论文阅读《Open-Domain Hierarchical Event Schema Induction by Incremental Prompting and Verification》
论文阅读《Open-Domain Hierarchical Event Schema Induction by Incremental Prompting and Verification》
- 1. Introduction
- 2. Task overview
- 3. Approach
-
- 3.1 Retrieval-Augmented Prompting
- 3.2 Event Skeleton Construction
- 3.3 Event Expansion and Validation
- 3.4 Event-Event Relation Verification
- 总结与启发
自从LLM兴起以来,传统的判别式信息抽取系统难以避免地受到冷落,我印象中一直倾向于抽取式任务的Blender Lab的研究工作,也从去年开始逐渐转向生成式任务。最近注意到一篇名为《Open-Domain Hierarchical Event Schema Induction by Incremental Prompting and Verification》的论文,目前状态是发表在ACL2023,源码还没有发布,但论文内容比较详尽,于是决定仔细阅读一下,并记录下这一篇阅读笔记。
一开始读到这篇论文的时候,误以为是利用LLM进行事件抽取的,但读了之后发现是用于schema的构建,并不是主要关心的方向,所以没打算把这篇笔记发出来。最近看到刘老师也更新了这篇文章的介绍:https://mp.weixin.qq.com/s/DuFHWUuSqdRrPSAyeYBYxg,加之论文的源码也已经开源:https://github.com/raspberryice/inc-schema,所以还是把这篇阅读记录总结一下。
这篇阅读笔记是大概两个月之前积压下来的,由于前段时间一直比较忙,博客也处于停更状态。近期时间相对充裕了一点,准备继续学习NLP、KG以及LLM相关的技术,并做好记录,博客内容也会恢复更新。
1. Introduction
思路:给定一个新的场景,仅需要非常轻量的人工指导,通过模型生成完整的event schema。
需要明确的是,这篇文章的内容是生成event schema,而非获取针对某个篇章的具体的event graph instance。
三个关键环节:
-
- 事件骨架构建(event skeleton construction)
-
- 事件扩展(event expansion)
-
- 事件-事件关系验证(event-event relation verification)
文章的主要贡献:
-
- 提出INCPROMPT结构,以构建复杂的event schema。相比之前的工作依赖于建立事件实例图(event instance graphs),不受限于信息抽取系统的作用域。
-
- 同时关注事件之间的层次关系和时间关系,可以支持全新的事件-事件关系。
-
- 在两个schema数据集上(ODIN, RESIN-11)验证了有效性,相比直接生成schema,事件的时间关系F1提高7.2%,层次关系F1提高31.0%。
2. Task overview
文章所做的主要工作,是在一个特定的Scenario(没有想好怎么翻译)下,或许一些列的事件及其对应的描述,所谓描述,是使用一句话代表一个事件(例如,“A person shows early symptoms of the disease”),而非一个特定的事件类型(例如,“Illness”)。这个描述应该是通用的,而不是基于某个特定的实例的(例如,“John had a mild fever due to COVID”)。
在开始方法的介绍之前,需要结合具体的代码,明确几个概念,否则很容易产生困扰。
Scenario: 在本文中,Scenario的概念是一个模糊的事件类型的统称,其以字符串形式表示,例如“protest”,“cyber attack”等。
Chapter: 一个大的场景下的段落结构,chapter可以视作是event的一种,它们之间可能存在时间关联。给定chapter结构图,就可以以此来指导schema的图结构的生成。每个Scenario下,会给出对应的chapter结构,其中的每个chapter,具有一个名字(name),如“contributing factor”,“peaceful protest”等,以及对应的一句话描述(description),以说明这个chapter的定义。除此之外,由于chapter之间可以存在时间关联,它们的这种可能存在的关联顺序也会被约束,例如,“contributing factor”可以发生在“peaceful protest”之前。
Event: 一系列事件中的某个事件节点,具有id,name,description等若干属性,总结具体如下表。
| Event的属性 | 含义 |
|---|---|
| id | id |
| name | 名称 |
| description | 描述 |
| level | 此事件是哪一层级 |
| is_schema | 是否为schema |
| is_chapter | 是否为chapter |
| children | 子事件的集合 |
| parent | 父事件的id |
| before | 发生在其之前的事件的集合 |
| after | 发生在其之后的事件的集合 |
| entiteis | 所包含的实体列表 |
| relations | 所包含的关系列表 |
Schema: Schema是一个可以被实例化的Event,具有可以表示一些列事件的一个图结构,由事件节点和它们之间的关系构成。从代码上体现来看,Schema类继承了Event类,并且每个schema具有一个scenario,以及一个属性G,用来存储其所包含的事件和事件关系。
一个初始的schema,所包含的事件,包括这个schema本身,以及其所涉及的所有chapter,如下:

单从定义来看,会有一点混乱,尤其是对于Event,Schema和chapter的关系,按照代码的结构,Schema和Chapter都是特殊的Event,但schema又是一个包含了若干事件和事件关系的图结构(体现在Schema.G)。
3. Approach
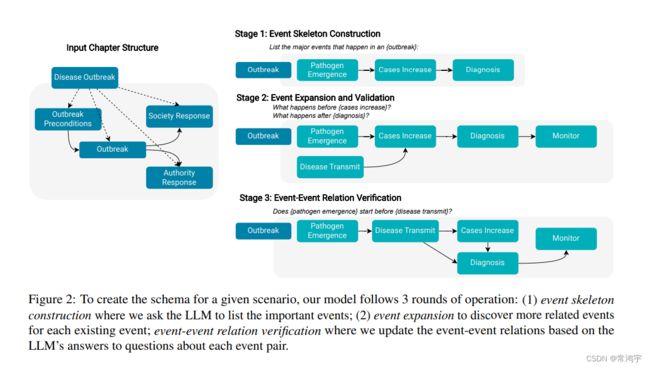
整个方法可以划分为三个部分,事件骨架构建(event skeleton construction )、事件扩展(event expansion),以及事件与事件之间的关系验证(event-event relation verification)。
-
- 事件骨架构建:直接向LLM询问,文本中所包含的主要事件,产生主要事件的列表,这些事件是scenario(或chapter)的子事件;
-
- 事件扩展:对于每个已经获取到的事件,去发现与之相关联的其他事件;
-
- 事件关系验证:基于向LLM询问的答案,更新事件与事件之间的关系。
3.1 Retrieval-Augmented Prompting
检索增强prompt,顾名思义,就是利用检索文章的结果,对原有的prompt进行增强。
这一步的目的是,通过增加所参考的文章样本,以生成一个更加通用的结果,而不是描述一个具体的实例。
对于一个特定的Scenario,通过获取维基百科页的参考链接,得到一系列相关的文章。
对于每个prompt,根据事件的描述,使用TCT-ColBERT召回top 3 的文章。
然后按照如下的方式,生成增强之后的Prompt:
“Based on the following passages {retrieved passages}, {prompt}”

3.2 Event Skeleton Construction
通过构建prompt,向LLM询问的方式,完成事件骨架的构建。
给定一个chapter c c c,利用prompt “List the major events in c?”,这一步通常会得到句子的一个列表。
进一步地,列表中的每个句子当做事件的描述,就可以将其转化为事件节点的列表。并且假设,所生成的事件列表是按照时间顺序的。

以scenario='protest'为例,根据每个chapter生成的prompt分别为:
contributing factor is defined as "The social-political background that caused the protest.".
List the major events that happen in the contributing factor of a protest:
peaceful protest is defined as "a demonstration is held by a group of people.".
List the major events that happen in the peaceful protest of a protest:
riot is defined as "a conflict breaks out between the protestors and the police.".
List the major events that happen in the riot of a protest:
civil justice is defined as "the protestors are arrested and face legal charges.".
List the major events that happen in the civil justice of a protest:
response is defined as "the society responds to the protests and demonstrations.".
List the major events that happen in the response of a protest:
在获取到事件列表之后,为了给每个事件分配一个易于理解的名字,使用in-context learning的方法,给定10个{描述,名称}pair,例如 {Disinfect the area to prevent infection of the disease, Sanitize} ,让模型通过对这10个例子,学会给事件起名。注意这里的起名是一个通用性的名字,而不是针对于某一个事件instance。
以下是论文附录中给出的in-cotext示例:

3.3 Event Expansion and Validation
给定一个事件节点 e e e(such as Cases Increase in Figure 2),使用例如“What are the steps in e?”,“What happens after e?”之类的prompt,去获取到该事件的相邻节点。
对于获取到的候选事件 e e e’,需要进行一系列的检测:
(1)重复性检测(Duplication Test )
检查是不是与已有事件重复,使用SBERT编码后计算余弦相似度,以及Jaro-Winkler计算字符相似度。
(2)特异性检测(Specificity Test)
通过问询LLM“Does the text contain any specific names, numbers, locations, or dates?”,过滤掉太细节的事件。采用10个样本的in-context样例来指引模型生成的答案为Yes或No。
(3)篇章检测(Chapter Test)
给出chapter event c c c的名称和定义,以及目标候选事件 e e e’,通过问询“Is e′ a part of c? ”来判断是否保留 e e e’。
如果 e ′ e^{'} e′通过了所有测试,那么它就可以作为一个新的事件节点保留下来,此时再利用3.2中所述方法,给这个新的事件起一个名字。
3.4 Event-Event Relation Verification
尽管在之前的过程中,通过询问“Is e′ a part of c? ”,已经可以获得一部分事件之间的关系(subevent),但文章认为,这些关系是不准确,或者有噪声的。
为了获取事件之间的时间关系和层级关系,一个直接的方法就是询问“Is e1 a part of e2?”和“Does e1 happen before e2?”,然而实验却表明,这种方法会造成:
- (1)关系错乱:两个事件之间既存在时间先后关系,又存在层级包含关系;
- (2)顺序敏感:模型倾向于对“before”和“after”两个问题都回答“YES。
(1)为了解决关系错乱的问题,不直接通过向大模型询问是否存在关系,而是通过判断事件与事件的起始时间、结束时间,以及持续时间之间的关系,来判断两个事件的时间关系;并且为层级关系添加一个约束,即如果事件 e 1 e_1 e1包含 e 2 e_2 e2,那么 e 1 e_1 e1的时间范围一定包含了 e 2 e_2 e2的时间范围。
所以原来的关于时间的一个问题,就变成了下表中的三个问题,通过这三个问题的答案,来判断两个事件之间的关系:

针对上表中的三个问题,并不是直接以问答的形式让模型返回Yes or No,而是使用OpenAI 的API获取词表中对数概率最大的5个token,然后判断预测为Yes,No或Unknown的token的概率。
(2)为了解决顺序敏感的问题,对不同的顺序(“Does e1 start before e2?” 和“Does e2 start before e1”)和不同的prompt(“Does e1 start before e2?”和“Does e2 start after e1?”)的结果取平均。
在获取到start time,end time,以及duration三个问题的结果之后,就可以创建事件节点与事件节点之间的边了,但是只保留三个问题对应答案的得分都大于某个阈值的边。
此外,考虑到事件节点之间的时间关系边,是纯粹依靠事件pair的描述来生成的,而没有任何结构化的限制,所以需要一个额外的步骤来消除事件图中存在的由两个以上事件构成的环。
以上就是论文中所涉及的主要方法的介绍,论文的实验部分和更多细节,限于篇幅和精力,就不再总结了,感兴趣的同学可以阅读原文。
总结与启发
总的来说,这篇文章没有针对instance-level的事件抽取任务进行探讨,而是利用大模型的生成能力,结合召回的若干篇章,形成事件的模式图,在这种模式下,作者希望获取到的是一系列相关的事件,每个事件的通用性的描述,以及事件之间的先后、层级的逻辑关系。
本文引入大模型去形成event schema,除了希望利用大模型的生成能力去定义一类事件的描述,主要原因应该是其所针对的场景是开放域,希望对任何一个场景都可以产生一种事件模式,从而减少人工定义事件模式的工作量。
然而,对于实际应用中事件抽取任务来讲,更大的工作量还是在于如何抽取具体的事件,schema的定义问题,我还是认为交由人工构建更加可靠。但本文所提出的利用大模型去进行生成,尤其是针对事件关系的预测时,采用问题拆解在组合的形式进行,通过添加规则的方法来过滤掉生成结果的逻辑错误的情况(毕竟生成式模型只讲概率,不讲逻辑),这种解决问题的思路还是很具有启发性的,在资源充分的情况下,或许可以采用这种形式引入大模型到instance-level的事件抽取任务,从一定程度上约束抽取(生成)结果不规范,不准确的情况。