8 种「Python 程序」定时执行方式
在日常工作中,我们常常会用到需要周期性执行的任务,一种方式是采用 Linux 系统自带的 crond 结合命令行实现,另外一种方式是直接使用Python。
最近我整理了一下 Python 定时任务的实现方式,建议收藏后学习。
![]()
利用while True: + sleep()实现定时任务
位于 time 模块中的 sleep(secs) 函数,可以实现令当前执行的线程暂停 secs 秒后再继续执行。所谓暂停,即令当前线程进入阻塞状态,当达到 sleep() 函数规定的时间后,再由阻塞状态转为就绪状态,等待 CPU 调度。
基于这样的特性我们可以通过while死循环+sleep()的方式实现简单的定时任务。
代码示例:
import datetime
import time
def time_printer():
now =
datetime.datetime.now()
ts =
now.strftime('%Y-%m-%d %H:%M:%S')
print('do func time :', ts)
def loop_monitor():
while True:
time_printer()
time.sleep(5)
# 暂停5秒
if __name__ ==
"__main__":
loop_monitor()主要缺点:
只能设定间隔,不能指定具体的时间,比如每天早上8:00
sleep 是一个阻塞函数,也就是说 sleep 这一段时间,程序什么也不能操作。
使用Timeloop库运行定时任务
Timeloop是一库,可用于运行多周期任务。这是一个简单的库,它使用decorator模式在线程中运行标记函数。
示例代码:
import time
from timeloop import
Timeloop
from datetime import
timedelta
tl= Timeloop()
@tl.job(interval=timedelta(seconds=2))def
sample_job_every_2s():
print "2s job current time :
{}".format(time.ctime())
@tl.job(interval=timedelta(seconds=5))def
sample_job_every_5s():
print "5s job current time :
{}".format(time.ctime())
@tl.job(interval=timedelta(seconds=10))
def sample_job_every_10s():
print "10s job current time :
{}".format(time.ctime())
利用内置模块sched实现定时任务
sched模块实现了一个通用事件调度器,在调度器类使用一个延迟函数等待特定的时间,执行任务。同时支持多线程应用程序,在每个任务执行后会立刻调用延时函数,以确保其他线程也能执行。
class sched.scheduler(timefunc, delayfunc)这个类定义了调度事件的通用接口,它需要外部传入两个参数,timefunc是一个没有参数的返回时间类型数字的函数(常用使用的如time模块里面的time),delayfunc应该是一个需要一个参数来调用、与timefunc的输出兼容、并且作用为延迟多个时间单位的函数(常用的如time模块的sleep)。
代码示例:
import datetime
import time
import sched
def time_printer():
now = datetime.datetime.now()
ts = now.strftime('%Y-%m-%d %H:%M:%S')
print('do func time :', ts)
loop_monitor()
def loop_monitor():
s = sched.scheduler(time.time, time.sleep)# 生成调度器
s.enter(5, 1, time_printer, ())
s.run()
if __name__ ==
"__main__":
loop_monitor()scheduler对象主要方法:
enter(delay, priority, action, argument),安排一个事件来延迟delay个时间单位。
cancel(event):从队列中删除事件。如果事件不是当前队列中的事件,则该方法将跑出一个ValueError。
run():运行所有预定的事件。这个函数将等待(使用传递给构造函数的delayfunc()函数),然后执行事件,直到不再有预定的事件。
个人点评:比threading.Timer更好,不需要循环调用。
![]()
利用调度模块schedule实现定时任务
schedule是一个第三方轻量级的任务调度模块,可以按照秒,分,小时,日期或者自定义事件执行时间。schedule允许用户使用简单、人性化的语法以预定的时间间隔定期运行Python函数(或其它可调用函数)。
先来看代码,是不是不看文档就能明白什么意思?
import schedule
import time
def job():
print("I'm working...")
schedule.every(10).seconds.do(job)
schedule.every(10).minutes.do(job)
schedule.every().hour.do(job)
schedule.every().day.at("10:30").do(job)
schedule.every(5).to(10).minutes.do(job)
schedule.every().monday.do(job)
schedule.every().wednesday.at("13:15").do(job)
schedule.every().minute.at(":17").do(job)
while True:
schedule.run_pending()
time.sleep(1)装饰器:通过 @repeat() 装饰静态方法
import time
from schedule import
every, repeat, run_pending
@repeat(every().second)
def job():
print('working...')
while True:
run_pending()
time.sleep(1)传递参数:
import schedule
def greet(name):
print('Hello', name)
schedule.every(2).seconds.do(greet, name='Alice')
schedule.every(4).seconds.do(greet, name='Bob')
while True:
schedule.run_pending()装饰器同样能传递参数:
from schedule import
every, repeat, run_pending
@repeat(every().second, 'World')
@repeat(every().minute, 'Mars')def hello(planet):
print('Hello', planet)while True:
run_pending()取消任务:
import schedule
i = 0
def some_task():
global i
i += 1
print(i)
if i == 10:
schedule.cancel_job(job)
print('cancel job') exit(0)
job = schedule.every().second.do(some_task)
while True:
schedule.run_pending()运行一次任务:
import time
import schedule
def job_that_executes_once():
print('Hello')
return
schedule.CancelJob
schedule.every().minute.at(':34').do(job_that_executes_once)
while True:
schedule.run_pending()
time.sleep(1)根据标签检索任务:
# 检索所有任务:
schedule.get_jobs()import schedule
def greet(name):
print('Hello {}'.format(name))schedule.every().day.do(greet, 'Andrea').tag('daily-tasks', 'friend')
schedule.every().hour.do(greet, 'John').tag('hourly-tasks', 'friend')
schedule.every().hour.do(greet, 'Monica').tag('hourly-tasks', 'customer')
schedule.every().day.do(greet, 'Derek').tag('daily-tasks', 'guest')
friends = schedule.get_jobs('friend')print(friends)根据标签取消任务:
# 取消所有任务:
schedule.clear()import schedule
def greet(name):
print('Hello {}'.format(name))
if name == 'Cancel':
schedule.clear('second-tasks')
print('cancel second-tasks')
schedule.every().second.do(greet, 'Andrea').tag('second-tasks', 'friend')
schedule.every().second.do(greet, 'John').tag('second-tasks', 'friend')
schedule.every().hour.do(greet, 'Monica').tag('hourly-tasks', 'customer')
schedule.every(5).seconds.do(greet, 'Cancel').tag('daily-tasks', 'guest')
while True:
schedule.run_pending()运行任务到某时间:
import schedule from datetime import datetime, timedelta, time
def job():
print('working...')
schedule.every().second.until('23:59').do(job) # 今天23:59停止schedule.every().second.until('2030-01-01 18:30').do(job) # 2030-01-01 18:30停止schedule.every().second.until(timedelta(hours=8)).do(job) # 8小时后停止schedule.every().second.until(time(23, 59, 59)).do(job) # 今天23:59:59停止schedule.every().second.until(datetime(2030, 1, 1, 18, 30, 0)).do(job) # 2030-01-01 18:30停止
while True:
schedule.run_pending()马上运行所有任务(主要用于测试):
import schedule
def job():
print('working...')
def job1():
print('Hello...')
schedule.every().monday.at('12:40').do(job)
schedule.every().tuesday.at('16:40').do(job1)
schedule.run_all()schedule.run_all(delay_seconds=3) # 任务间延迟3秒并行运行:使用 Python 内置队列实现:
import threadingimport timeimport schedule
def job1():
print("I'm running on thread %s" % threading.current_thread())
def job2():
print("I'm running on thread %s" % threading.current_thread())
def job3():
print("I'm running on thread %s" % threading.current_thread())
def run_threaded(job_func):
job_thread = threading.Thread(target=job_func) job_thread.start()schedule.every(10).seconds.do(run_threaded, job1)schedule.every(10).seconds.do(run_threaded, job2)schedule.every(10).seconds.do(run_threaded, job3)
while True:
schedule.run_pending()
time.sleep(1)![]()
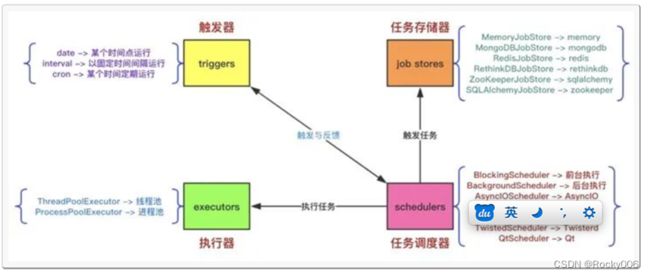
利用任务框架APScheduler实现定时任务
APScheduler(advanceded python scheduler)基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个Python定时任务系统。
它有以下三个特点:
类似于 Liunx Cron 的调度程序(可选的开始/结束时间)
基于时间间隔的执行调度(周期性调度,可选的开始/结束时间)
一次性执行任务(在设定的日期/时间运行一次任务)
APScheduler有四种组成部分:
触发器(trigger) 包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。作业存储(job store) 存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。
执行器(executor) 处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
调度器(scheduler) 是其他的组成部分。你通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。通过配置executor、jobstore、trigger,使用线程池(ThreadPoolExecutor默认值20)或进程池(ProcessPoolExecutor 默认值5)并且默认最多3个(max_instances)任务实例同时运行,实现对job的增删改查等调度控制
示例代码:
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime# 输出时间
def job():
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))# Blocking
Schedulersched = Blocking
Scheduler()sched.add_job(my_job, 'interval', seconds=5, id='my_job_id')sched.start()使用分布式消息系统Celery实现定时任务
Celery是一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具, 也可用于任务调度。Celery 的配置比较麻烦,如果你只是需要一个轻量级的调度工具,Celery 不会是一个好选择。
Celery 是一个强大的分布式任务队列,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行。我们通常使用它来实现异步任务(async task)和定时任务(crontab)。异步任务比如是发送邮件、或者文件上传, 图像处理等等一些比较耗时的操作 ,定时任务是需要在特定时间执行的任务。
需要注意,celery本身并不具备任务的存储功能,在调度任务的时候肯定是要把任务存起来的,因此在使用celery的时候还需要搭配一些具备存储、访问功能的工具,比如:消息队列、Redis缓存、数据库等。官方推荐的是消息队列RabbitMQ,有些时候使用Redis也是不错的选择。
它的架构组成如下图:

Celery架构,它采用典型的生产者-消费者模式,主要由以下部分组成:
Celery Beat,任务调度器,Beat进程会读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给任务队列。
Producer:需要在队列中进行的任务,一般由用户、触发器或其他操作将任务入队,然后交由workers进行处理。调用了Celery提供的API、函数或者装饰器而产生任务并交给任务队列处理的都是任务生产者。
Broker,即消息中间件,在这指任务队列本身,Celery扮演生产者和消费者的角色,brokers就是生产者和消费者存放/获取产品的地方(队列)。
Celery Worker,执行任务的消费者,从队列中取出任务并执行。通常会在多台服务器运行多个消费者来提高执行效率。
Result Backend:任务处理完后保存状态信息和结果,以供查询。Celery默认已支持Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy等方式。
实际应用中,用户从Web前端发起一个请求,我们只需要将请求所要处理的任务丢入任务队列broker中,由空闲的worker去处理任务即可,处理的结果会暂存在后台数据库backend中。我们可以在一台机器或多台机器上同时起多个worker进程来实现分布式地并行处理任务。
Celery定时任务实例:
Python Celery & RabbitMQ Tutorial
Celery 配置实践笔记
![]()
使用数据流工具Apache Airflow实现定时任务
Apache Airflow 是Airbnb开源的一款数据流程工具,目前是Apache孵化项目。以非常灵活的方式来支持数据的ETL过程,同时还支持非常多的插件来完成诸如HDFS监控、邮件通知等功能。Airflow支持单机和分布式两种模式,支持Master-Slave模式,支持Mesos等资源调度,有非常好的扩展性。被大量公司采用。
Airflow使用Python开发,它通过DAGs(Directed Acyclic Graph, 有向无环图)来表达一个工作流中所要执行的任务,以及任务之间的关系和依赖。比如,如下的工作流中,任务T1执行完成,T2和T3才能开始执行,T2和T3都执行完成,T4才能开始执行。

Airflow提供了各种Operator实现,可以完成各种任务实现:
BashOperator – 执行 bash 命令或脚本。
SSHOperator – 执行远程 bash 命令或脚本(原理同 paramiko 模块)。
PythonOperator – 执行 Python 函数。
EmailOperator – 发送 Email。
HTTPOperator – 发送一个 HTTP 请求。
MySqlOperator, SqliteOperator, PostgresOperator, MsSqlOperator, OracleOperator, JdbcOperator, 等,执行 SQL 任务。
DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator…
除了以上这些 Operators 还可以方便的自定义 Operators 满足个性化的任务需求。
一些情况下,我们需要根据执行结果执行不同的任务,这样工作流会产生分支。如:
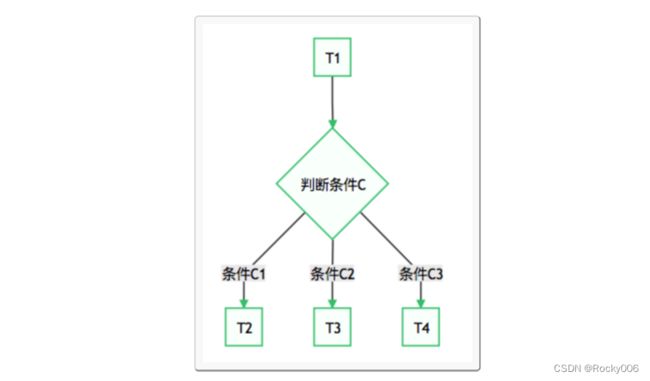
这种需求可以使用BranchPythonOperator来实现。
< END >