm] file=/var/log/httpd/shm.file size=1048576 [channel.socket:localhost:8009] tomcatId=localhost:8009 keepalive=1 info=Ajp13 forwarding over socket [ajp13:localhost:8009] channel=channel.socket:localhost:8009 [status:status] info=Status worker, displays runtime informations [uri:/*.jsp] worker=ajp13:localhost:8009 context=/
k.#vi /etc/httpd/conf/httpd.conf
改:DocumentRoot "/u01/www"
加:
在LoadModule最后加:
LoadModule jk2_module modules/mod_jk2.so
JkSet config.file /etc/httpd/conf/workers2.properties
在#之前加:
Order allow,deny
Deny from all
l:#mkdir /u01/ftproot
#mkdir /u01/www
#mkdir /u01/www/myjsp
m:在每个real server上生成index.jsp
#vi /var/www/html/index.jsp
<%@ page import="java.util.*,java.sql.*,java.text.*" contentType="text/html"
%>
<%
out.println("test page on real server 1");
%>
在real server2上就是"test page on real server 2"
n:下载jdbc Driver
http://www.oracle.com/technology/software/tech/java/sqlj_jdbc/htdocs/jdbc9201.html
可惜只有for JDK1.4的,在两台real server上分别
#cp -R /usr/local/tomcat/webapps/webdav/WEB-INF /u01/www/myjsp
#cp ojdbc14.jar ojdbc14_g.jar ocrs12.zip /u01/www/myjsp/WEB-INF/lib
o: 假设我有一台OracleServer,ip=10.3.1.211,sid=MYID,username=my,password=1234,
并有Oracle的例子employees的read权限,或干脆把这个table拷过来,我是Oracle9i中的
#vi /u01/www/myjsp/testoracle.jsp
<%@ page contentType="text/html" %>; <%@ page import="java.sql.*"%>; ;;Test ORACLE Employees ; ; ; <% String OracleDBDriver="oracle.jdbc.driver.OracleDriver"; String DBUrl="jdbc:oracle:thin:@10.3.1.211:1521:MYID"; String UserID="my"; String UserPWD="1234"; Connection conn=null; Statement stmt=null; ResultSet rs=null; try { Class.forName(OracleDBDriver); } catch(ClassNotFoundException ex) { System.out.println("Class.forname:"+ex); } conn=DriverManager.getConnection(DBUrl,UserID,UserPWD); stmt=conn.createStatement(); String sql="select * from EMPLOYEES"; rs = stmt.executeQuery(sql); out.print(";"); out.print("
;"); rs.close(); stmt.close(); conn.close(); %>; ;;"); out.print(" ;"+"EMPLOYEE_ID"); out.print(" ;"+"FIRST_NAME"); out.print(" ;"+"LAST_NAME"); out.print(" ;"+"EMAIL"); out.print(" ;"+"PHONE_NUMBER"); out.print(" ;"+"HIRE_DATE"); out.print(" ;"+"JOB_ID"); out.print(" ;"); try { while(rs.next()) { out.print(" ;"); int n=rs.getInt(1); out.print(" ;"); } } catch(SQLException ex) { System.err.println("ConnDB.Main:"+ex.getMessage()); } out.print(";"+n+" ;"); String e=rs.getString(2); out.print(";"+e+" ;"); //String e=rs.getString(3); out.print(";"+rs.getString(3)+" ;"); out.print(";"+rs.getString(4)+" ;"); out.print(";"+rs.getString(5)+" ;"); out.print(";"+rs.getString(6)+" ;"); out.print(";"+rs.getString(7)+" ;"); out.print("