源码学习初章-基础知识储备
文章目录
- 学前准备
- 源码地址
- 引言
- extern "C"
- 宏定义
- 平台宏
- 跨平台宏
- vstdio平台禁用警告宏
- 连接、双层宏定义
- 函数宏
- 系统函数宏
- 自定义函数宏
- 多语句执行宏do while0
- 普通宏定义
- C的一些必备函数知识
- 回调函数和函数指针
- 回调函数wireshark-4.0.7源码例子
- 函数指针wireshark4.0.7源码例子
- 结构体和关键字
- 结构体和联合体
- 结构体 struct
- 联合体 union
- 关键字
- static
- extern
- C++关键字 explicit
- 标志位与位操作
- & 、 |、<<、>>
- 标志位(|加标志)(&减/检标志)
- 代码习惯
- if else
- if else break
- 函数定义
- 其他内容后续补充
学前准备
源码地址
cJSON库地址
sqlite-github源码地址
sqlite官方网址
wireshark源码
引言
- 引言参考的是sqlite和wireshark的部分代码,第二篇开始进入cJSON正式篇
- 第一篇暂时不涉及github的源码,参考的是sqlite官网发布的shell.c sqlite3.h .c等文件进行简单的知识储备
- 另外由于工作中多是linux环境所以把vstdio卸载了,但是为了在windows下学习sqlite源码所以我采用的是Qt5.14.1 MinGW32进行开发
- 本文只会使用cpp的new和delete,其他语法将均为c的语法
- 面向对象只是一种设计模式,如果你愿意,你可以用汇编来实现面向对象
extern “C”
- 声明:
这么做的目的是把c作为底层开发库,这样任何一个编程语言都可以调用c写的库了- 区别
1、因为在 C 语言中,默认的函数调用约定是 C 调用约定(C calling convention),参数通过栈传递,由调用者清理栈。
2、在 C++ 中,默认的函数调用约定是 C++ 调用约定(C++ calling convention),其实质是通过名称修饰(Name Mangling)来支持函数重载,参数传递方式和 C 调用约定类似,但由于函数名被修饰,因此 C++ 编译器能够识别重载的函数- 做法
在头文件中 所有的 函数 结构体 变量 等能想到的所有内容都放在两个 "{}"中
#ifdef __cplusplus
extern "C" {
void fun1();
void fun2();
static struct Stu{
int a;
char b;
}stu{0,0};
int a=10;
}
#endif
宏定义
平台宏
跨平台宏
#if (defined(_WIN32) || defined(WIN32)) && !defined(_CRT_SECURE_NO_WARNINGS)
#define _CRT_SECURE_NO_WARNINGS
#endif
#include 总结:
- !defined(_CRT_SECURE_NO_WARNINGS)是为了防止C4996报错
- defined(_WIN32)和defined(WIN32)用来判断是否是windows,defined(WIN64)是在win系统基础上判断是不是win64位
vstdio平台禁用警告宏
#if defined(_MSC_VER)
#pragma warning(disable : 4054)// 禁用类型转换警告。此警告提示可能存在的类型转换问题。
#pragma warning(disable : 4055)//禁用类型转换警告。此警告提示可能存在的类型转换问题。
#pragma warning(disable : 4100)//禁用未使用的形参警告。此警告提示声明了但未在函数体内使用的形式参数。
//等
#endif /* defined(_MSC_VER) */
连接、双层宏定义
#include 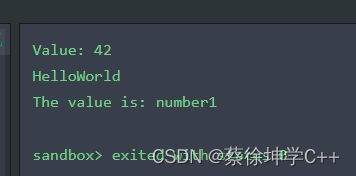
函数宏
系统函数宏
将系统函数变成我们自己的宏即可省去后期我们大量调用时的麻烦
当然也可以自己写个函数通过宏实现
# define GETPID (int)GetCurrentProcessId//获取当前进程函数
#include 
自定义函数宏
//宏定义自己的函数
//注意显示转换不是必须的,但写上更加直观
#include 
多语句执行宏do while0
# define CONTINUE_PROMPT_RESET \
do {setLexemeOpen(&dynPrompt,0,0); trackParenLevel(&dynPrompt,0);} while(0)
- 当有多条语句要执行时需要用{}将函数括起来,而用{}需要用do while循环好处:
1、使宏的用法更像函数调用,增加了代码的可读性和可维护性
2、可以避免一些编译器警告,因为使用了多条语句,编译器会认为这是一个复合语句
3、do-while(0) 循环体会执行一次,因为条件永远为真。这并不会引起运行时额外的开销,因为优化后的编译器会将其优化掉- 重点:宏中需要一行写完,如果分行需要用 \ 进行换行
#include 
# define CONTINUE_PROMPT_AWAITS(p,s) \
if(p && stdin_is_interactive) setLexemeOpen(p, s, 0)
//这个 if 是条件语句(单个条件语句),所以不用 do while0
普通宏定义
- 宏代表的是指针
#define CONTINUE_PROMPT_PSTATE_PTR (&dynPrompt)- 宏代表的是变量
#define CONTINUE_PROMPT_PSTATE_VALUE dynPrompt- 代表的是具体的常数
#define CONTINUE_PROMPT_PSTATE_CONSTANT 42
#include 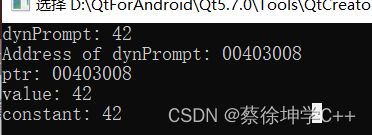
C的一些必备函数知识
回调函数和函数指针
#include 
回调函数wireshark-4.0.7源码例子
packet.h:76
typedef int (*dissector_t)(tvbuff_t *, packet_info *, proto_tree *, void *);//回调函数声明
packet.c:3310
/* Register a new dissector by name. */
dissector_handle_t
register_dissector(const char *name, dissector_t dissector, const int proto)
{
struct dissector_handle *handle;
handle = new_dissector_handle(DISSECTOR_TYPE_SIMPLE, dissector, proto, name, NULL, NULL);
return register_dissector_handle(name, handle);
}
packet-ssh.c:4799
ssh_handle = register_dissector("ssh", dissect_ssh, proto_ssh);
packet-ssh.c:676
static int
dissect_ssh(tvbuff_t *tvb, packet_info *pinfo, proto_tree *tree, void* data _U_)
{
/*这里面是ssh解析的具体代码,不做展示*/
}
函数指针wireshark4.0.7源码例子
packet-ssh.c:185
truct ssh_flow_data {
guint version;
gchar* kex;
int (*kex_specific_dissector)(guint8 msg_code, tvbuff_t *tvb,
packet_info *pinfo, int offset, proto_tree *tree,
struct ssh_flow_data *global_data, guint *seq_num);//函数指针声明
/* [0] is client's, [1] is server's */
#define CLIENT_PEER_DATA 0
#define SERVER_PEER_DATA 1
/*后续代码略*/
}
//---------------------------------------------------------------------------------
packet-ssh.c:1702
static void ssh_set_kex_specific_dissector(struct ssh_flow_data *global_data)
{
const char *kex_name = global_data->kex;
if (!kex_name) return;
if (strcmp(kex_name, "diffie-hellman-group-exchange-sha1") == 0 ||
strcmp(kex_name, "diffie-hellman-group-exchange-sha256") == 0)
{
global_data->kex_specific_dissector = ssh_dissect_kex_dh_gex;//函数指针赋值
}
/*dh group 和 ecdh 略*/
}
//---------------------------------------------------------------------------------
packet-ssh.c:1361
static int ssh_dissect_kex_dh_gex(guint8 msg_code, tvbuff_t *tvb,
packet_info *pinfo, int offset, proto_tree *tree,
struct ssh_flow_data *global_data, guint *seq_num)
结构体和关键字
结构体和联合体
结构体 struct
static struct DynaPrompt {
char dynamicPrompt[PROMPT_LEN_MAX];
char acAwait[2];
int inParenLevel;
char *zScannerAwaits;
} dynPrompt = { {0}, {0}, 0, 0 };
因为C没有构造函数,不能像cpp一样在构造函数对结构体进行赋初值,因此它赋初值的方法是在结构体定义的尾部赋值
每个成员变量含义:
dynamicPrompt 数组被初始化为 {0}:即所有元素都是空字符 ‘\0’。
acAwait 数组被初始化为{0}:即设置为两个空字符 ‘\0’。
inParenLevel 被初始化为 0:表示括号的层级初始值为 0。
zScannerAwaits被初始化为 0:它被初始化为 0,即指向空地址。
联合体 union
- 联合体的所有成员共用同一块内存空间,不同成员在内存中的位置是重叠的。
- 联合体的大小等于所有成员中占用内存最大的那个成员的大小
- 在同一时间,只能使用一个成员,存储一个成员的值会覆盖其他成员的值。
#include 
关键字
- static和extern的作用是相反的
static
因为源码中有大量的static函数、结构体等。
静态函数的作用是:
- 函数隐藏在当前源文件中,对其他部分不可见,实现隐藏实现细节的目的
- 将函数声明为 static 可以限制其作用域,避免与其他文件中的同名函数冲突
- 这是一种常见的编程技巧,用于实现模块化的代码结构和增强程序的安全性。
extern
- 当在一个源文件中使用 extern 来声明函数时,它告诉编译器该函数是在另一个源文件中定义的,而不是在当前文件中定义的
- 通常,这样的声明会放在头文件中,然后在其他源文件中包含该头文件,以便其他源文件可以访问和调用声明的函数。
C++关键字 explicit
- 这个关键字加在构造函数前,保证代码安全性
class MyClass {
public:
explicit MyClass(int value) {
// 构造函数的实现
}
};
//如果没有explicit关键字那么构造函数可以隐式调用
int num = 42;
MyClass obj = num; // 隐式调用构造函数,将整数转换为 MyClass 类型
//加上explicit关键字必须显式创建对象
int num = 42;
MyClass obj(num); // 显式调用构造函数,将整数转换为 MyClass 类型
标志位与位操作
& 、 |、<<、>>
1000&1010 = 1000
1000|1010 = 1010
1<<8 = 1*2的八次方(10000000)
256>>8 = 256/2的八次方( 10000000>>8)
可以简单地理解为加减法的关系,本处不做具体解释,可以参考网上其他信息
标志位(|加标志)(&减/检标志)
#include 过程
- flags = 00000000
- FLAG_A = 00000001
flags = 00000000 | 00000001 = 00000001- FLAG_C = 00000100
flags = 00000001 | 00000100 = 00000101- FLAG_A = 00000001
flags = 00000101 & 00000001 = 00000001 (非零,表示标志位 A 已设置)- FLAG_B = 00000010
flags = 00000101 & 00000010 = 00000000 (为零,表示标志位 B 未设置)- FLAG_C = 00000100
flags = 00000101 & 00000100 = 00000100 (非零,表示标志位 C 已设置)- 这样我们通过 | 加标志 再用 & 检查标志,我们就可以通过3bit的数据获得8种标志位情况
- 实际上我们不必用&检查标志位,因为8种情况我们都是知道的所以直接 == 0111(0x07) 或 0011(0x03)(等6种情况)即可
注:各种源码这种标志位过于普遍,本处不再贴此类代码
代码习惯
if else
if( dynPrompt.inParenLevel>9 ){
shell_strncpy(dynPrompt.dynamicPrompt, "(..", 4);
}else if( dynPrompt.inParenLevel<0 ){
shell_strncpy(dynPrompt.dynamicPrompt, ")x!", 4);
}else{
shell_strncpy(dynPrompt.dynamicPrompt, "(x.", 4);
dynPrompt.dynamicPrompt[2] = (char)('0'+dynPrompt.inParenLevel);
}
if else break
if( nmb !=0 && noc+nmb <= ncmax ){
//sss
}else break;
函数定义
这种函数参数列表是第一次看到
工作中没有遇到过这种写法,但是这种注释确实比较方便,易读性很好
后续会对这种格式进行讨论
static char *shellFakeSchema(
sqlite3 *db, /* The database connection containing the vtab */
const char *zSchema, /* Schema of the database holding the vtab */
const char *zName /* The name of the virtual table */
){
//。。。
}
其他内容后续补充
这个是为了cJSON库源码学习先初步学习的一些知识储备