Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Compose,RandomCrop)
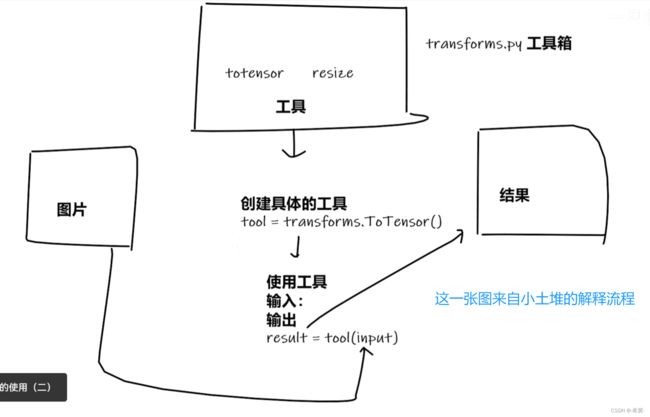
一、transforms的作用
transforms主要用于对图像进行变换,是常见的图像预处理方法。
二、transforms结构
通过pycharm中在该transforms.py下的structure进行查看

三、transforms的使用
首先引入transforms所在的模块
from torchvision import transforms
其次由上面的截图可以知道transforms就是一个.py文件,里面有很多的类以及方法,所以要先使用就必须通过.的形式去调用,如果要调用类,那就需要实例化,实例化后就是一个对象,对象就可以使用该类下的方法。
1、ToTensor类
class ToTensor:
"""Convert a PIL Image or ndarray to tensor and scale the values accordingly.
将PIL Image or ndarray类型转化为tensor 类型
from PIL import Image
from torchvision import transforms
img_path = "hymenoptera_data/train/ants_image/20935278_9190345f6b.jpg"
# 打开一张图片
img = Image.open(img_path)
# 使用transforms对图像进行变换
# 实例化totensor对象
to_tens = transforms.ToTensor()
# 将pil变成Tensor类型的图片
tens_img = to_tens(img) # 自动调用call函数
print(tens_img)
打印结果:
tensor([[[0.6784, 0.6863, 0.6863, ..., 0.2431, 0.2471, 0.2549],
[0.6824, 0.6824, 0.6824, ..., 0.2078, 0.2118, 0.2157],
[0.6745, 0.6745, 0.6784, ..., 0.1882, 0.1882, 0.1843],
...,
[0.5451, 0.5373, 0.5294, ..., 0.1216, 0.1216, 0.1216],
[0.5412, 0.5333, 0.5294, ..., 0.1294, 0.1294, 0.1333],
[0.5333, 0.5294, 0.5294, ..., 0.1137, 0.1216, 0.1255]],
[[0.0588, 0.0588, 0.0588, ..., 0.5176, 0.5216, 0.5294],
[0.0549, 0.0549, 0.0588, ..., 0.4863, 0.4902, 0.4941],
[0.0510, 0.0510, 0.0549, ..., 0.4588, 0.4588, 0.4549],
...,
[0.0353, 0.0353, 0.0314, ..., 0.2902, 0.2941, 0.3059],
[0.0314, 0.0314, 0.0314, ..., 0.2902, 0.3020, 0.3098],
[0.0196, 0.0235, 0.0314, ..., 0.3059, 0.3137, 0.3176]],
[[0.5961, 0.5922, 0.5765, ..., 0.3216, 0.3255, 0.3333],
[0.5804, 0.5725, 0.5647, ..., 0.2275, 0.2314, 0.2353],
[0.5569, 0.5529, 0.5490, ..., 0.1333, 0.1333, 0.1294],
...,
[0.3725, 0.3373, 0.3020, ..., 0.0824, 0.0863, 0.0941],
[0.3765, 0.3333, 0.3020, ..., 0.0627, 0.0706, 0.0784],
[0.3843, 0.3451, 0.3098, ..., 0.0863, 0.0941, 0.0980]]])
Process finished with exit code 0
tensor类型的数据包含哪些属性?

读取PIL Image类型用Image类,读取ndarray 类型用opencv,下面使用opencv。
import cv2
from torchvision import transforms
img_path = "hymenoptera_data/train/ants_image/20935278_9190345f6b.jpg"
# 打开一张图片,并使其类型为ndarray
img = cv2.imread(img_path)
print(type(img)) # 2、使用上一篇文章中的tensorboard进行查看
打开tensorboad的方法,进入终端tensorboard --logdir=log文件夹名称
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path = "hymenoptera_data/train/ants_image/20935278_9190345f6b.jpg"
# 打开一张图片
img = Image.open(img_path)
# 使用transforms对图像进行变换
# 实例化totensor对象
to_tens = transforms.ToTensor()
# 将pil变成Tensor类型的图片
tens_img = to_tens(img) # 自动调用call函数
print(tens_img)
# 使用上一篇文章中tensorboard进行查看
writer = SummaryWriter("transforms_logs")
writer.add_image("test_transforms",tens_img) # 标题,图像类型
writer.close()

四、其它常见的transforms

1、Normalize
class Normalize(torch.nn.Module):
"""Normalize a tensor image with mean and standard deviation.
This transform does not support PIL Image.
Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
channels, this transform will normalize each channel of the input
``torch.*Tensor`` i.e.,
``output[channel] = (input[channel] - mean[channel]) / std[channel]``
.. note::
This transform acts out of place, i.e., it does not mutate the input tensor.
Args:
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation in-place.
"""
由此可见,该类实例化时需要两个参数,第一个参数mean 代表每个通道上所有数值的平均值,第二个参数std 代表每个通道上所有数值的标准差。而图片的channels查看,可以通过print(img)进行查看mode是几个通道,下面demo的mode是rgba四个通道,故此时的均值和标准差应对应是四列,即会利用这两个参数分别将每层标准化(使数据均值为0,方差为1)后输出。
归一化计算公式:output[channel] = (input[channel] - mean[channel]) / std[channel]
即如果mean和std均为0.5,则代入公式中可以得到:
output[channel] = (input[channel] - 0.5) / 0.5
即:output[channel] = 2*input[channel]-1。
import cv2
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
writer = SummaryWriter("logs_2") # 定义存放log文件的文件夹
img = Image.open("image/python_img.png") # 打开图片
print(img) # 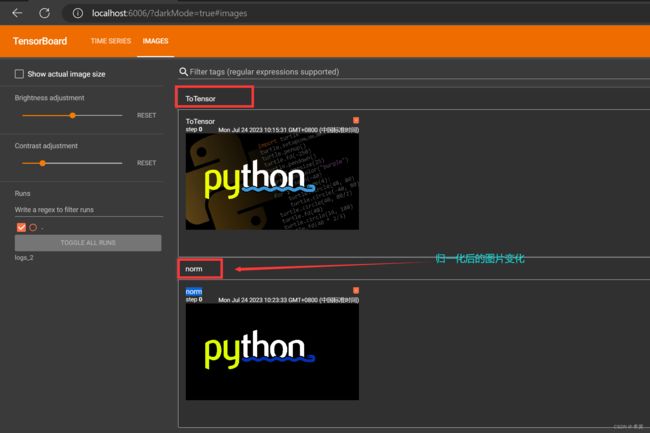
2、Resize
把输入的图片按照输入的参数值(h,w)重新设定大小。
class Resize(torch.nn.Module):
"""Resize the input image to the given size.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions
.. warning::
The output image might be different depending on its type: when downsampling, the interpolation of PIL images
and tensors is slightly different, because PIL applies antialiasing. This may lead to significant differences
in the performance of a network. Therefore, it is preferable to train and serve a model with the same input
types. See also below the ``antialias`` parameter, which can help making the output of PIL images and tensors
closer.
由
Args:
size (sequence or int): Desired output size. If size is a sequence like
(h, w), output size will be matched to this. If size is an int,
smaller edge of the image will be matched to this number.
i.e, if height > width, then image will be rescaled to
(size * height / width, size).
可知,当如果输入的参数是一个序列,即长和宽两个整数(h,w),则图像会按该长和宽进行resize。
如果输入的参数是一个整数x,将图片短边缩放至x,长宽比保持不变。
import cv2
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
writer = SummaryWriter("logs_2") # 定义存放log文件的文件夹
img = Image.open("image/python_img.png") # 打开图片
print(img) # 
3、compose
可以理解为多个Transforms操作的组合。即可以一次对输入的图片进行多个Transforms的操作
需要注意:compose中参数是前面的输出作为后面的输入,比如compose中第一个参数的输出是PIL类型,后面的输入也是PIL类型,所以可以直接使用compose,但是如果现在第一个的输出是tensor类型,但是第二个要求的输入是PIL,则会是类型不匹配,所以会报错。
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
writer = SummaryWriter("logs_2") # 定义存放log文件的文件夹
img = Image.open("image/python_img.png") # 打开图片
# 将img图片转化tensor类型,并返回tensor类型
trans_tens = transforms.ToTensor()
print(trans_tens)
# 将 img大小进行重新设定,并返回pIL类型
trans_resize = transforms.Resize(300)
print(trans_resize)
# compose 将ToTensor和Resize进行组合
trans_compose = transforms.Compose([trans_tens,trans_resize])
# 在tensorboard中可视化显示出来
compose_resize = trans_compose(img)
writer.add_image("compose",compose_resize,1)
writer.close()
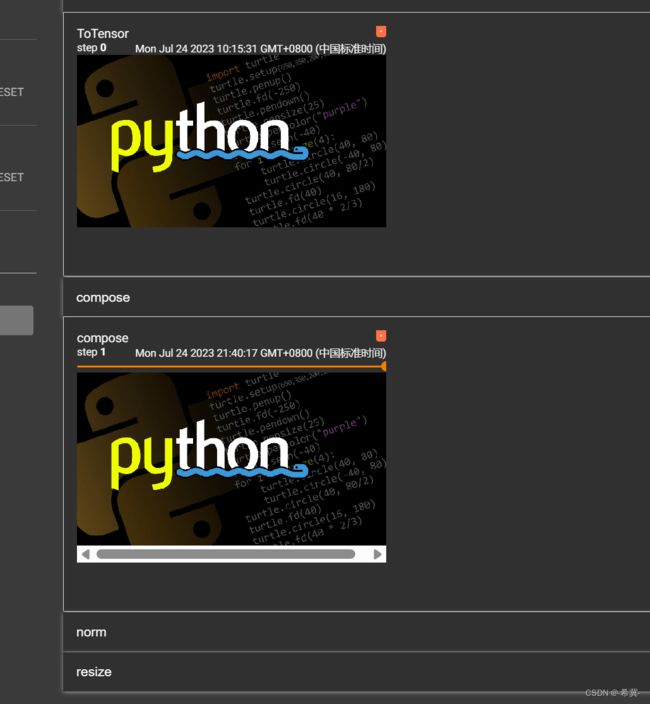
4、RandomCrop
随机裁剪:对图像进行随机大小裁剪,如果指定数字后就是按照数字大小进行裁剪。
class RandomCrop(torch.nn.Module):
"""Crop the given image at a random location.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions,
but if non-constant padding is used, the input is expected to have at most 2 leading dimensions
Args:
size (sequence or int): Desired output size of the crop. If size is an
int instead of sequence like (h, w), a square crop (size, size) is
made. If provided a sequence of length 1, it will be interpreted as (size[0], size[0]).
padding (int or sequence, optional): Optional padding on each border
of the image. Default is None. If a single int is provided this
is used to pad all borders. If sequence of length 2 is provided this is the padding
on left/right and top/bottom respectively. If a sequence of length 4 is provided
this is the padding for the left, top, right and bottom borders respectively.
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
writer = SummaryWriter("logs_2") # 定义存放log文件的文件夹
img = Image.open("image/python_img.png") # 打开图片
# 将img图片转化tensor类型,并返回tensor类型
trans_tens = transforms.ToTensor()
print(trans_tens)
# RandomCrop随机裁剪
trans_rand = transforms.RandomCrop(512) # 裁剪为512*512
# compose 将ToTensor和Resize进行组合
trans_compose = transforms.Compose([trans_rand,trans_tens])
# 随机裁剪10张并在tensorboard中可视化显示出来
for i in range(10):
img_trans_rand = trans_compose(img)
print(img_trans_rand)
writer.add_image("rands",img_trans_rand,i)
writer.close()
