腾讯太狠:10亿QPS的IM,如何实现?
前言
在40岁老架构师 尼恩的读者社区(50+)中,很多小伙伴拿高薪,完成架构的升级,进入架构师赛道,打开薪酬天花板。
然后,在架构师的面试过程中,常常会遇到IM架构的问题:
如果要你从0到1做IM架构, 需要从哪些方面展开?
你是怎么做项目的IM架构的?
10亿级以上qps的高并发IM,该如何架构?
现在,40岁老架构师尼恩,站在腾讯企业IM的巨人肩膀,给大家提供一份比较全面的参考答案。使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让你的面试官爱到 “不能自已、口水直流”。
也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典》V90版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请到公号【技术自由圈】获取
文章目录
-
- 前言
- 1、超高并发:核心接口峰值达到10亿级QPS
- 2、企业微信的业务场景分析
- 3、企业微信的架构分层
- 4、号段模式 seqsvr消息序列号架构
-
- 号段模式 的分布式ID总体架构
- 分号段共享存储架构:
- 5、消息收发模型架构
- 6、群聊消息写扩散架构
-
- 读扩散与写扩散
- 企业微信的写扩散架构
- 7、系统架构异步解耦
- 8、业务隔离架构设计
- 9、过载保护架构设计
-
- 服务过载问题
- 解决方案
- 10、万人大群的架构优化
-
- 10.1 技术背景
- 10.2 问题分析
- 10.3 优化1:并发限制
- 10.4 优化2:合并插入
- 10.5 优化3:业务降级
- 11、回执消息架构设计
-
- 11.1 技术背景
- 11.2 实现方案
- 11.3 优化1:异步化
- 11.4 优化2:合并处理
- 11.5 读写覆盖解决
- 12、撤回消息的架构设计
-
- 12.1 技术难点
- 12.2 解决方案
- 说在最后:有问题可以找老架构取经
- 推荐相关阅读
1、超高并发:核心接口峰值达到10亿级QPS
企业微信作为一款Tob场景的聊天im工具,用于工作场景的沟通,有着较为明显的高峰效应。
工作时间上午9:0012:00,下午14:0018:00,是聊天的高峰,消息量剧增。
核心接口,峰值达到10亿级QPS
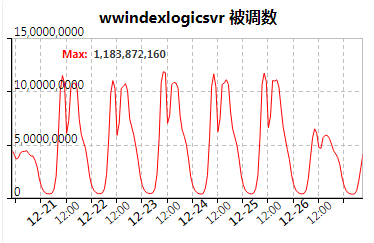
以上仅仅是核心接口。
在消息的ID生产模块,也有1000WQps以上。
2、企业微信的业务场景分析
企业微信是一款收费产品,消息系统的稳定性、可靠性、安全性尤其重要。
与TC的微信不同,而且针对toB场景的消息系统,需要支持更为复杂的业务场景。
针对toB场景的特有业务有:
- 1)消息鉴权:关系类型有群关系、同企业同事关系、好友关系、集团企业关系、圈子企业关系。收发消息双方需存在至少一种关系才允许发消息;
- 2)回执消息:每条消息都需记录已读和未读人员列表,涉及频繁的状态读写操作;
- 3)撤回消息:支持24小时的有效期撤回动作;
- 4)消息存储:云端存储时间跨度长,最长可支持180天消息存储,数百TB用户消息需优化,减少机器成本;
- 5)万人群聊:群人数上限可支持10000人,一条群消息就像一次小型的DDoS攻击;
- 6)微信互通:两个异构的im系统直接打通,可靠性和一致性尤其重要。
3、企业微信的架构分层

如上所示,整体架构分层如下。
1)接入层:
接收客户端的请求,根据类型转发到对应的安全分发层。
支持两种连接类型: 客户端可以通过长连或者短连接。
- 优先用长连接发起请求,
- 如果长连失败,则选用短连重试。
2)安全分发层:
http类型的WEB服务,
安全分发层 接收接入的的数据包,校验用户的session状态,
进行安全校验,并用后台派发的秘钥去解包,如解密失败则拒绝请求。
如果 解密成功,则解密为明文包体, 然后进行分发,转发到后端逻辑层对应的svr。
3)逻辑层:
各种业务微服务和异步处理服务,使用自研的rpc框架(类似dubbo)通信。
逻辑进行数据整合和逻辑处理。
和外部系统的通信,通过http协议,包括微信互通、手机厂商的推送平台等。
4)存储层:
使用kv类型的存储组件:采用的是基于levelDB模型开发msgkv。
消息的key为 消息的全局有序编号,使用SeqSvr序列号生成器,保证派发的seq单调递增不回退。
消息的key也用于消息的收发协议
4、号段模式 seqsvr消息序列号架构
微信服务器端为每一份需要与客户端同步的数据(例如消息)都会赋予一个唯一的、递增的序列号(后文称为sequence),作为这份数据的版本号。
在客户端与服务器端同步的时候,客户端会带上已经同步下去数据的最大版本号,后台会根据客户端最大版本号与服务器端的最大版本号,计算出需要同步的增量数据,返回给客户端。这样不仅保证了客户端与服务器端的数据同步的可靠性,同时也大幅减少了同步时的冗余数据。
这里不用乐观锁机制来生成版本号,而是使用了一个独立的seqsvr来处理序列号操作,
- 一方面因为业务有大量的sequence查询需求——查询已经分配出去的最后一个sequence,而基于seqsvr的查询操作可以做到非常轻量级,避免对存储层的大量IO查询操作;
- 另一方面微信用户的不同种类的数据存在不同的Key-Value系统中,使用统一的序列号有助于避免重复开发,同时业务逻辑可以很方便地判断一个用户的各类数据是否有更新。
从seqsvr申请的、用作数据版本号的sequence,具有两种基本的性质:
- 递增的64位整型变量
- 每个用户都有自己独立的64位sequence空间
举个例子,小明当前申请的sequence为100,那么他下一次申请的sequence,可能为101,也可能是110,总之一定大于之前申请的100。
而小红呢,她的sequence与小明的sequence是独立开的,假如她当前申请到的sequence为50,然后期间不管小明申请多少次sequence怎么折腾,都不会影响到她下一次申请到的值(很可能是51)。
这里用了每个用户独立的64位sequence的体系,而不是用一个全局的64位(或更高位)sequence,很大原因是全局唯一的sequence会有非常严重的申请互斥问题,不容易去实现一个高性能高可靠的架构。对微信业务来说,每个用户独立的64位sequence空间已经满足业务要求。
微信目前拥有数亿的活跃用户,每时每刻都会有海量sequence申请,这对seqsvr的设计也是个极大的挑战。
那么,既要sequence可靠递增,又要能顶住海量的访问,要如何设计seqsvr的架构?
我们先从seqsvr的架构原型说起。
号段模式 的分布式ID总体架构
什么是号段模式 的分布式ID总体架构? 请参见下面的博文文章,介绍得非常详细
滴滴太狠:分布式ID,如何达到1000Wqps?
不考虑号段模式的话,分布式ID应该是一个巨大的 64 位数组,而我们每一个微信用户,都在这个大数组里独占一格 8bytes 的空间,这个格子就放着用户已经分配出去的最后一个 sequence:cur_seq。
每个用户来申请 sequence 的时候,只需要将用户的 cur_seq+=1,保存回数组,并返回给用户。

图 1. 小明申请了一个 sequence,返回 101
任何一件看起来很简单的事,在海量的访问量下都会变得不简单。
前文提到,seqsvr 需要保证分配出去的 sequence 递增(数据可靠),还需要满足海量的访问量(每天接近万亿级别的访问)。
满足数据可靠的话,我们很容易想到把数据持久化到硬盘,但是按照目前每秒千万级的访问量(~10^7 QPS),基本没有任何硬盘系统能扛住。
后台架构设计很多时候是一门关于权衡的哲学,针对不同的场景去考虑能不能降低某方面的要求,以换取其它方面的提升。仔细考虑我们的需求,我们只要求递增,并没有要求连续,也就是说出现一大段跳跃是允许的(例如分配出的 sequence 序列:1,2,3,10,100,101)。于是我们实现了一个简单优雅的策略:
- 内存中储存最近一个分配出去的 sequence:cur_seq,以及分配上限:max_seq
- 分配 sequence 时,将 cur_seq++,同时与分配上限 max_seq 比较:如果 cur_seq > max_seq,将分配上限提升一个步长 max_seq += step,并持久化 max_seq
- 重启时,读出持久化的 max_seq,赋值给 cur_seq

图 2. 小明、小红、小白都各自申请了一个 sequence,但只有小白的 max_seq 增加了步长 100
这样通过增加一个预分配 sequence 的中间层,在保证 sequence 不回退的前提下,大幅地提升了分配 sequence 的性能。
实际应用中每次提升的步长为 10000,那么持久化的硬盘 IO 次数从之前~10^7 QPS 降低到~10^3 QPS,处于可接受范围。
在正常运作时分配出去的 sequence 是顺序递增的,只有在机器重启后,第一次分配的 sequence 会产生一个比较大的跳跃,跳跃大小取决于步长大小。
分号段共享存储架构:
请求带来的硬盘 IO 问题解决了,可以支持服务平稳运行,但该模型还是存在一个问题:重启时要读取大量的 max_seq 数据加载到内存中。
我们可以简单计算下,以目前 uid(用户唯一 ID)上限 2^32 个、一个 max_seq 8bytes 的空间,数据大小一共为 32GB,从硬盘加载需要不少时间。
另一方面,出于数据可靠性的考虑,必然需要一个可靠存储系统来保存 max_seq 数据,重启时通过网络从该可靠存储系统加载数据。如果 max_seq 数据过大的话,会导致重启时在数据传输花费大量时间,造成一段时间不可服务。
为了解决这个问题,我们引入号段 Section 的概念,uid 相邻的一段用户属于一个号段,而同个号段内的用户共享一个 max_seq,这样大幅减少了 max_seq 数据的大小,同时也降低了 IO 次数。
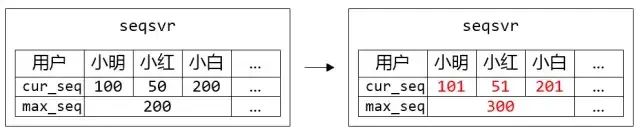
图 3. 小明、小红、小白属于同个 Section,他们共用一个 max_seq。在每个人都申请一个 sequence 的时候,只有小白突破了 max_seq 上限,需要更新 max_seq 并持久化
目前 seqsvr 一个 Section 包含 10 万个 uid,max_seq 数据只有 300+KB,为我们实现从可靠存储系统读取 max_seq 数据重启打下基础。
5、消息收发模型架构
企业微信的消息收发模型采用了推拉结合架构,这种方式可靠性高,设计简单。
以下是消息推拉的时序图:
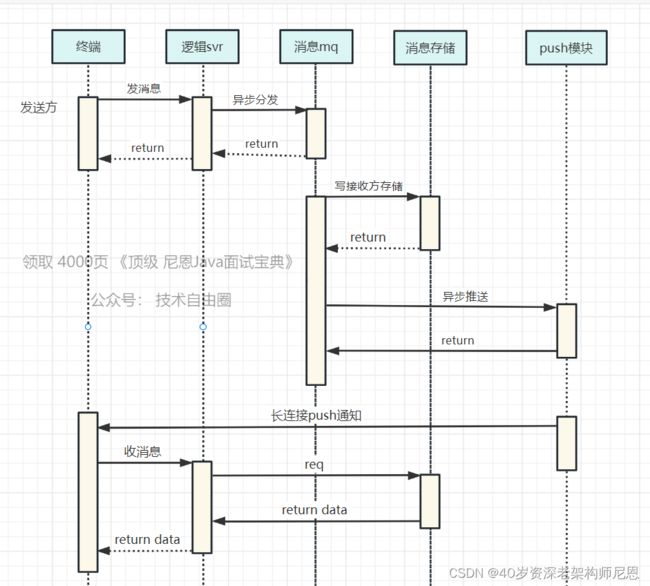
如上图所示,
第一步:后台推入接收方存储
发送方请求后台,把消息写入到接收方的存储,然后push通知接收方。
第二步:接收方收到通知后拉取消息
接受方收到push,主动上来后台收消息。
不重、不丢、及时触达,这三个是消息系统的核心指标:
- 1)实时触达:客户端通过与后台建立长连接,保证消息push的实时触达;
- 2)及时通知:如果客户端长连接不在,进程被kill了,利用手机厂商的推送平台,推送通知,或者直接拉起进程进行收消息;
- 3)消息可达:假如遇到消息洪峰,后台的push滞后,客户端有轮训机制进行兜底,保证消息可达;
- 4)消息防丢:为了防止消息丢失,只要后台逻辑层接收到请求,保证消息写到接收方的存储,失败则重试。如果请求在CGI层就失败,则返回给客户端出消息红点;
- 5)消息排重:客户端在弱网络的场景下,有可能请求已经成功写入存储,回包超时,导致客户端重试发起相同的消息,那么就造成消息重复。为了避免这种情况发生,每条消息都会生成唯一的appinfo,后台通过建立索引进行排重,相同的消息直接返回成功,保证存储只有一条。
6、群聊消息写扩散架构
读扩散与写扩散
所谓**读扩散,**就是: 存储一次,多次读。
所谓写扩散,就是:存储多次,各自读。
放到群聊的场景里说
读扩散,群里的每条消息只存储一份,群成员读取同一份数据。
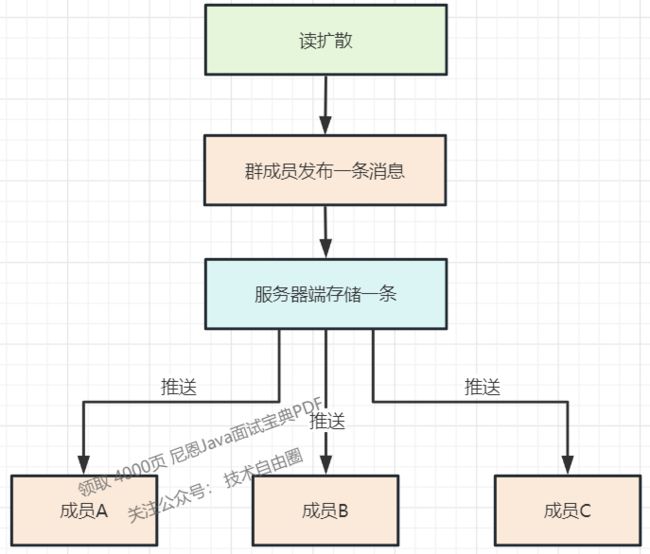
优点:
- 数据实时性高;
- 写入逻辑简单;
- 节约存储空间。
缺点:
- 数据读取会存在热点问题;
- 需要维护离线群成员与未读消息的关系。
写扩散,群里发一条消息,给每个群成员都存储一份,群成员各自读自己的那一份。
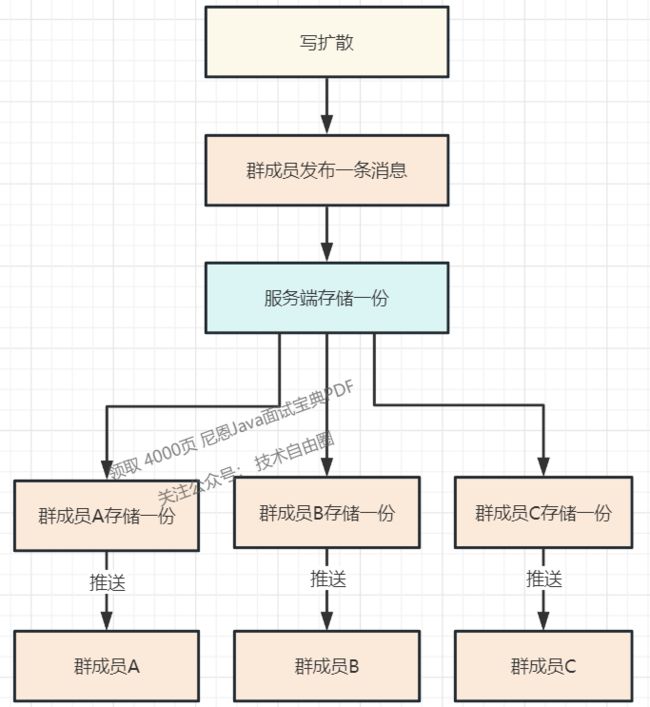
优点:
- 控制逻辑与数据读取逻辑简单;
- 用户数据独立,满足更多的业务场景,比如:回执消息、云端删除等等;
- 一个数据点丢失,不影响其他用户的数据点。
缺点:
- 存储空间的增加;
- 写扩散需要专门的扩散队列;
- 先写扩散后读,实时性差。
企业微信的写扩散架构
每条消息存多份,每个群聊成员在自己的存储都有一份。
优点:
- ① 只需要通过一个序列号就可以增量同步所有消息,收消息协议简单;
- ② 读取速度快,前端体验好;
- ③ 满足更多ToB的业务场景:回执消息、云端删除。
同一条消息,在每个人的视角会有不同的表现。例如:回执消息,发送方能看到已读未读列表,接受方只能看到是否已读的状态。云端删除某条群消息,在自己的消息列表消失,其他人还是可见。
缺点:存储容量的增加。
企业微信采用了扩散写的方式,消息收发简单稳定。存储容量的增加,可以通过冷热分离的方案解决,冷数据存到廉价的SATA盘,扩散读体验稍差,协议设计也相对复杂些。
下图是扩散写的协议设计:
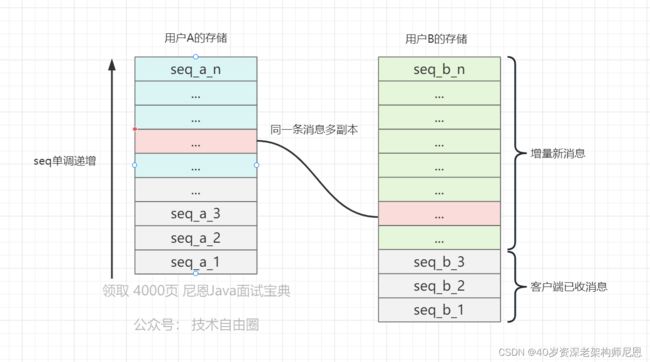
如上图所示:
- 1)每个用户只有一条独立的消息流。同一条消息多副本存在于每个用户的消息流中;
- 2)每条消息有一个seq,在同个用户的消息流中,seq是单调递增的;
- 3)客户端保存消息列表中最大seq,说明客户端已经拥有比该seq小的所有消息。若客户端被push有新消息到达,则用该seq向后台请求增量数据,后台把比此seq大的消息数据返回。
7、系统架构异步解耦
总的方案:
- 企业微信的消息系统,会依赖很多外部模块,甚至外部系统。
- 与外部系统的交互,全设计成异步化。
为了避免外部系统或者外部模块出现故障,拖累消息系统,导致耗时增加,则需要系统解耦。
解耦之后,进行通过异步mq,去异步重试去保证成功,主流程不受影响。
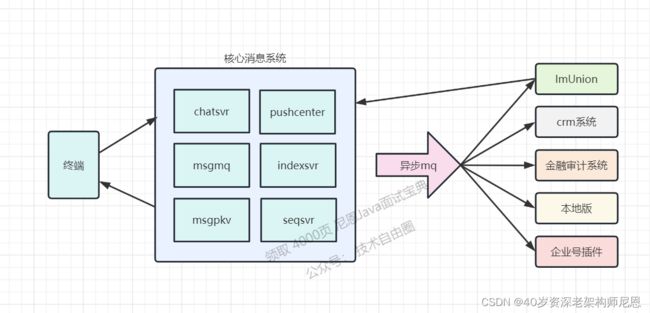
例如ImUnion异步化:
与微信消息互通时,通过外部系统ImUnion进行权限判断,调用耗时较长。
如何异步化:先让客户端成功,如果ImUnion异步失败,则回调客户端使得出红点。
再如消息审计功能异步化:
金融版的消息审计功能,需要把消息同步到审计模块,增加rpc调用。
异步化策略:消息审计功能是非主流程,则异步重试机制,去保证成功,主流程不受影响。
再如crm模块异步:
客户服务的单聊群聊消息,需要把消息同步到crm模块,增加rpc调用。
异步化策略:crm模块异步功能是非主流程,则异步重试机制,去保证成功,主流程不受影响。
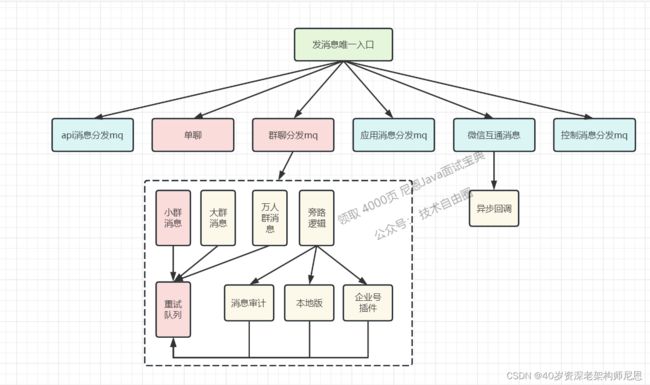
8、业务隔离架构设计
企业微信的消息类型有多种:
- 1)单聊群聊:基础聊天,优先级高;
- 2)api 消息:企业通过api接口下发的消息,有频率限制,优先级中;
- 3)应用消息:系统应用下发的消息,例如公告,有频率限制,优先级中;
- 4)控制消息:不可见的消息。例如群信息变更,会下发控制消息通知群成员,优先级低。
群聊按群人数,又分成3类:
- 1)普通群:小于100人的群,优先级高;
- 2)大 群:小于2000人的群,优先级中;
- 3)万人群:优先级低。
业务繁多:如果不加以隔离,那么其中一个业务的波动有可能引起整个消息系统的瘫痪。
重中之重:需要保证核心链路的稳定,就是企业内部的单聊和100人以下群聊,因为这个业务是最基础的,也是最敏感的,稍有问题,投诉量巨大。
其余的业务:互相隔离,减少牵连。按照优先级和重要程度进行隔离,对应的并发度也做了调整,尽量保证核心链路的稳定性。
解耦和隔离的效果图:
9、过载保护架构设计
关于过载保护的系统化介绍文章, 请参见
10亿级用户,如何做 熔断降级架构?微信和hystrix的架构对比
服务过载问题
上一小结中过载保护策略所带来的问题就是:系统过载返回失败,前端发消息显示失败,显示红点,会严重影响产品体验。
发消息是im系统的最基础的功能,可用性要求达到几乎100%,所以这个策略肯定需要优化。
解决方案
解决方案思路就是:尽管失败,也返回前端成功,后台保证最终成功。
为了保证消息系统的可用性,规避高峰期系统出现过载失败导致前端出红点,做了很多优化。
具体策略如下:
- 1)逻辑层hold住失败请求,返回前端成功,不出红点,后端异步重试,直至成功;
- 2)为了防止在系统出现大面积故障的时候,重试请求压满队列,只hold住半小时的失败请求,半小时后新来的请求则直接返回前端失败;
- 3)为了避免重试加剧系统过载,指数时间延迟重试;
- 4)复杂的消息鉴权(好友关系,企业关系,集团关系,圈子关系),耗时严重,后台波动容易造成失败。如果并非明确鉴权不通过,则幂等重试;
- 5)为了防止作恶请求,限制单个用户和单个企业的请求并发数。例如,单个用户的消耗worker数超过20%,则直接丢弃该用户的请求,不重试。
优化后,后台的波动,前端基本没有感知。
以下是优化前后的流程对比:

10、万人大群的架构优化
10.1 技术背景
企业微信的群人数上限是10000,只要群内每个人都发一条消息,那么扩散量就是10000 * 10000 = 1亿次调用,非常巨大。
10000人投递完成需要的耗时长,影响了消息的及时性。
10.2 问题分析
既然超大群扩散写量大、耗时长,那么自然会想到:超大群是否可以单独拎出来做成扩散读呢。
下面分析一下超大群设计成单副本面临的难点:
- ① 一个超大群,一条消息流,群成员都同步这条流的消息;
- ② 假如用户拥有多个超大群,则需要同步多条流,客户端需维护每条流的seq;
- ③ 客户端卸载重装,并不知道拥有哪些消息流,后台需存储并告知;
- ④ 某个超大群来了新消息,需通知所有群成员,假如push没触达,客户端没办法感知有新消息,不可能去轮训所有的消息流。
综上所述:单副本的方案代价太大。
以下将介绍我们针对万人群聊扩散写的方案,做的一些优化实践。
10.3 优化1:并发限制
万人群的扩散量大,为了是消息尽可能及时到达,使用了多协程去分发消息。但是并不是无限制地加大并发度。
为了避免某个万人群的高频发消息,造成对整个消息系统的压力,消息分发以群id为维度,限制了单个群的分发并发度。
消息分发给一个人的耗时是8ms,那么万人的总体耗时是80s,并发上限是5,那么消息分发完成需要16s。16s的耗时,在产品角度来看还、是可以接受的,大群对及时性不敏感。同时,并发度控制在合理范围内。
除了限制单个群id的并发度,还限制了万人群的总体并发度。单台机,小群的worker数为250个,万人群的worker数为30。
10.4 优化2:合并插入
工作场景的聊天,多数是在小群完成,大群用于管理员发通知或者老板发红包。
大群消息有一个常见的规律:平时消息少,会突然活跃。例如:老板在群里发个大红包,群成员起哄,此时就会产生大量的消息。
消息量上涨、并发度被限制、任务处理不过来,那么队列自然就会积压。积压的任务中可能存在多条消息需要分发给同一个群的群成员。
此时:可以将这些消息,合并成一个请求,写入到消息存储,消息系统的吞吐量就可以成倍增加。
在日常的监控中,可以捕获到这种场景,高峰可以同时插入20条消息,对整个系统很友善。
10.5 优化3:业务降级
比如:群人员变更、群名称变动、群设置变更,都会在群内扩散一条不可见的控制消息。群成员收到此控制消息,则向后台请求同步新数据。
举个例子:一个万人群,由于消息过于频繁,对群成员造成骚扰,部分群成员选择退群来拒绝消息,假设有1000人选择退群。那么扩散的控制消息量就是1000w,用户收到控制消息就向后台请求数据,则额外带来1000w次的数据请求,造成系统的巨大压力。
控制消息在小群是很有必要的,能让群成员实时感知群信息的变更。
但是在大群:群信息的变更其实不那么实时,用户也感觉不到。所以结合业务场景,实施降级服务,控制消息在大群可以直接丢弃、不分发,减少对系统的调用。
11、回执消息架构设计
11.1 技术背景
回执消息是办公场景经常用到的一个功能,能看到消息接受方的阅读状态。
一条回执消息的阅读状态会被频繁修改,群消息被修改的次数和群成员人数成正比。每天上亿条消息,读写频繁,请求量巨大,怎么保证每条消息在接受双方的状态是一致的是一个难点。
11.2 实现方案
消息的阅读状态的存储方式两个方案。
方案一:
思路:利用消息存储,插入一条新消息指向旧消息,此新消息有最新的阅读状态。客户端收到新消息,则用新消息的内容替换旧消息的内容展示,以达到展示阅读状态的效果。
优点:复用消息通道,增量同步消息就可以获取到回执状态,复用通知机制和收发协议,前后端改造小。
缺点:
- ① 存储冗余,状态变更多次,则需插入多条消息;
- ② 收发双方都需要修改阅读状态(接收方需标志消息为已读状态),存在收发双方数据一致性问题。
方案二:
思路:独立存储每条消息的阅读状态,消息发送者通过消息id去拉取数据。
优点:状态一致。
缺点:
- ① 构建可靠的通知机制,通知客户端某条消息属性发生变更;
- ② 同步协议复杂,客户端需要准确知道哪条消息的状态已变更;
- ③ 消息过期删除,阅读状态数据也要自动过期删除。
企业微信采用了方案一去实现,简单可靠、改动较小:存储冗余的问题可以通过LevelDB落盘的时候merge数据,只保留最终状态那条消息即可;一致性问题下面会介绍如何解决。
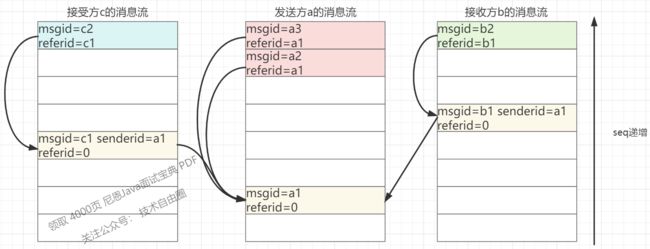
上图是协议流程(referid:被指向的消息id,senderid:消息发送方的msgid):
- 1)每条消息都有一个唯一的msgid,只在单个用户内唯一,kv存储自动生成的;
- 2)接收方b已读消息,客户端带上msgid=b1请求到后台;
- 3)在接受方b新增一条消息,msgid=b2,referid=b1,指向msgid=b1的消息。并把msgid=b2的消息内容设置为消息已读。msgid=b1的消息体,存有发送方的msgid,即senderid=a1;
- 4)发送方a,读出msgid=a1的消息体,把b加入到已读列表,把新的已读列表保存到消息体中,生成新消息msgid=a2,referid=a1,追加写入到a的消息流;
- 5)接收方c已读同一条消息,在c的消息流走同样的逻辑;
- 6)发送方a,读出msgid=a1的消息体,把c加入到已读列表,把新的已读列表保存到消息体中,生成新消息msgid=a3,referid=a1,追加写入到a的消息流。a3>a2,以msgid大的a3为最终状态。
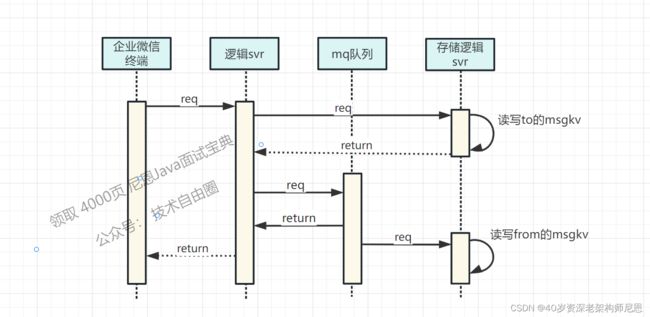
11.3 优化1:异步化
接受方已读消息,让客户端同步感知成功,但是发送方的状态没必要同步修改。因为发送方的状态修改情况,接受方没有感知不到。
那么,可以采用异步化的策略,降低同步调用耗时。
具体做法是:
- 1)接受方的数据同步写入,让客户端马上感知消息已读成功;
- 2)发送方的数据异步写入,减少同步请求;
- 3)异步写入通过重试来保证成功,达到状态最终一致的目的。
11.4 优化2:合并处理
客户端收到大量消息,并不是一条一条消息已读确认,而是多条消息一起已读确认。为了提高回执消息的处理效率,可以对多条消息合并处理。

如上图所示:
- 1)X>>A:表示X发了一条消息给A;
- 2)A合并确认3条消息,B合并确认3条消息。那么只需要处理2次,就能标志6条消息已读;
- 3)经过mq分发,相同的发送方也可以合并处理。在发送方,X合并处理2条消息,Y合并处理2条消息,Z合并处理2条消息,则合并处理3次就能标志6条消息。
经过合并处理,处理效率大大提高。
11.5 读写覆盖解决
发送方的消息处理方式是先把数据读起来,修改后重新覆盖写入存储。接收方有多个,那么就会并发写发送方数据,避免不了出现覆盖写的问题。
流程如下:
- 1)发送方某条消息的已读状态是X;
- 2)接收方a确认已读,已读状态修改为X+a;
- 3)接收方b确认已读,已读状态修改为X+b;
- 4)接收方a的状态先写入,接受方b的状态后写入。这最终状态为X+b;
- 5)其实正确的状态是X+a+b。
处理这类问题,无非就一下几种办法。
方案一:因为并发操作是分布式,那么可以采用分布式锁的方式保证一致。操作存储之前,先申请分布式锁。这种方案太重,不适合这种高频多账号的场景。
方案二:带版本号读写。一个账号的消息流只有一个版本锁,高频写入的场景,很容易产生版本冲突,导致写入效率低下。
方案三:mq串行化处理。能避免覆盖写问题,关键是在合并场景起到很好的作用。同一个账号的请求串行化,就算出现队列积压,合并的策略也能提高处理效率。
企业微信采用了方案三,相同id的用户请求串行化处理,简单易行,逻辑改动较少。
12、撤回消息的架构设计
12.1 技术难点
“撤回消息”相当于更新原消息的状态,是不是也可以通过referid的方式去指向呢?
回执消息分析过:通过referid指向,必须要知道原消息的msgid。
区别于回执消息:撤回消息需要修改所有接收方的消息状态,而不仅仅是发送方和单个接收方的。消息扩散写到每个接收方的消息流,各自的消息流对应的msgid是不相同的,如果沿用referid的方式,那就需要记录所有接收方的msgid。
12.2 解决方案
分析:撤回消息比回执消息简单的是,撤回消息只需要更新消息的状态,而不需要知道原消息的内容。接收方的消息的appinfo都是相同的,可以通过appinfo去做指向。
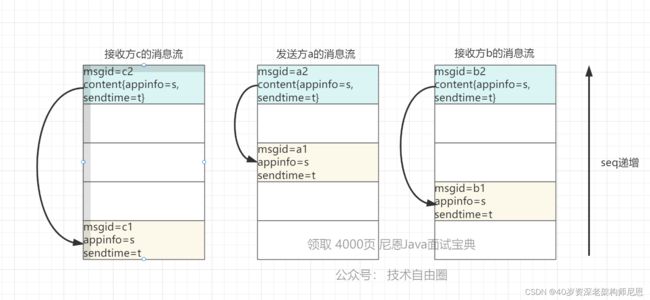
协议流程:
- 1)用户a、b、c,都存在同一条消息,appinfo=s,sendtime=t;
- 2)a撤回该消息,则在a的消息流插入一条撤回的控制消息,消息体包含{appinfo=s,sendtime=t};
- 3)客户端sync到撤回的控制消息,获取到消息体的appinfo与sendtime,把本地appinfo=s且sendtime=t的原消息显示为撤回状态,并删除原消息数据。之所以引入sendtime字段,是为了防止appinfo碰撞,加的双重校验;
- 4)接收方撤回流程和发送方一致,也是通过插入撤回的控制消息。
该方案的优点明显,可靠性高,协议简单。
撤回消息的逻辑示意图:
说在最后:有问题可以找老架构取经
架构之路,充满了坎坷。
架构和高级开发不一样 , 架构的问题是open的,开发式的,没有标准答案的。
在做架构过程中,或者在转型过程中,如果遇到复杂的场景,确实不知道怎么做架构方案,确实找不到有底的方案,怎么办? 可以来找40岁老架构尼恩求助。
上次一个小伙伴,他们要进行 电商网站的黄金链路架构, 开始找不到思路,但是经过尼恩 10分钟语音指导,一下就豁然开朗。
关于IM架构,后面尼恩会出一个系列的视频,帮助大家彻底掌握,从而开启自己的 架构师之路。
如果需要把IM、推送平台、秒杀平台 等优质项目,写人简历,也可以找尼恩指导。
下面是昨晚尼恩指导的13年经验小伙伴, 经过1小时指导后,简历 金光闪闪、脱胎换骨:
推荐相关阅读
《网易一面,痛失30K:为啥用阻塞队列,list不行吗?》
《美团二面:epoll性能那么高,为什么?》
《腾讯太狠:40亿QQ号,给1G内存,怎么去重?》
《京东太狠:100W数据去重,用distinct还是group by,说说理由?》
《美团太狠:接口被恶刷10Wqps,怎么防?》
《顶奢好文:3W字,穿透Spring事务原理、源码,最少读10遍》
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓