葡萄酒质量预测 -- 机器学习项目基础篇(1)
在这里,我们将根据给定的特征预测葡萄酒的质量。我们使用互联网上免费提供的葡萄酒质量数据集。该数据集具有影响葡萄酒质量的基本特征。通过使用几种机器学习模型,我们将预测葡萄酒的质量。
导入库和数据集
- Pandas是一个有用的数据处理库。
- 用于处理数组的Numpy库。
- Seaborn/Matplotlib用于数据可视化。
- Sklearn -该模块包含多个库,这些库具有预实现的功能,可以执行从数据预处理到模型开发和评估的任务。
- XGBoost -这包含eXtreme Gradient Boosting机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings('ignore')
现在让我们看看数据集的前五行。
df = pd.read_csv('winequality.csv')
print(df.head())

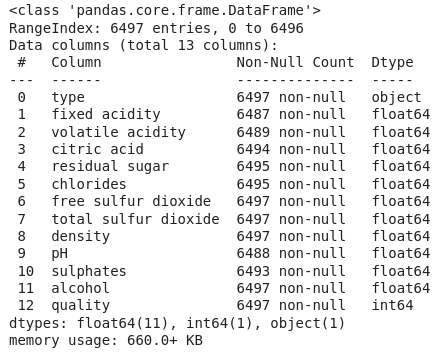
让我们研究一下数据集中每一列中的数据类型。
df.info()
现在我们将探索数据集的描述性统计度量。
df.describe().T

探索性数据分析(EDA)
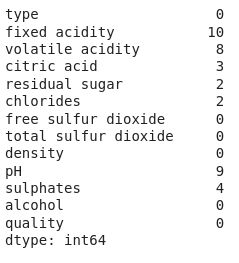
EDA是一种使用可视化技术分析数据的方法。它用于发现趋势和模式,或在统计摘要和图形表示的帮助下检查假设。 现在,让我们检查数据集列中空值的数量。
df.isnull().sum()
由于不同列中的数据是连续值,因此让我们通过平均值来估算缺失值。
for col in df.columns:
if df[col].isnull().sum() > 0:
df[col] = df[col].fillna(df[col].mean())
df.isnull().sum().sum()
输出:
0
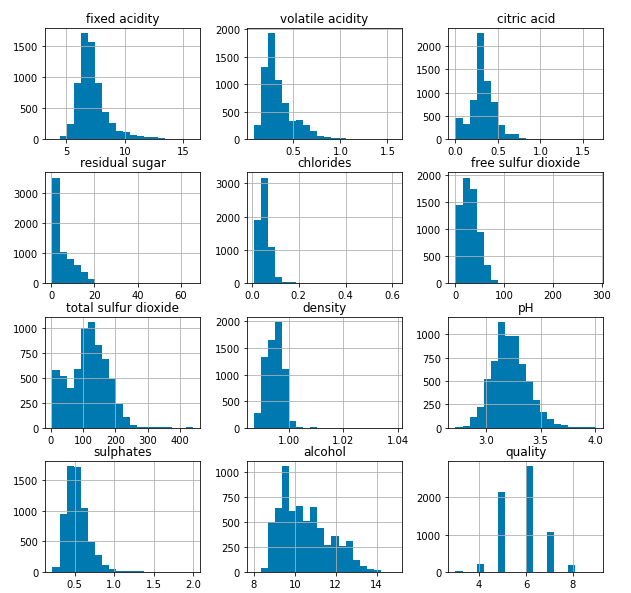
让我们绘制直方图来可视化数据集列中具有连续值的数据的分布。
df.hist(bins=20, figsize=(10, 10))
plt.show()
现在,让我们绘制计数图,以可视化每种葡萄酒质量的数字数据。
plt.bar(df['quality'], df['alcohol'])
plt.xlabel('quality')
plt.ylabel('alcohol')
plt.show()

有时提供给我们的数据包含冗余特征,它们无助于提高模型的性能,这就是为什么我们在使用它们来训练模型之前删除它们。
plt.figure(figsize=(12, 12))
sb.heatmap(df.corr() > 0.7, annot=True, cbar=False)
plt.show()

从上面的热图中,我们可以得出结论,“total sulphur dioxide”和“free sulphur dioxide”是高度相关的特征,因此,我们将删除它们。
df = df.drop('total sulfur dioxide', axis=1)
模型建立
让我们为训练准备数据,并将其分为训练和验证数据,以便我们可以根据用例选择哪个模型的性能最好。我们将训练一些最先进的机器学习分类模型,然后使用验证数据从中选择最佳模型。
df['best quality'] = [1 if x > 5 else 0 for x in df.quality]
我们也有一个对象数据类型的列,让我们用0和1替换它,因为只有两个类别。
df.replace({'white': 1, 'red': 0}, inplace=True)
从数据集中分离特征和目标变量后,我们将其分成80:20的比例进行模型选择。
features = df.drop(['quality', 'best quality'], axis=1)
target = df['best quality']
xtrain, xtest, ytrain, ytest = train_test_split(
features, target, test_size=0.2, random_state=40)
xtrain.shape, xtest.shape
输出:
((5197, 11), (1300, 11))
在训练之前对数据进行归一化有助于我们实现模型的稳定和快速训练。
norm = MinMaxScaler()
xtrain = norm.fit_transform(xtrain)
xtest = norm.transform(xtest)
由于数据已经完全准备好了,让我们在上面训练一些先进的机器学习模型。
models = [LogisticRegression(), XGBClassifier(), SVC(kernel='rbf')]
for i in range(3):
models[i].fit(xtrain, ytrain)
print(f'{models[i]} : ')
print('Training Accuracy : ', metrics.roc_auc_score(ytrain, models[i].predict(xtrain)))
print('Validation Accuracy : ', metrics.roc_auc_score(
ytest, models[i].predict(xtest)))
print()

模型评估
从上述准确率,我们可以说,逻辑回归和SVC()分类器在验证数据上表现更好,验证数据和训练数据之间的差异更小。让我们使用Logistic回归模型绘制验证数据的混淆矩阵。
metrics.plot_confusion_matrix(models[1], xtest, ytest)
plt.show()
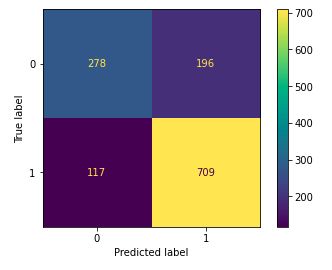
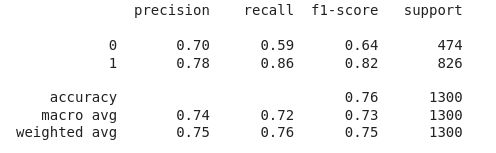
让我们打印性能最好的模型的分类结果。
print(metrics.classification_report(ytest,
models[1].predict(xtest)))