MySQL数据库——多表查询介绍
目录
数据准备
笛卡尔积
内连接
显示内连接
隐式内连接
外连接
左外连接
右外连接
子查询
基本运用举例
子查询的不同情况
子查询的结果是单行单列的
子查询的结果是多行单列的
子查询的结果是单行多列的
子查询的结果是多行多列的
子查询小结
多表查询的练习
数据准备
部门表
员工表
岗位表
工资等级表
1.查询所有员工信息。查询员工编号,员工姓名,工资,职务名称,职务描述
2.查询员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置
3.查询员工姓名,工资,工资等级
4.查询员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级
5.查询出部门编号、部门名称、部门位置、部门人数
6.查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询
数据准备
# 创建部门表
CREATE TABLE dept(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
#插入部门表数据
INSERT INTO dept (NAME) VALUES ('开发部'),('市场部'),('财务部');
# 创建员工表
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
gender CHAR(1), -- 性别
salary DOUBLE, -- 工资
join_date DATE, -- 入职日期
dept_id INT,
FOREIGN KEY (dept_id) REFERENCES dept(id) -- 外键,关联部门表(部门表的主键)
);
#插入员工表数据
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('孙悟空','男',7200,'2013-02-24',1);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('猪八戒','男',3600,'2010-12-02',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('唐僧','男',9000,'2008-08-08',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('白骨精','女',5000,'2015-10-07',3);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('蜘蛛精','女',4500,'2011-03-14',1);成功插入后数据如下:

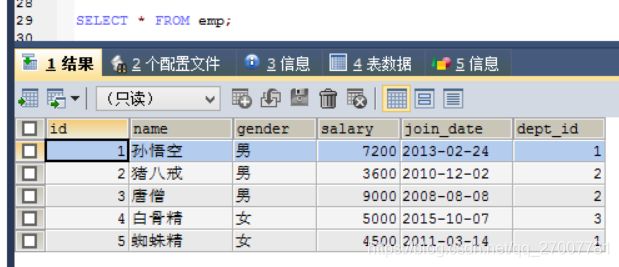
笛卡尔积
当执行SELECT * FROM 表1,表2时,这时候两个表中的记录会进行交叉连接,任意组合,组合出来的结果数是他们记录数的乘积。我们把这个得到的结果成为笛卡尔积,笛卡尔积本身没什么作用,但是加上限制条件时,作用就体现出来了,当我们加上条件SELECT * FROM 表1 别名1, 表2 别名2 WHERE 别名1.xx=别名2.xx,让从表的外键与主键相等时,这时候会剔除没用的交叉记录,这样得到的结果就是内连接了
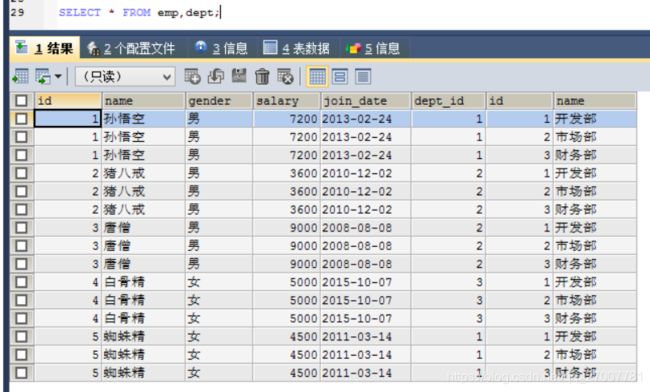
例如:SELECT * FROM emp,dept;
结果如下:总共十五条,是emp表和dept记录数的乘积

内连接
内连接(Inner Join)又称简单连接或自然连接,是一种常见的连接查询。内连接使用比较运算符对两个表中的数据进行比较,并列出与连接条件匹配的数据行,组合成新的纪录。也就是说在内连接查询中,只有满足条件的记录才能出现在查询结果中
内连接有两种:显示内连接和隐式内连接,隐式内连接是写法比较简单,直接用WHERE,而显示内连接说是性能比较高,但是我没检测出来,显示内连接的INNER可写可不写
内连接取的是两张表符合连接条件的交集

显示内连接
语法:SELECT * FROM 表1 别名1 [INNER] JOIN 表2 别名2 ON 别名1.xx= 别名2.xx
例子:SELECT * FROM emp t1 [INNER] JOIN dept t2 ON t1.`dept_id` = t2.`id`

隐式内连接
使用where条件消除无用数据
语法:SELECT * FROM 表1 别名1, 表2 别名2 WHERE 别名1.xx=别名2.xx
例子:SELECT * FROM emp t1,dept t2 WHERE t1.`dept_id` = t2.`id`

外连接
外连接就是内连接条件交集的部分加上自己特有的部分
左外连接
查询的是左表所有数据以及和右表的交集部分
语法:SELECT * FROM 表1 别名1 LEFT [OUTER] JOIN 表2 别名2 ON 别名1.xx=别名2.xx(LEFT OUTER JOIN简写LEFT JOIN)
例子:现在员工表里面添加小白龙信息
INSERT INTO emp(NAME,gender,salary) VALUES ('白龙马','男','3000');
在用左外连接做查询看得到的结果:



右外连接
查询的是右表所有数据以及和左表的交集部分
语法:SELECT * FROM 表1 别名1 RIGHT [OUTER] JOIN 表2 别名2 ON 别名1.xx=别名2.xx(RIGHT OUTER JOIN可以简写成RIGHT JOIN)
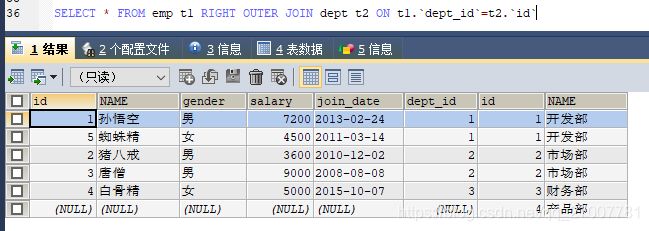
例子:我们在部门表里添加一个产品部
INSERT INTO dept(id,NAME) VALUES ('4','产品部');
SELECT * FROM emp t1 RIGHT OUTER JOIN dept t2 ON t1.`dept_id`=t2.`id`
以dept为主表,主表部门表记录完全显示,根据条件符合的左表记录展示,不符合的都填充null


子查询
概念:查询中嵌套查询,称嵌套查询为子查询。
基本运用举例
-- 最终目的:查询工资最高的员工信息
-- 1 查询最高的工资是多少 9000
SELECT MAX(salary) FROM emp;-- 2 查询员工信息,并且工资等于9000的
SELECT * FROM emp WHERE emp.`salary` = 9000;-- 一条sql就完成这个操作。子查询
SELECT * FROM emp WHERE emp.`salary` = (SELECT MAX(salary) FROM emp);

子查询的不同情况
子查询的结果是单行单列的
这种子查询结果可以做为条件,使用运算符去判断,运算符=、>、<、>=、<=、<>
例如:查询员工工资小于平均工资的人(跟上面的基础案例一样)
SELECT * FROM emp WHERE emp.salary < (SELECT AVG(salary) FROM emp);

子查询的结果是多行单列的
子查询结果是多行单列,结果集类似于一个数组,子查询可以作为条件,使用运算符in all any来判断
SELECT * FROM 表1 别名1 WHERE 列1 [IN, ALL, ANY] (SELECT 列 FROM 表2 别名2 WHERE 条件)
例如:查询'财务部'和'市场部'所有的员工信息
SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部';
SELECT * FROM emp WHERE dept_id = 3 OR dept_id = 2;
-- 子查询
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME = '财务部' OR NAME = '市场部');

子查询的结果是单行多列的
这种情况用的比较少,因为查询出来的多列可能是数据类型不同的,不如多行单列来的纯粹,也是使用in all any等关键字,不过是多个列同时判断
SELECT * FROM 表1 别名1 WHERE (列1,列2) IN (SELECT 列1, 列2 FROM 表2 别名2 WHERE 条件)
子查询的结果是多行多列的
子查询可以作为一张虚拟表参与查询
SELECT * FROM 表1 别名1 , (SELECT ....) 别名2 WHERE 条件
例如:查询员工入职日期是2011-11-11日之后的员工信息和部门信息
SELECT * FROM dept t1 ,(SELECT * FROM emp WHERE emp.`join_date` > '2011-11-11') t2 WHERE t1.id = t2.dept_id;

子查询小结
1.子查询结果只要是单列,则在 WHERE 后面作为条件
2.子查询结果只要是多列,一般在 FROM 后面作为表进行二次查询(单行多列先不做考虑)
多表查询的练习
数据准备
-- 部门表
CREATE TABLE dept (
id INT PRIMARY KEY PRIMARY KEY, -- 部门id
dname VARCHAR(50), -- 部门名称
loc VARCHAR(50) -- 部门所在地
);
-- 添加4个部门
INSERT INTO dept(id,dname,loc) VALUES
(10,'教研部','北京'),
(20,'学工部','上海'),
(30,'销售部','广州'),
(40,'财务部','深圳');
-- 职务表,职务名称,职务描述
CREATE TABLE job (
id INT PRIMARY KEY,
jname VARCHAR(20),
description VARCHAR(50)
);
-- 添加4个职务
INSERT INTO job (id, jname, description) VALUES
(1, '董事长', '管理整个公司,接单'),
(2, '经理', '管理部门员工'),
(3, '销售员', '向客人推销产品'),
(4, '文员', '使用办公软件');
-- 员工表
CREATE TABLE emp (
id INT PRIMARY KEY, -- 员工id
ename VARCHAR(50), -- 员工姓名
job_id INT, -- 职务id
mgr INT , -- 上级领导
joindate DATE, -- 入职日期
salary DECIMAL(7,2), -- 工资
bonus DECIMAL(7,2), -- 奖金
dept_id INT, -- 所在部门编号
CONSTRAINT emp_jobid_ref_job_id_fk FOREIGN KEY (job_id) REFERENCES job (id),
CONSTRAINT emp_deptid_ref_dept_id_fk FOREIGN KEY (dept_id) REFERENCES dept (id)
);
-- 添加员工
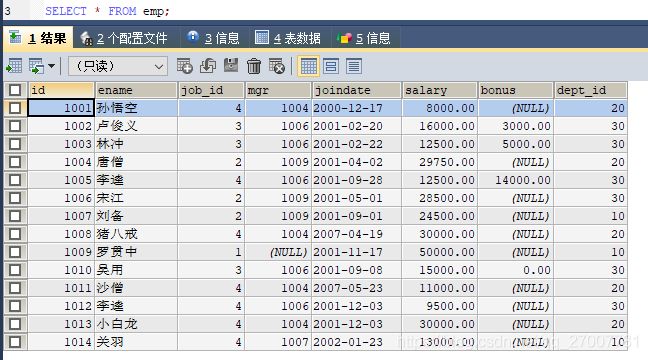
INSERT INTO emp(id,ename,job_id,mgr,joindate,salary,bonus,dept_id) VALUES
(1001,'孙悟空',4,1004,'2000-12-17','8000.00',NULL,20),
(1002,'卢俊义',3,1006,'2001-02-20','16000.00','3000.00',30),
(1003,'林冲',3,1006,'2001-02-22','12500.00','5000.00',30),
(1004,'唐僧',2,1009,'2001-04-02','29750.00',NULL,20),
(1005,'李逵',4,1006,'2001-09-28','12500.00','14000.00',30),
(1006,'宋江',2,1009,'2001-05-01','28500.00',NULL,30),
(1007,'刘备',2,1009,'2001-09-01','24500.00',NULL,10),
(1008,'猪八戒',4,1004,'2007-04-19','30000.00',NULL,20),
(1009,'罗贯中',1,NULL,'2001-11-17','50000.00',NULL,10),
(1010,'吴用',3,1006,'2001-09-08','15000.00','0.00',30),
(1011,'沙僧',4,1004,'2007-05-23','11000.00',NULL,20),
(1012,'李逵',4,1006,'2001-12-03','9500.00',NULL,30),
(1013,'小白龙',4,1004,'2001-12-03','30000.00',NULL,20),
(1014,'关羽',4,1007,'2002-01-23','13000.00',NULL,10);
-- 工资等级表
CREATE TABLE salarygrade (
grade INT PRIMARY KEY, -- 级别
losalary INT, -- 最低工资
hisalary INT -- 最高工资
);
-- 添加5个工资等级
INSERT INTO salarygrade(grade,losalary,hisalary) VALUES
(1,7000,12000),
(2,12010,14000),
(3,14010,20000),
(4,20010,30000),
(5,30010,99990);
部门表

员工表
岗位表
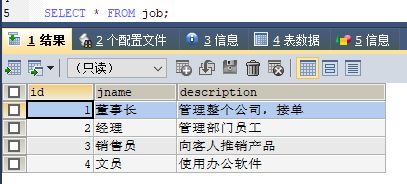
工资等级表

总体分析思路:
1.分析我们所要查询的字段在哪些表中
2.这些表有什么关联条件
3.先写表,给表起别名,在写条件,最后写要查询的列
1.查询所有员工信息。查询员工编号,员工姓名,工资,职务名称,职务描述
分析:
1.员工编号,员工姓名,工资,需要查询emp表 职务名称,职务描述 需要查询job表
2.查询条件 emp.job_id = job.idSELECT t1.`id`, -- 员工编号 t1.`ename`, -- 员工姓名 t1.`salary`,-- 工资 t2.`jname`, -- 职务名称 t2.`description` -- 职务描述 FROM emp t1, job t2 WHERE t1.`job_id` = t2.`id`;

2.查询员工编号,员工姓名,工资,职务名称,职务描述,部门名称,部门位置
分析:
1. 员工编号,员工姓名,工资 emp 职务名称,职务描述 job 部门名称,部门位置 dept
2. 条件: emp.job_id = job.id and emp.dept_id = dept.idSELECT t1.`id`, -- 员工编号 t1.`ename`, -- 员工姓名 t1.`salary`,-- 工资 t2.`jname`, -- 职务名称 t2.`description`, -- 职务描述 t3.`dname`, -- 部门名称 t3.`loc` -- 部门位置 FROM emp t1, job t2,dept t3 WHERE t1.`job_id` = t2.`id` AND t1.`dept_id` = t3.`id`;

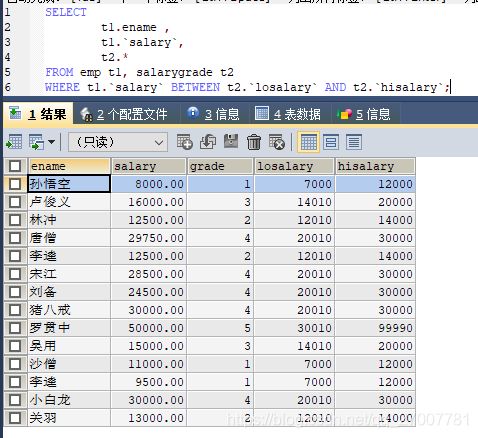
3.查询员工姓名,工资,工资等级
分析:
1.员工姓名,工资 emp 工资等级 salarygrade
2.条件 emp.salary >= salarygrade.losalary and emp.salary <= salarygrade.hisalary
emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalary
SELECT t1.ename , t1.`salary`, t2.* FROM emp t1, salarygrade t2 WHERE t1.`salary` BETWEEN t2.`losalary` AND t2.`hisalary`;
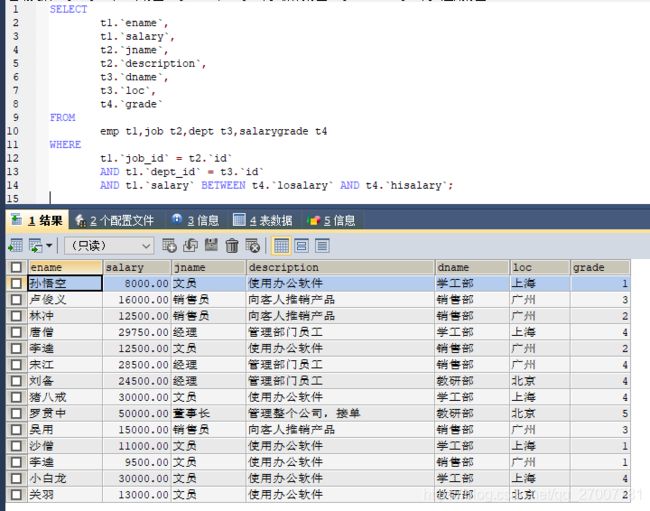
4.查询员工姓名,工资,职务名称,职务描述,部门名称,部门位置,工资等级
分析:
1. 员工姓名,工资 emp , 职务名称,职务描述 job 部门名称,部门位置,dept 工资等级 salarygrade
2. 条件: emp.job_id = job.id and emp.dept_id = dept.id and emp.salary BETWEEN salarygrade.losalary and salarygrade.hisalarySELECT t1.`ename`, t1.`salary`, t2.`jname`, t2.`description`, t3.`dname`, t3.`loc`, t4.`grade` FROM emp t1,job t2,dept t3,salarygrade t4 WHERE t1.`job_id` = t2.`id` AND t1.`dept_id` = t3.`id` AND t1.`salary` BETWEEN t4.`losalary` AND t4.`hisalary`;
5.查询出部门编号、部门名称、部门位置、部门人数
分析:
1.部门编号、部门名称、部门位置 dept 表。 部门人数 emp表
2.使用分组查询。按照emp.dept_id完成分组,查询count(id)
3.使用子查询将第2步的查询结果和dept表进行关联查询SELECT t1.`id`,t1.`dname`,t1.`loc` , t2.total FROM dept t1, (SELECT dept_id,COUNT(id) total FROM emp GROUP BY dept_id) t2 WHERE t1.`id` = t2.dept_id;

6.查询所有员工的姓名及其直接上级的姓名,没有领导的员工也需要查询
分析:
1.姓名 emp, 直接上级的姓名 emp
* emp表的id 和 mgr 是自关联
2.条件 emp.id = emp.mgr
3.查询左表的所有数据,和 交集数据
* 使用左外连接查询SELECT t1.ename, t1.mgr, t2.`id`, t2.`ename` FROM emp t1 LEFT JOIN emp t2 ON t1.`mgr` = t2.`id`;
