视觉SLAM十四讲笔记-9-2
视觉SLAM十四讲笔记-9-2
文章目录
- 视觉SLAM十四讲笔记-9-2
-
- 9.2 BA 与图优化
-
- 9.2.1 投影模型和 BA 代价函数
- 9.2.2 BA的求解
- 9.2.3 稀疏性和边缘化
- 9.2.4 鲁棒核函数
9.2 BA 与图优化
Bundle Adjustment(BA),是指从视觉图像中提炼出最优的 3D模型和相机参数(内参数和外参数)。考虑从任意特征点出来的几个光线(bundles of light rays),它们会在几个相机的成像平面上变成像素或是检测到的特征点。如果调整各相机姿态和各特征点的空间位置,使得这些光线最终收束到相机的光心,就称为 BA。
下面重点介绍 BA 对应的图模型结构的特点,然后介绍一些通用的快速求解方法。
9.2.1 投影模型和 BA 代价函数
投影过程:
一个世界坐标系下的点 p p p,
1.把世界坐标系下的点转换到相机坐标系,这里利用相机外参数(R,t):
P ′ = R p + t = [ X ′ , Y ′ , Z ′ ] T P' = Rp+t = [X',Y',Z']^T P′=Rp+t=[X′,Y′,Z′]T
2.将 P ′ P' P′ 投至归一化平面,得到归一化坐标:
P c = [ u c , v c , 1 ] T = [ X ′ / Z ′ , Y ′ / Z ′ , 1 ] T P_c = [u_c,v_c,1]^T = [X'/Z',Y'/Z',1]^T Pc=[uc,vc,1]T=[X′/Z′,Y′/Z′,1]T
3.考虑到归一化坐标的畸变情况,得到去畸变前的原始像素坐标(例如只考虑径向畸变时):
{ u c ′ = u c ( 1 + k 1 r c 2 + k 2 r c 4 ) v c ′ = v c ( 1 + k 1 r c 2 + k 2 r c 4 ) \left\{\begin{array}{l} u_{c}^{\prime}=u_{c}\left(1+k_{1} r_{c}^{2}+k_{2} r_{c}^{4}\right) \\ \\ v_{c}^{\prime}=v_{c}\left(1+k_{1} r_{c}^{2}+k_{2} r_{c}^{4}\right) \end{array}\right. ⎩⎨⎧uc′=uc(1+k1rc2+k2rc4)vc′=vc(1+k1rc2+k2rc4)
4.根据相机内参模型,计算像素坐标:
{ u s = f x u c ′ + c x v s = f y v c ′ + c y \left\{\begin{array}{l} u_{s}=f_{x} u_{c}^{\prime}+c_{x} \\ \\ v_{s}=f_{y} v_{c}^{\prime}+c_{y} \end{array}\right. ⎩⎨⎧us=fxuc′+cxvs=fyvc′+cy
这一系列计算流程看似复杂,下面用流程图形象地表示整个过程。这个过程就是前面讲的观测方程。

之前把它抽象地记为:
z = h ( x , y ) z = h(x,y) z=h(x,y)
上面步骤中给出了它详细的参数化过程。具体来说,这里的 x x x 代表相机的位姿,即外参 R , t R,t R,t,它对应的李群为 T T T,李代数为 ξ \xi ξ。路标 y y y 即这里的三维点 p p p,而观测数据则是像素坐标 z = [ u s , v s ] T z = [u_s,v_s]^T z=[us,vs]T。以最小二乘的角度来考虑,那么可以列写关于此次观测的误差:
e = z − h ( T , p ) e = z - h(T,p) e=z−h(T,p)
然后,把其他时刻的观测量也考虑进来,可以给误差添加一个下标。这 z i j z_{ij} zij 为在位姿 T i T_i Ti 时刻观察路标 p j p_j pj 产生的数据,那么整体的代价函数为:
1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i j ∥ 2 = 1 2 ∑ i = 1 m ∑ j = 1 n ∥ z i j − h ( T i , p j ) ∥ 2 \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{n}\left\|e_{i j}\right\|^{2}=\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{n}\left\|z_{i j}-h\left(T_{i}, p_{j}\right)\right\|^{2} 21i=1∑mj=1∑n∥eij∥2=21i=1∑mj=1∑n∥zij−h(Ti,pj)∥2
9.2.2 BA的求解
观察到上面说的 h ( T , p ) h(T,p) h(T,p),很容易看出该函数不是线性函数,所以希望使用非线性优化的手段来优化它。根据非线性优化的思想,应该从某个初始值开始,不断地寻找下降的方向 Δ x \Delta x Δx,来找到目标函数的最优解,即不断地求解增量方程 H Δ x = g H \Delta x = g HΔx=g 中的增量 Δ x \Delta x Δx。
尽管误差项都是针对单个位姿和路标点的,但是在整体 BA 目标函数上,应该把自变量定义成所有待优化的变量:
x = [ T 1 , T 2 , . . . , T m , p 1 , p 2 , . . . , p n ] T x = [T_1,T_2,...,T_m,p_1,p_2,...,p_n]^T x=[T1,T2,...,Tm,p1,p2,...,pn]T
相应地,增量方程中的 Δ x \Delta x Δx 则是对整体自变量的增量。在这个意义下,当给自变量一个增量时,目标函数在 Δ x \Delta x Δx 附近进行泰勒展开为:
1 2 ∥ f ( x + Δ x ) ∥ 2 ≈ 1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i j + F i j Δ ξ i + E i j Δ p j ∥ 2 \frac{1}{2} \left \| f(x+\Delta x) \right \|^2\approx \frac{1}{2}\sum_{i=1}^{m} \sum_{j=1}^{n} \left \| e_{ij}+F_{ij}\Delta \xi _i + E_{ij}\Delta p_j\right \|^2 21∥f(x+Δx)∥2≈21i=1∑mj=1∑n∥eij+FijΔξi+EijΔpj∥2
其中, F i j F_{ij} Fij 表示整个代价函数在当前状态下对相机姿态的偏导数,而 E i j E_{ij} Eij 表示该函数对路标点位置的偏导。在 7.7.3 7.7.3 7.7.3节(视觉 SLAM 十四讲笔记-7-4) 中最小化重投影误差时介绍了 F i j F_{ij} Fij, E i j E_{ij} Eij 具体的形式。
把相机位姿变量放在一起:
x c = [ ξ 1 , ξ 2 , . . . , ξ m ] T ∈ R 6 m x_c = [ \xi _1, \xi _2,...,\xi _m]^T\in R^{6m} xc=[ξ1,ξ2,...,ξm]T∈R6m
并把空间点的变量也放在一起:
x p = [ p 1 , p 2 , . . . , p n ] T ∈ R 3 n x_p = [p_1,p_2,...,p_n]^T\in R^{3n} xp=[p1,p2,...,pn]T∈R3n
那么,目标函数在 Δ x \Delta x Δx 附近进行泰勒展开式子可以变为:
1 2 ∥ f ( x + Δ x ) ∥ 2 = 1 2 ∥ e + F Δ x c + E Δ x p ∥ 2 \frac{1}{2} \left \| f(x+\Delta x) \right \|^2=\frac{1}{2} \left \| e+F\Delta x _c + E\Delta x_p\right \|^2 21∥f(x+Δx)∥2=21∥e+FΔxc+EΔxp∥2
该式从一个由很多个小型二次型之和,变成了矩阵形式。这里的雅克比矩阵 E E E 和 F F F 必须是整体目标函数对整体变量的导数,它将是一个很大块的矩阵,而里面每个小分块是由每个误差项的导数 F i j F_{ij} Fij, E i j E_{ij} Eij 拼凑起来的。
无论使用高斯牛顿法还是列文伯格-马夸尔特方法,最后都会面对增量线性方程:
H Δ x = g H \Delta x = g HΔx=g
由于把变量归类成位姿和空间点两种,所以雅克比矩阵可以分块为:
J = [ F E ] J=[F\quad E] J=[FE]
那么,以高斯牛顿法为例,则 H H H 矩阵为:
H = J T J = [ F T F F T E E T F E T E ] H = J^TJ = \begin{bmatrix} F^TF & F^TE\\ E^TF & E^TE \end{bmatrix} H=JTJ=[FTFETFFTEETE]
一般来讲,在 SLAM 中,一幅图像会提出数百个特征点,这个线性方程包含了所有相机位姿和路标点,维度会非常大。如果直接对 H H H 求逆来计算增量方程,消耗的资源会非常多。幸运的是,这里的 H H H 矩阵具有一定的结构。利用这个特殊结构,可以加速求解过程。
9.2.3 稀疏性和边缘化
21世纪视觉 SLAM 的一个重要进展是认识到了海森矩阵 H H H 的稀疏结构,并发现该结构可以自然地、显式地用图优化来表示。本节将详细讨论该矩阵的稀疏结构。
海森矩阵 H H H 的稀疏性是由雅可比矩阵 J ( x ) J(x) J(x) 引起的。考虑这些代价函数当中的其中一个 e i j e_{ij} eij。注意,这个误差项只描述了在 T i T_i Ti 看到 p j p_j pj 这件事,只涉及到第 i i i 个相机位姿和第 j j j 个路标点,对其余部分的变量的导数都为0。所以该误差项对应的雅克比矩阵有下面的形式:
J i j ( x ) = ( 0 2 ∗ 6 , 0 2 ∗ 6 , ∂ e i j ∂ T i , 0 2 ∗ 6 , . . . , 0 2 ∗ 3 , ∂ e i j ∂ p j , 0 2 ∗ 3 , 0 2 ∗ 3 , . . . , 0 2 ∗ 3 ) J_{ij}(x) = (0_{2*6},0_{2*6},\frac{\partial e_{ij}}{\partial T_i} ,0_{2*6},...,0_{2*3},\frac{\partial e_{ij}}{\partial p_j},0_{2*3},0_{2*3},...,0_{2*3}) Jij(x)=(02∗6,02∗6,∂Ti∂eij,02∗6,...,02∗3,∂pj∂eij,02∗3,02∗3,...,02∗3)
其中, 0 2 ∗ 6 0_{2*6} 02∗6 表示维度为 2 ∗ 6 2 * 6 2∗6 的零矩阵,同理 0 2 ∗ 3 0_{2*3} 02∗3 表示维度为 2 ∗ 3 2 * 3 2∗3 的零矩阵。该误差项对相机姿态的偏导 ∂ e i j ∂ T i \frac{\partial e_{ij}}{\partial T_i} ∂Ti∂eij 维度为 2 ∗ 6 2*6 2∗6,对路标点的偏导 ∂ e i j ∂ p j \frac{\partial e_{ij}}{\partial p_j} ∂pj∂eij 维度为 2 ∗ 3 2*3 2∗3。这个误差项的雅克比矩阵,除了这两块为非零块,其余地方都为零。这体现了该误差项与其他路标和轨迹无关的特性。从图优化角点来说,这条观测边只和两个顶点有关。那么,它对增量方程有何影响? H H H 矩阵为什么会产生稀疏性尼?
以下图为例,设 J i j J_{ij} Jij 只在 i , j i,j i,j 处有非零块,那么对 H H H 的贡献为 J i j T J i j J_{ij}^TJ_{ij} JijTJij。这个 J i j T J i j J_{ij}^TJ_{ij} JijTJij 矩阵也仅有 4 个非零块,位于 ( i , i ) , ( i , j ) , ( j , i ) , ( j , j ) (i,i),(i,j), (j,i), (j,j) (i,i),(i,j),(j,i),(j,j)。对于整体的 H H H,有:
H = ∑ i , j J i j T J i j H = \sum_{i,j}^{}J_{ij}^TJ_{ij} H=i,j∑JijTJij
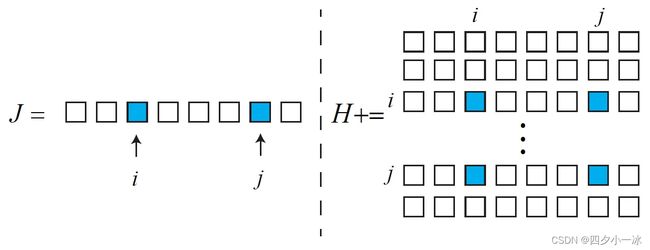
请注意, i i i 在所有相机位姿中取值, j j j 在所有路标中取值。把 H H H 进行分块:
H = [ H 11 H 12 H 21 H 22 ] H = \begin{bmatrix} H_{11} & H_{12}\\ H_{21} &H_{22} \end{bmatrix} H=[H11H21H12H22]
这里的 H 11 H_{11} H11 只和相机位姿有关,而 H 22 H_{22} H22 只和路标点有关。
当遍历 i , j i,j i,j 时,以下事实总是成立的:
1.不管 i , j i,j i,j 怎么变, H 11 H_{11} H11 都是对角阵,只有在 H i , i H_{i,i} Hi,i 处有非零块;
2.同理, H 22 H_{22} H22 也是对角阵,只在 H j , j H_{j,j} Hj,j 处有非零块;
3.对于 H 12 H_{12} H12 和 H 21 H_{21} H21,它们可能是稀疏的,也可能是稠密的,视具体的观测数据而定。
这显示了海森矩阵 H H H 的稀疏结构。之后对线性方程的求解中,也正需要利用它的稀疏结构。这里再举一个实例来直观地说明一下。假设一个场景内有 2 个相机位姿 ( C 1 , C 2 ) (C_1,C_2) (C1,C2) 和 6 个路标点 ( P 1 , P 2 , P 3 , P 4 , P 5 , P 6 ) (P_1,P_2,P_3,P_4,P_5,P_6) (P1,P2,P3,P4,P5,P6) 。这些相机和点云所对应的变量为 T i , i = 1 , 2 T_i, i =1,2 Ti,i=1,2 以及 p j , j = 1 , . . . , 6 p_j,j=1,...,6 pj,j=1,...,6。相机 C 1 C_1 C1 观测到路标点 P 1 , P 2 , P 3 , P 4 P_1,P_2,P_3,P_4 P1,P2,P3,P4 ,相机 C 2 C_2 C2观测到路标点 P 3 , P 4 , P 5 , P 6 P_3,P_4,P_5,P_6 P3,P4,P5,P6。将这个过程画成示意图,如下图所示。
 可以推出,场景下的 BA 目标函数应该为:
可以推出,场景下的 BA 目标函数应该为:
1 2 ( ∥ e 11 ∥ 2 + ∥ e 12 ∥ 2 + ∥ e 13 ∥ 2 + ∥ e 14 ∥ 2 + ∥ e 23 ∥ 2 + ∥ e 24 ∥ 2 + ∥ e 25 ∥ 2 + ∥ e 26 ∥ 2 ) \frac{1}{2} (\left \| e_{11} \right \|^2+ \left \| e_{12} \right \|^2+\left \| e_{13} \right \|^2+\left \| e_{14} \right \|^2+\left \| e_{23} \right \|^2+\left \| e_{24} \right \|^2+\left \| e_{25} \right \|^2+\left \| e_{26} \right \|^2) 21(∥e11∥2+∥e12∥2+∥e13∥2+∥e14∥2+∥e23∥2+∥e24∥2+∥e25∥2+∥e26∥2)
这里的 e i j e_{ij} eij 使用之前定义过的代价函数,即:
1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i j ∥ 2 = 1 2 ∑ i = 1 m ∑ j = 1 n ∥ z i j − h ( T i , p j ) ∥ 2 \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{n}\left\|e_{i j}\right\|^{2}=\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{n}\left\|z_{i j}-h\left(T_{i}, p_{j}\right)\right\|^{2} 21i=1∑mj=1∑n∥eij∥2=21i=1∑mj=1∑n∥zij−h(Ti,pj)∥2
以 e 11 e_{11} e11 为例,它描述了在 C 1 C_1 C1 看到了 P 1 P_1 P1 ,与其他的相机位姿和路标无关。令 J 11 J_{11} J11 为 e 11 e_{11} e11 所对应的雅克比矩阵,不难看出 e 11 e_{11} e11 对相机变量 ξ 2 \xi _2 ξ2 和路标点 p 2 , . . . , p 6 p_2,...,p_6 p2,...,p6 的偏导都为0。把所有变量以 x = ( ξ 1 , ξ 2 , p 1 , p 2 , p 3 , p 4 , p 5 , p 6 ) x = (\xi _1,\xi _2,p_1,p_2,p_3,p_4,p_5,p_6) x=(ξ1,ξ2,p1,p2,p3,p4,p5,p6)^T的顺序摆放,则有:
J 11 = ∂ e 11 ∂ x = ( ∂ e 11 ∂ ξ 1 , 0 2 ∗ 6 , ∂ e 11 ∂ p 1 , 0 2 ∗ 3 , 0 2 ∗ 3 , 0 2 ∗ 3 , 0 2 ∗ 3 , 0 2 ∗ 3 ) J_{11} = \frac{\partial e_{11}}{\partial x} = (\frac{\partial e_{11}}{\partial \xi_1},0_{2*6},\frac{\partial e_{11}}{\partial p_1},0_{2*3},0_{2*3},0_{2*3},0_{2*3},0_{2*3}) J11=∂x∂e11=(∂ξ1∂e11,02∗6,∂p1∂e11,02∗3,02∗3,02∗3,02∗3,02∗3)
为了方便表示稀疏性,用带颜色的方块表示矩阵在该方块内有数值,其余没有颜色的区域表示矩阵在该处数值都为0。
为了得到该目标函数对应的雅克比矩阵,可以将这些 J i j J_{ij} Jij 按照一定顺序列为向量,那么整体雅克比矩阵及相应的 H H H 矩阵的稀疏情况如下图所示:
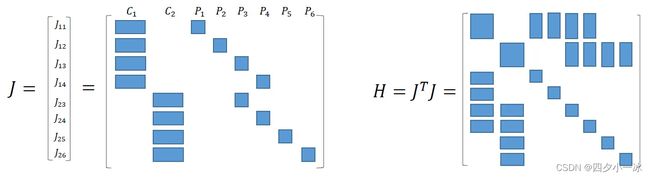
从上图 H H H 矩阵的结构可以看出,除了对角元素外的其余部分有着完全一致的结构。事实上也的确如此。上面的海森矩阵 H H H 一共有 8 个子矩阵块,对于 H H H 矩阵中处于非对角线的矩阵来说,如果该矩阵块非零,则其位置对应的变量(相机位姿和路标点)在图模型中存在一条边。
所以,海森矩阵 H H H 中的非对角部分的非零矩阵块可以理解为其对应的两个变量之间存在联系,或者可以称之为约束。于是,我们发现图优化结构与增量方程的稀疏性存在明显的联系。
考虑更一般的情况。假设有 m m m 个相机位姿, n n n 个路标点。由于通常路标的数量远远多余相机,于是 n n n 远远大于 m m m。因此,一般的 H H H 矩阵左上角块显得非常小,而右下角的对角块占据了大量地方。除此之外,非对角部分则分布着散乱的观测数据。由于形状很像箭头,又称为箭头形矩阵。
对于这种具有稀疏性结构的 H H H,线性方程 H Δ x = g H \Delta x = g HΔx=g 的求解会有什么不同尼?现实中存在若干种利用 H H H 的稀疏性加速计算方法。本节中介绍视觉 SLAM 中一种最常用的手段:Schur 消元。(在 SLAM 研究中也称为 Marginalization(边缘化))
将 H H H 矩阵划分为四个块,左上角为对角块矩阵,每个对角块元素的维度与相机位姿的维度相同,且是一个对角块矩阵。右下角也是对角块矩阵,每个对角块的维度是路标的维度。非对角块的结构与具体观测数据有关。将这四个块记为 B , E , E T , C B,E,E^T,C B,E,ET,C。
于是,对应的线性方程组也可以由 H Δ x = g H \Delta x = g HΔx=g 变为如下形式:
[ B E E T C ] [ Δ x c Δ x p ] = [ v w ] \begin{bmatrix} B & E\\ E^T &C \end{bmatrix}\begin{bmatrix} \Delta x_c\\ \Delta x_p \end{bmatrix} = \begin{bmatrix} v \\ w \end{bmatrix} [BETEC][ΔxcΔxp]=[vw]
其中 B B B 为对角块矩阵,每个对角块的维度和相机参数的维度相同,对角块的个数是相机变量的个数。由于路标数量会远远大于相机变量个数,所以 C C C 往往会远大于 B B B。三维空间中每个路标点为三维,于是 C C C 矩阵为对角块矩阵,每个块为 3 * 3 矩阵。

对角块求逆的难度远小于对一般矩阵求逆的难度,因为只需要对那些对角线矩阵块分别求逆就行。
考虑到这个特性,对线性方程组进行高斯消元,两边同时左乘一个
[ I − E C − 1 0 I ] \begin{bmatrix} I & -EC^{-1}\\ 0 &I \end{bmatrix} [I0−EC−1I],目标是消除 H H H 矩阵右上角的非对角部分 E E E。得:
[ I − E C − 1 0 I ] [ B E E T C ] [ Δ x c Δ x p ] = [ I − E C − 1 0 I ] [ v w ] [ B − E C − 1 E T E − E C − 1 C E T C ] [ Δ x c Δ x p ] = [ v − E C − 1 w w ] ⇓ [ B − E C − 1 E T 0 E T C ] [ Δ x c Δ x p ] = [ v − E C − 1 w w ] \begin{gathered} {\left[\begin{array}{cc} I & -E C^{-1} \\ \mathbf{0} & I \end{array}\right]\left[\begin{array}{cc} B & E \\ E^{T} & C \end{array}\right]\left[\begin{array}{l} \Delta \mathbf{x}_{c} \\ \Delta \mathbf{x}_{p} \end{array}\right]=\left[\begin{array}{cc} I & -E C^{-1} \\ 0 & I \end{array}\right]\left[\begin{array}{c} v \\ w \end{array}\right]} \\ \\ {\left[\begin{array}{cc} B-E C^{-1} E^{T} & E-E C^{-1} C \\ E^{T} & C \end{array}\right]\left[\begin{array}{l} \Delta \mathbf{x}_{c} \\ \Delta \mathbf{x}_{p} \end{array}\right]=\left[\begin{array}{c} v-E C^{-1} w \\ w \end{array}\right]} \\ \Downarrow \\ {\left[\begin{array}{cc} B-E C^{-1} E^{T} & \mathbf{0} \\ E^{T} & C \end{array}\right]\left[\begin{array}{c} \Delta \mathbf{x}_{c} \\ \Delta \mathbf{x}_{p} \end{array}\right]=\left[\begin{array}{c} v-E C^{-1} w \\ w \end{array}\right]} \end{gathered} [I0−EC−1I][BETEC][ΔxcΔxp]=[I0−EC−1I][vw][B−EC−1ETETE−EC−1CC][ΔxcΔxp]=[v−EC−1ww]⇓[B−EC−1ETET0C][ΔxcΔxp]=[v−EC−1ww]
高斯消元后,方程组第一行变为与 Δ x p \Delta x_p Δxp 无关的项。单独把它拿出来,得到关于位姿部分 δ x c \delta x_c δxc 的增量方程:
[ B − E C − 1 E T ] Δ x c = v − E C − 1 w [B - EC^{-1}E^T]\Delta x_c = v - EC^{-1}w [B−EC−1ET]Δxc=v−EC−1w
这个线性方程的维度和 B B B 矩阵一样。通常做法是,先求解这个方程,然后把解得的 Δ x c \Delta x_c Δxc 带入原方程,求解 Δ x p \Delta x_p Δxp。这个过程称为 Marginalization,或者 Schur 消元。
相比于直接求解线性方程的做法,优势在于:
1.在消元过程中,由于 C C C 为对角块,所以 C − 1 C^{-1} C−1 容易求出。
2.求解了 Δ x c \Delta x_c Δxc 之后,路标部分的增量方程由 Δ x p = C − 1 ( w − E T Δ x c ) \Delta x_p = C^{-1}(w - E^T\Delta x_c) Δxp=C−1(w−ETΔxc) 给出。
前面说到, H H H 矩阵的非对角块的非零元素对应着相机和路标点的关联。那么,对 H H H 矩阵进行Schur Elimination舒尔消元后的 系数,记为 S S S 矩阵的稀疏性是否具有物理意义呢?答案是肯定的。此处,不加证明的说, S S S 矩阵的非对角线上的非零矩阵块,表示该处对应的两个相机变量之间存在着共同观测的路标点,有时称为共视(Co-visibility)。反之如果该块为零,表示这两个相机没有共同观测的路标点。例如,下图所示的稀疏矩阵,左上角前 4 * 4 个矩阵块可以表示对应的相机变量 C 1 , C 2 , C 3 , C 4 , C_1,C_2,C_3,C_4, C1,C2,C3,C4, 之间有共同观测。
从概率角度来说,称这一步为边缘化Marginalization,是因为实际上把求 [ Δ x c Δ x p ] [ \Delta x_c \; \Delta x_p] [ΔxcΔxp]的问题,转化成先固定 Δ x p \Delta x_p Δxp,求出 Δ x c \Delta x_c Δxc,再求 Δ x p \Delta x_p Δxp 的过程。这一步相当于做了条件概率展开:
P ( x c , x p ) = P ( x c ∣ x p ) P ( x p ) P(x_c,x_p) = P(x_c|x_p)P(x_p) P(xc,xp)=P(xc∣xp)P(xp)
结果是求出了关于 Δ x p \Delta x_p Δxp 的边缘分布,故称为边缘化。在前面介绍的边缘化过程中,实际上我们把所有的路标点都给边缘化了。根据实际情况,也能选择一部分进行边缘化。同时,舒尔消元只是实现边缘化的其中一种方式,同样可以使用 Cholesky 分解进行边缘化。
在进行了舒尔消元后,还需要求解线性方程组 [ B − E C − 1 E T ] Δ x c = v − E C − 1 w [B - EC^{-1}E^T]\Delta x_c = v - EC^{-1}w [B−EC−1ET]Δxc=v−EC−1w,对它的求解是否需要什么技巧?很遗憾,这部分属于传统的矩阵数值求解,通常是用分解来计算的。不管采用何种求解方法,都建议利用 H H H 矩阵的稀疏性进行舒尔消元。不光是因为这样可以提高速度,也因为消元后的 [公式] 矩阵的条件数往往比之前的 H H H 矩阵要小。舒尔消元而不意味着将所有路标点都消掉,将相机变量消元也是 SLAM 中采用的手段。
9.2.4 鲁棒核函数
在前面的BA问题种,将最小化误差项的二范数平方和作为目标函数。这种做法虽然很直观,但存在一个严重的问题:如果出现误匹配等问题,某个误差项给的数据是错误的,会把原本不应该加到图中的边给加进去了,然而优化算法并不能辨别出这是个错误数据,它会把所有数据都当作误差来处理。在算法看来,这相当于我们突然观测到了一次很不可能产生的数据。这时,图优化中会有一条误差很大的边,它的梯度也很大,意味着调整与它相关的变量会使目标函数下降更多。所以,算法将试图优先调整这条边所连接的节点的估计值,使他们顺应这条边的无理要求。由于这条边的误差真的很大,往往会抹平其他正确边的影响,使优化算法专注于调整一个错误的值,这显然不是希望看到的。
出现这种问题的原因是,当误差很大时,二范数增长得很快。于是就有了核函数的存在。核函数保证每条边的误差不会大到没边而掩盖其他的边。具体的方式是,把原来误差的二范数度量替换成一个增长没有那么快的函数,同时保证自己的光滑性质(不然无法求导)。因为它们使得整个优化结果更为稳健,所以又叫鲁棒核函数(Robust Kernel )。
鲁棒核函数有许多种,例如常用的 Huber 核:
H ( e ) = { 1 2 e 2 if ∣ e ∣ ≤ δ δ ( ∣ e ∣ − 1 2 δ ) otherwise H(e)= \begin{cases}\frac{1}{2} e^{2} & \text { if }|e| \leq \delta \\ \delta\left(|e|-\frac{1}{2} \delta\right) & \text { otherwise }\end{cases} H(e)={21e2δ(∣e∣−21δ) if ∣e∣≤δ otherwise
可以看到,当误差 e e e 大于某个阈值 δ \delta δ 后,函数增长由二次形式变成了一次形式,相当于限制了梯度的最大值。同时, Huber 核函数又是光滑的,可以很方便地求导。下图展示了 Huber 核函数与二次函数的对比,可见在误差很大时 Huber 核函数增长明显低于二次函数。

除了 Huber 核,还有 Cauchy 核、Tukey核等。