算法通关村第一关——链表经典问题之删除链表元素专题笔记
删除特定节点
题目描述
给你一个链表的头节点head和一个整数val,请你删除链表汇总所有满足Node.val == val 的节点,并返回新的头节点
示例
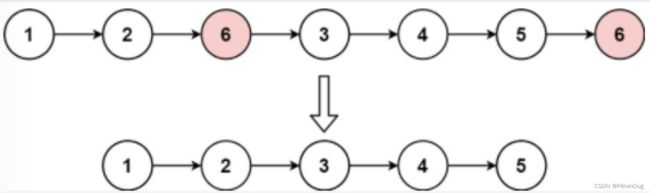
输入: head = [1,2,6,3,4,5,6] , val = 6
输出:[1,2,3,4,5]
分析
在删除节点cur时,必须要知道其前驱prev节点和后继next节点,然后让pre.next=next。这时候cur节点就脱离链表了,cur节点会在某个时刻被GC回收。
首节点处理方式的不同
插入操作:在插入首元素时,需要将新插入的节点的next指针指向原首元素,并且更新链表的头指针指向新插入的节点。而对于其他元素的插入操作,需要先找到插入位置的前驱节点,然后进行指针的变换。
删除操作:在删除首元素时,只需要将头指针指向首元素的next节点,并且可以自动回收原首元素所占用的内存。而对于其他元素的删除操作,需要找到待删除节点的前驱节点,然后进行指针的调整。
边界情况处理:首元素是链表的起点,所以在处理边界情况时需要特别注意。例如,在遍历链表时,首元素可能需要进行特殊处理;在判断链表是否为空时,需要检查头指针是否为空。
删除操作首节点的不同
由于首节点的特殊,为此,可以先创建爱你一个虚拟节点dummyHead,使其next域指向head,即 dummyHead.next = head,这样就不用单独处理首节点了
图例
实现步骤
1. 创建一个虚拟链表头dummyHead,使其next指向head
2. 开始循环链表寻找目标元素,注意这里是通过cur.next.val来判断的
3. 如果找到目标元素,就是用cur.next = cur.next.next 来删除节点(dummyHead.next = head , cur = dummyHead,因此需要cur.next = cur.next.next )
4. 注意最后返回的时候,要使用dummyHead.next,而不是dummyHead
代码实现
/**
* 给你一个链表的头节点head和一个整数val,请你删除链表汇总所有满足Node.val == val 的节点,并返回新的头节点
* 示例:
* 输入: head = [1,2,6,3,4,5,6] , val = 6
* 输出:[1,2,3,4,5]
* @param head 头节点
* @param val 指定的整数val
* @return 新的头节点
*/
public DoubleNode deleteNode(DoubleNode head , int val){
DoubleNode dummyNode = new DoubleNode(0);
dummyNode.next = head;
DoubleNode cur = dummyNode;
while (cur.next != null){
if (cur.next.data == val){
cur.next = cur.next.next;
}else {
cur = cur.next;
}
}
return dummyNode.next;
}删除倒数第N个节点
题目描述
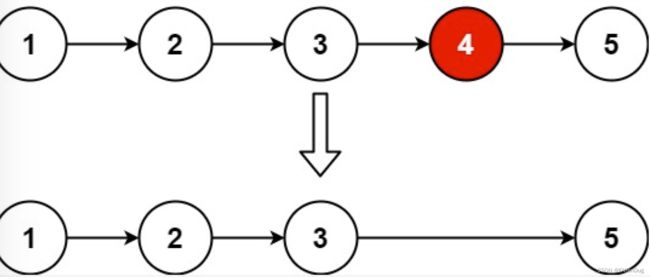
给你一个链表,删除链表的倒数第n个节点,并且返回链表的头节点
解题思路
方法1:先遍历链表,找到链表总长度L,然后重新遍历,位置L-N+1的元素就是要删除的元素
方法2:使用双指针来寻找倒数第N个元素的位置,然后将其删除
图例
代码实现
1.计算链表长度
/**
* 删除倒数第n个节点
* 给你一个链表,删除链表的倒数第n个节点,并且返回链表的头节点
* @param head 链表头节点
* @param n 要删除的第n个位置
* @return 链表头节点
*/
public DoubleNode removeNthFromEnd(DoubleNode head , int n){
DoubleLinkedList list = new DoubleLinkedList();
// 虚拟节点:为了不单独处理首节点
DoubleNode dummyHead = new DoubleNode(0,head);
DoubleNode node = dummyHead;
// 获取链表长度
int length =list.getDoubleLinkedListLength(head);
// 寻找要删除位置的前一个位置
for (int i = 1; i < length - n +1; i++) {
node = node.next;
}
// 删除该位置
node.next = node.next.next;
return dummyHead.next;
}2.双指针实现
public DoubleNode removeNthFromEnd1(DoubleNode head, int n){
// 虚拟节点:方便插入和删除操作,不需要对头部进行特殊处理
DoubleNode dummy = new DoubleNode(0);
dummy.next = head;
// 创建快慢指针
DoubleNode fast = head;
DoubleNode slow = dummy;
// 快指针先走到n的位置
for (int i = 0; i < n; i++) {
fast = fast.next;
}
// 当快指针走完,慢指针走到n的位置
while (fast != null){
slow = slow.next;
fast = fast.next;
}
slow.next = slow.next.next;
return dummy.next;
}删除重复元素
重复元素保留1个
题目描述
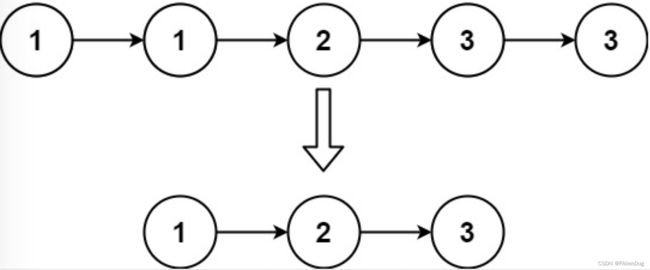
存在一个按升序排列的链表,给你这个链表的头节点head ,请你删除所有重复的元素,使每个元素只出现一次,返回同样按升序排列的结果链表
示例
* 输入:head = [1,1,2,3,3] * 输出:[1,2,3]
图例
思路
由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是连续的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。具体地,我们从指针 cur 指向链表的头节点,随后开始对链表进行遍历。如果当前 cur 与cur.next对应的元素相同,那么我们就将cur.next 从链表中移除;否则说明链表中已经不存在其它与cur 对应的元素相同的节点,因此可以将 cur 指 cur.next。当遍历完整个链表之后,我们返回链表的头节点即可。
注意事项
当遍历到最后一个节点时,cur.next为空,这时要加以判断
代码实现
/**
* 重复元素保留一个
* 存在一个按升序排列的链表,给你这个链表的头节点head ,请你删除所有重复的元素,
* 使每个元素只出现一次,返回同样按升序排列的结果链表
*
* 示例:
* 输入:head = [1,1,2,3,3]
* 输出:[1,2,3]
* @param head 链表头节点
* @return 删除重复元素后的头节点
*/
public DoubleNode deleteDuplicates(DoubleNode head){
// 对空链表不作处理
if (head == null){
return head;
}
// 辅助节点
DoubleNode cur = head;
while (cur.next != null){
if (cur.data == cur.next.data){
cur.next = cur.next.next;
}else {
cur = cur.next;
}
}
return head;
}
重复元素都不要
示例
* 输入:head = [1,2,3,3,4,4,5] * 输出:[1,2,5]
思路
当一个都不要时,链表只要直接对cur.next 以及 cur.next.next 两个node进行比较就行了,这里要注意两个node可能为空,稍加判断就行了。
代码实现
/**
* 重复元素都不要
* 示例:
* 输入:head = [1,2,3,3,4,4,5]
* 输出:[1,2,5]
* @param head 链表头节点
* @return 删除重复元素后的头节点
*/
public DoubleNode deleteDuplicates1(DoubleNode head){
if (head == null){
return head;
}
DoubleNode dummy = new DoubleNode(0);
dummy.next = head;
DoubleNode cur = dummy;
while (cur.next != null && cur.next.next != null){
if (cur.next.data == cur.next.next.data){
int curNum = cur.next.data;
// 只能删除1个重复的元素,如果有多个重复的元素,就需要循环删除
// cur.next = cur.next.next;
while (cur.next != null && cur.next.data == curNum){
cur.next = cur.next.next;
}
}else {
cur = cur.next;
}
}
return dummy.next;
}