C语言第九课------------------数组----------------C中之将
作者前言
|
|
—————————————————————————
目录
数组
-
一维数组的使用
-
一维数组在内存中的存储
-
二维数组的创建和初始化
-
二维数组的使用
-
二维数组在内存中的存储
- 数组越界
- 数组作为函数参数
——————————————————————————————————————
一维数组的创建和初始化
数组的创建
数组是一组相同类型元素的集合。,简而言之,数组是表示一串数据数据类型相同的数据
数组的创建方式
元素数据类型 数组名[数组的大小];#include
int main()
{
int arr[5];
int arr1[3 + 2];
char arr2[3];
return 0;
} 在一些编译器中,是可以使用变量当作数组的大小的,是因为在C99之前只能是常量指定大小,C99之后引用了变长数组的概念,数组的大小是可以使用变量指定的,vs2019、vs2022是不支持的,数组的长度一旦确定了就不能改变了,
变长数组不能初始化,我们还是使用常量定义数组
数组的初始化
#include
int main()
{
int arr[10] = { 1,2,3,4 };
return 0;
} 
可以看出未初始化部分是默认为0
完全初始化
#include
int main()
{
int arr[3] = { 1,2,3 };
char arr1[3] = { 'a',68,98 };
int arr2[] = { 1,2,3 };
getchar();
return 0;
} 注意一下,在字符串数组中写入整数是会默认为ASCII值,然后自动转换为字符
一维数组的使用
#include
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9 };
int sz = sizeof arr / sizeof(int);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
getchar();
return 0;
} 这里引入了[] ,下标引用操作符。它其实就数组访问的操作符。
1. 数组是使用下标来访问的,下标是从0开始。
2. 数组的大小可以通过计算得到。
一维数组在内存中的存储
要想了一维数组在内存中的存储,就必须了解数组中每个元素的地址
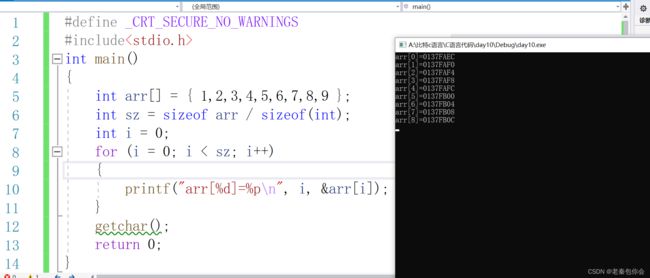
十六进制
可以看出地址之间相差4,是因为整形元素一个占四个字节,一个字节一个地址,
1.数组在内存中是连续存放的
2.随着下标的增长,地址是由低到高变化的

二维数组的创建和初始化
二维数组的创建
#include
int main()
{
int arr[3][5];
char arr1[2][3];
return 0;
} 二维数组的初始化
#include
int main()
{
int arr[3][5] = { 0 };//可以想象成一个矩阵,三行五列
int arr1[3][5] = { 1,2,3,4,5,2,3,4,5,6,3,4,5,6,7 };
int arr2[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
int arr3[3][5] = { {1,2},{0},{1,2,3,4,5} };
int arr4[][5] = { {1,2},{0},{1,2,3,4,5} };
return 0;
} 二维数组的使用
#include
int main()
{
int arr1[3][5] = { {1,2},{0},{1,2,3,4,5} };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d ", arr1[i][j]);
}
printf("\n");
}
return 0;
} 这里是二维数组的简单使用
二维数组在内存中的存储
一样的跟一维数组一样,每个元素打印出来地址
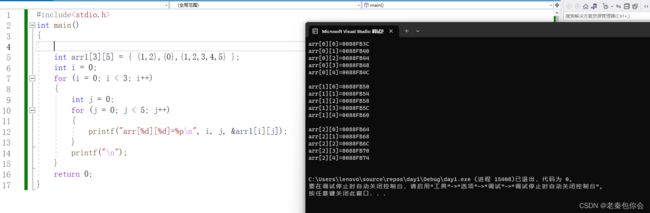
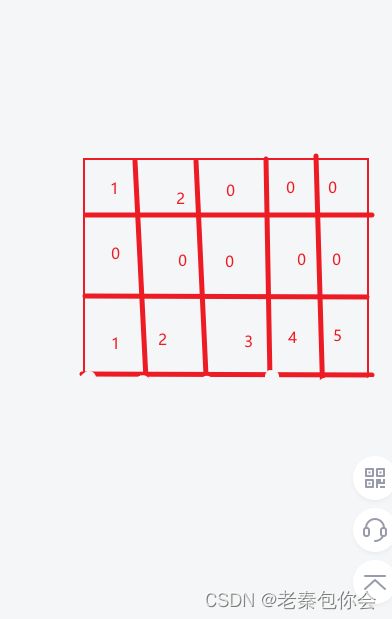
上面模型是我想的,但实际却是 下面这个图

· 所以我们在定义二维数组的时候行可以省略,但是列不能省略,当每行存储几个元素只要给出就能通过计算出有几行
简单的说二维数组的存储是连续的,或者可以说二维数组是一维数组组成的数组,
数组越界
当一个数组有n个元素
数组的下标是有范围限制的。数组的下标规定如果小于0,或者大于n - 1,就是数组越界访问了,C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,最好要自己检查
数组作为函数参数
下面我们利用冒泡排序来介绍这里
冒泡排序就是相邻的两个元素进行比较,排序过程中我们要清楚进行几趟排序,每趟排序有多少给元素进行比较,每一趟比较完,是否要去避免一些元素重复比较
#include
int main()
{
int arr[] = { 10,9,8,7,6,5,4,3,2,1 };
int sz = sizeof arr / sizeof(int);
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int num = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = num;
}
}
}
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
getchar();
return 0;
} 如果我们把冒泡排序封装到一个函数里
#include
void sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)//趟数
{
int j = 0;
for (j = 0; j < sz - 1; j++)
{
if (arr[j] > arr[j + 1])
{
int num = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = num;
}
}
}
}
int main()
{
int arr[] = { 10,9,8,7,4,5,6,1,2,3 };
int sz = sizeof arr / sizeof(int);
sort(arr, sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
getchar();
return 0;
} 是一样的效果,可能有一些小可爱就会犯一个错误,就是直接传数组进去,然后在函数内部求长度,这就需要我们理解数组名是啥
数组名是什么?

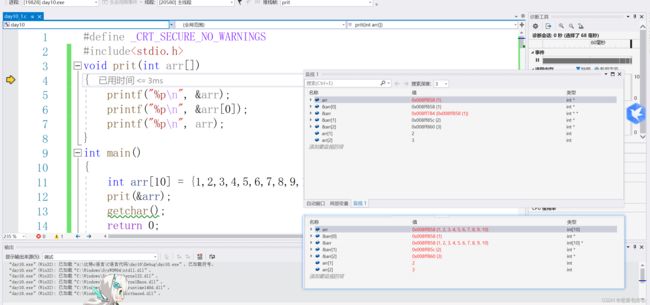
需要注意的是sizeof(arr)这个数组名表示整个数组的大小,,&arr也是表示数组的大小,除此之外遇到的数组名都是首元素的地址
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
//prit(&arr);
printf("%p\n", &arr);//整个数组的地址
printf("%p\n", &arr + 1);
printf("%p\n", &arr[0]);
printf("%p\n", arr + 1);
printf("%p\n", &arr[0] + 1);
printf("%p\n", &arr[0 + 1]);
getchar();
return 0;
}得到下一个元素的地址,的写法可以是如上图
#include
void prit(int arr[])
{
printf("%p\n", &arr);
printf("%p\n", &arr + 1);
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%p\n", arr + 1);
printf("%p\n", &arr[0] + 1);
printf("%p\n", &arr[0 + 1]);
printf("_________________");
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
prit(&arr);
printf("%p\n", &arr);//整个数组的地址
printf("%p\n", &arr + 1);
printf("%p\n", &arr[0]);
printf("%p\n", arr + 1);
printf("%p\n", &arr[0] + 1);
printf("%p\n", &arr[0 + 1]);
getchar();
return 0;
} 这个代码可以更清楚传&arr和传arr的区别
总结:
数组的定义和使用就暂时讲到这里了,有不懂的小可爱可以私聊我