linux-4.19 内存管理
目录
内存管理
内存模型
buddy system
内存分配&zone 水位设置
slab 分配
kmalloc 分配
vmalloc 分配
malloc 分配
mmap
缺页异常
page
内存管理数据结构图
内存管理
在内核的内存初始化阶段,memblock 在完成了一些最基本的物理内存信息收集以及必要的内存分配之后,就需要着手开始向 buddy 系统进行迁移了。
struct page 和 pfn
对于 buddy 而言,最小的管理单元为一个物理页面,每个页面都由 struct page 结构来描述,该结构包含页面属性、是否分配、引用计数等页面相关信息,struct page 结构和页面本身是独立的,一片物理内存所对应的所有 struct page 结构通常会被统一分配,占用连续的物理内存。
同时,为了管理方便,每个物理页面还映射到一个页帧号 pfn,页面基地址和 pfn 基于线性映射,4K 页面映射的系统中 pfn = page_vaddr >> 12。
内存模型
内核中的内存模型分为三种:
- FLATMEM:平坦内存模型
- DISCONTIGMEM:非连续内存模型
- SPARSEMEM:稀疏内存模型
内存模型是否合适两个判断标准,一是是否在支持非连续内存的同时不造成内存的过多浪费,二是该内存模型是否能很好地处理 struct page 与物理页面之间的映射
SPARSEMEM模型
SPARSEMEM 在内存的描述中使用了 section 的概念(注意这里的section 和 MMU 的 section 映射不是同一个概念),section 的大小由体系结构决定,由原来对整块内存的操作变成对多个内存 section 的操作,分配 struct page 相关的操作更加灵活,可以做到按需分配。
为了在物理页帧号 pfh 和 strcut page之间进行高效转换,物理页帧号 pfn 的几个高位用于索引sections数组,解决了从物理页面到 struct page 的映射,另一方向上,段号被编码在 struct page 中,由 struct page 到物理页面的映射也就解决了。
PLATMEM 模型
在内核的初始化阶段,将会一次性为所有的物理页面 struct page 结构体,占用连续的内存,基地址保存在全局变量 struct page* mem_map 中,因此,struct page 和物理页帧号之间的映射实现为:
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)
实现非常简单,从原理上来说,也就是物理页面相对于物理内存基地址的偏移等于 struct page 结构相对 mem_map 基地址的偏移,基于这个进行双向的映射。
其它内存模型如下:
kernel-4.19/include/asm-generic/memory_model.h
/* SPDX-License-Identifier: GPL-2.0 */
2 #ifndef __ASM_MEMORY_MODEL_H
3 #define __ASM_MEMORY_MODEL_H
4
5 #include
6
7 #ifndef __ASSEMBLY__
8
9 #if defined(CONFIG_FLATMEM)
10
11 #ifndef ARCH_PFN_OFFSET
12 #define ARCH_PFN_OFFSET (0UL)
13 #endif
14
15 #elif defined(CONFIG_DISCONTIGMEM)
16
17 #ifndef arch_pfn_to_nid
18 #define arch_pfn_to_nid(pfn) pfn_to_nid(pfn)
19 #endif
20
21 #ifndef arch_local_page_offset
22 #define arch_local_page_offset(pfn, nid) \
23 ((pfn) - NODE_DATA(nid)->node_start_pfn)
24 #endif
25
26 #endif /* CONFIG_DISCONTIGMEM */
27
28 /*
29 * supports 3 memory models.
30 */
31 #if defined(CONFIG_FLATMEM)
32
33 #define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
34 #define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \
35 ARCH_PFN_OFFSET)
36 #elif defined(CONFIG_DISCONTIGMEM)
37
38 #define __pfn_to_page(pfn) \
39 ({ unsigned long __pfn = (pfn); \
40 unsigned long __nid = arch_pfn_to_nid(__pfn); \
41 NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\
42 })
43
44 #define __page_to_pfn(pg) \
45 ({ const struct page *__pg = (pg); \
46 struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \
47 (unsigned long)(__pg - __pgdat->node_mem_map) + \
48 __pgdat->node_start_pfn; \
49 })
50
51 #elif defined(CONFIG_SPARSEMEM_VMEMMAP)
52
53 /* memmap is virtually contiguous. */
54 #define __pfn_to_page(pfn) (vmemmap + (pfn))
55 #define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
56
57 #elif defined(CONFIG_SPARSEMEM)
58 /*
59 * Note: section's mem_map is encoded to reflect its start_pfn.
60 * section[i].section_mem_map == mem_map's address - start_pfn;
61 */
62 #define __page_to_pfn(pg) \
63 ({ const struct page *__pg = (pg); \
64 int __sec = page_to_section(__pg); \
65 (unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
66 })
67
68 #define __pfn_to_page(pfn) \
69 ({ unsigned long __pfn = (pfn); \
70 struct mem_section *__sec = __pfn_to_section(__pfn); \
71 __section_mem_map_addr(__sec) + __pfn; \
72 })
73 #endif /* CONFIG_FLATMEM/DISCONTIGMEM/SPARSEMEM */
74
75 /*
76 * Convert a physical address to a Page Frame Number and back
77 */
78 #define __phys_to_pfn(paddr) PHYS_PFN(paddr)
79 #define __pfn_to_phys(pfn) PFN_PHYS(pfn)
80
81 #define page_to_pfn __page_to_pfn
82 #define pfn_to_page __pfn_to_page
83
84 #endif /* __ASSEMBLY__ */
85
86 #endif
Kernel 4.19
#
# Memory Management options
#
CONFIG_SELECT_MEMORY_MODEL=y
# CONFIG_FLATMEM_MANUAL is not set
CONFIG_SPARSEMEM_MANUAL=y
CONFIG_SPARSEMEM=y
CONFIG_HAVE_MEMORY_PRESENT=y
CONFIG_SPARSEMEM_EXTREME=y
CONFIG_SPARSEMEM_VMEMMAP_ENABLE=y
CONFIG_SPARSEMEM_VMEMMAP=y
CONFIG_HAVE_MEMBLOCK=y
CONFIG_NO_BOOTMEM=y
CONFIG_MEMORY_ISOLATION=y
CONFIG_SPLIT_PTLOCK_CPUS=4
CONFIG_COMPACTION=y
CONFIG_MIGRATION=y
CONFIG_PHYS_ADDR_T_64BIT=y
# CONFIG_KSM is not set
CONFIG_DEFAULT_MMAP_MIN_ADDR=4096
CONFIG_ARCH_SUPPORTS_MEMORY_FAILURE=y
# CONFIG_MEMORY_FAILURE is not set
# CONFIG_TRANSPARENT_HUGEPAGE is not set
# CONFIG_CLEANCACHE is not set
# CONFIG_FRONTSWAP is not set
CONFIG_CMA=y
# CONFIG_CMA_DEBUG is not set
CONFIG_CMA_AREAS=7
# CONFIG_ZPOOL is not set
# CONFIG_ZBUD is not set
CONFIG_ZSMALLOC=y
CONFIG_PGTABLE_MAPPING=y
# CONFIG_ZSMALLOC_STAT is not set
# CONFIG_MM_EVENT_STAT is not set
CONFIG_GENERIC_EARLY_IOREMAP=y
# CONFIG_BALANCE_ANON_FILE_RECLAIM is not set
# CONFIG_DEFERRED_STRUCT_PAGE_INIT is not set
# CONFIG_IDLE_PAGE_TRACKING is not set
CONFIG_PROCESS_RECLAIM_ENHANCE=y
CONFIG_PROCESS_RECLAIM=y
CONFIG_DYNAMIC_TUNNING_SWAPPINESS=y
CONFIG_ARCH_HAS_PTE_SPECIAL=y
CONFIG_FRAME_VECTOR=y
# CONFIG_PERCPU_STATS is not set
# CONFIG_GUP_BENCHMARK is not set
CONFIG_ARCH_SUPPORTS_SPECULATIVE_PAGE_FAULT=y
CONFIG_SPECULATIVE_PAGE_FAULT=y
CONFIG_MTK_MM_DEBUG=y
# CONFIG_OPLUS_MEM_MONITOR is not set
CONFIG_PHYSICAL_ANTI_FRAGMENTATION=y
CONFIG_KMALLOC_DEBUG=y
CONFIG_VMALLOC_DEBUG=y
# CONFIG_MEMLEAK_DETECT_THREAD is not set
CONFIG_DUMP_TASKS_MEM=y
CONFIG_NET=y
CONFIG_COMPAT_NETLINK_MESSAGES=y
CONFIG_NET_INGRESS=y
CONFIG_NET_EGRESS=y
buddy system
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
ZONE_DMA 区域用于DMA 大量数据访问;
ZONE_HIGHMEM 用于32 位系统 内核空间受限,动态映射访问
ZONE_MOVABLE 用于内核页面回收和碎片处理
NUMA 节点
尽管本系列文章并不涉及到 numa 系统的分析,但是在内核中,buddy 子系统会将所有机器抽象为 numa 架构,非 numa 系统被内核视为单节点 numa 系统,这样就可以实现接口的统一,在分析内存时还是不能忽略这个概念。
因此,不难推出,一个 numa 节点就是一个完整的内存管理区域,每个 numa 节点包含一个 struct pglist_data 结构,同样是以 pgdat -> zones -> pages 的树形结构来管理一片完整的物理内存。
buddy system
伙伴系统(buddy system),动态管理存储。
kernel-4.19/arch/arm64/kernel/setup.c
void __init setup_arch(char **cmdline_p){
paging_init();
339
340 acpi_table_upgrade();
341
342 /* Parse the ACPI tables for possible boot-time configuration */
343 acpi_boot_table_init();
344
345 if (acpi_disabled)
346 unflatten_device_tree();
347
348 bootmem_init();
349
350 kasan_init();
}
paging_init 函数中建立完页表之后,会执行bootmem_init,对 zone 执行初始化工作
496 void __init bootmem_init(void)
497 {
498 unsigned long min, max;
499
500 min = PFN_UP(memblock_start_of_DRAM());
501 max = PFN_DOWN(memblock_end_of_DRAM());
502
503 early_memtest(min << PAGE_SHIFT, max << PAGE_SHIFT);
504
505 max_pfn = max_low_pfn = max;
506 min_low_pfn = min;
507
508 arm64_numa_init();
509 /*
510 * Sparsemem tries to allocate bootmem in memory_present(), so must be
511 * done after the fixed reservations.
512 */
513 arm64_memory_present();
514
515 sparse_init();
516 zone_sizes_init(min, max);
517
518 memblock_dump_all();
519 }
246 #else
247
248 static void __init zone_sizes_init(unsigned long min, unsigned long max)
249 {
250 struct memblock_region *reg;
251 unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES];
252 unsigned long max_dma = min;
253
254 memset(zone_size, 0, sizeof(zone_size));
255
256 /* 4GB maximum for 32-bit only capable devices */
257 #ifdef CONFIG_ZONE_DMA32
258 max_dma = PFN_DOWN(arm64_dma_phys_limit);
259 zone_size[ZONE_DMA32] = max_dma - min;
260 #endif
261 zone_size[ZONE_NORMAL] = max - max_dma;
262
263 memcpy(zhole_size, zone_size, sizeof(zhole_size));
264
265 for_each_memblock(memory, reg) {
266 unsigned long start = memblock_region_memory_base_pfn(reg);
267 unsigned long end = memblock_region_memory_end_pfn(reg);
268
269 if (start >= max)
270 continue;
271
272 #ifdef CONFIG_ZONE_DMA32
273 if (start < max_dma) {
274 unsigned long dma_end = min(end, max_dma);
275 zhole_size[ZONE_DMA32] -= dma_end - start;
276 }
277 #endif
278 if (end > max_dma) {
279 unsigned long normal_end = min(end, max);
280 unsigned long normal_start = max(start, max_dma);
281 zhole_size[ZONE_NORMAL] -= normal_end - normal_start;
282 }
283 }
284
285 free_area_init_node(0, zone_size, min, zhole_size);
286 }
287
288 #endif /* CONFIG_NUMA *
kernel-4.19/include/linux/mmzone.h
struct zone {
/* zone watermarks, access with *_wmark_pages(zone) macros */ unsigned long watermark[NR_WMARK];
#每个zone 对应的三个水位值,跟杀应用内存回收相关
long lowmem_reserve[MAX_NR_ZONES];
#highmem zone 内存不足会占用一部分normal zone ,normal zone 不足会占用一部分DMA zone #,所以对DMA zone 和 normal zone 都要预留一部分,避免被其它zone 占完。
#/proc/sys/vm # cat min_free_kbytes
....
struct free_area free_area[MAX_ORDER];
#空闲页管理,这里按照 2^n (n =0,...,11) 页大小管理空闲的页面
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
对应每种 2^n 页大小的空闲空间,将对应的空间分为下面的 MIGRATE_TYPES 中类型:
enum migratetype {
45 MIGRATE_UNMOVABLE,
46 MIGRATE_MOVABLE,
47 MIGRATE_RECLAIMABLE,
48#ifdef CONFIG_CMA
}

Linux内存调节之lowmem reserve - 知乎
linux内存子系统 - buddy 子系统1 - 框架的建立 - 知乎
linux内存子系统 - buddy 子系统2 - memblock 到 buddy - 知乎
linux内存子系统 - buddy 子系统0 - 数据结构与基本原理 - 知乎
可以查看
/proc/zoneinfo
/proc/pagetypeinfo
/proc/buddyinfo (不同类型页面按 2^n 大小统计的页面数量)
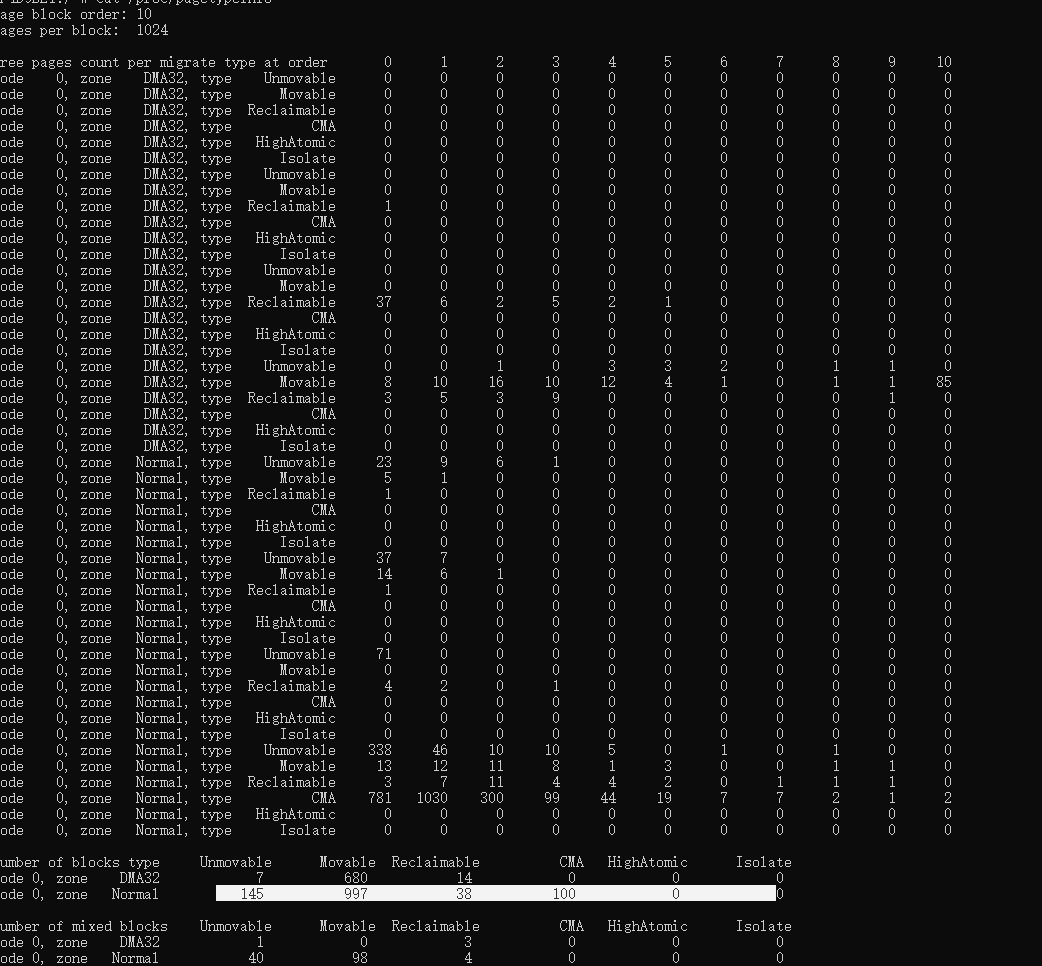

/proc/meminfo
/proc/vmstat
内存统计信息
vmstat 命令查看系统内存、i/o、cpu 等资源使用情况

内存分配&zone 水位设置
伙伴系统通过alloc_pages 分配物理页
kernel-4.19/mm/page_alloc.c
kernel-4.19/include/linux/gfp.h
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
gfp_mask 分配掩码,分为两类,一类zone modifiers ,自定从哪个zone 分配,比如_GFP_DMS 、__GFP_MOVABLE 等,由低4位确定;另一类是action modifiers,不限制从哪个zone 分配,但是会改变分配行为;另外一个参数指分配联系页面数 2^n;
如alloc_pages(GFP_KERNEL,order)
->...->_alloc_pages_modemask
这里会调用get_page_from_freelist 尝试分配物理页,如果失败就会调用__alloc_pages_slowpath
水位设置:

7706static void __setup_per_zone_wmarks(void)
7707{
7708 unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
7709 unsigned long pages_low = extra_free_kbytes >> (PAGE_SHIFT - 10);
7710 unsigned long lowmem_pages = 0;
7711 struct zone *zone;
7712 unsigned long flags;
7713
7714 /* Calculate total number of !ZONE_HIGHMEM pages */
7715 for_each_zone(zone) {
7716 if (!is_highmem(zone))
7717 lowmem_pages += zone->managed_pages;
7718 }
7719
7720 for_each_zone(zone) {
7721 u64 min, low;
7722
7723 spin_lock_irqsave(&zone->lock, flags);
7724 min = (u64)pages_min * zone->managed_pages;
7725 do_div(min, lowmem_pages);
7726 low = (u64)pages_low * zone->managed_pages;
7727 do_div(low, vm_total_pages);
7728
7729 if (is_highmem(zone)) {
7730 /*
7731 * __GFP_HIGH and PF_MEMALLOC allocations usually don't
7732 * need highmem pages, so cap pages_min to a small
7733 * value here.
7734 *
7735 * The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN)
7736 * deltas control asynch page reclaim, and so should
7737 * not be capped for highmem.
7738 */
7739 unsigned long min_pages;
7740
7741 min_pages = zone->managed_pages / 1024;
7742 min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL);
7743 zone->watermark[WMARK_MIN] = min_pages;
7744 } else {
7745 /*
7746 * If it's a lowmem zone, reserve a number of pages
7747 * proportionate to the zone's size.
7748 */
7749 zone->watermark[WMARK_MIN] = min;
7750 }
slab 分配
slab 将伙伴系统分配的页可以按字节再次分配
kernel-4.19/mm/slab_common.c
struct kmem_cache *kmem_cache_create(); 创建slab 描述符,用户创建自己的缓冲描述符
kmalloc 用于创建通用slab 缓冲
void kmem_cache_destory(); 销毁slab描述符
kmem_cache_alloc;分配slab 缓存对象,会关闭本地中断
kmem_cache_free ;释放slab 对象,会关闭本地中断
kernel-4.19/include/linux/slab.h
262#ifdef CONFIG_SLOB
263/*
264 * SLOB passes all requests larger than one page to the page allocator.
265 * No kmalloc array is necessary since objects of different sizes can
266 * be allocated from the same page.
267 */
268#define KMALLOC_SHIFT_HIGH PAGE_SHIFT
269#define KMALLOC_SHIFT_MAX (MAX_ORDER + PAGE_SHIFT - 1)
270#ifndef KMALLOC_SHIFT_LOW
271#define KMALLOC_SHIFT_LOW 3
272#endif
273#endif
274
275/* Maximum allocatable size */
276#define KMALLOC_MAX_SIZE (1UL << KMALLOC_SHIFT_MAX)
277/* Maximum size for which we actually use a slab cache */
278#define KMALLOC_MAX_CfACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH)
279/* Maximum order allocatable via the slab allocagtor */
280#define KMALLOC_MAX_ORDER (KMALLOC_SHIFT_MAX - PAGE_SHIFT)
281
282/*
283 * Kmalloc subsystem.
284 */
285#ifndef KMALLOC_MIN_SIZE
286#define KMALLOC_MIN_SIZE (1 << KMALLOC_SHIFT_LOW)
287#endif
28
slab 区域位2^25 * PAGE_SIZE = 32M ;
当分配slab 时,会根据分配的size 从 2^0~2^order( 最大KMALLOC_MAX_ORDER) 个页面大小尝试,直到找到最合适的order 。
kernel-4.19/include/linux/slab_def.h
struct kmem_cache {
#cpu 本地缓存
struct array_cache __percpu *cpu_cache;
#cpu缓存&cpu共享缓存计数相关
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
# 根据 num = 2^order 页面/ (size + sizeof(freelist_cache))
#也就是根据分配对象size 大小,确定分配了页面可以细分位多少个对象,这里可以简单认为分配一个size 大小对象,依附分配一个freelist_cache;
unsigned int num; /* # of objs per slab */
struct kmem_cache *freelist_cache;
unsigned int freelist_size;
#left_over = 2^order - 2^order 页面/ (size + sizeof(freelist_cache))
#分配了num个对象,还剩余的空间,这个时候 colour_off = cache_line_size() ,也就是一级缓存
#大小;colour = left_over/colour_off ,剩余空间可以当多少个一级缓存;
#这里跟本cpu本地缓存,其它cpu共享缓存相关
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
#node 链表管理slab 分配对象使用情况
struct kmem_cache_node *node[MAX_NUMNODES];
}
slob 适用于微小嵌入式系统,slub 使用大型大内存系统,这样性能比slab更好
kmalloc 分配
kmalloc 是使用slab机制,按照2^order 页内存,来创建多个slab 描述符,如16B、32B、64B、... 、32M,系统命名为kmalloc-16等;这些实在系统启动 是create_kmalloc_caches()中完成。
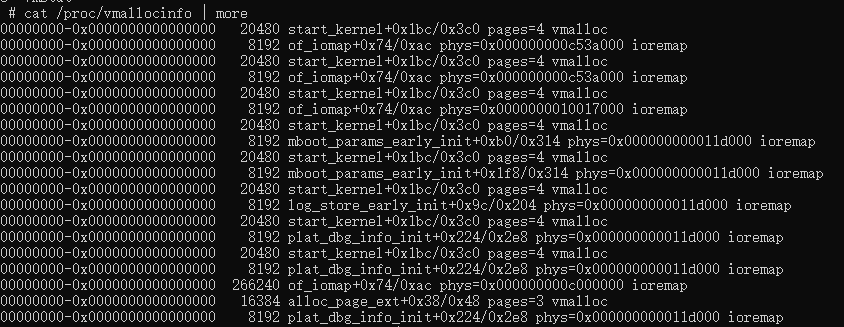
vmalloc 分配
vmalloc.c
void *vzalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL | __GFP_ZERO);
}
vmallc 优先从高端内存(arm32),从VMALLOC_START~ VMALLOC_END分配,虚拟地址是连续,物理地址不一定连续。 vmalloc 会睡眠,不能在中断上下文使用。
这里会创建struct vm_struct 来描述申请的vmalloc区域,从VMALLOC_START~ VMALLOC_END 查找目前系统中vmap_area_root红黑树查找适合的空闲空间,找到就返回vmap_area 描述符,不存在合适的,就通过alloc_page 来分配物理页面;这里如果分配页面小于一页,调用kmalloc_node ,这就成了slab 分配,大于一页大小调用__vmalloc_node;
int node, const void *caller);
1684static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
1685 pgprot_t prot, int node)
1686{
1687 struct page **pages;
1688 unsigned int nr_pages, array_size, i;
1689 const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;
1690 const gfp_t alloc_mask = gfp_mask | __GFP_NOWARN;
1691 const gfp_t highmem_mask = (gfp_mask & (GFP_DMA | GFP_DMA32)) ?
1692 0 :
1693 __GFP_HIGHMEM;
1694
1695 nr_pages = get_vm_area_size(area) >> PAGE_SHIFT;
1696 array_size = (nr_pages * sizeof(struct page *));
1697
1698 /* Please note that the recursion is strictly bounded. */
1699 if (array_size > PAGE_SIZE) {
1700 pages = __vmalloc_node(array_size, 1, nested_gfp|highmem_mask,
1701 PAGE_KERNEL, node, area->caller);
1702 } else {
1703 pages = kmalloc_node(array_size, nested_gfp, node);
1704 }
1705
1706 if (!pages) {
1707 remove_vm_area(area->addr);
1708 kfree(area);
1709 return NULL;
1710 }
1711
1712 area->pages = pages;
1713 area->nr_pages = nr_pages;
1714
1715 for (i = 0; i < area->nr_pages; i++) {
1716 struct page *page;
1717
1718 if (node == NUMA_NO_NODE)
1719 page = alloc_page(alloc_mask|highmem_mask);
1720 else
1721 page = alloc_pages_node(node, alloc_mask|highmem_mask, 0);
1722
1723 if (unlikely(!page)) {
1724 /* Successfully allocated i pages, free them in __vunmap() */
1725 area->nr_pages = i;
1726 atomic_long_add(area->nr_pages, &nr_vmalloc_pages);
1727 goto fail;
1728 }
1729 area->pages[i] = page;
1730 if (gfpflags_allow_blocking(gfp_mask|highmem_mask))
1731 cond_resched();
1732 }
1733 atomic_long_add(area->nr_pages, &nr_vmalloc_pages);
1734
1735 if (map_vm_area(area, prot, pages))
1736 goto fail;
1737 return area->addr;
1738
1739fail:
1740 warn_alloc(gfp_mask, NULL,
1741 "vmalloc: allocation failure, allocated %ld of %ld bytes",
1742 (area->nr_pages*PAGE_SIZE), area->size);
1743 vfree(area->addr);
1744 return NULL;
1745}
再通过map_vm_area 建立页表页面映射。
vma
kernel-4.19/include/linux/mm_types.h
struct mm_struct {
struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
#ifdef CONFIG_SPECULATIVE_PAGE_FAULT
rwlock_t mm_rb_lock;
#endif
u64 vmacache_seqnum; /* per-thread vmacache */
mmap 是记录vma 的链表,进程中所以vma 按照地址递增链接的在mmap ;当vma 数量小,查找效率高
mm_rb 进程中按照数链接;当vma 数量很大,查找效率高
find_vma(address ) 通过虚拟地址查找合适的vma;task_struct 中vmacache[] 缓存这最近访问过的vma 信息;进程地址空间在内核中使用VMA来抽象描述,VMA离散分布在3G 用户空间(arm32)。
malloc 分配
malloc 为用户空间进程分配空间,通过brk 系统调用,向内核申请内存分配;内核分配一个VMA 区域,建立页面映射,返回虚拟地址。
在arm32 位系统,3G 用户空间,在每个进程可执行文件,在加载时,从低地址到高地址,为保留区,代码段区,数据段区,接着是brk 分配堆区,start_brk = end_data ,再往上是mmap 区,栈;
mmap
mmap/munmap 接口时用户空间常用的一个系统调用接口,跟brk 机制类似,有很大vma相关操作。
kernel-4.19/mm/mmap.c
bionic/libc/bionic/mmap.cpp
void* mmap(void* addr, size_t size, int prot, int flags, int fd, off_t offset) {
return mmap64(addr, size, prot, flags, fd, static_cast
}
addr : 指定映射到进程空间的地址,通常NULL,由内核选择合适地址
size:映射到进程空间的大小
prot:设置内存映射读写属性
flags:设置内存映射属性,如共享映射、私有映射
fd:文件映射对应文件句柄
offset:文件映射时表示文件偏移
flags: MAP_SHARED 共享区域,多个进程可以通过共享映射一个文件,将文件映射到进程空间,可以看到其它进程修改的内容,修改后内容会同步到磁盘文件。
MAP_PRIVATE 创建私有写时复制映射,多个进程通过私有映射同一个文件到进程空间,其它进程看不到修改的内容,修改后内容不会同步磁盘。
MAP_ANONYMOUS 没有关联文件的映射,映射区域会初始化为0
匿名私有映射:通常用于分配内存
文件私有映射:通常用于加载动态库
匿名共享映射:通常用户进程间共享内存;通过shmem 模块打开 /dev/zero 设备文件来创建
文件共享映射:通常用于内存映射I/O ,用于进程间通信;多个进程将同一个文件映射到进程地址空间,这样修改文件内容,其它进程可以看到
mmap 文件映射只是建立进程地址空间vma 映射,没有分配page cache 及建立映射和磁盘将文件内容读入page cache。当需要读写文件,会产生缺页中断,将对应的内容从磁盘读入page cache。madvise() 可以让系统建立vma 时预读到page cache.
缺页异常
malloc 和 mmap 都是用户空间api 在内核实现,通过系统调用;两个函数都只创建进程空间地址vma 的映射。当访问时,会发生data abort 缺页异常中断,fault.c 里面调用 do_dataabort(addr ,fsr ,regs)
arm mmu 中有两个跟存储访问失效存储器, 失效状态寄存器 fsr 和 失效地址寄存器 far ,这两个寄存器信息会传入do_dataabort,根据fsr 确定失效原因,及解析来处理函数
1// SPDX-License-Identifier: GPL-2.0
2static struct fsr_info fsr_info[] = {
3 { do_bad, SIGBUS, 0, "unknown 0" },
4 { do_bad, SIGBUS, 0, "unknown 1" },
5 { do_bad, SIGBUS, 0, "unknown 2" },
6 { do_bad, SIGBUS, 0, "unknown 3" },
7 { do_bad, SIGBUS, 0, "reserved translation fault" },
8 { do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" },
9 { do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 2 translation fault" },
10 { do_page_fault, SIGSEGV, SEGV_MAPERR, "level 3 translation fault"
如果这个时候没有找到vma,发生在用户空间(task_struct->mm_struct 为空),则调用__do_user_fault() 发生异常信号-》force_sig_info 发送信号到异常进程;发生在内核空间,调用__do_kernel_fault();找到了vma ,调用handle_mm_fault建立vma 到物理页面映射。
page
kernel-4.19/include/linux/mm_types.h
struct page {
unsigned long flags; #页面标志位及section、zone 、node等信息
struct address_space *mapping;
#内核有两种地址,一种时文件映射,这个跟文件存储的介质关联;
#另外一种是匿名映射或ksm,使用低2位判断;最低一位不为0,指向指向struct anon_vma
#低第二位不为0 对应ksm.
atomic_t _refcount; #内核中计数跟着页面,伙伴系统分配好页面,会设置位1;get_page()会自加,put_page()会
#自减;当为 0 时,说明页面空闲或即将释放;大于0 说明已经分配并内核正在使用
atomic_t _mapcount; #被进程PTE 映射的进程数;-1 表示没有进程页映射,0 表示只有父进程pte 映射
}
页面锁PG_locked
unsigned long flags;定义了一个标志位 PG_locked,内核理页pg_locked获取一个页面锁;lock_page() 用于申请页面锁,被占用就会睡眠等待。
kernel-4.19/include/linux/pagemap.h
kernel-4.19/mm/filemap.c
476/*
477 * lock_page may only be called if we have the page's inode pinned.
478 */
479static inline __sched void lock_page(struct page *page)
480{
481 might_sleep();
482 if (!trylock_page(page))
483 __lock_page(page);
484}
485
/**
1307 * __lock_page - get a lock on the page, assuming we need to sleep to get it
1308 * @__page: the page to lock
1309 */
1310void __sched __lock_page(struct page *__page)
1311{
1312 struct page *page = compound_head(__page);
1313 wait_queue_head_t *q = page_waitqueue(page);
1314 wait_on_page_bit_common(q, page, PG_locked, TASK_UNINTERRUPTIBLE, true);
1315}
1316EXPORT_SYMBOL(__lock_page);
RMVA 反向映射虚拟内存
多个用户进程PTE 映射到一个物理页面;RMVA 就是确定某个物理页面被哪些进程PTE 映射了。
malloc 调用会创建匿名页;cow 写时复制也会创建匿名页面;
anon_vma 简称av ;anon_vma_chain 简称avc
fork 创建子进程,会将父进程vma 、PTE 复制到子进程,这样多个vma 页面映射到同一个物理页;面;页可以使用ksm 将不相干vma 页面映射到同一个物理页面。
kswap 回收匿名页面;页面迁移都需要断开跟物理页面映射的PTE 页表项;unmap 用于端口,ksm页面,匿名页面,文件映射页面。
内存管理数据结构图
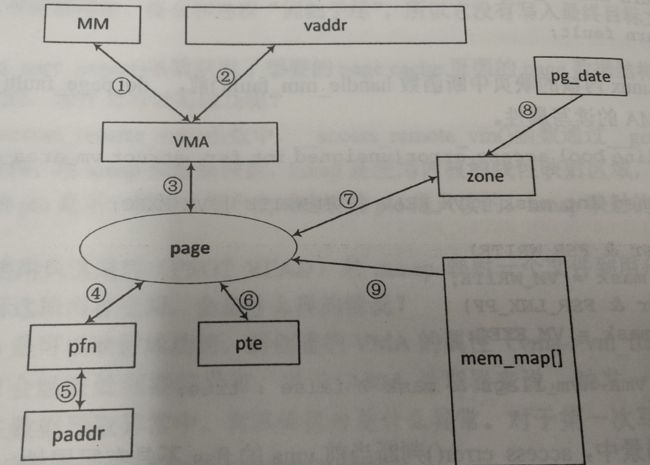
内存异常
android 内存管理
prorank
memtest 坏点检测、内存填充
malloc_debug
memleak c/c++ 内存泄漏
踩内存 asan
Java的四种引用
强引用,永远都不会被回收的内存,程序宁愿跑出oom也不回回收
软引用,当内存不足时会进行回收(实际回收时会对内存分类标记,GC第一次运行会按优先级回收弱引用和虚引用,这时若内存还是不足,则GC会再执行一次,将软引用回收)
弱引用,GC一开始工作就回回收
虚引用,任何时候都有可能被回收
java 静态域持有对象的应用、java 内部非静态类持有外部类引用,导致对象泄漏
内存优化:开机内存 =》 压缩(zram)、启动控制、应用占用内存
运行时内存 =》 内存压缩、内存泄漏(java/native)、内存碎片管理
1、zram
2、unmovable
3、java heap 参数
4、lmk uevent事件上报(lmk native 泄漏不会杀,这样就可以java统计占内存高给到底层杀掉对应native service)
内存异常
用户态内核态内存异常种类
应用内存泄漏、系统内存泄漏
1、使用未初始化内存
栈上变量、全局变量、局部静态变量没有初始化
2、使用释放的内存如uaf
已经释放堆内存、返回的局部变量、内存踩踏、null、内核中已经释放的内存(page、vmalloc、slab 等)
3、越界
栈溢出、堆溢出、全局变量buffer 溢出、数组越界、数据类型强制转换导致越界访问
4、内存泄漏
进程内存泄漏:Native heap 内存泄漏,如malloc 、new 、brk 、mmap;java heap 泄漏
系统内存泄漏:slab 内存泄漏、vmalloc内存泄漏、alloc_page 内存泄漏
oom 虚拟内存、物理内存
内存异常检测:
未初始化内存、使用释放的内存、越界访问类型:
用户态:uasan、hwasan、gwp-asan(native内存,集成到app)
内核态:kasan、slub_debug
内存泄漏:
用户态 1、 LeakCannary/AndroidProfile、mat
2、malloc_debug、mmap_debug(native)
内核态slub_debug、slubtrace
vmallocinfo
page_owner(stackdepot)
kmemleak

参考链接
内核入口 - start_kernel · Linux Insides中文